본 포스트는 LG Aimers 활동에 참여하며 온라인 AI 교육을 정리한 내용입니다!
프로그램에 관심이 있으시다면 https://www.lgaimers.ai/ 를 참고해주세요!!
Machine Learning
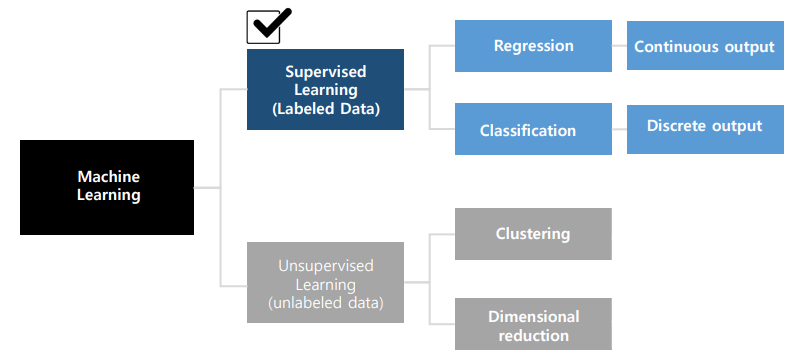
- Data로부터 내재된 패턴을 학습하는 과정
- spam mail 판단, image 인지, 가격 예측 등이 가능하다.
- Binary Classification / Multiclass classification / Regression..
Supervised Learning
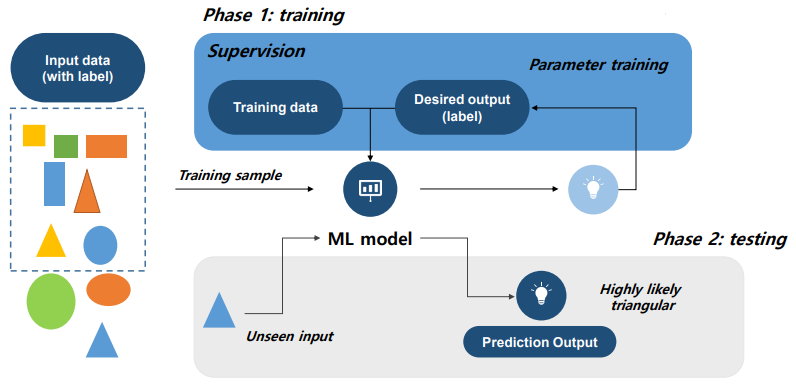
- 데이터 셋이 입력 X와 출력 y(label)의 쌍으로 구성되어 있다.
- data set을 이용하여 X→y로 가는 함수 h를 학습하는 것이 목표이다.
- ML model이 data를 이용하여 학습을 하고 판단을 한다. model의 parameter값을 조정하며 label을 더욱 정확하게 맞출 수 있도록 한다.
- feature : 입력 표현으로, domain knowledge를 알고 있어야 사용을 원활히 할 수 있다.
Target function
- 입력 X를 출력 y로 wrapping을 하는 정답 함수
- 모든 입력 sample에 대해 분류하고 성능을 보장하기 위해서는 모든 case를 확인해야하지만, 제한적인 숫자로 구성된 data set을 사용하기 때문에 최대한 target fuction에 근접한 모델을 만들어야한다.
Model Seclection
- 풀고자 하는 문제에 가장 적합한 model을 선택하는 과정
Optimization
- model parameter를 최적화하여 model이 가장 우수한 성능을 제공하도록 하는 과정
Generalization
- model이 학습 과정에서 관찰하지 못한 sample에 대해서도 우수한 성능을 제공하도록 하는 방식
- generalized error(error function)을 최소화해야한다.
Errors
- 각 sample 별로 pointwise로 계산한다.
- data sample에서 발생하는 모든 sample의 pointwise error를 합쳐서 overall error를 계산한다.
- loss function(cost function) : overall error를 계산하는 함수
Squared error
- 모델 출력 h(x)와 정답 y의 차이를 제곱하여 계산
Binary error
- 내부의 logic을 판별하여 맞으면 0, 틀리면 1인 함수
Bias and Variance
- model 의 정확도 ↑
- bias ↓
- model의 일반성 ↑
- variance ↓
Underfitting
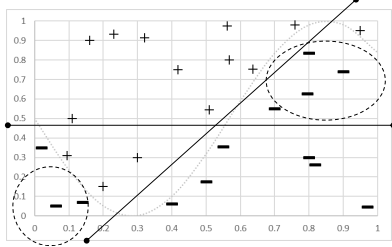
- high bias / low variance
- 너무 간단한 model을 사용하게 되었을 때 발생한다.
Overfitting
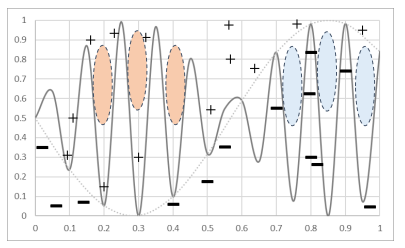
- low bias / high variance
- 너무 복잡한 모델을 사용했을 때 발생한다.
Bias-variance trade-off
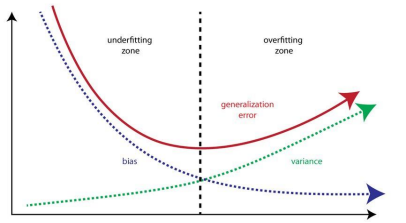
- 모델의 복잡도가 높아지면 overfitting이 발생하기 쉬우며 variance는 높아지지만 bias는 낮아지게 된다.
- model에 새로운 sample을 적용하기 어려워진다.
- 모델의 복잡도가 낮아지면 underfitting이 발생하기 쉬우며 bias는 높아지고 variance는 낮아지게 된다.
- model이 제대로 된 성능을 내기 어려워진다.
Avoid overfitting
- 복잡도 증가 속도 > Data set sample 수
- overfitting의 문제가 커지고 있다.
- Data를 늘리기
- 노력과 비용의 소모가 크다.
- Data augmentation
- Data를 변형하거나 computer로 생성/합성을 하여 sample을 늘리는 방법이 있다.
- Regularization / Ensemble..
Curse of Dimension(차원의 저주)
- data 또는 입력 feature의 차원이 증가한다면 지수적으로 sample의 숫자가 늘어나야 하지만 어려운 상황이다.
Cross-validation(CV)
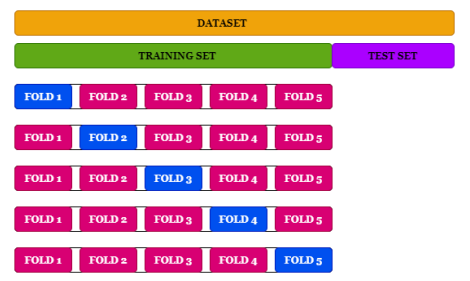
- train set을 k개의 그룹으로 분리하고, k-1개의 그룹을 train하고 1개를 validation을 하는 방식
- data augmentation을 진행하여 모델을 일반화하는데 도움이 될 수 있다.

안녕하세요 :) Data/AI 공부 중인 한국외대 컴퓨터공학부 조권휘입니다.