일반적인 ML 워크 플로우의 핵심 단계
머신러닝의 프로젝트의 목표는 수집된 데이터를 사용하여 이 데이터를 머신러닝 알고리즘을 적용하여 통계 분석을 제공하는 것입니다.
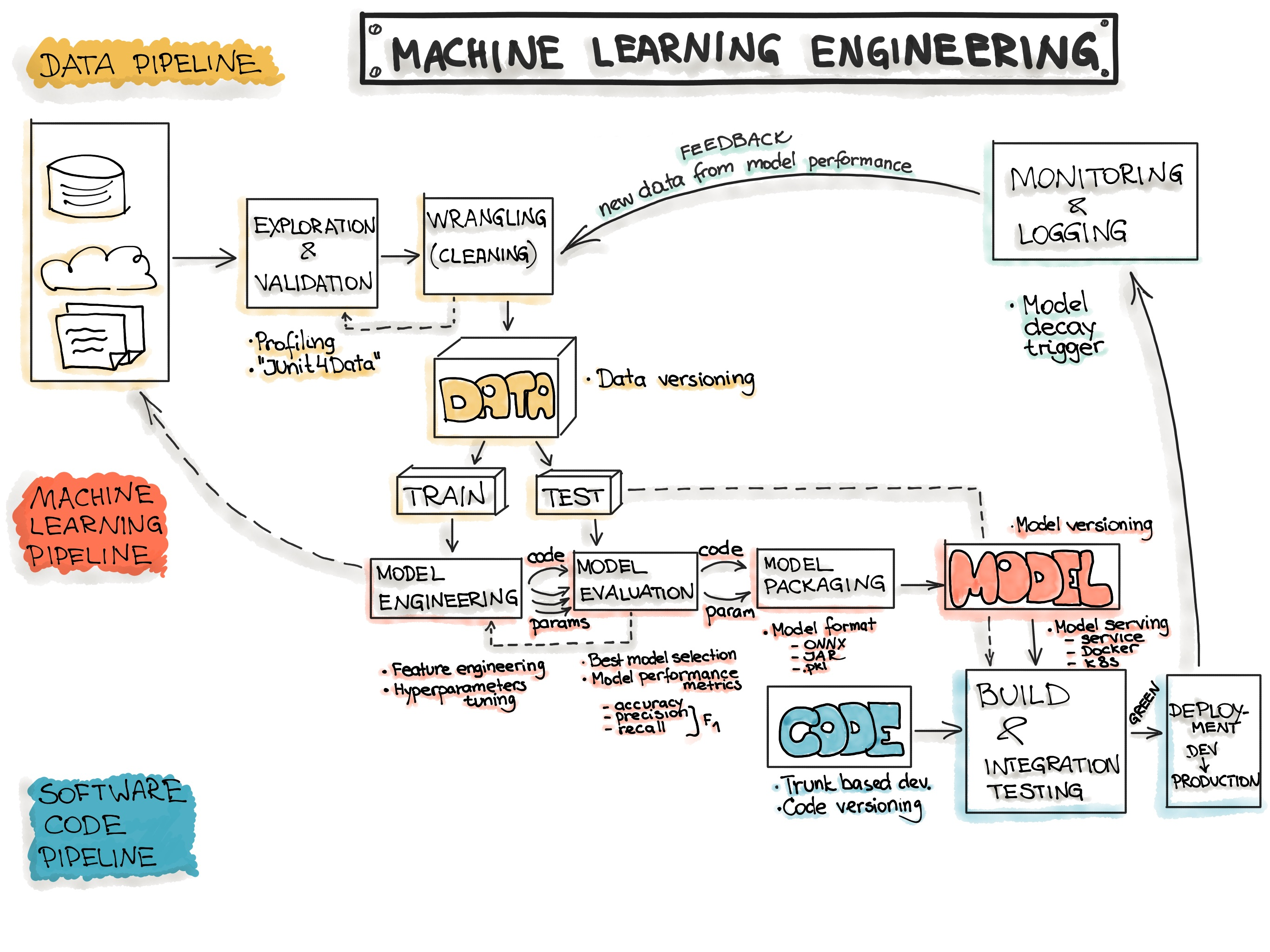
즉, 여기서 기본적으로 Data, ML Model, Code에 대한 세 가지의 주요 아티팩트에 대한 이야기를 할 수 있습니다.
기본적인 아티팩트 3가지에 해당하는 머신러닝 플로우는 3가지의 주요 단계로 구성됩니다.
- 데이터 엔지니어링 : 데이터 수집 및 데이터 준비
- ML 모델 엔지니어링 : ML 모델 교육 및 제공
- 코드 엔지니어링 : ML 모델을 최종적으로 통합
데이터 엔지어링
모든 데이터 과학 워크플로의 초기 단계는 분석할 데이터를 수집하고 준비하는 것
가트너의 따르면, 데이터 준비에서의 데이터 수집단계는 “an iterative and agile process for exploring, combining, cleaning and transforming raw data into curated datasets for data integration, data science, data discovery and analytics/business intelligence (BI) use cases”.
이라고 하며, 특히, 준비 단계는 분석을 위한 데이터 준비를 위한 중간 단계임에도 불구하고 자원과 시간 측면에서 가장 비용이 많이 드는 단계라고 표현하고 있다.
즉, 데이터 준비는 데이터 오류가 다음 단계인 데이터 분석으로 전파되는 것을 방지하는 것이 중요하기 때문에 데이터 과학 워크플로우에서 중요한 활동이라고 할 수 있고, 그렇지 못하면 데이터에서 잘못된 통찰력이 도출될 수 있다고 이야기하고 있습니다.
데이터 엔지니어링 파이프라인에는 기계 학습 알고리즘을 위한 교육 및 테스트 데이터 세트를 제공하는 사용 가능한 데이터에 대한 일련의 작업이 포함하고 있습니다.
- Data Ingestion - Collecting data by using various frameworks and formats, such as Spark, HDFS, CSV, etc. This step might also include synthetic data generation or data enrichment.
- Exploration and Validation - Includes data profiling to obtain information about the content and structure of the data. The output of this step is a set of metadata, such as max, min, avg of values. Data validation operations are user-defined error detection functions, which scan the dataset in order to spot some errors.
- Data Wrangling (Cleaning) - The process of re-formatting particular attributes and correcting errors in data, such as missing values imputation.
- Data Labeling - The operation of the Data Engineering pipeline, where each data point is assigned to a specific category.
- Data Splitting - Splitting the data into training, validation, and test datasets to be used during the core machine learning stages to produce the ML model.
모델 엔지니어링
ML 워크플로의 핵심은 ML 모델을 얻기 위해 기계 학습 알고리즘을 작성하고 실행하는 단계입니다.
모델 엔지니어링 파이프라인에는 아래와 같은 단계로 이루어 집니다.
- Model Training - The process of applying the machine learning algorithm on training data to train an ML model. It also includes feature engineering and the hyperparameter tuning for the model training activity.
- Model Evaluation - Validating the trained model to ensure it meets original codified objectives before serving the ML model in production to the end-user.
- Model Testing - Performing the final “Model Acceptance Test” by using the hold backtest dataset.
- Model Packaging - The process of exporting the final ML model into a specific format (e.g. PMML, PFA, or ONNX), which describes the model, in order to be consumed by the business application.
모델 배포
기계 학습 모델을 교육한 후에는 모바일 또는 데스크톱 애플리케이션과 같은 비즈니스 애플리케이션에 배포해야 합니다. ML 모델은 예측을 생성하기 위해 다양한 데이터 포인트(특징 벡터)가 필요한데, 이를 ML 워크플로의 마지막 단계는 이전에 엔지니어링된 ML 모델을 기존 소프트웨어에 업데이트/ 통합을 하는 것을 목표로 하고 있습니다.
이 단계에는 다음 작업이 포함됩니다.
- Model Serving - The process of addressing the ML model artifact in a production environment.
- Model Performance Monitoring - The process of observing the ML model performance based on live and previously unseen data, such as prediction or recommendation. In particular, we are interested in ML-specific signals, such as prediction deviation from previous model performance. These signals might be used as triggers for model re-training.
- Model Performance Logging - Every inference request results in the log-record.
참고 : DATA MESH ARCHITECTURE
https://www.datamesh-architecture.com/
참고 문서
https://ml-ops.org/content/end-to-end-ml-workflow#data-engineering
