모~든것이 HTTP다.
HTML뿐 아니라 text, img, 영상, JSON, XML등 byte로 표현할수있는 모든 데이터의 전송이 가능하고
서버간 데이터를 주고받을때도 어지간하면 HTTP프로토콜을 이용한다
version
- v0.9 : GET메서드만 있었고 http Header가 없었다고 한다
- v1.0 : http Header가 추가되고 GET이외의 메서드가 추가됬다
- v1.1 : 가장 중요한버전. v1.1에서 http의 거의 모든기능이 확립되었고 그 이후 버전은 v1.1의 성능개선을 중점으로 다룬다고 한다.
그리고 각각의 버전이 기반으로하는 프로토콜이 다르다는데
HTTP 1.1 + HTTP 2 버전 -> TCP프로토콜 기반
HTTP3 버전 -> UDP프로토콜 기반
현재는 v1.1이 주류이니 v1.1을 자세히 봐야한다. 하지만 v2와 v3버전도 점점 증가하는 추세이다
(구글에 검색을할때 오는 데이터의 프로토콜을 보면 v2,v3버전이 상당히 많다)
중요한건 버전별로 뭐가 지원됬는지 여부보다 http도 버전이있고 역사가 있다는거다.
특징
- 클라이언트 - 서버 구조
- 무상태(StateLess)
- 비연걸성(ConnectionLess)
- 단순 + 확장의 용이 -> http가 표준이 된 이유일 것이다.
1. 클라이언트-서버 구조
말그대로다.
클라이언트(request) - 서버(response)가 완전히 구분되어 있다는거다.
이렇게 구분 되어 있다는것은 클라이언트 / 서버가 완전히 다른 역할을 하기때문에
확실한 분업에대한 효율성과 더불어 각각이 독립되어서 개선이 이루어질 수 있다는거다.
ex) 클라이언트는 UI/UX에 집중하면 되고 / 서버는 데이터관리 + reponse에만 집중하면 되는거
2. 무상태(stateless)
https://irostub.github.io/web/stateful-stateless/
stateful(상태유지) stateless(무상태)를 가장 잘 이해할수있는 포스팅인 것 같다.
해당 포스팅을 참조해서 글을 쓰자면.
무상태(Stateless)는 서버가 클라이언트의 상태를 보존하지 않는다.
만약 상태유지(Stateful)를 특징으로 갖는다면. 중간에 클라이언트(브라우저)의 요청이 많아지는 순간이오면. 서버는 이에 대응하기위해 조치를 취할텐데 이과정에서. 응답하는 서버가 바뀌어버린다면. 바뀐 서버는 클라이언트의 상태를 모르기때문에 제대로된 응답을 해주지 못할것이다.
즉 stateful은 응답하는 서버가 항상 같게 유지되어야 한다는것.
하지만 무상태(stateless)는 클라이언트의 요청이 급증해면 그에맞춰 단순히 서버를 증설하기만 하면된다.
증설과정에서 응답하는 서버가 바뀌어도 무상태기때문에 클라이언트가 어차피 과거의 상태까지 쭉 말해주니까 서버입장에서는 몰라도 상관이없는거다.
즉 응답하는 서버를 쉽게 바꿀수도 + 증가하는 클라이언트의 요청에 대응하기도 쉽다는 것.
이는 엄청나게 쉬운 확장성을 갖게해준다
하지만 한계도 있다
-
무상태다 보니 클라이언트가 과거의 상태를 다 말하기때문에 request(요청)시 보내는 data가 아무래도 상태유지보다는 많을 것 이다.
-
아무리 http가 무상태(stateless)프로토콜 이라도 상태유지가 필요한 순간이 있다.
예를들면 유저의 로그인상태를 유지시켜야하는 경우이다.
이러한 경우엔 일반적으로 클라이언트(브라우저)의 쿠키 / 서버의 세션 을 이용해서 상태유지를 시키지만. 기본적인 App설계는 최대한 무상태(stateless)를 지키려고 해야한다.
즉 어쩔 수 없는 경우에만 상태유지를 하고 아니라면 최대한 무상태를 지키려고 해야한다는 것
(상태유지는 최소한으로!)
3. 비연결성(Connectionless)
HTTP는 '연결'을 유지하지 않는 모델이다.
즉 클라이언트의 요청(request)에 따른 서버에 응답(response)이 이루어지면 서버는 해당 클라이언트와 연결을 끊는다. 그렇기때문에 서버의 자원도 효율적으로 사용할 수 있을것이다.
(연결이 유지되고 있다는 것은 서버의 자원을 잡아먹고있다는 소리니까)
응답(response)는 초단위 이하로 상~당히 빠른속도로 응답하고 바로 연결이 끊어지는데
실제 수천명이 서비스를 이용해서 요청(request)을 많이 보내도 서버가 요청에대해 동시처리를 하는 케이스는 매우매우 드물다고한다
(응답의 속도가 매우 빠르고 응답즉시 연결을 끊어버리니)
하지만 한계도 있다
HTTP v1.1이 현재 주류이고 해당 버전은 TCP프로토콜을 기반으로 한다.
즉 TCP프로토콜 기반이기 때문에 3-way-handshake를 거친다는 소린데
(간단하게 말해서 서로가 연결이 됬나 먼저 확인하는 과정을 거친다는 소리다)
서버가 응답(response)이후 연결을 끊으니 다음 요청이 오면 또 연결을 확인하는 과정을 거쳐야한다는 것이다. -> 그만큼 시간을 잡아먹는다는 소리다.
추가로 서버로부터 오는 응답(response)의 리소스는 HTML뿐 아니라 JavaScript파일, Css파일, img파일 등 온갖 종류의 리소스가 오는데. 이게 한 뭉탱이로 오는게 아니란것을 나는안다. html을 먼저주고 그후에 js파일,css파일 등이 올텐데
- html파일을 보내줬으니 서버는 연결을 끊을 것 이다.
- 그후 js파일 css파일을 요청시 또 3-way-handshake과정을 거치고 서버가 js파일 css파일을 보내주면 또 연결을 끊을 것 이다.
이게 반복될건데. 수많은 리소스가 올텐데. 너무 시간을 잡아먹을 것이다.
하지만 HTTP 지속연결 (persistent connections)로 문제를 해결했고,
HTTP v2 v3 버전에서는 더많은 최적화가 되었다고 한다.
(지속연결은 말그대로 서버가 응답을 보냈다고 연결을 끊는게아닌 서버입장에서 보내야하는 리소스들을 다 보낼때까지 클라이언트와 연결을 유지시키는 것이다.)
Http Message
클라이언트 - 서버간 데이터가 교환되는 방식
즉 이 Http message를 이용해 데이터를 주고받는다는데. 구조가 정해져있는 message다
구조는 아래와 같다.
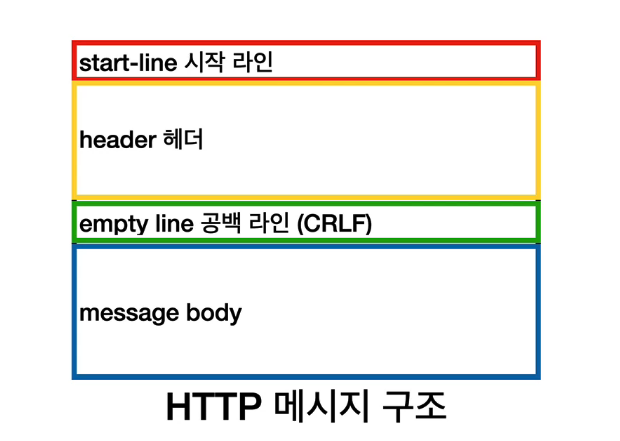
하나하나 뜯어보자면
1. start-line
말그대로 message의 시작 라인이며. 요청(request)/응답(response)의 시작라인은 각각 다르다. (request-line / status-line)
request-line
클라이언트가 요청(request)을 보낼때 http message의 시작라인(start-line) 구성은 아래와 같다.
- Method SP(공백) request-target(요청대상) SP HTTP-version CRLF(엔터공백)
- ex -> GET /search?q=hello&hl=ko HTTP/1.1
Http메서드 + 요청대상 + Http버전의 조합이다. 요청대상은 절대경로('/'로 시작)이지만 예외가 존재한다. 공백의 위치가 정해져 있다는 것은 정해진 위치가 아닌곳에서 공백을 쓰면 안되는 것을 의미한다.
status-line
서버가 응답(resopnse)을 보낼때 http message의 시작라인(start-line) 구성은 아래와 같다
- HTTP-version SP(공백) status-code SP(공백) reason-phrase CRLF(엔터공백)
- ex -> HTTP/1.1 204 No Content
Http버전 + 상태코드 + 이유문구(reason-phrase)의 조합이다. 이유문구는 상태코드를 짧게 설명하는 텍스트라고 보면 된다.
2. header 헤더
http로 전송을 할때 필요한 모든 부가정보가 들어있다.
예를들면 message body의 크기, 브라우저 정보, 인증 등
서버입장에서 header에는 서버의 정보, 캐시관리 정보 등 전송에 필요한 부가정보가 들어있는거다.
필요시 임의의 헤더(header)를 추가할 수 있다 하지만 약속된 서버와의 통신에서만 쓸 수 있을 것이다.
구성은 아래와 같다.
- Field-name":" OWS Field-value OWS(띄워쓰기 허용)
Field-name은 대소문자 구분은 안하지만 공백은 써야하는 곳에만 허용된 것을 볼 수 있다.
아래 사진은 start-line에 뒤이어 나오는 header의 모습
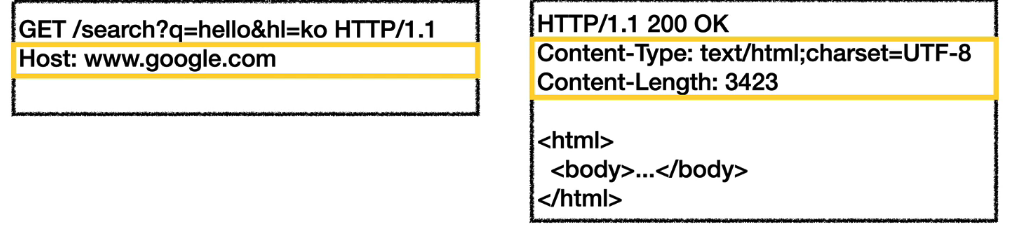
공백라인(CRLF)은 말그대로 공백라인 이니까 제외하고. 바로 message body를 보자
3. message body
실제 전송할 데이터가 담김
HTML문서, 이미지, 영상 등 byte로 표현할 수 있는 모~든 데이터의 전송이 가능하다.
헤더 + 바디부분은 내용이 매우 적지만 추후 학습하게되면 적도록 하겠다.