WaveShare사의 저가 카메라 IMX219-83 stereo 카메라 모듈을 이용하여 고가 카메라의 기능 중 depth estimation 기능을 구현하려 했다. 비록 성공적이진 못했지만, 이곳에서 제공하는 코드를 분석해보고, 차후에 더 개발해보자.
1. stereo camera depth estimation
스테레오 카메라가 depth를 추정하는 과정은 아래와 같다. 스테레오 카메라의 양안 모두 pinhole 모델이라 가정하고 풀어보자.
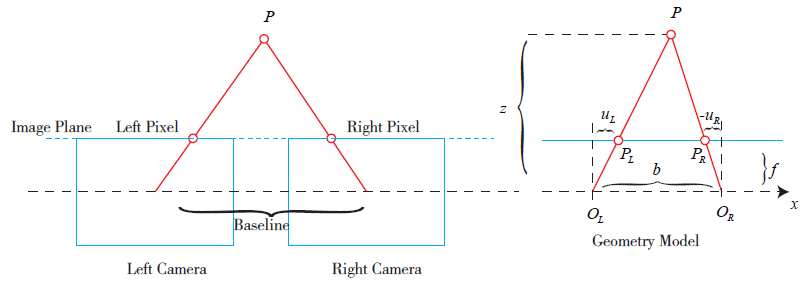
간단한 삼각측량법이다. 먼저 두 카메라 렌즈로 부터 이미지를 받아들이고 3D point P 가 양 렌즈에 PL과 PR로 projected 될 것이고, 우리는 삼각형의 닮음을 이용하여 다음과 같은 식을 얻어낼 수 있다. 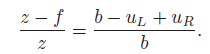
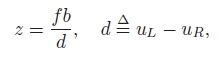
위 식을 통해 얻어낸 것은 z 값이라는 것. 그런데 d는 무엇일까? disparity라고 하며, 같은 점을 두 카메라가 바라보았을 때 생기는 x pixel값 차이이다. 만약에 카메라가 left right로 정렬된 것이 아니라 수직상태로 정렬되었다면, y pixel 값 차이로 동일한 모델을 만들어 쓰면 되겠다.
어찌되었든 우리는 z값을 얻을 수 있고, 카메라로부터 얼마나 떨어져 있는지 계산할 수 있게 된다. 하지만 위와 같은 PL, PR을 우리는 얻을 수 있는가라고 묻는다면 답은 '네니오' 라고 생각한다. 이 매칭과정이 정말 어려워서 계속해서 딥러닝이나 다른 논문이 나오는 수준이다.
가장 먼저해야하는 것은 두 이미지의 epipolar plane을 맞추는 것이다. 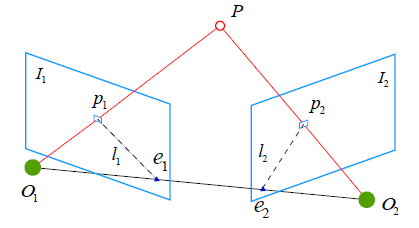 우리가 갖는 두 이미지의 매칭이 되는 epipolar plane을 맞춘다는 것은, 같은 feature를 같은 높이에서 바라본다는 의미이고, 이를 해야지만 위와 같은 계산을 할 수 있다(꼭 필요하냐고 물어본다면 크게 차이가 나지 않는다면, depth map을 만들때만 사용하지, feature를 이용한 depth estimation에서는 그렇게 차이가 나지 않는다. 하지만 우리는 depth map을 만든다는 가정하에 얘기하는 것). 이 과정을 stereo rectification이라고 하고, 이미지상에는 다음과 같은 선으로 표현할 수 있다.
우리가 갖는 두 이미지의 매칭이 되는 epipolar plane을 맞춘다는 것은, 같은 feature를 같은 높이에서 바라본다는 의미이고, 이를 해야지만 위와 같은 계산을 할 수 있다(꼭 필요하냐고 물어본다면 크게 차이가 나지 않는다면, depth map을 만들때만 사용하지, feature를 이용한 depth estimation에서는 그렇게 차이가 나지 않는다. 하지만 우리는 depth map을 만든다는 가정하에 얘기하는 것). 이 과정을 stereo rectification이라고 하고, 이미지상에는 다음과 같은 선으로 표현할 수 있다.  어떤 느낌인지 감이 오는가? 단순하게 같은 특징을 갖는 라인을 같은 높이에 맞춰놓는다라고 생각하면 편하다.
어떤 느낌인지 감이 오는가? 단순하게 같은 특징을 갖는 라인을 같은 높이에 맞춰놓는다라고 생각하면 편하다.
그렇다면 순서대로 생각해보자.
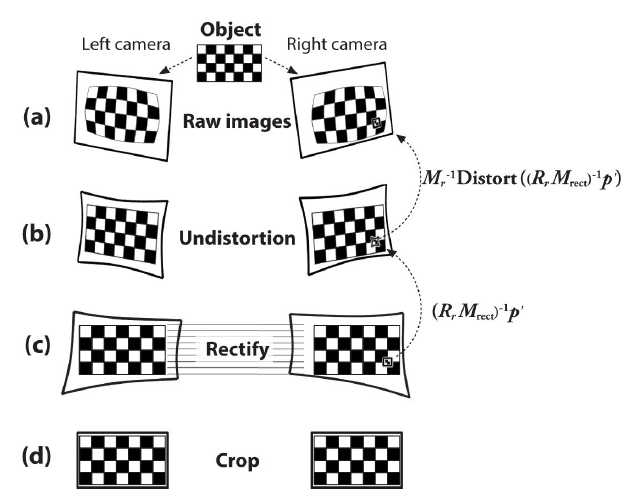
1. 각 카메라를 calibration 하여 intrinsic, extrinsic matrix를 구한다.
2. rectification 과정을 통해 두 이미지의 epipolar line을 같은 높이선상에 둔다.
3. matching 과정을 통해 disparity를 구한다.
4. 계산을 통해 depth map을 구한다.
이렇게 한다면 depth estimation은 끝이다. 그렇다면 실제 calibration 과정과 필요한 opencv 함수에 대해 알아보자.
2. Calibration
calibration은 총 세가지를 분석 했다. WaveShare, ROS, LearnOpenCV
핵심이 되는 곳만 짚어보자. 다운로드나 사용 링크는 아래에 남겨두겠다.
2-1. WaveShare
cameraMatrix[0] = initCameraMatrix2D(objectPoints,imagePoints[0],imageSize,0);
cameraMatrix[1] = initCameraMatrix2D(objectPoints,imagePoints[1],imageSize,0);
Mat R, T, E, F;
double rms = stereoCalibrate(objectPoints, imagePoints[0], imagePoints[1],
cameraMatrix[0], distCoeffs[0],
cameraMatrix[1], distCoeffs[1],
imageSize, R, T, E, F,
CALIB_FIX_INTRINSIC,
TermCriteria(TermCriteria::COUNT+TermCriteria::EPS, 100, 1e-5) );
Mat R1, R2, P1, P2, Q;
Rect validRoi[2];
stereoRectify(cameraMatrix[0], distCoeffs[0],
cameraMatrix[1], distCoeffs[1],
imageSize, R, T, R1, R2, P1, P2, Q,
CALIB_ZERO_DISPARITY, 1, imageSize, &validRoi[0], &validRoi[1]);
// Precompute maps for cv::remap()
initUndistortRectifyMap(cameraMatrix[0], distCoeffs[0], R1, P1, imageSize, CV_16SC2, rmap[0][0], rmap[0][1]);
initUndistortRectifyMap(cameraMatrix[1], distCoeffs[1], R2, P2, imageSize, CV_16SC2, rmap[1][0], rmap[1][1]);
remap(src, dst, rmap[0][0], rmap[0][1], INTER_LINEAR);
remap(src, dst, rmap[1][0], rmap[1][1], INTER_LINEAR);calibration 과정 중 매번 나오는 것인 체스보드 calibration 과정을 기억할 것이다. 위 과정은 이미 체스보드의 교차점들을 objectPoints, imagePoints[2]에 포함되어 있다.
-
initCameraMatrix2D를 통해 우리는 intrinsic matrix를 얻을 수 있다.
-
stereoCalibrate을 통해 Rotation matrix, Translation vector, Essential Matrix, Fundamental Matrix를 구한다. 여기서 구하는 R, T는 왼쪽 카메라를 기준으로 볼때, 오른쪽 카메라의 rotation과 translation을 의미한다. 만일 본인이 반대 방향으로 했다면 반대방향으로 생각할 것.
-
stereoRectify을 통해 이미지를 정렬한다. 이때, R1, R2, P1, P2, Q, validRoi[2]가 존재하는데,
- R1: 1번 카메라를 위한 rectification matrix(rotation matrix 3x3) 이다.
- P1: 1번 카메라를 위한 Translation matrix
- Q: 4x4의 disparity to depth mapping matrix이다. 이를 이용하여 point cloud를 만들 수 있다. 자세히는 reprojectTo3D 함수를 보자.
- validRoi: 사용 가능한 rectification 이미지 부분이다. alpha값에 의해 달라진다(1)
 validRoi란 위와 같이 초록색 부위를 의미한다.
validRoi란 위와 같이 초록색 부위를 의미한다.
그런데, 위에서 보통 1(왼쪽)을 기준으로 생각하기 때문에 P1, P2 쌍은 다음과 같이 생기는게 보통이다. 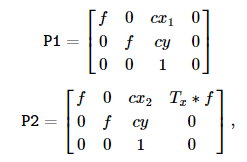 우리는 rectification 과정을 통해 cy1, cy2 값을 갖게 한것을 잊지 말자.
우리는 rectification 과정을 통해 cy1, cy2 값을 갖게 한것을 잊지 말자.
-
initUndistortRectifyMap 함수를 통해 remap에서 사용할 undistortion하고 rectification transform할 수 있는 matrix를 얻자. 두가지 rmap을 요구하는데, 각각 x, y축에 관한 내용이다.
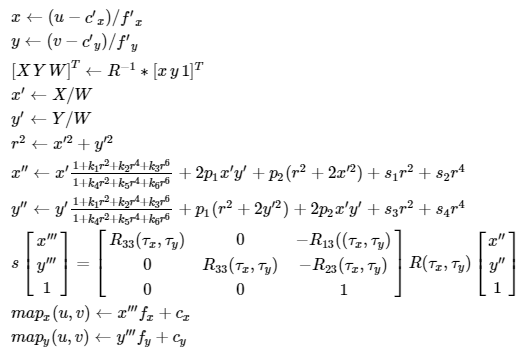
-
마지막으로 remap함수를 통해 원하는 이미지를 만들자.
2-2. LearnOpenCV
cv::Mat mtxL,distL,R_L,T_L;
cv::Mat mtxR,distR,R_R,T_R;
cv::Mat new_mtxL, new_mtxR;
// Calibrating left camera
cv::calibrateCamera(objpoints,
imgpointsL,
grayL.size(),
mtxL,
distL,
R_L,
T_L);
new_mtxL = cv::getOptimalNewCameraMatrix(mtxL,
distL,
grayL.size(),
1,
grayL.size(),
0);
// Calibrating right camera
cv::calibrateCamera(objpoints,
imgpointsR,
grayR.size(),
mtxR,
distR,
R_R,
T_R);
new_mtxR = cv::getOptimalNewCameraMatrix(mtxR,
distR,
grayR.size(),
1,
grayR.size(),
0);LearnOpenCV에서는 다른 방식으로 intrinsic matrix를 구했다. 이외에는 동일한 방식으로 진행한다.
2-3. ROS1
위의 코드를 본인이 이해하고 싶지 않다거나, 보고 싶지 않고 단순히 구현된 것으로 intrinsic matrix, extrinsic matrix, rotation, translation, essential, fundamental 을 구하고 싶다면 ROS의 구현되어 있는 UI를 이용하면 좋겠다. 방법은 간단하다. 아래의 shell을 따라가자.
# http://wiki.ros.org/camera_calibration/Tutorials/StereoCalibration
# 의존성 확인
rosdep install camera_calibration
rosmake camera_calibration
# 카메라 켈리브레이션 approximate 옵션은 카메라 timestamp delay를 0.1초 정도 허용해준다. 아래에서 자신의 topic에 맞는 이름을 넣어주자.
rosrun camera_calibration cameracalibrator.py --approximate 0.1 --size 8x6 --square 0.108 right:=/my_stereo/right/image_raw left:=/my_stereo/left/image_raw right_camera:=/my_stereo/right left_camera:=/my_stereo/left이후에는 약 40장 정도의 사진을 찍게 되겠다. 그 후 calibrate를 한 뒤 save해주면 되겠다.

3. get depth map
위에서까지는 rectification이 된 map을 얻었다면, 이제는 disparity를 구해야 한다. disparity를 구하려면 두 이미지에서 동일한 점을 계산할 수 있어야 하는데, 이에 대해서 정말 다양한 방법이 있다. StereoBM, StereoSGBM, 딥러닝 등등이 있는데, 간단하게 opencv에서 제공하는 StereoSGBM 사용법만 파악하고 넘어가자.
Ptr<StereoSGBM> sgbm = StereoSGBM::create(0,64,11);
/*
parameter setting
*/
Mat disp(left.size(), CV_16S), depth;
sgbm->compute(left, right, disp);위에서 파라미터 세팅이 있는데 잠시만 넘어가고, 어쨋든 sgbm->compute를 하면 disparity를 계산해준다는 것이다. 하지만 그냥 넘어 갈 수 없는 것이 있다. 현재 만들어진 disparity의 데이터 형이 CV_16S라 imshow()를 해서 보일 수 없다는 것이다.
잘 생각해보면 disparity를 이용해서 depth를 구하는데, depth에 음수가 있을 수 있나?(disparity는 음수가 있을 수 있다) 또한 OpenCV에서 표현할 수 있는 depth의 한계는 CV_16U(cm)이다. 약 65m가 한계라는 뜻이다. 어쨋든 우리는 disparity를 한번 normalizing한 뒤 depth를 표현할 필요가 있다는 것이다.
normalizing 하는 방식에서 WaveShare사와 LearnOpenCV의 차이가 있다.
아래는 waveshare사이다.
double minVal; double maxVal;
minMaxLoc( disp, &minVal, &maxVal );
add(disp, -minVal, disp);
divide(disp, 16, disp);
disp.convertTo( disp, CV_8UC1); signed 16bit integer 인것을 알고, minMaxLoc을 통해 disp의 최소값, 최대값을 구한 뒤, add를 통해 disp의 최소값을 0으로 맞춰놓았다. 그 후 16으로 나눈다. 그 후에 8UC1로 바꾸는다.
다음은 LearnOpenCV이다.
disp.convertTo(disparity,CV_32F, 1.0);
disparity = (disparity/(float)16.0 - (float)minDisparity)/((float)numDisparities);여기서 numDisparities는 다음과 같다.
numDisparities – Maximum disparity minus minimum disparity. This parameter must be divisible by 16.
16배수의 수이며, max disparity - minimum 값이라고 한다. 고로 normalizing 할 수 있는 값이다. 하지만 OpenCV에서는 다음과 같은 함수를 제공한다.
void cv::normalize(InputArray src,
InputOutputArray dst,
double alpha = 1,
double beta = 0,
int norm_type = NORM_L2,
int dtype = -1,
InputArray mask = noArray()
)
// 다음과 같은 normalize가 가능하다.
normalize(disp, disp8, 0, 255, CV_MINMAX, CV_8U);위 같은 경우는 그냥 imshow() 하기 위한 것일까? 개인적으로는 disp8이 아닌, disp16으로 하고 CV_16U를 사용하여 65m 거리를 표현하는 것이 더 좋아보인다. 이 함수에 대해서는 더 알아볼 필요가 있지만, 단순히 imshow()를 하기 위해서는 인터넷에서 자주 사용하는 것으로 보인다.
WaveShare사의 normalizing 방식은 개인적으로 정석적이라 생각한다. 16s데이터 형식을 32f로 바꾸어주며 normalizing 해주는 것. 그 후 depth를 계산한 뒤 ushort형식(unsigned 16bit int)로 바꾸어 depth를 표현해 주는 것. 그리고 그 이미지를 imshow 해주는 것. imshow는 ushort를 표현해 줄 수 있다고 한다. 물론 내용을 바꾸어 표현하지만, 실제 값을 바꾸는 것은 아니니 상관없다고 생각한다.
LearnOpenCV 방식은 imshow를 고려하지 않았다고 생각한다. 하지만 depth를 구하기에는 무리가 없다.
두 식들로 depth를 구해보자.
z = fb/d 임을 기억하는가? 각각의 disparity를 fb에 나누고, 그 값을 넣어준 matrix를 만들면 되겠다.
다음은 WaveShare사의 코드이다.
void disp2Depth(cv::Mat dispMap, cv::Mat &depthMap, double Disp2Depth)
{
int type = dispMap.type();
if (type == CV_8U)
{
int height = dispMap.rows;
int width = dispMap.cols;
uchar* dispData = (uchar*)dispMap.data;
ushort* depthData = (ushort*)depthMap.data;
for (int i = 0; i < height; i++)
{
for (int j = 0; j < width; j++)
{
int id = i*width + j;
if (!dispData[id]) {
depthData[id] = 65535;
continue;
}
depthData[id] = ushort( (float)Disp2Depth/ ((float)dispData[id]) );
}
}
}
else
{
cout << "please confirm dispImg's type!" << endl;
cv::waitKey(0);
}
}여기서 Disp2Depth값은 fb인데, 이를 다음과 같이 표현했다.
Disp2Depth = Q.at<double>(2, 3) * -T.at<double>(0, 0);Q는 아래와 같다. T는 translation vector인데, 1->2 값이니까 baseline이다. 하지만 방향이 반대이므로 -값을 취한것으로 보인다. 개인적인 생각으론 그냥 parameter로 만들어서 계산하는게 맞다고 본다. 굳이 복잡한 방식의 표현보다는.

어찌 되었든 값은 fb라는 것이다. 고로 depth 값은 맞다.
4. stereo matching parameter
OpenCV의 StereoMatching 모듈은 정말 작성은 쉽지만, 원하는 깔끔한 맵을 보기에는 세밀한 파라미터 튜닝이 필요한 듯 하다. 필자도 적당한 param 선정방식을 아직 정하지 못했다. 하지만 각각의 파라미터에 대한 이해는 필요하다. 그러므로 아래의 글을 보자.
numberOfDisparities = numberOfDisparities > 0 ? numberOfDisparities : ((img_size.width/8) + 15) & -16;
sgbm->setPreFilterCap(63);
int sgbmWinSize = SADWindowSize > 0 ? SADWindowSize : 3;
sgbm->setBlockSize(sgbmWinSize);
int cn = img1.channels();
sgbm->setP1(8*cn*sgbmWinSize*sgbmWinSize);
sgbm->setP2(32*cn*sgbmWinSize*sgbmWinSize);
sgbm->setMinDisparity(0);
sgbm->setNumDisparities(numberOfDisparities);
sgbm->setUniquenessRatio(10);
sgbm->setSpeckleWindowSize(100);
sgbm->setSpeckleRange(32);
sgbm->setDisp12MaxDiff(1);
sgbm->setMode(StereoSGBM::MODE_SGBM);- minDisparity - possible disparity 최소값. 보통은 0인데, rectification 알고리즘이 이미지를 이동시켜서 제대로 선정해야함.
- numDisparities - Max - min disparity. 16으로 나뉘어져야함.
- blockSize - Matched block size. 1이상의 홀수여야함. 보통 3~11사이에서 선정됨.
- P1 - The first parameter controlling the disparity smoothness.
- P2 - 동일한 기능. 그 값이 클 수록 disparity가 부드럽다. 항상 P2>P1이여야 한다. 좋은 P1, P2는 다음과 같이 선정된다. 8number_of_image_channelsblockSizeblockSize and 32number_of_image_channelsblockSizeblockSize
- disp12MaxDiff - Maximum allowed difference (in integer pixel units) in the left-right disparity check. 음수로 체크하면 이 기능을 사용하지 않는다. 이유는 모르겠지만 대부분 +1로 선정한다.
- preFilterCap - Truncation value for the prefiltered image pixels, 필터링된 이미지를 자르는 값 크기.
- uniquenessRatio - 보통 5~15사이로 선정된다.
- SpeckleWindowSize - 보통 50~200 사이로 선정된다.
- SpeckleRange - 16으로 곱해져야하며, 보통 1,2 가 선정된다.
- Mode - StereoSGBM::MODE_HH로 하면 run the full-scale two-pass dynamic programming algorithm 된다.
speckle - 작은 반점.
 windowsize에 대한 영상 이미지이다. 보고 참고하면 좋을 듯 하다.
windowsize에 대한 영상 이미지이다. 보고 참고하면 좋을 듯 하다.
Learning OpenCV 3에서 파라미터 세팅에대한 자세한 얘기가 나와있다. 만약 본인이 흥미가 있다면 "Stereo Correspondence" 부분을 찾아서 읽어보자. page는 pdf 파일 기준 737~759(19장)이다.
5. Easy Start With ROS
위의 일련의 과정들이 어느정도 이해가 되었다고 하자. 하지만 이를 직접 작성하는 것은 무척 힘든 일이다. 물론 관련하여 참고 링크를 올려놓았지만 만약 본인은 이러한 과정보다는 그냥 결과만 바란다면 ROS에서 제공하는 패키지들을 이용하면 편하겠다. 물론 ROS 사용자들에게만 편하다...
https://answers.ros.org/question/317961/rtabmap-how-to-view-or-export-the-disparity-images-from-stereo-sgm/
정말 답변이 잘 나와있는 링크이다. sgbm말고 bm방식으로도 사용할 수 있다.
일단 위 링크에서 calibration을 하려면, rosbagfile 사용하는 것이 좋다. 그러한 파일이 있다면 다음과 같은 방식으로 시작하면 되겠다.
ROS_NAMESPACE=narrow_stereo_textured rosrun stereo_image_proc stereo_image_proc
rosrun rqt_reconfigure rqt_reconfigurecalibration은 위같은 방식으로 하고, 아래의 링크로 원하는 pcl을 얻도록 하자! 정말 잘 정리된 깃헙이며, IMX219-83 ros라고 검색하면 바로 나오는 github이다!
https://github.com/borongyuan/jetson_csi_stereo_ros 추가로 이 링크에서 jetson nano에 ROS1을 OpenCV4.1.1 로 사용할 수 있는 Vision Pkg도 있으니 어렵게 melodic 버전 맞춘다고 downgrade하지 말고 저걸 사용해보자!
[ref]
- stereorectify 함수: https://docs.opencv.org/3.4/d9/d0c/group__calib3d.html#ga617b1685d4059c6040827800e72ad2b6
- WaveShare사 코드: https://www.waveshare.com/wiki/IMX219-83_Stereo_Camera
- LearnOpenCV 깃헙 링크: https://github.com/spmallick/learnopencv/blob/master/stereo-camera/calibrate.cpp
- LearnOpenCV Stereo Camera Calibration 방법: https://learnopencv.com/making-a-low-cost-stereo-camera-using-opencv/
- Stereo Calibration with ROS1: http://wiki.ros.org/camera_calibration/Tutorials/StereoCalibration
- https://docs.opencv.org/3.4/d1/d1b/group__core__hal__interface.html#ga4a3def5d72b74bed31f5f8ab7676099c
- StereoSGBM 파라미터 세팅: https://docs.opencv.org/4.x/d2/d85/classcv_1_1StereoSGBM.html
- Stereo Basic: https://www.youtube.com/watch?v=hUVyDabn1Mg
- stereo camera parameter setting with ROS: https://answers.ros.org/question/317961/rtabmap-how-to-view-or-export-the-disparity-images-from-stereo-sgm/
- stereo camera parameter setting with ROS: http://wiki.ros.org/stereo_image_proc/
- IMX219-83 ROS: https://github.com/borongyuan/jetson_csi_stereo_ros
