https://arxiv.org/abs/1910.06711
K. kumar et al., "MelGAN: Generative Adversarial Networks for Conditional Waveform Synthesis," NIPS, 2019.
- High quality coherent waveform을 생성하는 GAN 제안
- MOS를 통해 고품질 mel-spectrogram inversion에 대해 제안된 접근 방식의 효율성 제시
- 더 적은 파라미터로 성능 개선
Goal
- Proposal of a GAN-based model to generate high quality coherent waveform
Contribution
- Proposing a non-autoregressive feed forward convolution architecture for generating audio waveform in GAN structure
- Proposing a model that is faster than other mel-spectrogram inversion method without considerable degradation in audio quality
- Successful learning of GAN to generate raw audio without additional distillation or perceptual loss functions
Model
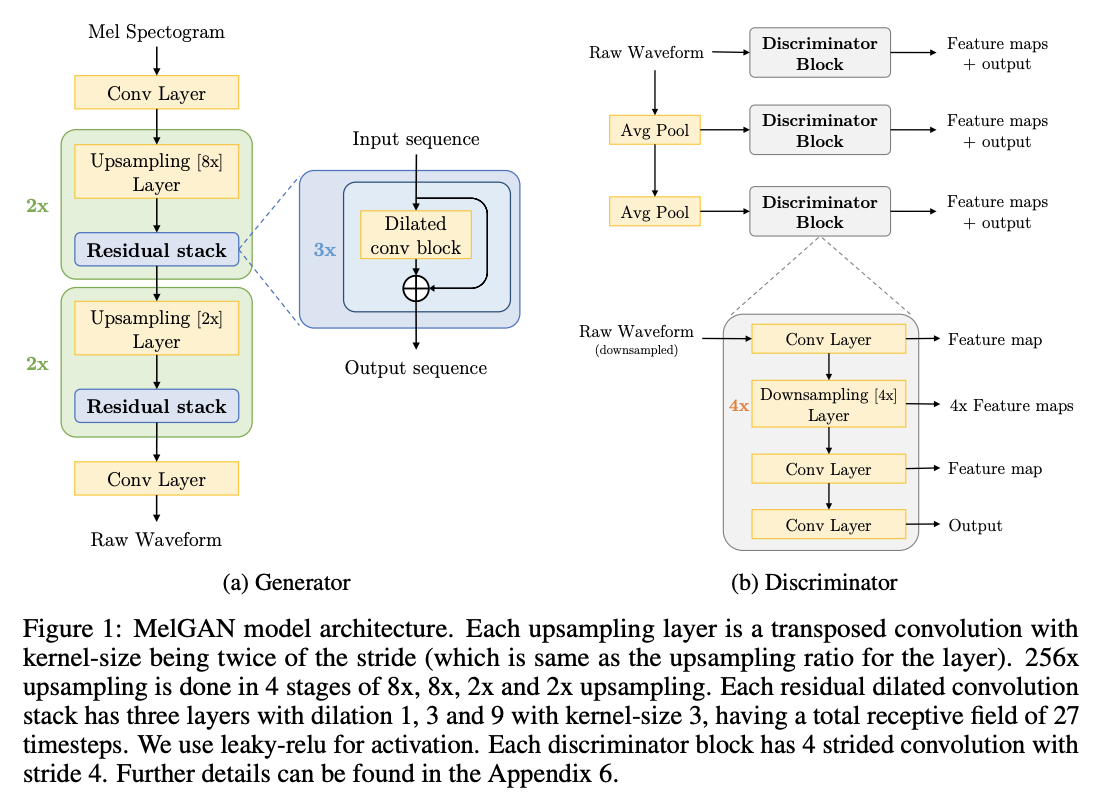
Generator
Architecture
- Input: mel-spectrogram, Output: raw waveform
- Not using a global noise vector as input
Induced receptive field
- Putting an inductive bias that there is long range
- correlation among the audio timesteps
Checkerboard artifacts
- Using kernel-size as a multiple of stride
Normalization technique
- Weight normalization
Discriminator
Multi-scale architecture
- Using 3 discriminators that have identical network
- Operating on different audio scales
Window-based objective
Training Objectives
Hinge loss version of the GAN [J. Lim et al., 2017]
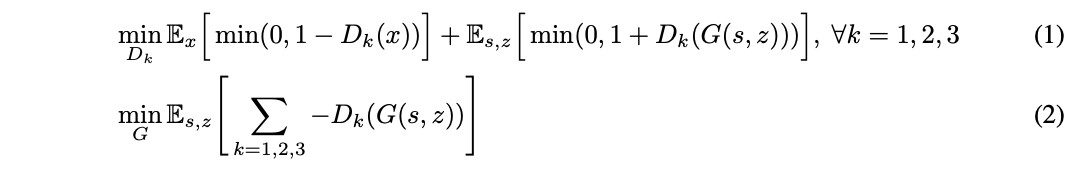
Feature matching
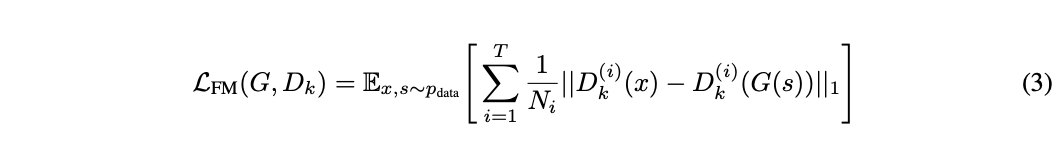

- 𝑳1 distance between the discriminator feature maps of real and synthetic audio
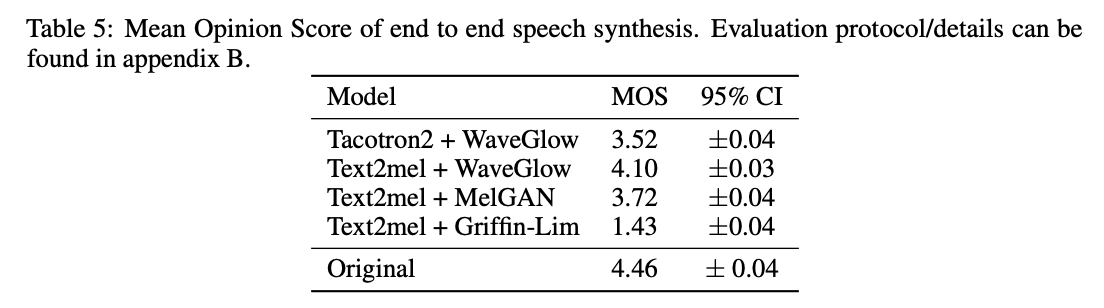
Results
- Fewer parameters, fast inference speed
- Improved generated audio quality



𝑯𝒐𝒏𝒆𝒔𝒕𝒚 𝑰𝒏𝒕𝒆𝒈𝒓𝒊𝒕𝒚 𝑬𝒙𝒄𝒆𝒍𝒍𝒆𝒏𝒄𝒆