https://arxiv.org/abs/2010.05646
J. Kong et al., “HiFi-GAN: Generative Adversarial Networks for Efficient and High Fidelity Speech Synthesis,” NIPS, 2020.
카카오에서 투고한 논문!
Goal
- Proposal of a GAN-based model to efficiently generate high-fidelity speech
Contribution
- Higher computational efficiency and improved sample quality than AR or flow-based models
- Proposing a discriminator which consists of small sub-discriminators, each of which obtains only a specific periodic parts of raw waveforms
Method
Generator
- Fully convolutional neural network
- Multi-Receptive Filed Fusion (MRF)
- Observing patterns of various lengths in parallel
- Output: sum of outputs of multiple residual blocks
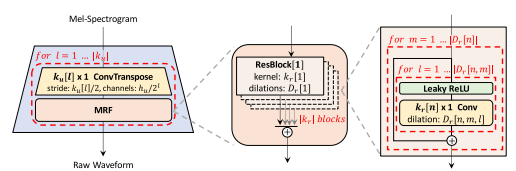
Figure 1: The generator upsamples mel-spectrograms up to |ku| times to match the temporal resolution of raw waveforms. A MRF module adds features from |kr| residual blocks of different kernel sizes and dilation rates. Lastly, the n-th residual block with kernel size kr[n] and dilation rates Dr[n] in a MRF module is depicted.
Discriminator
- Speech audio consists of sinusoidal signals with various periods
- The importance of knowing the patterns of various periods that underlie speech data
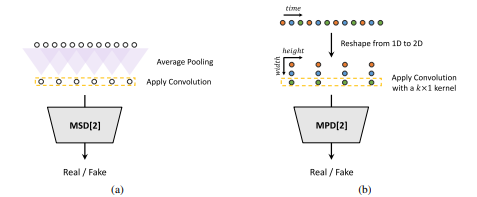
Figure 2: (a) The second sub-discriminator of MSD. (b) The second sub-discriminator of MPD with
period 3.
Multi-Period Discriminator (MPD)
- Mixture of sub-discriminators
- Accepting only equally spaced input audio samples
- Designed to capture different implicit structures by looking at different parts of the input audio
Multi-Scale Discriminator (MSD)
- MPD's sub-discriminators using only decomposed samples
- Addition of MSD to evaluate continuous speech
= Consists of 3 sub-discriminators operating on different input scales
Training Loss
GAN loss
- Convert the binary cross-entropy part of GAN to least square loss function for non-vanishing gradient flow [X. mao et al., 2017]
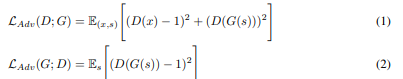
Mel-spectrogram loss
- To increase the efficiency and improve the quality of the generated speech
- L1 distance between the mel-spectrogram of a waveform synthesized by the generator and that of a ground truth waveform
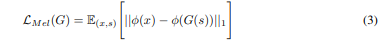
Feature Matching loss
- L1 distance between a ground truth sample and a conditionally generated sample
- A learned similarity metric measured as the difference in discriminator features between the ground truth and generated samples
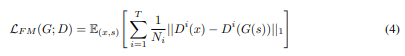
Final loss
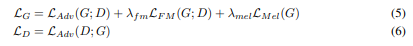
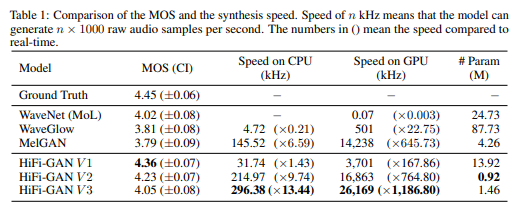
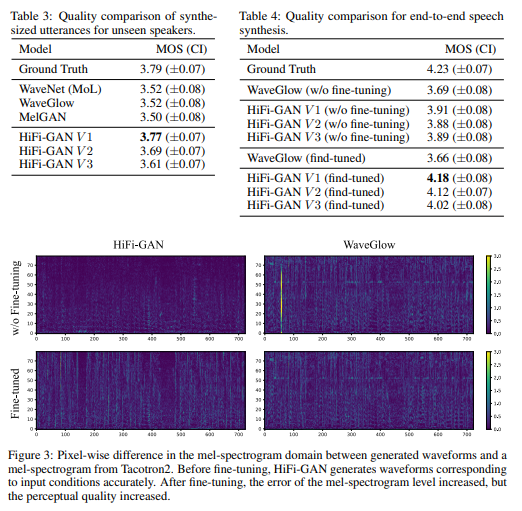
Experimental Results
- Improved audio quality and synthesis speed
- Outperforms the best publicly available performance models in terms of synthetic quality

𝑯𝒐𝒏𝒆𝒔𝒕𝒚 𝑰𝒏𝒕𝒆𝒈𝒓𝒊𝒕𝒚 𝑬𝒙𝒄𝒆𝒍𝒍𝒆𝒏𝒄𝒆