Negative Can Be Positive: Signed Graph Neural Networks for Recommendation

한줄요약
"negative can be positive"
이 논문은 SiReN: Sign-Aware Recommendation Using Graph Neural Networks 의 선행연구를 기반으로 두고 있다. 선행연구 논문을 리뷰해놨으니 먼저 이거부터 보고 오면 좋을 것 같다.
(https://velog.io/@chwchong/SiReN-Sign-Aware-Recommendation-Using-Graph-Neural-Networks)
ABSTRACT
negative feedback에 대한 연구는 상당히 어려운 일이다. 여기서는 negative feedback에 대한 분석하여 이것의 역할을 조사했더니 예상과는 다른 결과를 발견했다. negative feedback의 순위가 낮게 매겨진게 아니고 심지어 일부는 높은 순위에 rank 되어있다. 이 논문은 SiGRec (Signed Graph Neural Network Recommendation model) 이라는 모델을 소개한다. positive feedback과 negative feedback을 모두 활용하는 모델이고, 새로운 loss funtion인 SiC (Sign Cosine) loss도 함께 소개한다. SiGRec은 기존의 모델은 능가하는 성능을 보여준다.
1. Introduction
negative feedback을 modeling 하는 것은 성능을 크게 올리는 것으로 여겨지지만 negative feedback을 다루는 방법은 많은 도전에 직면해있다. 이 논문에서는 negative feedback의 역할을 조사했는데 negative item ranking과 model training에서 긍정적일 수 있다는 것을 발견했다.
• negative feedback의 역할을 질적, 양적으로 조사했다.
• 위의 발견을 바탕으로 SiGRec을 소개한다.
• negative feedback이 있는 네 개의 실제 데이터 세트에 대한 추천 실험을 수행했다.
2. Preliminaries and research objective
Definition 1: Bipartite Graph in Recommendation
bipartite graph를 G = (U,I,E)로 정의한다. U는 user set, I는 item set, E는 set of weighted edges between U and I 이다. G는 adjacency matrix A로 표현될 수 있다. 여기서 A의 크기는 (U+I) x (U+I) 이다.
Remark 1: edges에 weighted가 있지만 기존 연구들은 edges를 binarize 한다 (여기서 positive feedback은 1로, negaitve feedback은 0으로, unknown도 0으로 나타낸다).
Remark 2: GNN-based CF methods는 아래 식과 같은 message-passing scheme으로 user and node embeddings를 생성한다.
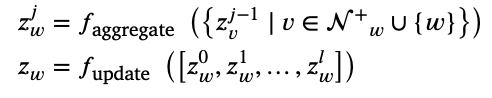
Definition 2: Negative Edge in Recommendation
edge가 threshold 𝜏 보다 낮으면 negative (-) 이고, 그게 아니면 postive (+) 이다.
Remark 3: threshold 𝜏 는 5-rating sacles 일 때 4.0 일 수 있고, 각 user 별의 평균으로 값을 잡을 수도 있다.
Definition 3: Signed Bipartite Graph in Recommendation
signed bipartite graph G는 아래와 같이 G+와 G-의 합집합으로 표현된다. G+는 positive bipartite graph이고, G-는 negative bipartite graph이다. E도 E+와 E-의 합집합으로 나타내지고, adjacency matrix도 A+와 A-로 나뉜다.
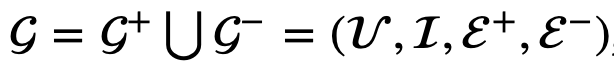
Research objective
1. to analyze the negative feedback in recommendations
2. to model negative bipartite graph G− with a new design of model and training loss
3. Analysis and motivation on negative feedback
다양한 종류의 negative feedback을 소개한다.
- low rate: Amazon-Book dataset과 Yelp dataset이 있다. explicit feedback이며 4.0 미만을 negative feedback으로 간주한다.
- skip content: Zhihu dataset이 있다. 답변을 건너뛰는 것과 같은 user의 행동을 negative feedback으로 본다.
- click dislike button: WeChat dataset이 있다. user는 dislike button을 클릭하여 negative feedback을 제출할 수 있다.
아래의 표를 보면 Negative ratio에서 Zhihu 같은 skip scenario는 interaction cost가 낮기 때문에 ratio가 높고, WeChat 같은 click dislike button scenario는 interaction cost가 높기 때문에 ratio가 낮다.
negative preference는 scenario별로 다를 수 있다. negative한 의견을 표출하는 과정에서 clike dislike button이 skip 보다 더 강하게 표출하는 방식일 수 있다.
negative feedback을 다루는 것은 쉬운 일이 아니다. 예를 들어서 공상과학 소설 팬인 user가 "To Hold Up the Sky" 라는 공상과학 소설에 negative feedback을 준 이유가 "The Three-Body Problem" 이라는 공상과학 소설보다 흥미롭지 않다는 것 때문이었다고 해보자. 그렇다고 해서 user가 공상과학 소설에 negative feedback을 주었으니 공상과학 소설을 싫어한다고 가정하는 것은 추천시스템에 성능을 해칠 수 있다는 것이다.
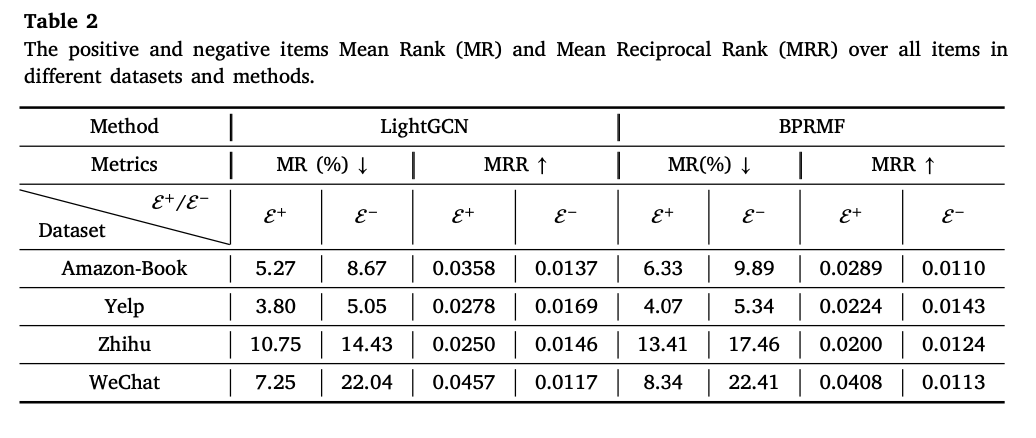
아래 그림은 MR과 MRR을 구하는 방법이고, 아래 표는 LightGCN과 BPRMF에서 그 결과를 보여준다. MR은 작을수록 (더 높은 rank에 위치함) 좋은 성능이고, MRR을 클수록 (더 높은 rank에 위치함) 더 좋은 성능이다. E+는 positive edges이고, E-는 negative edges이다. 표를 보면 positive의 순위가 negative보다 높다는 것을 알 수 있다. 하지만 일부 negative edges의 순위가 최상위에 매겨진다는 것을 볼 수 있다 (Yelp dataset에 대한 LightGCN 모델의 MR이 5.05%). 저자들은 이 이유를 negative feedback의 형성 메커니즘과 관련이 있다고 추측한다.

전통적으로 negative edges를 처리하는 2가지 방법이 있다.
1. Keeping only high-scoring interactions (a.k.a. only positive edges): negative edges를 지우고 (삭제하고) 사용하지 않는 방법이다.
2. Ignoring the sign of interactions (a.k.a. both positive and negative edges): 부호를 무시하는 방법이다. 자세히 말하면 positive edges와 negative edges를 구분하지 않고 그냥 하나의 edges으로 보는거다 (positive edges는 1, negative edges도 1, unknown edges는 0으로 두는거다. 이상하다고 생각할 수도 있지만 생각보다 효과는 좋다).
아래의 결과는 다음과 같은 실험을 통해 나온 결과이다. 일단 먼저 4가지 종류의 G에 대해 정의하고 실험을 시작한다.
G(0) --> negative edges는 삭제하고 positive edges만으로 훈련한다.
G(-1) -> positive edges는 삭제하고 negative edges만으로 훈련한다.
G(1) --> positive edges와 negative edges를 부호 구분 없이 동일하게 positive edges로 취급하여 훈련한다. (바로 위에 전통적으로 negative edges를 처리하는 방법 2와 동일하다).
G(2) --> negative edges와 동일한 수의 edges를 unobserved edges에서 random하게 뽑아서 G(1)에 추가한다 (noise를 주는 것이다). 결과적으로 G(1)의 대조군 역할을 하는 것이다.
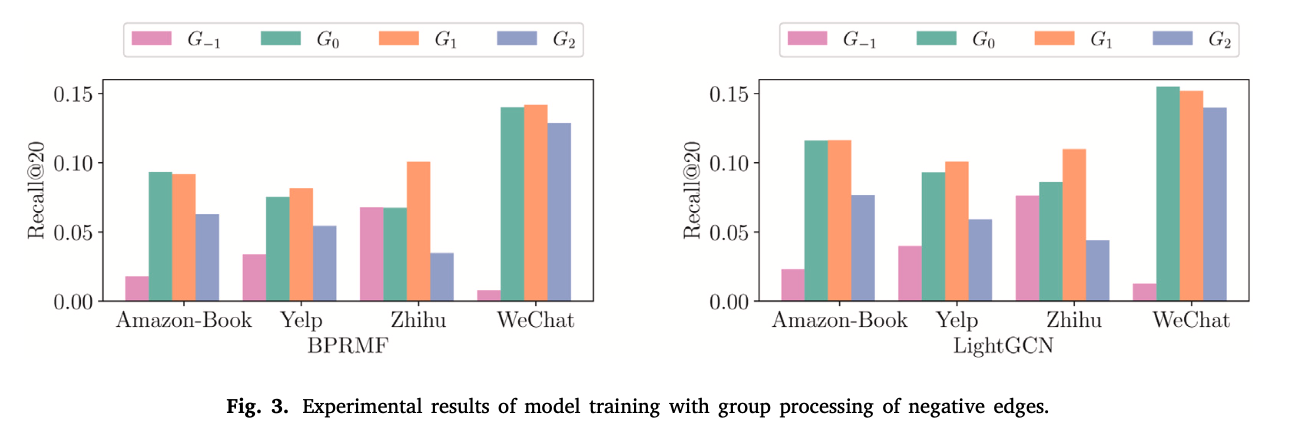
위의 실험 결과를 정리하자면
1. G(-1)의 성능이 가장 나쁘다. positive edges보다 negative edges가 적기 때문에 생기는 현상으로도 볼 수 있고, negative edges로 훈련해서 positive edges를 예측해야하기 때문에 성능이 나쁠 수밖에 없다.
2. G(2)는 noise 때문에 G(1)과 G(0)에 비해 성능이 떨어진다.
3. G(1)이 G(2)보다 좋은 성능을 보였기 때문에 negative edges를 positive edges로 취급하는 것은 모든 dataset에서 긍정적인 결과를 보여준다.
4. 몇몇 dataset에서 G(1)이 G(0)보다 성능이 좋다. 저자는 "negative edges can be positive in some datasets (Zhihu and Yelp)" 라고 언급한다. negative edges를 positive edges로 동일하게 취급하여 train에 활용했을 뿐인데 몇몇 dataset에서 positive edges만을 사용한 것보다 성능이 좋다는 것은 개인적으로 상당히 놀랍다고 볼 수 있다고 생각한다. 반면에 Amazon-Book과 WeChat에서는 G(1)이 G(0)보다 성능이 안 좋다. G(1)이 G(0)보다 성능이 좋을 때도 있지만 안 좋을 때도 있는데 negative edges를 G(1) 방식처럼 simply adding 하는게 아니라 negative edges를 다루는 더 나은 방법이 필요하다고 저자는 말한다.
개인적으로 이 논문을 reveiw 하고 있는 내가 봤을 때 위의 실험이 상당히 신선하다고 느낀다 (전체적으로 negative feedback을 활용하는 모델을 제시하기 전에 negative feedback에 대한 분석을 하고 들어가는 것이 상당히 좋았다). 나도 추천시스템의 negative feedback을 연구하면서 수많은 시행착오와 실패를 겪었다. 어떤 영화를 부정평가했다는 것은 일단 그 영화를 봤다는 것이고, 그 영화를 봤다는 것은 그 영화에 관심이 있었기 때문이라고 해석한다면 이것을 부정적으로 볼 수는 없는 것 아니냐는 내용의 이야기를 지도교수님과 나눴던 적이 있는데 그때는 단순한 가설일 뿐이었다. 그런데 이 논문에서 이것에 대한 갈증을 풀어주었다. 이 논문을 통해 내 연구의 상당한 진척을 이뤘다.
Discussion
위의 실험에서 negative feedback이 item ranking과 model training에 긍정적인 영향을 미친다는 것을 알 수 있다. 저자는 이 이유가 negative feedback의 형성 메커니즘에 있다고 주장한다.
low rate scenario의 경우, 비록 user가 low rating을 주었지만 애초에 흥미가 있어서 그 item을 interacted한거고 그 item에 대한 기대를 만족하지 못했기 때문이라고 볼 수도 있다.
skipping content scenario와 clicking dislike button scenario의 경우, user가 interacted한 item은 기존의 추천시스템이 추천한 것이다. 이것은 그 user의 과거 interaction을 기반으로 추천이 된 것이기 때문에 user의 positive intest를 어느정도 반영한 것이다.
3가지 negative feedback scenario (low rate, skipping content, clicking dislike button) 중에서 가장 강한 negative interest를 보여주는 것은 clicking dislike button scenario이다. WeChat dataset은 Table 2에서 MR이 22.04%이고, Fig 3에서 LightGCN의 G(0) > G(1)이다.
low rate scenario는 skipping content scenario보다 more negative하다. Zhihu dataset (skipping content scenario)에서 G(1) > G(0)이다. 이 결과는 skipping content는 빈번하게 일어나고 low-cost 이기 때문이다 (content를 skip하는 것은 low rate를 매기거나 dislike 버튼을 click하는 것만큼의 수고로움은 없으니). 그래서 부정적인 감정이 강하지 않다.
low rate scenario는 user로부터 direct negative feedback을 가지고 있지만 이 행동은 이미 해당 item을 watched/purchased한 후에 low rating을 한 것이다. user가 비록 low rating을 했지만 적어도 초기 단계에서는 positive interest를 가지고 있었다는 것을 의미한다.
clicking dislike button scenario는 추천 item에 부정적인 감정이 더 많다는 것을 의미한다.
이러한 finding을 바탕으로 추천 성능의 향상을 위해 다양한 negative feedback을 활용하는 모델을 설계한다.
4. Methodology
SiGRec의 모델은 아래의 그림과 같다. SiGRec에서 GNN train은 LightGCN을 사용한다 (LightGCN을 모르면 이해가 어려울 수 있으니 LightGCN 논문을 이해하고 와야한다. https://arxiv.org/abs/2002.02126).
아래 그림에서 보이는 것과 같이 signed graph를 부호별로 split하여 positive graph와 negative graph를 만든다. 그리고 positive graph를 LightGCN 모델에 태우고 Z+를 얻고, negative graph에 Z+를 LightGCN으로 태운 값을 MLP로 태운 것이 Z-이다. 마지막으로 Z+와 Z-를 concatenate하여 최종 예측 값을 predict 하는 방식이다.
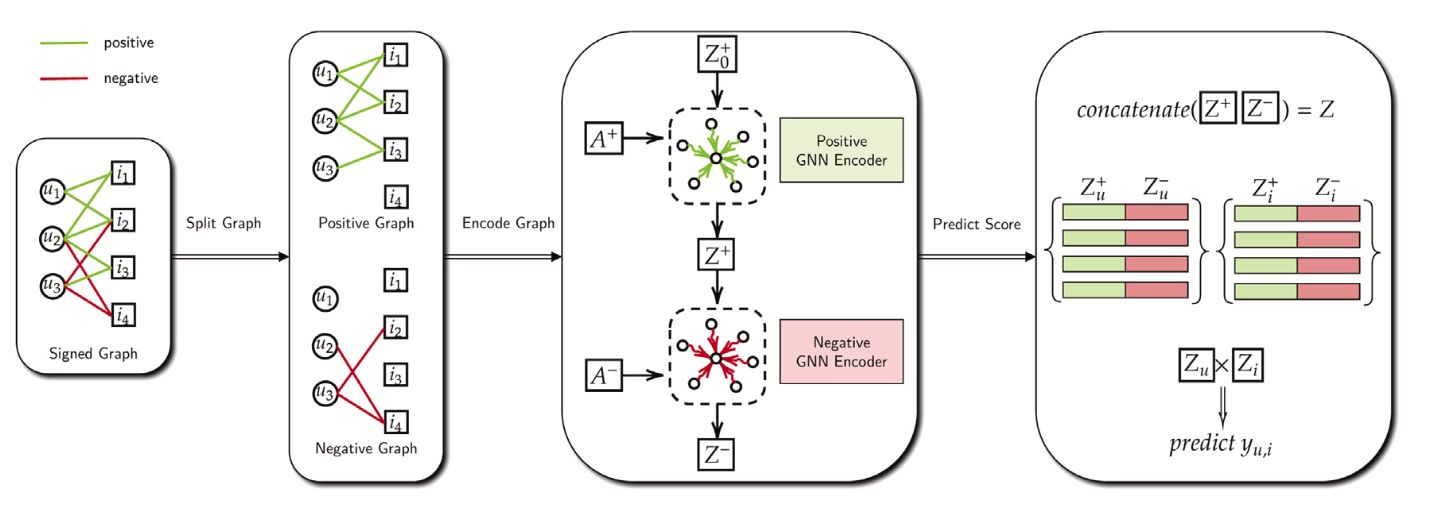
바로 위에서 언급한 모델 순서를 수식으로 표현해보자.
Z+(j+1) 구하는 과정은 아래와 같다.
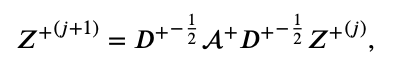
final positive embedding 구하는 수식은 아래와 같다.
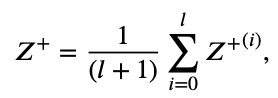
Z+(j+1) 구하는 식을 풀어쓴 것, final positive embedding 구하는 식을 풀어쓴 것은 아래와 같다 (LightGCN 논문을 알고 있거나 보고 왔다면 한 번에 이해되는 수식이니 LightGCN을 무조건 알아야한다).
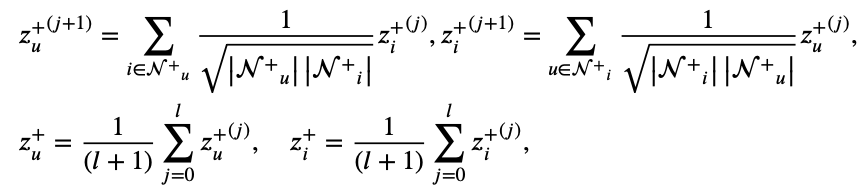
negative graph에 구해진 Z+를 LightGCN으로 태운 후에 MLP로 태워서 나온 Z-를 구하는 식은 아래와 같다.
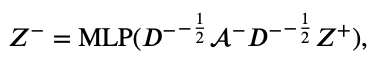
final embeddings Z를 구하기 위해 Z+와 Z-를 concatenate하는 수식은 아래와 같다.
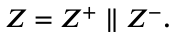
loss function
여기서 loss는 positive와 negative를 모두 모델링 해야하는 중요한 임무를 맡는다.
위의 식에서 나온 final embeddings Z에서 inner product를 통해 최종 예측 점수를 아래 식과 같이 계산한다. 이제부터 이 논문에서 제안하는 loss로 이 예측값을 최적화 해야한다.
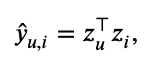
논문의 loss 소개 순서와는 다르게 결론부터 말하면 최종 loss 식은 아래와 같다.
첫번째 항으로 bpr loss를 사용하고, 두번째 항으로 sign (cosine) loss를 사용하고, 세번째 항의 L𝑟𝑒𝑔는 𝐿2 regularization of parameter이다.
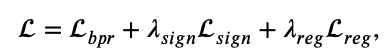
그래서 이제부터 첫번째 항과 두번째 항의 loss 수식에 대해 자세히 알아보겠다.
먼저 첫번째 항인 Lbpr 부터 알아보자. 수식은 아래와 같다. 우리가 알고 있는 BPR 수식과 동일하다 (BPR을 이해했다고 가정하고 부가적인 설명은 안 할 예정이니 BPR을 모른다면 무조건 BPR 논문을 읽고 와야한다. https://arxiv.org/pdf/1205.2618.pdf).
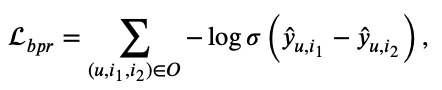
여기서 이 논문 저자는 선행 연구인 "SiReN: Sign-Aware Recommendation Using Graph Neural Networks"에서 사용하는 loss인 sbpr (bpr을 변형)의 목적이기도한 positive와 negative의 차이를 directly하게 모델링할 수 없다고 말한다 (SiReN: Sign-Aware Recommendation Using Graph Neural Networks 논문에 대해 알고 싶다면 다음 링크에 들어가면 된다. https://velog.io/@chwchong/SiReN-Sign-Aware-Recommendation-Using-Graph-Neural-Networks). SiReN 논문의 sbpr에서 c=2인데 여기서 c=1로만 두면 원래의 오리지널 bpr과 식이 같아진다. 여기서는 c=1로 두고 positive와 negative의 차이 없이 동일한 loss를 수행한다. 여기서 positive와 negative의 차이를 두는 것이 아닌 다른 loss (두번째 항 loss)를 추가해서 차이를 두겠다는거다.
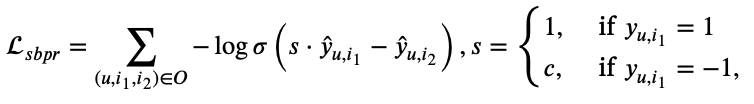
이제 두번째 항인 Lsign에 대해 알아보자.
수식은 아래와 같다(pytorch에서는 COSINE EMBEDDING LOSS로 나와있다. https://pytorch.org/docs/stable/generated/torch.nn.CosineEmbeddingLoss.html).
positive일 때는 그냥 평범하게 cosine similarity가 높아지게끔 만들어주는 loss이다.
그런데 negative일 때는 얘기가 달라진다. cosine similarity가 margin 𝜇 보다 크다면 제재를 주는 것으로 해석할 수 있다. 여기서 margin 𝜇는 0.9이다 (dataset에 따라 0.7인 경우도 있긴하지만 대부분 dataset에서는 0.9 최적값). 저자는 𝜇가 zu와 zi의 방향의 일관성을 제어하는 flexible한 hyperparameter라고 주장한다.
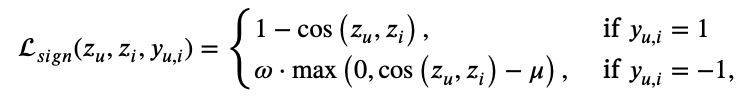
결론적으로 이 2개의 loss를 통해 아래의 최종 loss식이 나온다 (위에서 시작부터 언급했지만 다시 언급함). 첫번째 항은 그냥 오리지널 bpr loss, 두번째 항은 sign (cosine) loss, 세번째 항의 L𝑟𝑒𝑔는 𝐿2 regularization of parameter이다.
이 논문의 선행 연구 논문인 "SiReN: Sign-Aware Recommendation Using Graph Neural Networks"의 sbpr loss는 positive와 negative의 차이를 모델링할 수 없다고 이 논문의 저자는 주장하면서 sbpr 대신 오리지널 bpr을 사용하고, 새로운 loss인 Sign Cosine (SiC) loss를 사용한다. bpr loss는 pairwise loss이고, Sic loss는 pointwise loss이기 때문에 pairwise loss와 pointwise loss를 함께 사용하여 embedding을 효과적으로 최적화할 수 있다고 말한다. 결론적으로 bpr loss에서는 positive와 negative의 구분 없이 단지 observed(positive와 negative 관계 없이 평가된 것)와 unobserved(소비하지 않아서 평가되지 않은 것)의 차이를 모델링하고, SiC loss에서는 positive와 negative의 차이를 모델링한다. 이 2개의 loss 조합은 singed network에 효과적으로 적용될 수 있다.
5. Experiments
실험 dataset은 Yelp, Amazon-Book, Zhihu, WeChat 이렇게 4가지다. train:validation:test = 70:10:20 이다. 평가는 Precision@N, Recall@N, nDCG@N으로 한다. 아래 표는 실험 결과를 나타낸다. 모든 dataset 모든 구간에서 SiGRec이 SOTA를 기록한다.

위의 실험 결과를 분석하면 BRPMF > NeuMF 인데 추천시스템에서 pointwise loss가 pairwise loss보다 덜 효과적일 수 있다고 말한다.
NGCF, DGCF, LightGCN > BPRMF 인데 NGCF, DGCF, LightGCN와 같은 GNN 방법도 BPRMF와 동일하게 BPR loss를 사용하였고, bipartite graph의 구조적 정보를 효과적으로 활용한다고 볼 수 있다.
GNN 방법 (NGCF, DGCF, LightGCN)에서는 LightGCN이 가장 성능이 좋다. GNN 방법에서 simplified architecture가 더 좋은 성능과 robustness를 보인다.
SiReN은 Amazon-Book, Yelp, Zhihu의 대부분 지표에서 LightGCN을 능가하지만 WeChat에서는 LightGCN에게 뒤지는 결과를 보여주는데 이 논문 저자는 SiReN의 sbpr loss가 기대만큼 제대로 작동하지 않을 수 있다고 지적한다.
이 논문 모델인 SiGRec은 모든 dataset 모든 지표에서 SOTA를 기록한다. SiGRec을 사용하면 negative edges가 CF task에 긍정적일 수 있다고 말한다.
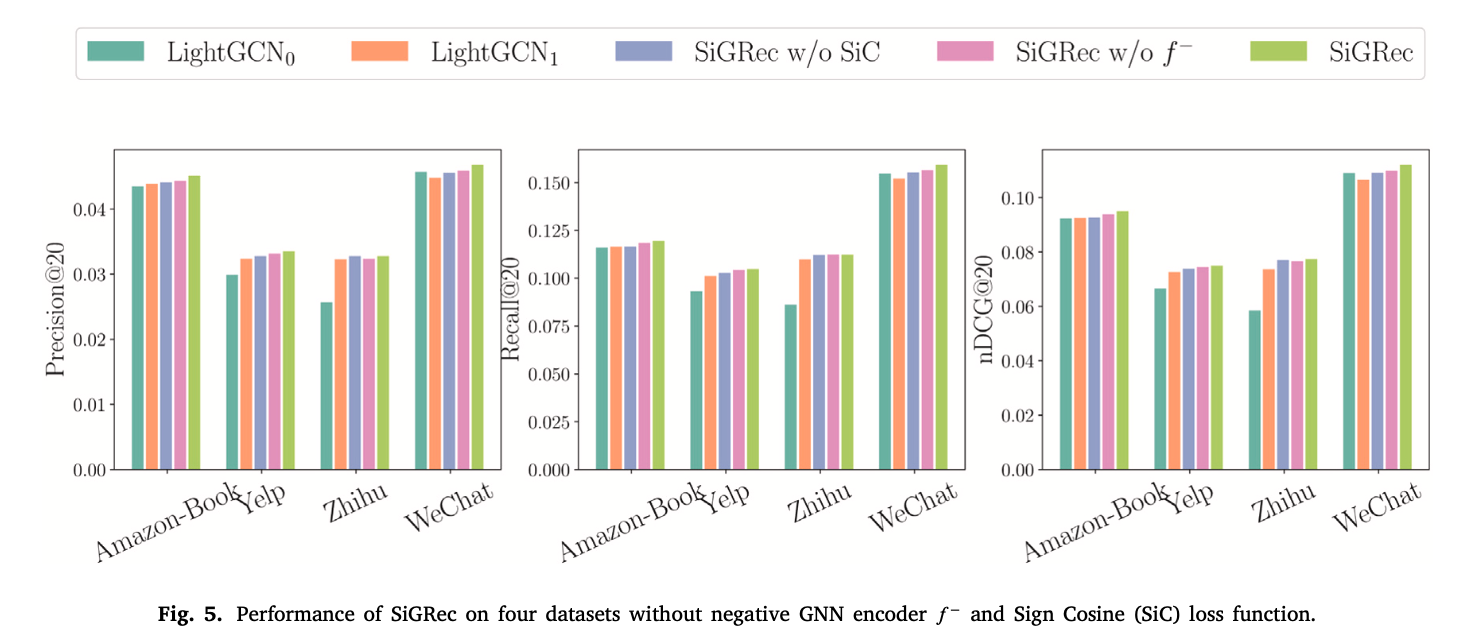
그리고 ablation study를 통해 아래의 그림이 negative GNN encoder와 SiC loss가 도움이 된다는 것을 증명한다.
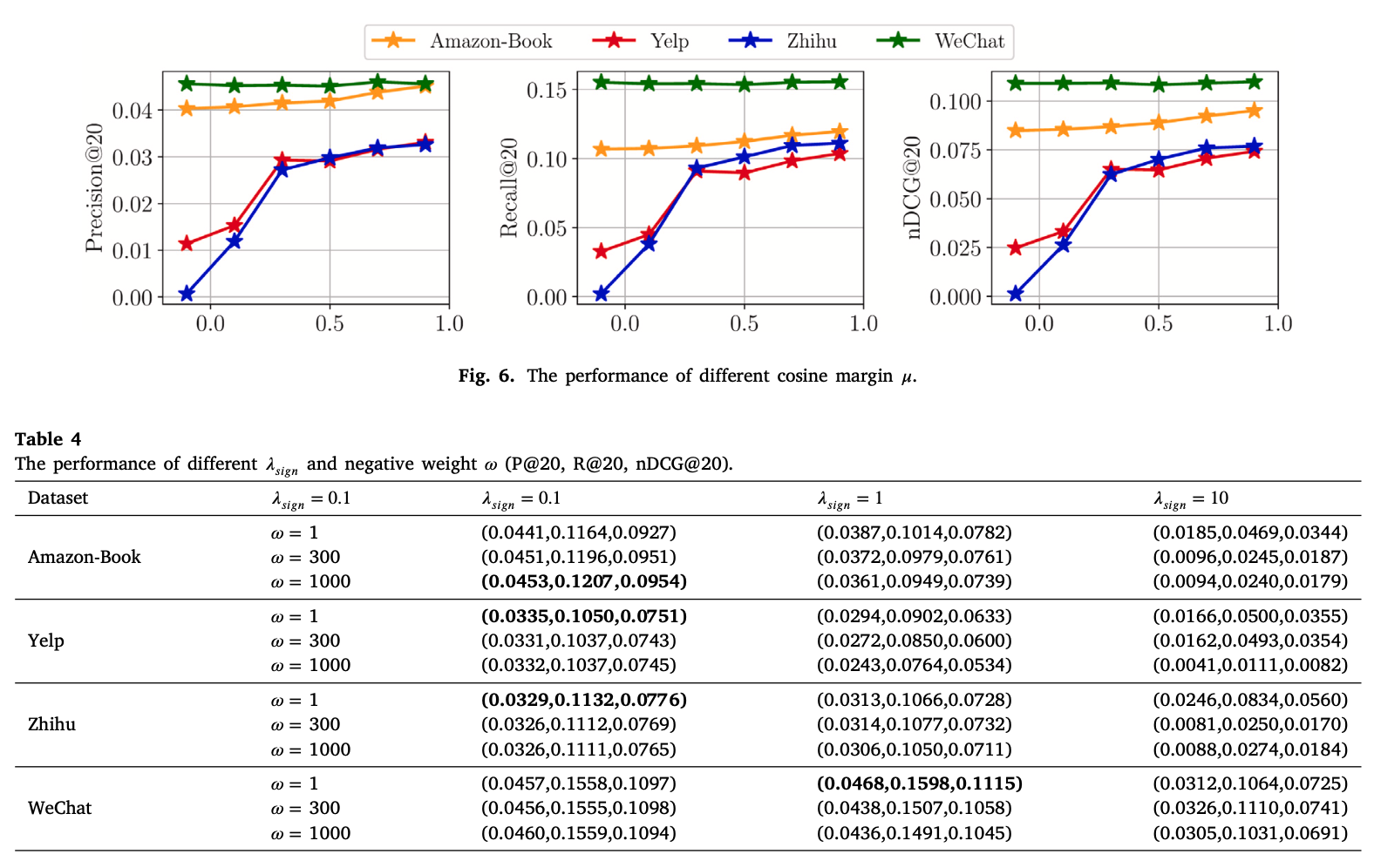
아래 그림과 표는 최적의 hyperparameter를 찾기 위한 실험이다. margin 𝜇에 대한 실험에서 margin 𝜇의 최적값이 상당히 크다는게 개인적으로 놀랍다. margin 𝜇가 크면 구분하기 어려운 negative에 초점을 맞추게 된다고 말한다.
6. Related work
- Graph neural networks in recommendation
- Signed network modeling
- Negative feedback in recommendation
SiReN은 negative feedback의 다양한 scenario 중에서 low rate scenario에만 집중했다는 것을 비판한다.
7. Conclusion
이 연구는 추천시스템에서 negative feedback에 집중했고, 이것을 분석하는 것부터 연구를 수행했다. 그 결과 negative feedback이 부정적이지만은 않다는 점을 발견하고, negative interactions을 긍정적으로 모델링하는 것은 성능에 도움이 된다고 했다. 이 분석을 바탕으로 SiGRec을 개발하였고, 이것은 LightGCN을 통해 positive embeddnig과 negative embedding을 생성하였다. 그리고 MLP로 매핑하였다. 여기서 최적화를 위해 BPR loss와 Sic loss를 사용하였다. 그리고 Z+와 Z-를 concatenate하여 점수를 예측한다. 그리고 이 모델은 SOTA를 기록했다.
8. Implications and future work
- Theoretical and practical implications
- Limitations and future work
