👀 LeNet-5
합성곱(convolutional)과 다운 샘플링(sub-sampling)(혹은 풀링)을 반복적으로 거치면서 마지막 완전연결층에서 분류를 수행한다.
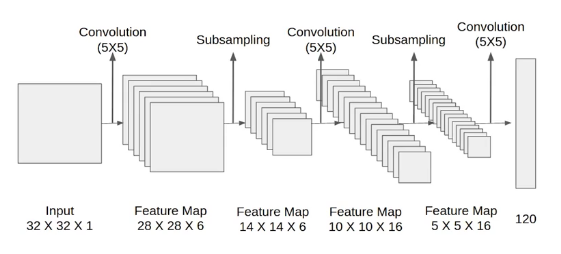
- C1에서 5X5 합성곱 연산 후 28X28 크기의 특성 맵(feature map) 6개를 생성
- S2에서 다운샘플링하여 특성 맵 크기를 14X14로 축소
- C3에서 5X5 합성곱 연산하여 10X10 크기의 특성 맵 16개를 생성
- S4에서 다운 샘플링하여 특성 맵 크기를 5X5로 축소
- C5에서 5X5 합성곱 연산하여 1X1 크기의 특성 맵 120개를 생성
- F6에서 완전연결층으로 C5 결과를 유닛(또는 노드) 84개에 연결시킴.
(* 여기서 C는 합성곱층, S는 풀링층을 의미. F는 완전연결층을 의미)
| 계층 유형 | 특성 맵 | 크기 | 커널 크기 | 스트라이드 | 활성화 함수 |
|---|---|---|---|---|---|
| 이미지 | 1 | 32X32 | - | - | - |
| 합성곱층 | 6 | 28X28 | 5X5 | 1 | ReLU |
| 최대 풀링층 | 6 | 14X14 | 2X2 | 2 | - |
| 합성곱층 | 16 | 10X10 | 5X5 | 1 | ReLU |
| 최대 풀링층 | 16 | 5X5 | 2X2 | 2 | - |
| 완전연결층 | - | 120 | - | - | ReLU |
| 완전연결층 | - | 84 | - | - | ReLU |
| 완전연결층 | - | 2 | - | - | Softmax |
다음부터 LeNet-5를 활용한 개, 고양이 이미지 분류를 수행해 보려고 한다.
Image classification with LeNet-5
import torch
import torchvision
from torch.utils.data import DataLoader, Dataset
from torchvision import transforms
from torch.autograd import Variable
from torch import optim
import torch.nn as nn
import torch.nn.functional as F
import os
import cv2
from PIL import Image
from tqdm import tqdm_notebook as tqdm
import random
from matplotlib import pyplot as plt
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')먼저 필요한 라이브러리를 호출한다. torch.device()로 GPU 할당을 선언한다.
# data preprocessing
class ImageTransform() :
def __init__(self, resize, mean, std) :
self.data_transform = {
'train' : transforms.Compose([
transforms.RandomResizedCrop(resize, scale=(0.5, 1.0)),
# scale=(0.5, 1.0) : 랜덤 크기 50~100% 리사이징
transforms.RandomHorizontalFlip(), # 수평 반전
transforms.ToTensor(), # (H, W, C) --> (C, H, W)
transforms.Normalize(mean ,std) # 정규화
# mean (0.485, 0.456, 0.406), std (0.229, 0.224, 0.225)
# ---> ImageNet의 이미지 RGB 채널마다 평균과 표준편차를 의미
]),
'val' : transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(resize),
transforms.ToTensor(),
transforms.Normalize(mean, std)
])
}
def __call__(self, img, phase) :
return self.data_transform[phase](img)이미지 데이터셋을 전처리하는 클래스를 생성한다.
# 데이터셋 로드 후 train, test ,validation 분리
cat_dir = r'../080289-main/chap06/data/dogs-vs-cats/Cat/'
dog_dir = r'../080289-main/chap06/data/dogs-vs-cats/Dog/'
cat_img_filepath = sorted([os.path.join(cat_dir, f) for f in os.listdir(cat_dir)])
dog_img_filepath = sorted([os.path.join(dog_dir, f) for f in os.listdir(dog_dir)])
img_filepath = [*cat_img_filepath, *dog_img_filepath]
correct_img_filepath = [i for i in img_filepath if cv2.imread(i) is not None]
random.seed(12)
random.shuffle(correct_img_filepath)
train_img_filepath = correct_img_filepath[:400] # train 400
val_img_filepath = correct_img_filepath[400:-10] # val 92
test_img_filepath = correct_img_filepath[-10:] # test 10
print(len(train_img_filepath), len(val_img_filepath), len(test_img_filepath))데이터셋을 로드하여 훈련(train), 검증(val), 테스트(test) 셋으로 분리한다.
# 테스트 데이터셋 이미지 확인
def display_img_grid(img_filepath, pred_labels=(), cols=5) :
rows = len(img_filepath) // cols
figure, ax = plt.subplots(nrows=rows, ncols=cols, figsize=(12, 6))
for i, img_filepath in enumerate(img_filepath) :
image = cv2.imread(img_filepath)
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
true_label = os.path.normpath(img_filepath).split(os.sep)[-2]
pred_label = pred_labels[i] if pred_labels else true_label
color = 'green' if true_label == pred_label else 'red'
ax.ravel()[i].imshow(image)
ax.ravel()[i].set_title(pred_label, color=color)
ax.ravel()[i].set_axis_off()
plt.tight_layout()
plt.show()display_img_grid(test_img_filepath)
테스트 데이터셋 이미지를 출력한다.
# 이미지 데이터셋 클래스 정의
class DogvsCatDataset(Dataset) :
def __init__(self, file_list, transform=None, phase='train') :
self.file_list = file_list
self.transform = transform
self.phase = phase
def __len__(self) :
return len(self.file_list)
def __getitem__(self, idx) :
img_path = self.file_list[idx]
img = Image.open(img_path)
img_transformed = self.transform(img, self.phase)
label = img_path.split('/')[-1].split('.')[0]
if label == 'dog' :
label = 1
elif label == 'cat' :
label = 0
return img_transformed, label데이터를 로드하는 방법을 정의한다. 고양이의 레이블은 0, 개의 레이블은 1이 된다.
# 변수 값 정의
size = 224
mean = (0.485, 0.456, 0.406)
std = (0.229, 0.224, 0.225)
batch_size = 32전처리 시 사용할 변수 값을 정의한다.
# 이미지 데이터셋 정의
train_dataset = DogvsCatDataset(train_img_filepath, transform=ImageTransform(size, mean, std),
phase='train')
val_dataset = DogvsCatDataset(val_img_filepath, transform=ImageTransform(size, mean, std),
phase='val')
index = 0
print(train_dataset.__getitem__(index)[0].size()) # 훈련 데이터의 크기 출력
print(train_dataset.__getitem__(index)[1]) # 레이블 출력DogvsCatDataset() 클래스를 이용하여 전처리를 적용한 훈련, 검증 데이터셋을 로드한다.
이미지는 컬러 상태에서 224*224 크기를 가진다. (레이블은 랜덤 0 또는 1)
# 데이터로더 정의
train_dataloader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
val_dataloader = DataLoader(val_dataset, batch_size=batch_size, shuffle=False)
dataloader_dict = {'train' : train_dataloader, 'val' : val_dataloader}
batch_iterator = iter(train_dataloader)
inputs, label = next(batch_iterator)
print(inputs.size())
print(label)데이터로더를 이용하여 훈련 데이터셋을 메모리로 불러온 후, 데이터셋 크기와 레이블을 출력한다.
# 네트워크 클래스
class LeNet(nn.Module) :
def __init__(self) :
super(LeNet, self).__init__()
self.cnn1 = nn.Conv2d(in_channels=3, out_channels=16,
kernel_size=5, stride=1, padding=0) # (16, 220 ,220)
self.relu1 = nn.ReLU()
self.maxpool1 = nn.MaxPool2d(kernel_size=2) # (16, 110 ,110)
self.cnn2 = nn.Conv2d(in_channels=16, out_channels=32, kernel_size=5,
stride=1, padding=0) # (32, 106, 106)
self.relu2 = nn.ReLU()
self.maxpool2 = nn.MaxPool2d(kernel_size=2) # (32, 53, 53)
self.fc1 = nn.Linear(32*53*53, 512)
self.relu5 = nn.ReLU()
self.fc2 = nn.Linear(512, 2)
self.output = nn.Softmax(dim=1)
def forward(self, x) :
out = self.cnn1(x)
out = self.relu1(out)
out = self.maxpool1(out)
out = self.cnn2(out)
out = self.relu2(out)
out = self.maxpool2(out)
out = out.view(out.size(0), -1)
out = self.fc1(out)
out = self.fc2(out)
out = self.output(out)
return out모델 네트워크를 설계하는 클래스를 생성한다.
** 출력 크기 공식(참고용)
-
Conv2d 계층 출력 크기 공식
output size = (W-F+2P) / S+1
** W : 입력 데이터 크기 , F : 커널 크기 , P : 패딩 크기 , S : 스트라이드 -
MaxPool2d 계층 출력 크기 공식
output size = IF / F
** IF : 입력 필터 크기 , F : 커널 크기
# 모델 객체 생성
model = LeNet()
print(model)
model 객체를 생성하여 학습을 준비한다.
** torchsummary(참고)
torchsummary 라이브러리를 사용하면 케라스와 같은 형태로 모델을 출력해 볼 수 있다.
# !pip install torchsummary
from torchsummary import summary
summary(model, input_size=(3, 224, 224))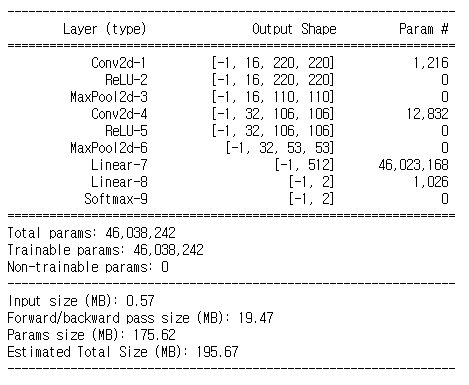
# 학습 가능한 파라미터 확인
def count_params(model) :
return sum(p.numel() for p in model.parameters() if p.requires_grad)
print(f'Model has {count_params(model):,} trainable parameters')model.parameters()를 이용하여 학습가능한 파라미터 수를 확인한다. (실행 결과는 46,038,242개)
# define optimizer and loss function
optimizer = optim.SGD(model.parameters(), lr=0.001, momentum=0.9)
criterion = nn.CrossEntropyLoss()옵티마이저와 손실 함수를 정의한다. 경사 하강법으로 모멘텀 SGD를 사용한다.
모멘텀 SGD는 SGD에 관성이 추가된 것으로, 매번 기울기를 구하지만 가중치를 수정하기 전에 이전의 수정 방향(+, -)를 참고하여 같은 방향으로 일정 비율만 수정되도록 하는 방법이다.
- lr(learning rate) : 가중치를 변경할 때 변경 크기
- momentum : SGD를 적절한 방향으로 가속화하여 진동을 줄여주는 매개변수
# 모델의 파라미터와 손실함수를 디바이스에 할당
model = model.to(device)
criterion = criterion.to(device)# define train function
def train_model(model, dataloader_dict, criterion, optimizer, n_epochs) :
since = time.time()
best_acc = 0.0
for epoch in range(n_epochs) :
print(f'Epoch {epoch+1}/{n_epochs}')
print('-' * 20)
for phase in ['train', 'val'] :
if phase == 'train' :
model.train()
else :
model.eval()
epoch_loss = 0.0
epoch_corrects = 0
for inputs, labels in tqdm(dataloader_dict[phase]) :
inputs = inputs.to(device)
labels = labels.to(device)
optimizer.zero_grad() # 기욹 ㅣ초기화
with torch.set_grad_enabled(phase == 'train') :
outputs = model(inputs)
_, preds = torch.max(outputs, 1)
loss = criterion(outputs, labels)
if phase == 'train' :
loss.backward()
optimizer.step()
# 손실 함수는 오차를 배치크기로 나누어 평균을 반환하므로,
# epoch_loss 계산 시 loss.item()과 inputs.size()를 곱하여 줌
epoch_loss += loss.item() * inputs.size(0)
epoch_corrects += torch.sum(preds == labels.data)
epoch_loss = epoch_loss / len(dataloader_dict[phase].dataset)
epoch_acc = epoch_corrects.double() / len(dataloader_dict[phase].dataset)
print(f'{phase} Loss : {epoch_loss:.4f} Acc : {epoch_acc:.4f}')
if phase == 'val' and epoch_acc > best_acc :
best_acc = epoch_acc
best_model_wts = model.state_dict()
time_elapsed = time.time() - since
print(f'Training complete in : {time_elapsed // 60:.0f}m {time_elapsed % 60:.0f}s')
print(f'Best val acc : {best_acc:4f}')
return model모델 학습 함수를 정의한다.
import time
n_epochs = 10
model = train_model(model, dataloader_dict, criterion, optimizer, 13)
모델을 학습시킨다. 전체 데이터를 사용하지 않아서 높은 결과를 얻지 못하므로, 더 좋은 성능을 얻으려면 데이터셋을 늘려서 테스트 해 보아야 한다.
# 모델 테스트 함수 정의
import pandas as pd
id_list = []
pred_list = []
_id = 0
with torch.no_grad() :
for test_path in tqdm(test_img_filepath) :
img = Image.open(test_path)
_id = test_path.split('/')[-1].split('.')[1]
transform = ImageTransform(size, mean, std)
img = transform(img, phase='val')
img = img.unsqueeze(0)
img = img.to(device)
model.eval()
outputs = model(img)
preds = F.softmax(outputs, dim=1)[:, 1].tolist()
id_list.append(_id)
pred_list.append(preds[0])
res = pd.DataFrame({
'id' : id_list,
'label' : pred_list
})
res.sort_values(by='id', inplace=True)
res.reset_index(drop=True, inplace=True)
res.to_csv('./LeNet.csv', index=False)모델 테스트 함수를 정의한다.
# 테스트 데이터셋의 이미지 출력
class_ = classes = {0 : 'cat', 1 : 'dog'}
def display_img_grid(images_filepath, pred_labels=(), cols=5) :
rows = len(images_filepath) // cols
figure, ax = plt.subplots(nrows=rows, ncols=cols, figsize=(12, 6))
for i, images_filepath in enumerate(images_filepath) :
image = cv2.imread(images_filepath)
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
a = random.choice(res['id'].values)
label = res.loc[res['id'] == a, 'label'].values[0]
if label > 0.5 :
label = 1
else :
label = 0
ax.ravel()[i].imshow(image)
ax.ravel()[i].set_title(class_[label])
ax.ravel()[i].set_axis_off()
plt.tight_layout()
plt.show()display_img_grid(test_img_filepath)
예측 결과를 시각화하는 함수를 정의한다.
📚 reference
- (길벗) 딥러닝 파이토치 교과서 / 서지영 지음
- github

안녕하세요.
궁금하게 있어서요.
5*5 크기의 필터는 어떻게 만들어 지는건가요?