
EfficientNetv2는 가볍고 효율적이면서 좋은 성능을 갖는 vision model이다. mobile과 같이 자원이 제한된 환경에서 많이 사용되며, 이미지 분류와 같은 작업에 효과적이다.
이 포스팅에서는 현재 내가 진행중인 프로젝트 일부인 "교통 표지판 분류"를 EfficientNetv2로 간단하게 수행해보고자 한다.
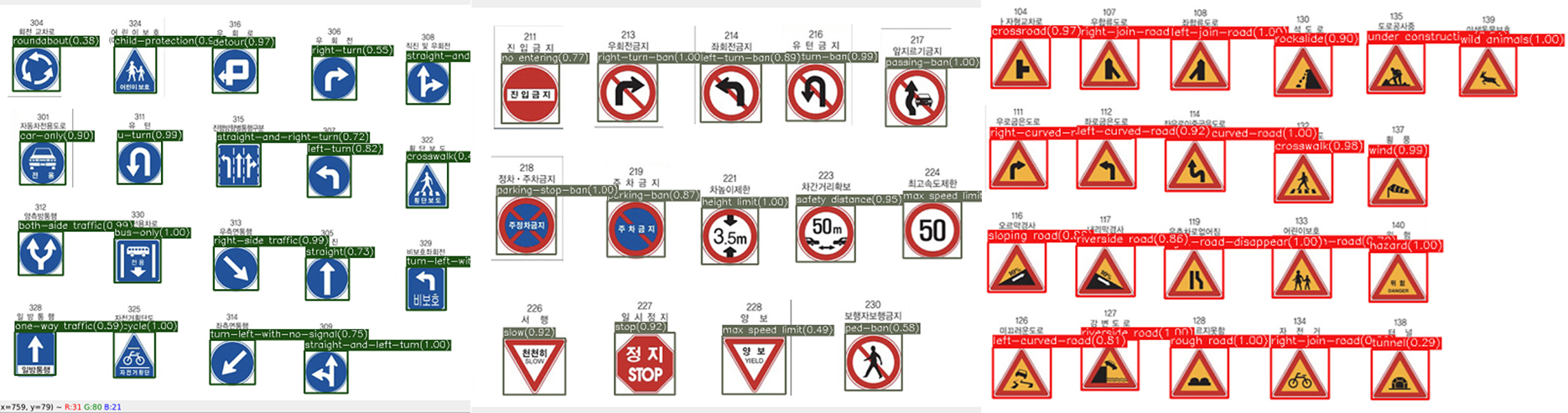
프로젝트에 대하여 간략히 설명하자면, 먼저 교통 표지판을 "제한", "지시", "주의" 3가지 type으로 분류한 후, YOLO detector를 통해 3가지 표지판을 탐지할 수 있도록 했다.

그 다음, 이 3가지 표지판에서 세부적인 내용을 classification으로 분류하는 것이다. 예를 들면, 제한 표지판을 탐지했다면 "속도 제한" 표지판인지, "주차 제한" 표지판인지, .. 등등의 세세한 분류 작업이다. 그리고 선행되는 Yolo detector 훈련은 먼저 완료했으며, classification 작업을 EfficientNetv2로 수행하는 것이다.
EfficientNet 모델에 대한 설명은 다른 포스팅에서 하고, 여기서는 pytorch 구현 코드만 간단히 다룬다.
모델 학습
import torch
import torchvision
import torchvision.transforms as transforms
from torch.utils.data import DataLoader, Dataset
from torchvision import models
import torch.nn as nn
import torch.optim as optim
from torch.utils.data.dataset import random_split
from PIL import Image
import os
import cv2
from torchvision import datasets
import glob
# custom dataset
class CustomDataset(Dataset):
def __init__(self, root_dir, transform=None):
self.root_dir = root_dir
self.transform = transform
self.images = os.listdir(root_dir)
def __len__(self):
return len(self.images)
def __getitem__(self, idx):
img_name = os.path.join(self.root_dir, self.images[idx])
image = Image.open(img_name)
if self.transform:
image = self.transform(image)
return image
# load dataset and transform
transform_train = transforms.Compose([
transforms.RandomResizedCrop(224),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
])
# ImageFolder 데이터셋 로드
train_dataset = datasets.ImageFolder(root='/your/train/folder/path/', transform=transform_train)
idx_to_cls = {v:k for k,v in train_dataset.class_to_idx.items()}
# train_dataset = CustomDataset(root_dir='/your/train/folder/path/', transform=transform_train)
train_size = int(0.8 * len(train_dataset))
val_size = len(train_dataset) - train_size
train_dataset, val_dataset = random_split(train_dataset, [train_size, val_size])
# 검증 데이터셋에도 동일한 변환 적용
val_dataset.dataset.transform = transform_train
# DataLoader 설정
train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True)
val_loader = DataLoader(val_dataset, batch_size=32, shuffle=False)
model = models.efficientnet_v2_s(pretrained=True)
# Adjust the classifier for the number of classes in your dataset
# number of classes
class_folder_dir=glob.glob("./your/class/folder/path/*")
num_classes = len(class_folder_dir) # Change to your number of classes
print(f"number of classes : {num_classes}")
model.classifier[1] = nn.Linear(model.classifier[1].in_features, num_classes)
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model.to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.01)
def train_and_validate_model(train_loader, val_loader, model, criterion, optimizer, num_epochs=25):
best_acc = 0.0
for epoch in range(num_epochs):
model.train()
running_loss = 0.0
running_corrects = 0
for inputs, labels in train_loader:
inputs, labels = inputs.to(device), labels.to(device)
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item() * inputs.size(0)
_, preds = torch.max(outputs, 1)
running_corrects += torch.sum(preds == labels.data)
epoch_loss = running_loss / len(train_loader.dataset)
epoch_acc = running_corrects.double() / len(train_loader.dataset)
# 검증 단계
model.eval()
val_loss = 0.0
val_corrects = 0
for inputs, labels in val_loader:
inputs, labels = inputs.to(device), labels.to(device)
with torch.no_grad():
outputs = model(inputs)
loss = criterion(outputs, labels)
_, preds = torch.max(outputs, 1)
val_loss += loss.item() * inputs.size(0)
val_corrects += torch.sum(preds == labels.data)
val_loss = val_loss / len(val_loader.dataset)
val_acc = val_corrects.double() / len(val_loader.dataset)
print(f'Epoch {epoch+1}/{num_epochs}, '
f'Train Loss: {epoch_loss:.4f}, Train Acc: {epoch_acc:.4f}, '
f'Val Loss: {val_loss:.4f}, Val Acc: {val_acc:.4f}')
# 모델 저장 조건 추가: 현재 검증 정확도가 지금까지의 최고보다 더 높으면 모델 저장
if val_acc > best_acc:
best_acc = val_acc
torch.save(model.state_dict(), 'your_best_model.pth')
return model
model = train_and_validate_model(train_loader, val_loader, model, criterion, optimizer, num_epochs=25)
모델 로드 및 추론
def load_model(model_path):
model = models.efficientnet_v2_s(pretrained=False)
model.classifier[1] = nn.Linear(model.classifier[1].in_features, num_classes)
model.load_state_dict(torch.load(model_path))
model.to(device)
model.eval()
return model
model = load_model('your_best_model.pth')
def predict_image(image_path, model, transform):
image = Image.open(image_path)
image = transform(image).unsqueeze(0).to(device)
with torch.no_grad():
outputs = model(image)
probabilities=torch.nn.functional.softmax(outputs,dim=1)
max_prob, predicted = torch.max(probabilities, 1)
predicted_label = idx_to_cls[predicted.item()]
return max_prob.item(), predicted_label
test_image_path='./your/image/path/image.jpg'
max_prob, predicted_label = predict_image(test_image_path, model, transform_train)
print(f'Predicted class: {max_prob, predicted_label}')
test_img = cv2.imread(test_image_path)
cv2.imshow("test_img", test_img)
cv2.waitKey(0)
cv2.destroyAllWindows()추론 결과

아직 데이터 분류가 다 끝나지 않아서 실제로 적용해 보았을 때 정확도는 낮지만, 적어도 분류는 되고 있음을 알 수 있다 (..ㅎ)
기회가 되면 이전 과정(detection)에 대해서도 포스팅 해보겠다.

AI에 대체되지 않는 인재가 되자