Semantic Change Detection 이해하기
0
Goal
- semantic change detection을 명확히 이해한다.
- 기존의 semantic change detection 모델과 현재 구현된 model의 구조를 파악한다.
- semantic change detection의 metric과 loss function을 수학적으로 이해한다.
들어가기에 앞서...
- 필자는 현재 포항공과대학교 3학년에 재학 중이고, 6~8월 간 메이사플래닛이라는 기업에서 Research Intern으로 근무하며 diffusion model을 이용한 semantic change detection 모델 'DDPM-scd'을 개발했다.
- 본 글에 소개되는 metric의 경우 semantic change detection에서 사용되는 다양한 것들을 다루기 위해 노력했다.
- 본 글에 소개되는 모델의 loss function의 경우 필자가 개발한 모델과, 참고 자료가 됐던 'Bi-SRNet'에서 사용된 loss function을 다루고, 수학적인 의미에 대해 설명했다.
- 모델을 개발하기 위해 참고했던 문헌들은 글 맨 아래에 담아둘 예정이고, 조만간 모델 개발 과정을 담은 글을 업로드할 예정이다.
Model
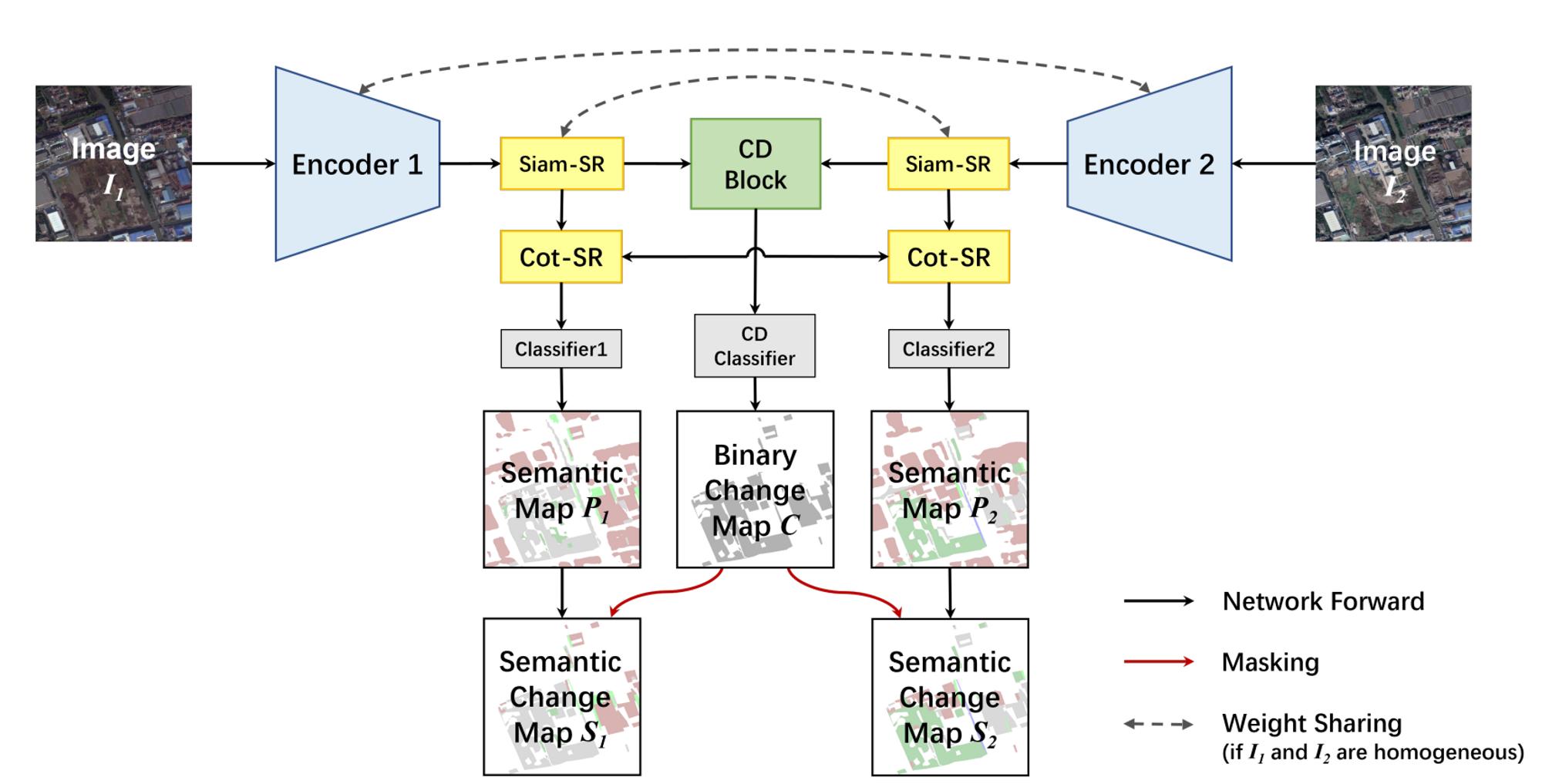
Bi-SRNet
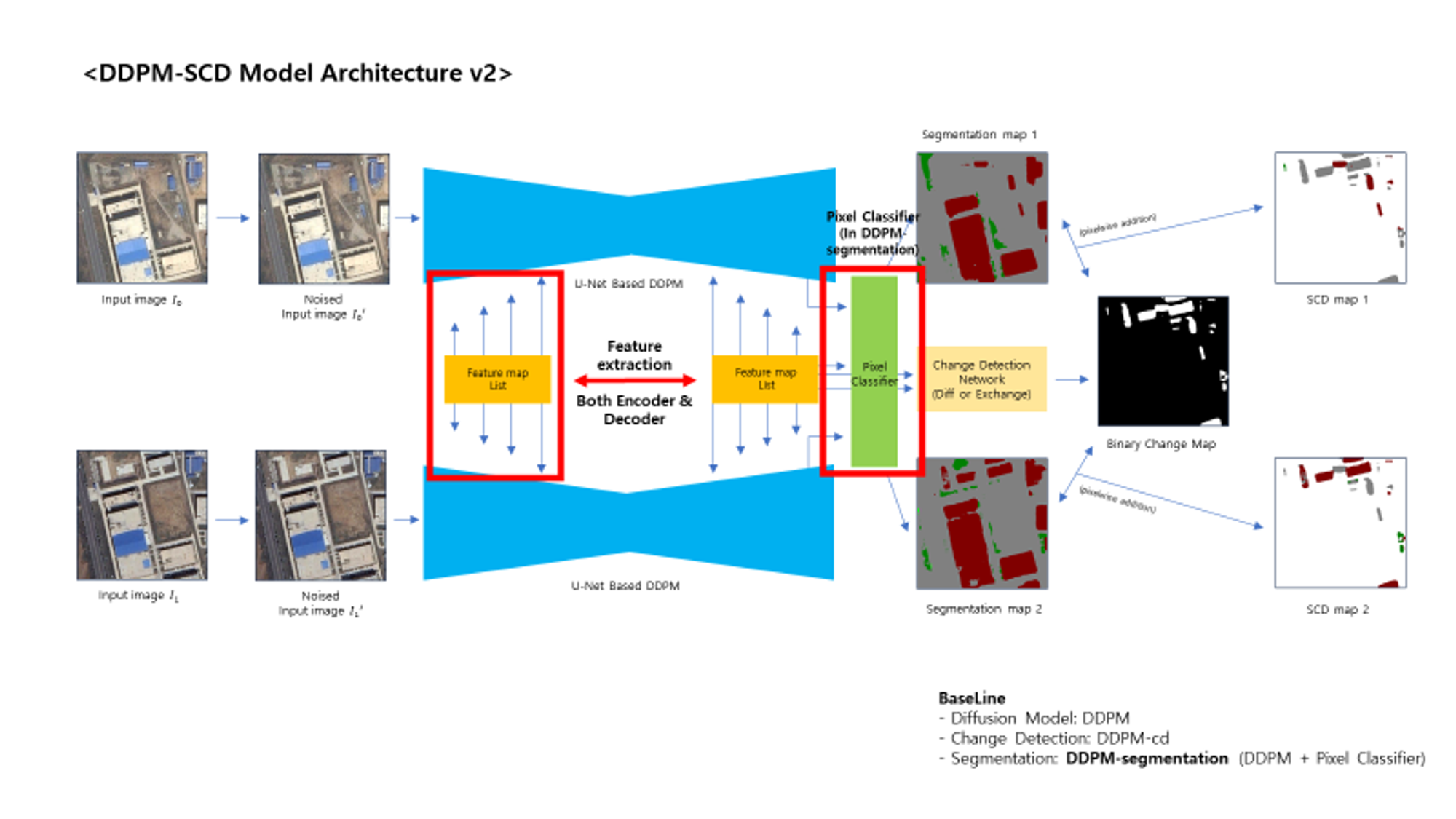
DDPM-scd (Ours)
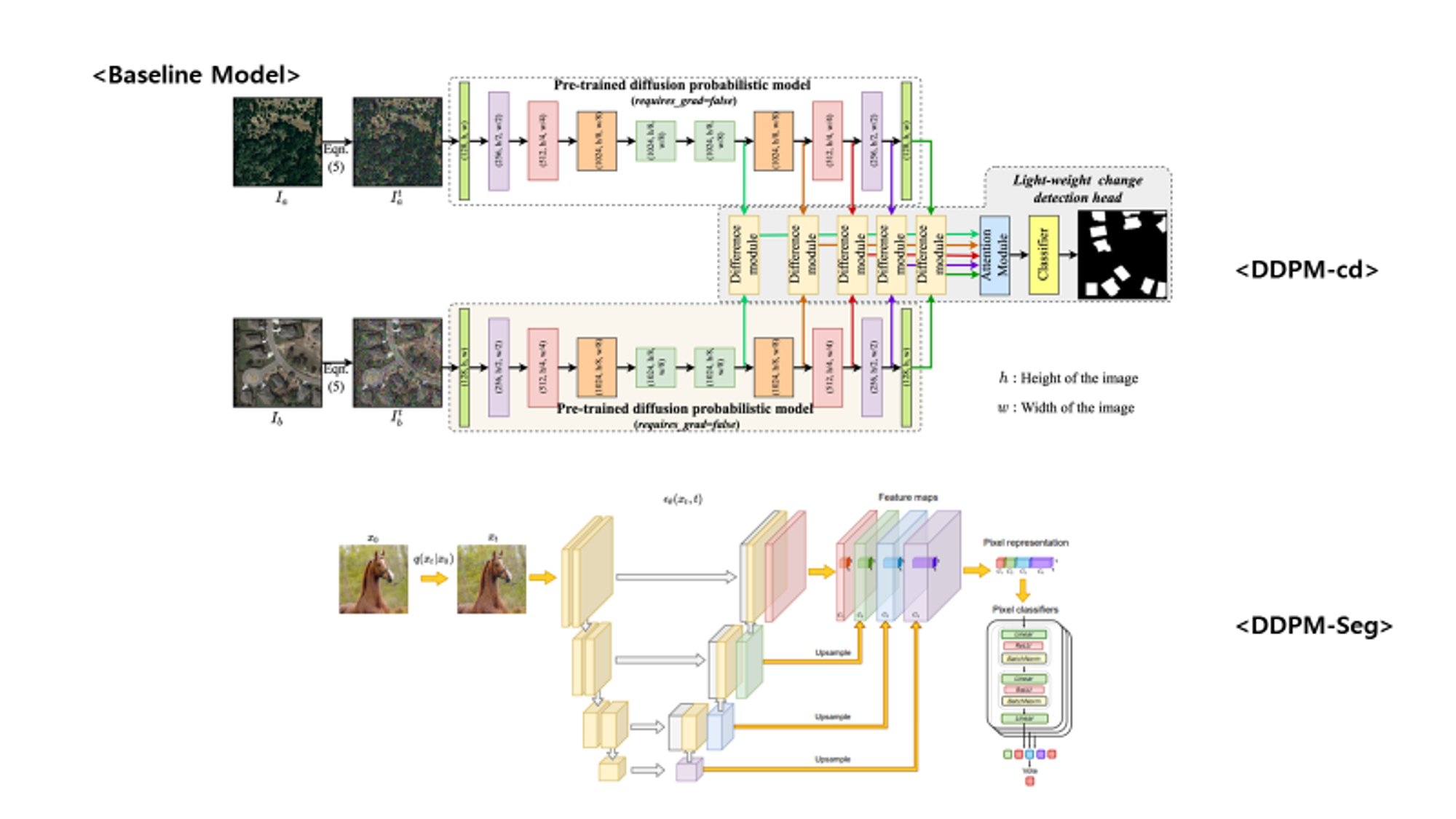
DDPM-cd / DDPM-segmentation (Baseline Model)
- Bi-SRNet, DDPM-cd, DDPM-segementation에서 아이디어를 얻어 제작함.
- Bi-SRNet에서는 binary change map과 semantic map은 독립적으로 구하고, 간단한 픽셀 연산을 통해 prediction을 구해냄. 다만 loss로 optimizer을 update할 때 둘 사이의 consistency를 regularize하는 방법을 제시하고, segmentation을 하기 위한 feature extraction 도중 Cot-SR Block(cross attention)이 있음.
- DDPM-scd에서도 모델이 예측하는 방식은 같음. 단 loss_sc나 cross attention 등은 ablation study 사항으로 고려해두고, 아직 적용하진 않음
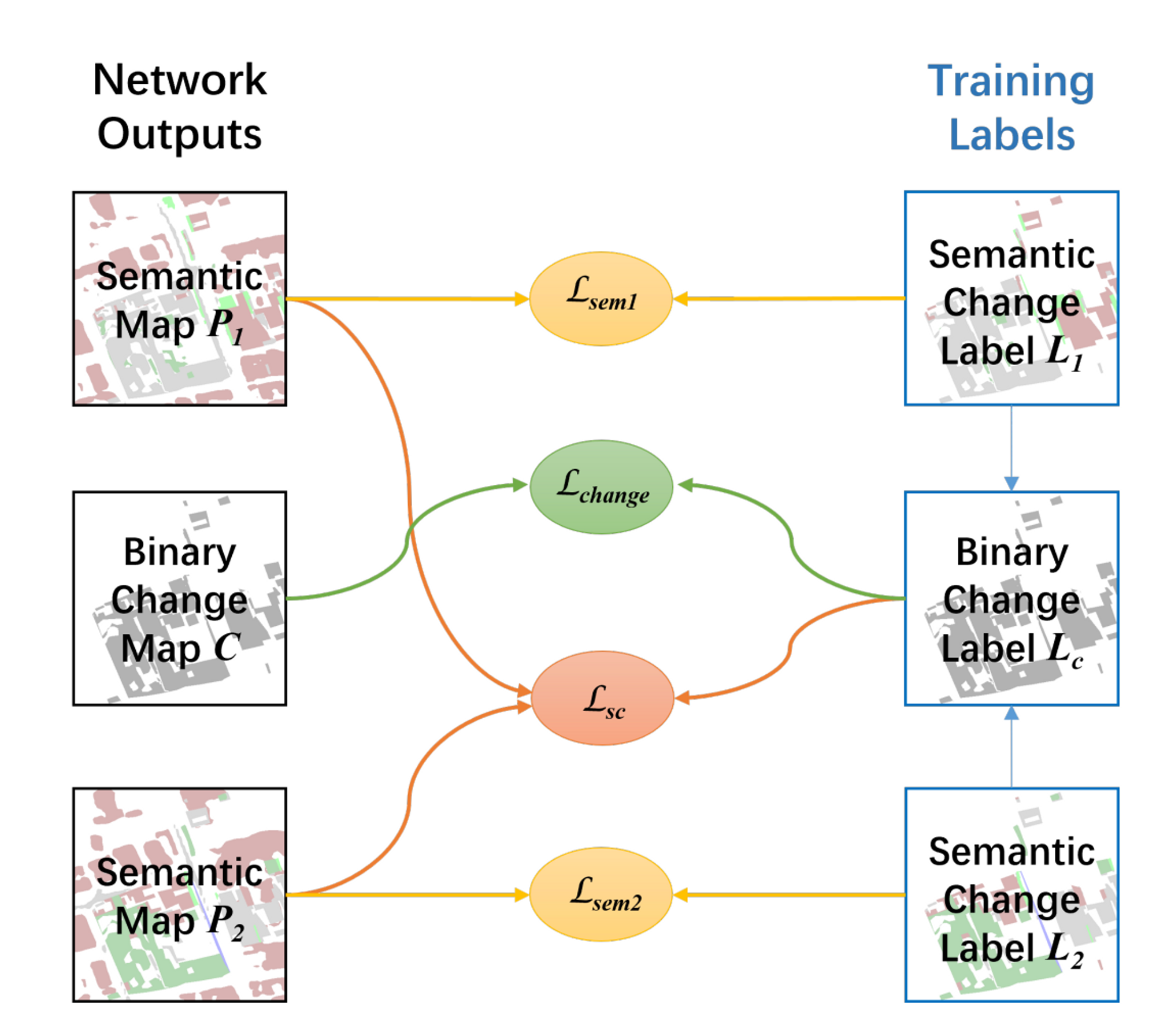
Loss function
- 개발한 모델에서는 Bi-SRNet에서 제안한 loss function을 사용 (l_sc는 제외)
- Bi-SRNet에서 사용한 loss function은 3가지 term의 합임.
L_sem
- multi class cross entropy loss이다. semantic change detection 데이터셋에는 segmentation에 대한 label이 존재하지 않으므로, scd map과 segmentation map 사이의 multi class cross entropy loss를 측정한다. (torch.nnCrossEntropy2d의 ignore_label=0으로 설정 후 계산)
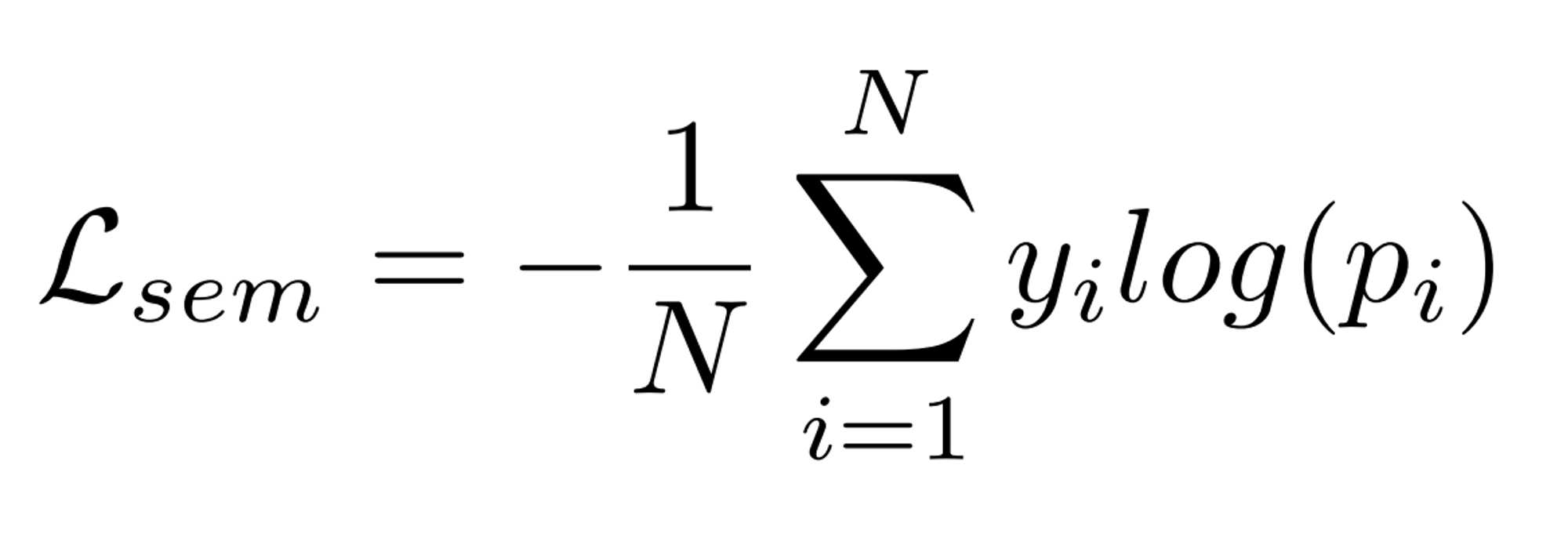
L_change
- Binary cross Entropy 함수로 측정
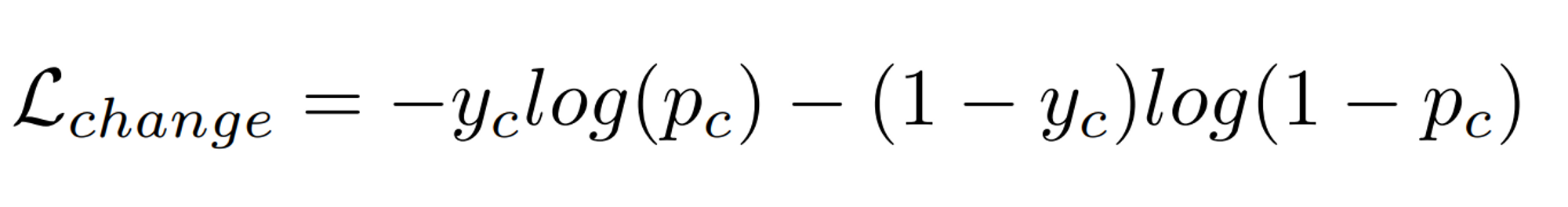
L_sc
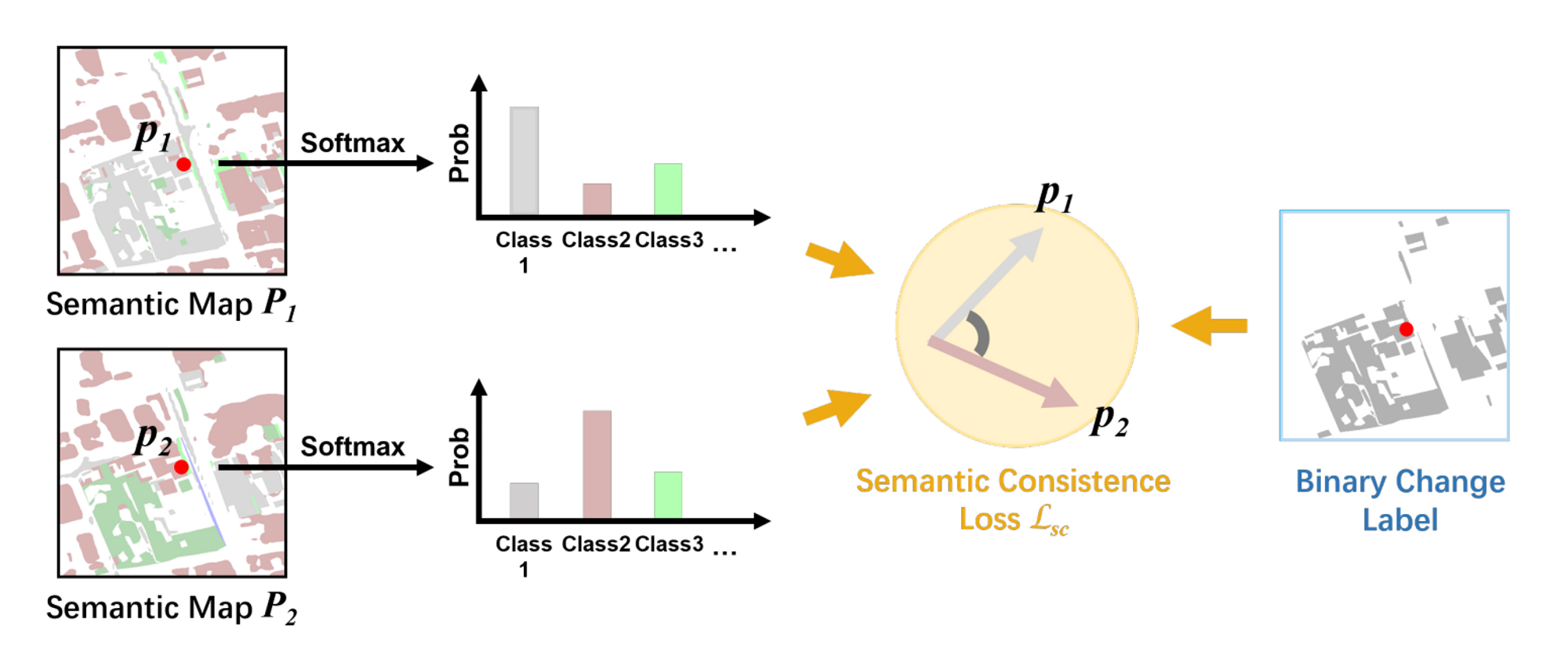
- segementation과 change detection 사이의 consistency를 늘리기 위한 regularization 정도로 이해할 수 있다.
- pre - post segmentation map에 대해 cosine 유사도를 측정하고 이를 기반으로 loss를 준다. cosine 유사도는 두 벡터 사이의 방향의 유사성을 측정하는 지표로, 두 벡터가 이루는 각의 cosine값이다.
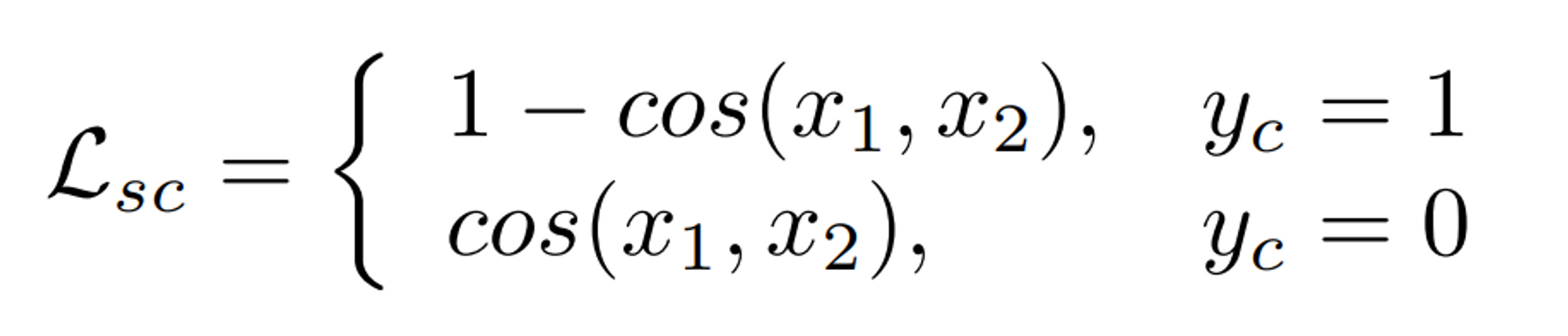
- x_1와 x_2는 각각 두 segmentation map에서 뽑아낸 feature vector이다.
- y_c는 semantic change label에서 뽑아낸 binary change label의 픽셀값이다. change된 경우 (흰 색으로 visualize) 1, unchange된 경우 (검은색으로 visualize) 0이다.
- 이를 기하적으로 해석해보면, change label 상에서 바뀐 부분에서는 두 feature vector가 유사하지 않을 수록 패널티를 부여하고 바뀌지 않은 부분에 대해서는 두 feature vector가 유사할수록 패널티를 부여한다는 것이다.
- 즉, 기존에는 change detection과 semantic segmentation을 잘 하기 위해서만 집중했다면, 두 task의 부드러운 연결을 위해 change된 지점에서는 두 scd map의 feature vector가 전반적으로 비슷하게, unchange된 지점에서는 두 scd map의 feature vector가 비슷하지 않게 regularize한다는 것이다.
Total Loss
-
semantic change detection 모델의 학습 과정에서는, 각 task에서 loss를 순차적으로 측정하고, 모든 task가 끝난 한 iteration마다 각 loss를 모두 더한 뒤 합친 loss에 대해 loss.backward()와 optimizer.step() 함수를 호출한다.
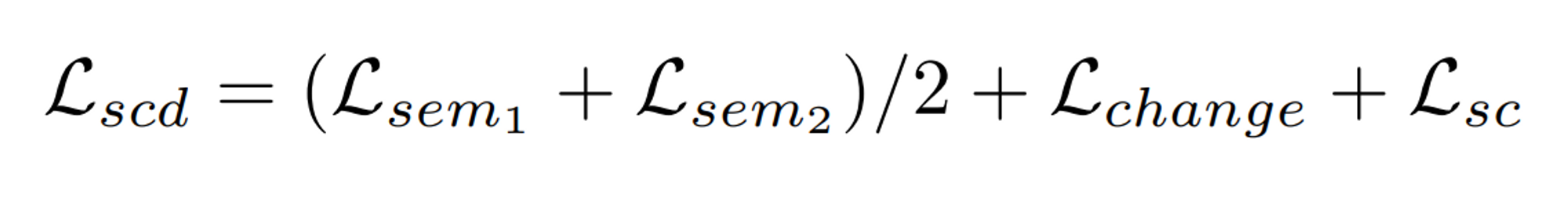
Metric
- 모델 성능 측정의 기준이 되는 지표들이다.
- 크게 change detection의 성능을 측정 / semantic segmentation의 성능을 측정 / semantic change detection 자체를 측정하는 3가지 방법으로 나누어 생각할 수 있겠다. ****
- 사용한 모든 metric들은 multi-class confusion matrix를 기반으로 계산된다.
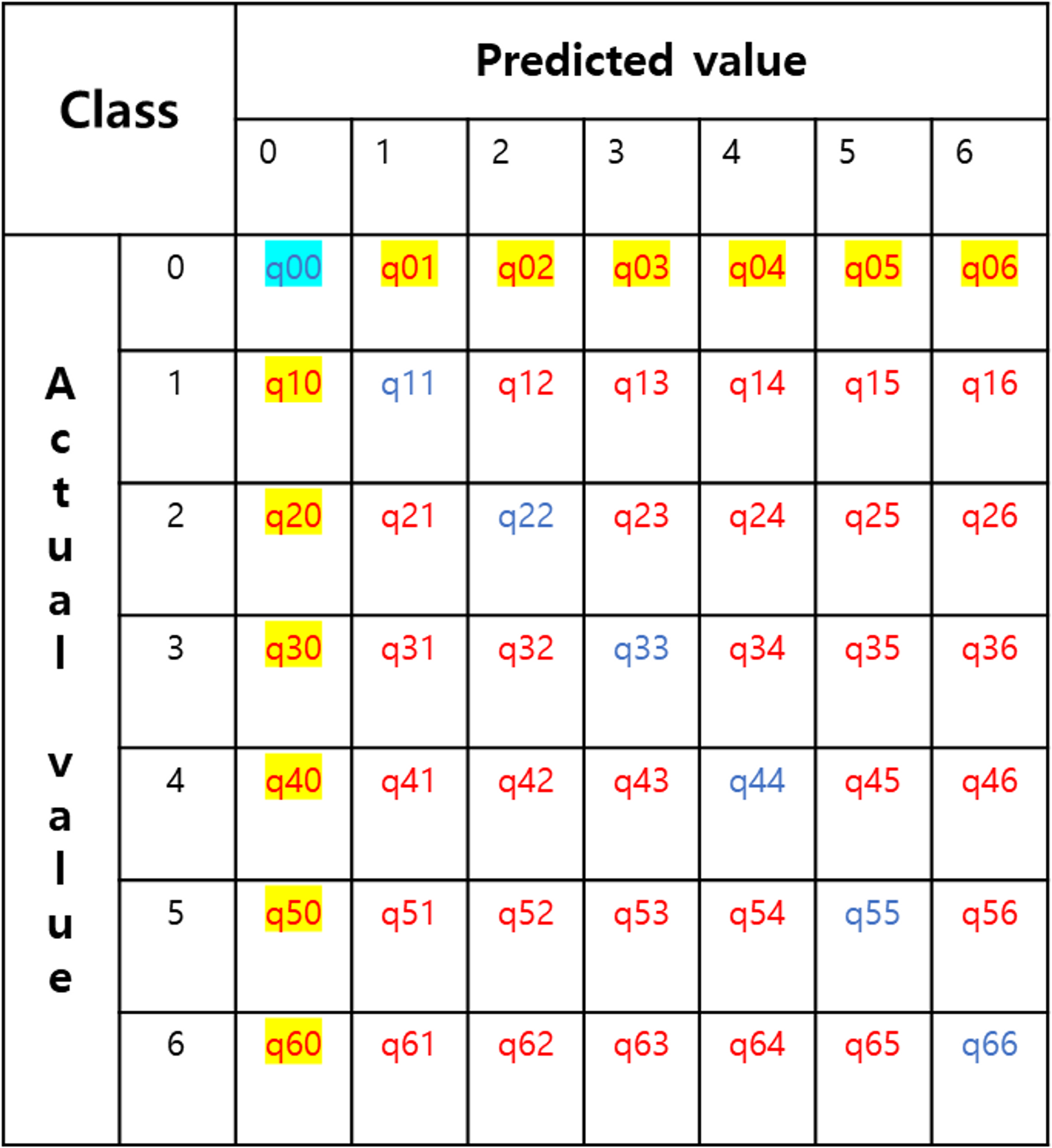
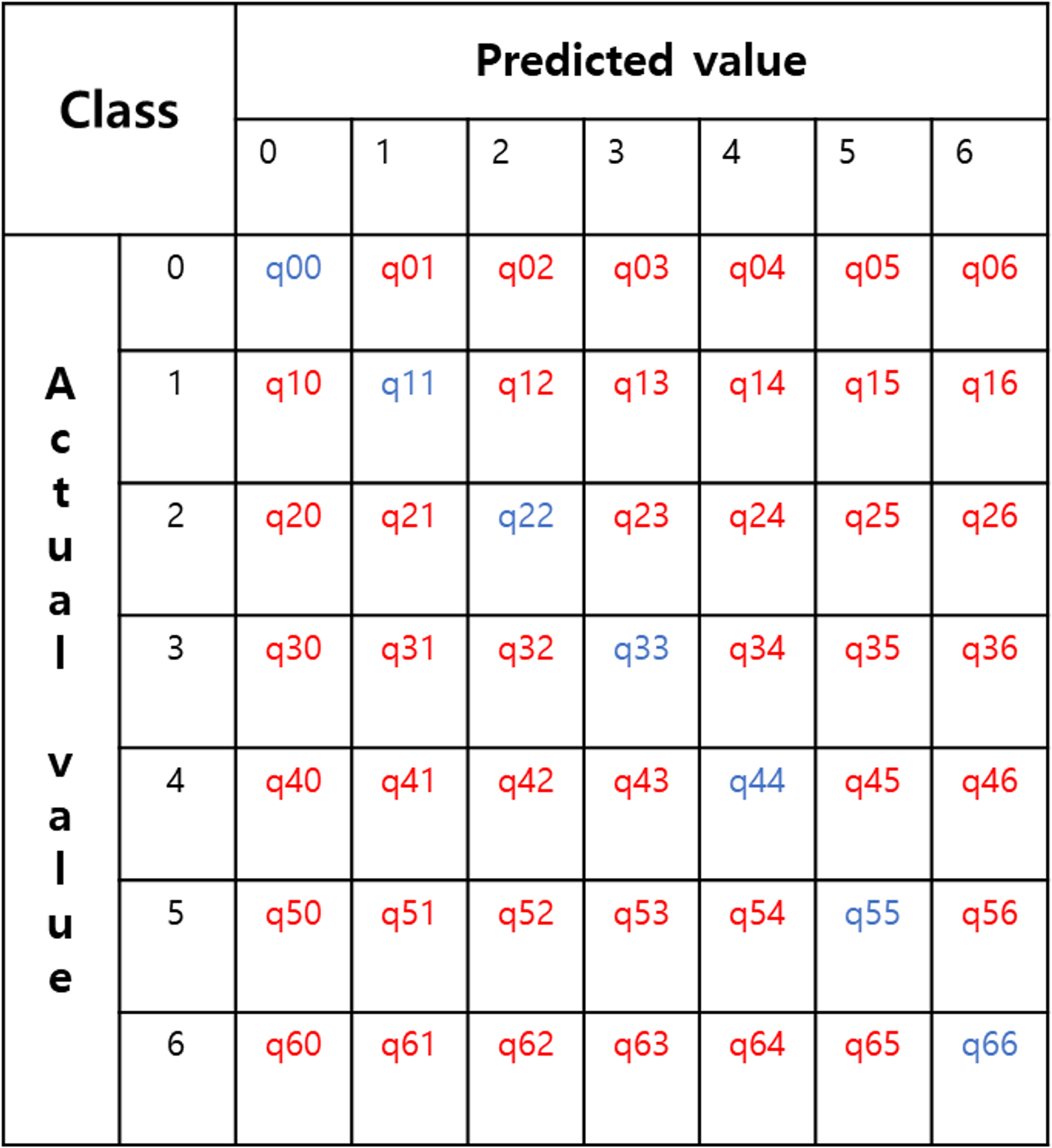 multi-class confusion matrix - 7 classes
multi-class confusion matrix - 7 classes
- segmentation class가 7가지라고 생각해보자. 이 때, 이미지를 픽셀 단위로 분류했을 때, predicted value 7가지, actual value 7가지로 총 49가지의 class로 분류 가능하다.
- 각 성분들은 해당 class에 속한 픽셀들의 개수를 나타낸다.
- SECOND라는 데이터셋의 0번 label은 ‘no-change’이다.
- confusion matrix의 주대각성분들은 옳게 예측한 경우이다. (Accuracy의 분자 성분이 될 것)
- 기타 성분들은 틀리게 예측한 경우이다.
- change detection의 성능 측정: F1-score
- F1 score: Precision과 Recall의 Harmonic Mean (note: change map은 한 pair에 대해 한 장)
- Binary change detection에서는, 픽셀을 2x2 confusion matrix로 분류 가능하기 때문에 일반적인 precision과 recall을 생각하면 됨. (TP, TN, FP, FN)
- semantic segmentation의 성능 측정: IoU
- IoU: semantic segmentation에서는 class 별로 groundtruth와 prediction 사이의 교집합 / 합집합을 구한다. 예를 들어 tree (0, 255, 0) class에 대한 IoU를 구한다면, prediction과 ground에서 겹치는 초록색 픽셀의 개수를 구하고, 각각의 픽셀 개수를 구해서 연산해주면 된다.
- 모든 class에 대해 산술평균을 구하면 mean IoU, 다만 이를 적용할 땐 class 간의 불균형은 고려하지 않는 계산임.
- semantic change detection의 성능 측정: OA, mIoU, F_scd, Kappa, SeK
OA
- overall accuracy, true 픽셀 개수(주대각성분 개수)를 이미지의 픽셀 개수로 나눈 것
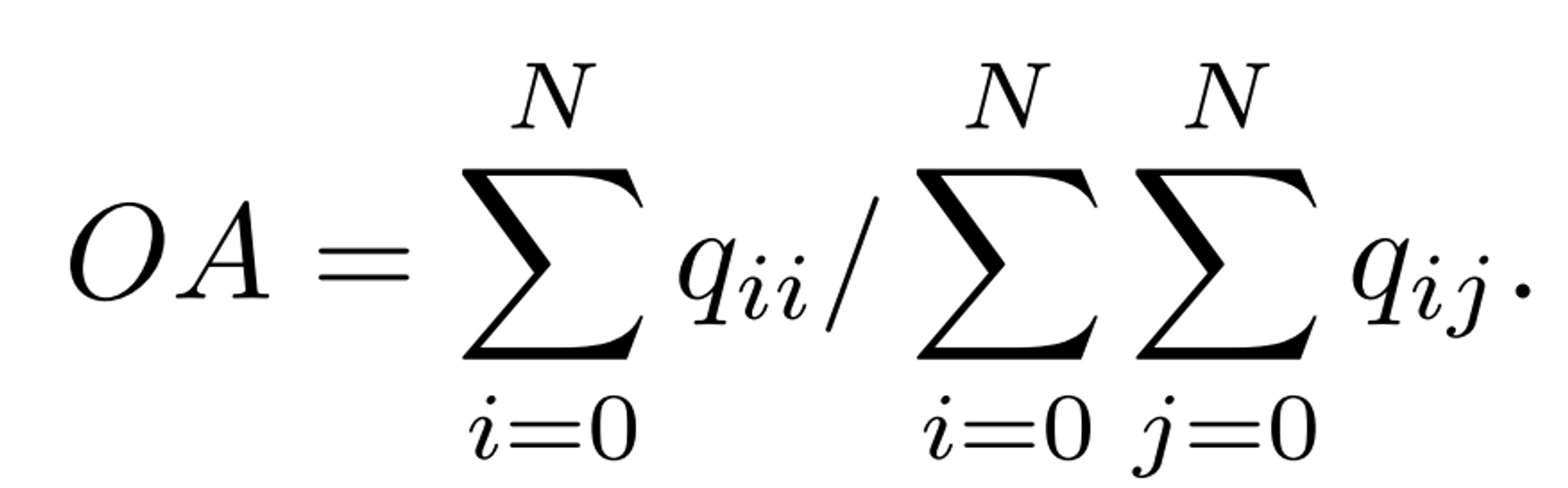
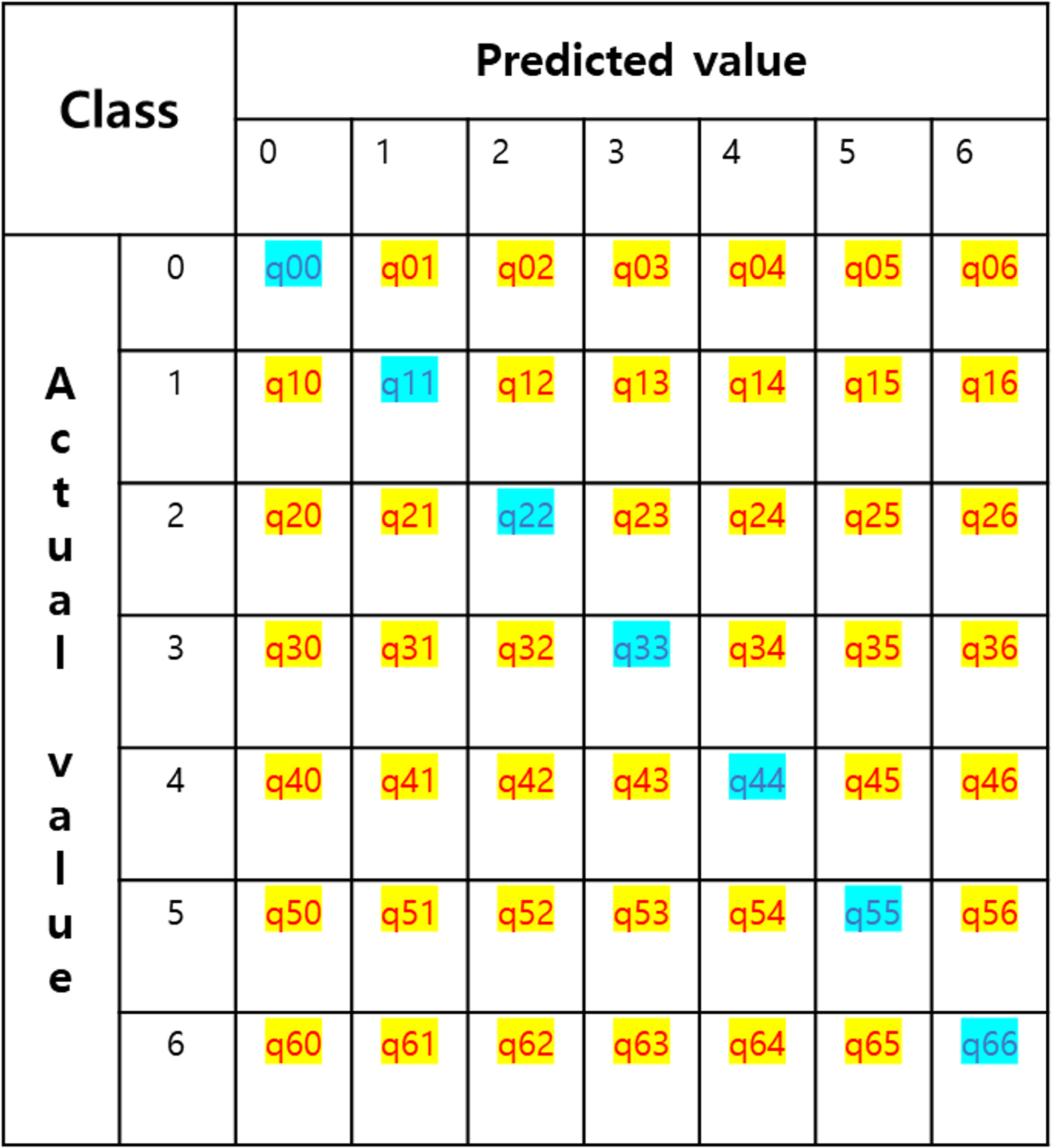 OA: (하늘색) / (하늘색 + 노란색)
OA: (하늘색) / (하늘색 + 노란색)
mIoU
- mean Intersection over Union, pre-IoU와 post-IoU의 평균값
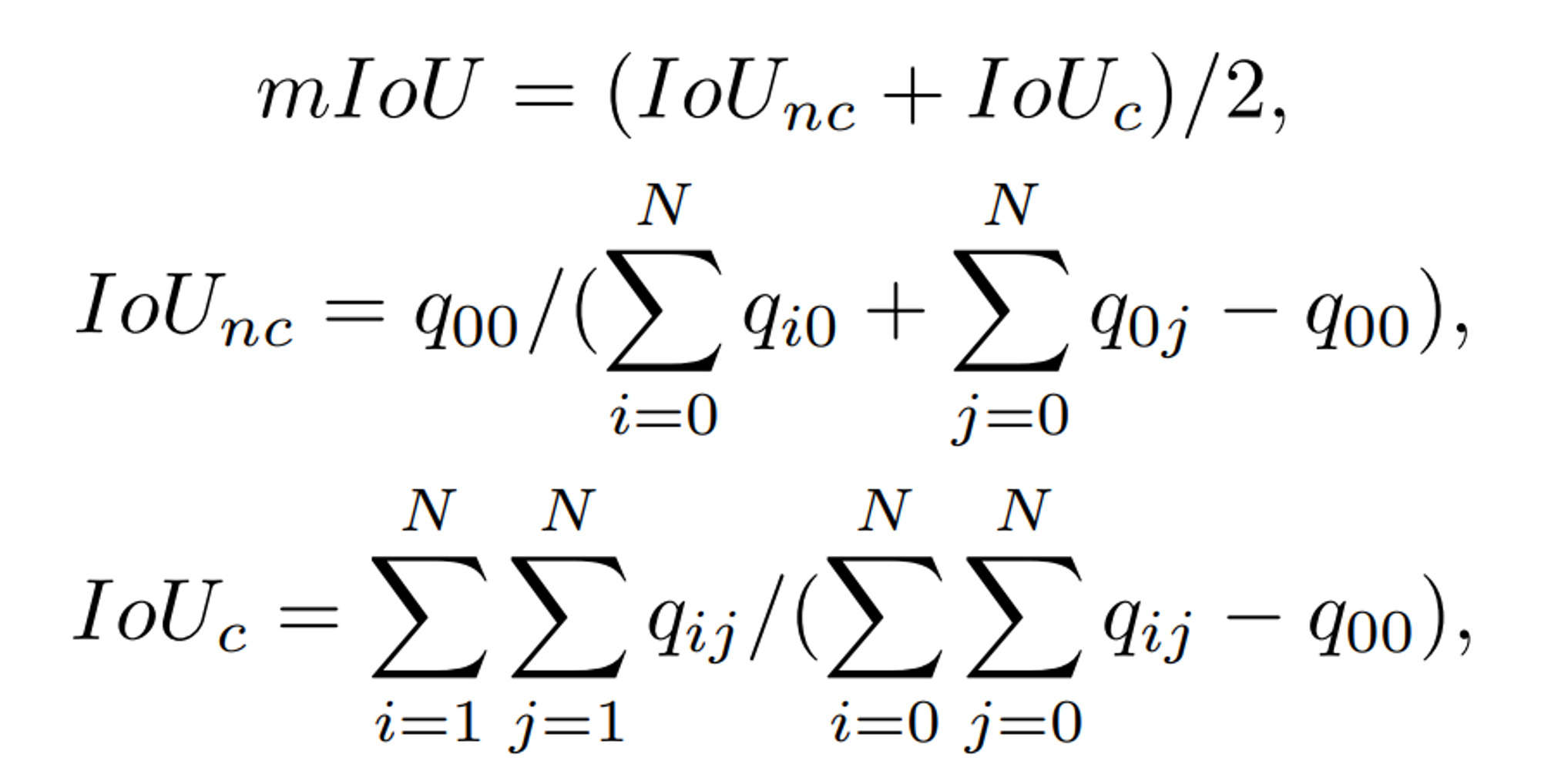
 IoU_nc: (하늘색) / (하늘색 + 노란색)
IoU_nc: (하늘색) / (하늘색 + 노란색)
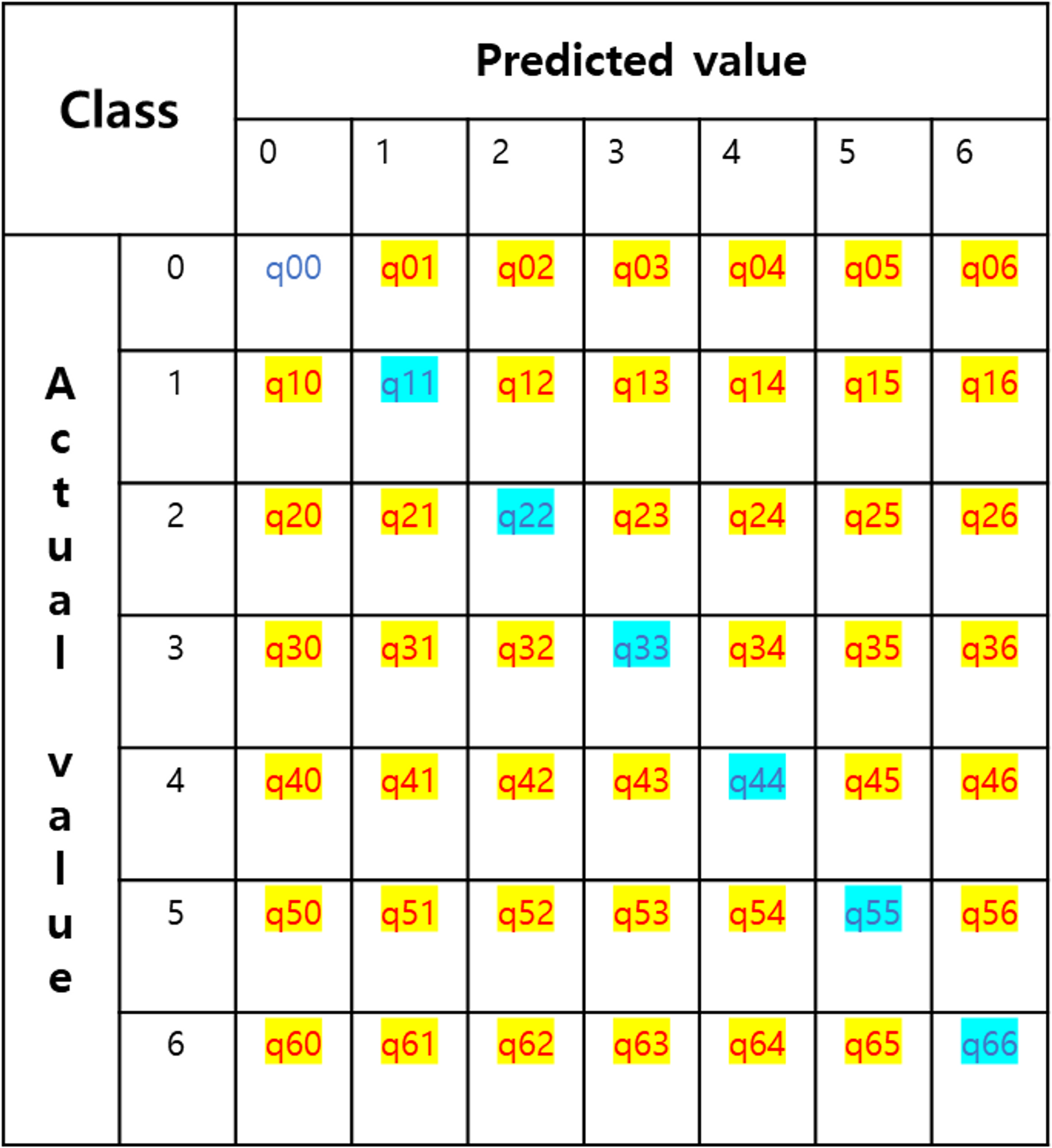 IoU_c: (하늘색) / (하늘색 + 노란색)
IoU_c: (하늘색) / (하늘색 + 노란색)
Kappa (Cohen’s Kappa)
- Kappa는 두 개 이상의 예측에 대해 예측 유사도를 판별하는 metric이다.
- confusion matrix를 이용한 Kappa는, actual value와 predicted value 사이의 유사도를 판별한다고 생각할 수 있다.
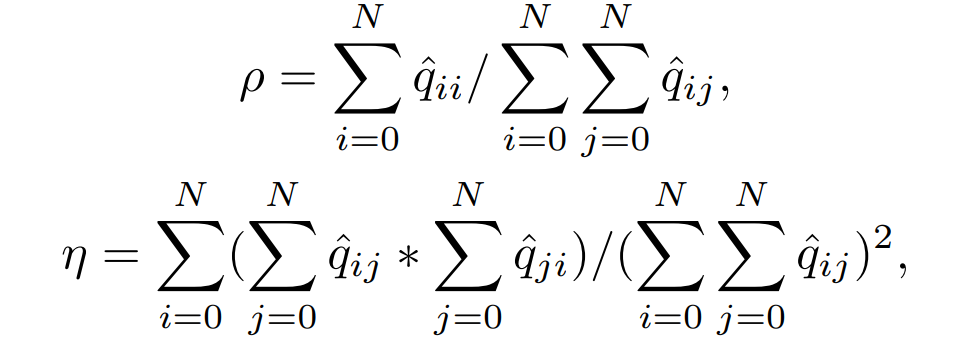
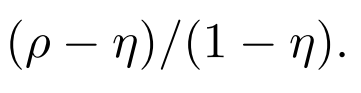
- 이 때 모델이 예측한 결과인 confusion matrix에서, 을 0으로 바꾼 pseudo-confusion matrix (q_hat)를 사용한다. 그 이유는, 실제로 데이터셋에서 0번 label, 흰색으로 표시된 픽셀들이 적지 않은 비중을 차지하는데(이는 성능 측정에 있어서 꽤 dominant하다.) no-change 픽셀들을 metric 계산에 있어서 배제하기 위함이다.
- 각 값들을 살펴보면, 우선 observed accuracy(rho)는 이 배제된, 즉 no-change label에 대한 true prediction이 배제된 것만 제외하면 평범한 OA이다.
- 그 뒤, expected accuracy(eta)는 false prediction들만 가지고 계산을 한다. expected accuracy 또는 random accuracy라고 이야기하는데, random prediction과 비교해서 모델의 예측 성능이 얼마나 나은지 평가한다.
- 이 두 값을 가지고 observed accuracy가 expected accuracy보다 얼마나 높은지를 반영하여 모델이 무작위 예측보다 얼마나 더 나은 성과를 보이는지를 평가한다. 다르게 말하면, Kappa의 분자는 우연에 의한 일치를 배제한 관찰자 사이의 일치도이고, Kappa의 분모는 우연에 의한 일치를 배제했을 때 획득 가능한 최대 일치도 (rho=1인 경우의)와의 비율이다. 따라서 우연에 의한 일치가 제외된 일치도로 해석할 수 있다.
- rho와 eta 모두 0~1 사이의 값을 갖는 확률들이고, 따라서 Kappa의 범위는 -1~1이다. 음수가 나올 수도 있음에 주의하자. 실제로 Bi-SRNet을 테스트해보면 음수값이 나오기도 한다.
- 두 관찰자 간에 판단이 완전히 일치하는 경우 kappa는 +1, 두 관찰자 간의 판단에서 rho가 eta보다 크다면 kappa는 0~1 사이의 양수 값을 가지고, eta가 더 크다면 -1~0 사이의 음수를 갖는다. 대체로 kappa가 0.7 이상이면 관찰자 간에 일치도가 좋은 것으로 평가한다.
SeK
- Separated Kappa - Kappa를 보정한 형태의 metric
- 기존 Kappa에 을 곱한 형태이다. 이 때 IoU는 change map의 IoU라는 것이 중요하다.
- 이 term을 추가하게 된 정확한 motivation은 모르겠지만, IoU까지 동시에 반영을 하면서 changed label에 대해서 잘 잡아내는지를 weight로 준 것 같다.
- IoU의 범위는 0~1이므로 SeK는 -1/e ~ 1/e 사이의 값을 가짐
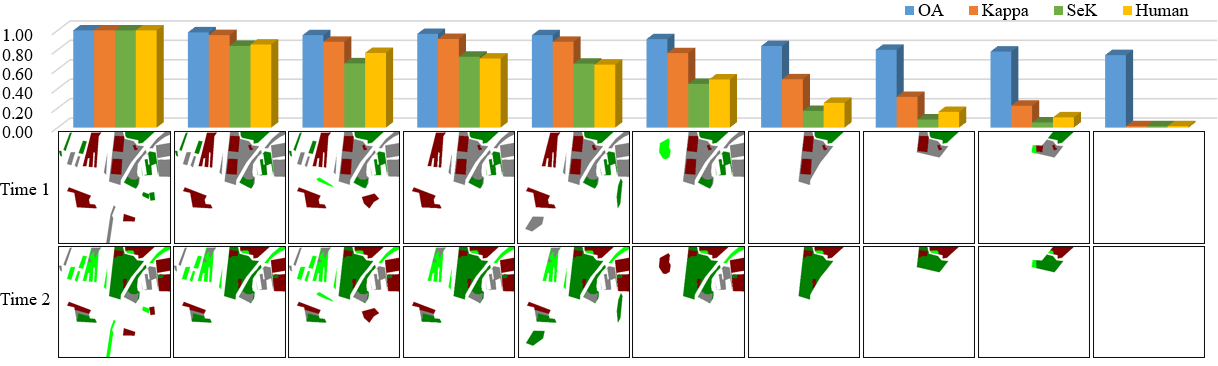
- 사람의 눈으로 평가한 정성적 결과와, Kappa보다는 SeK가 더 유사하다는 실험 결과가 있었다. 이를 통해, Kappa보다는 SeK가 더 합리적인 metric이라고 저자들은 주장한다.
F_scd
- multi-class에서의 precision과 recall을 생각하면 된다.
- no-change label에 대한 true predict는 배제한다. (즉 분모에 trace(Q)에서 q_00을 뺌)
- F_scd는 P_scd와 R_scd의 Harmonic Mean
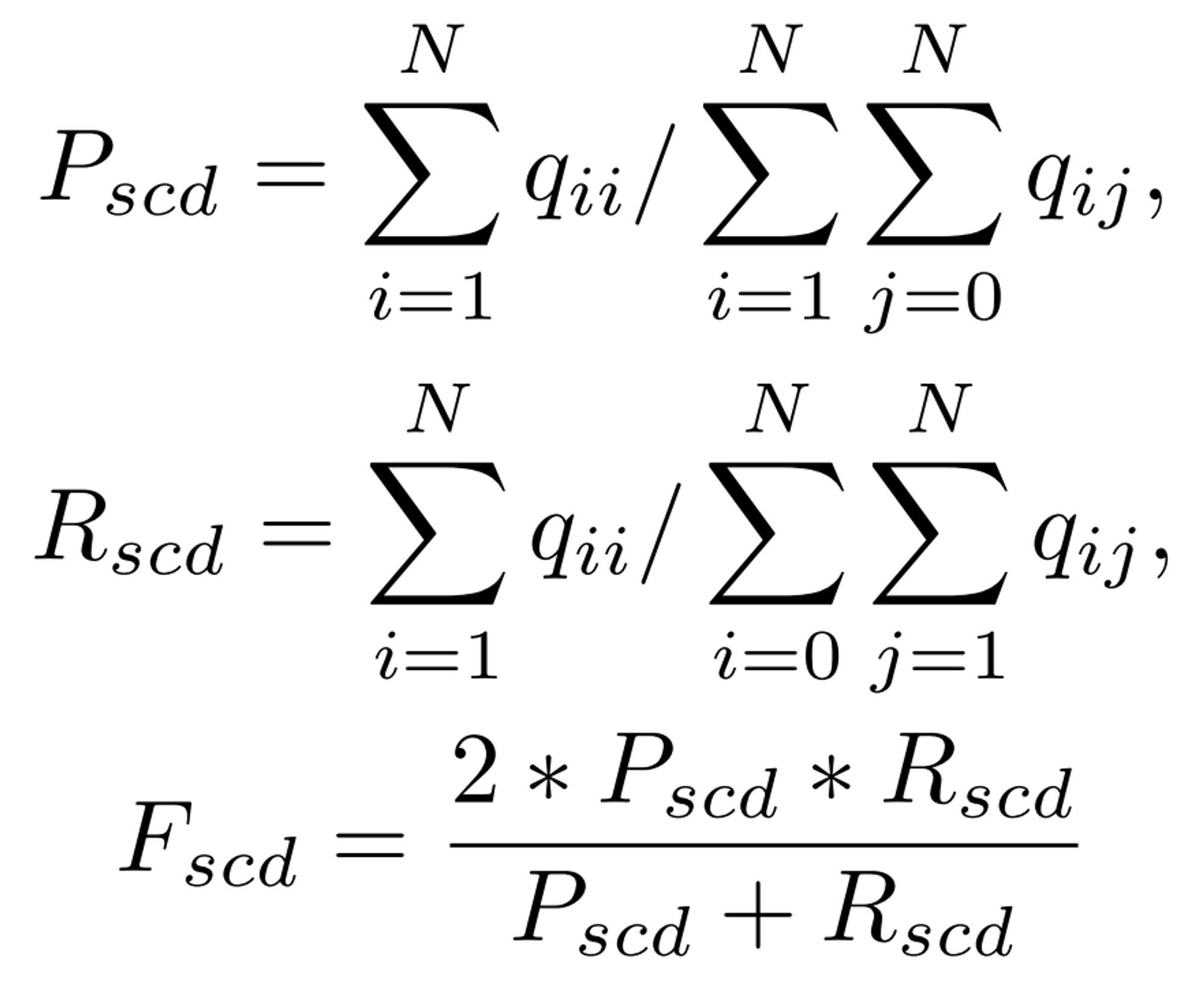
Reference
- Bi-Temporal Semantic Reasonng for the Semantic Change Detection in HR Remote Sensing Images (Bi-SRNet): https://arxiv.org/abs/2108.06103
- Denoising Diffusion Probabilistic Models (DDPM): https://arxiv.org/abs/2006.11239
- DDPM-CD: Remote Sensing Change Detection using Denoising Diffusion Probabilistic Models (DDPM-cd): https://arxiv.org/abs/2206.11892
- Label-Efficient Semantic Segmentation with Diffusion Models (DDPM-segmentation): https://arxiv.org/abs/2112.03126
- Cohen's Kappa: https://en.wikipedia.org/wiki/Cohen%27s_kappa

Master Student @ KAIST CS / Generative Modeling
글 재미있게 봤습니다.