✅ 서브쿼리
- 하나의
SQL 쿼리문 안에 포함된 또 다른SELECT 쿼리를 의미
메인쿼리 : 최종적으로 결과를 보여주는 쿼리
서브쿼리 : 메인쿼리 안에서 필요한 값을 먼저 계산·조회해 주는 쿼리
왜 서브쿼리를 사용할까? 예시를 보자
쇼핑몰에서 판매하는 상품들의 평균 가격보다 비싼 상품을 조회하라는 문제가 있다고 가정하자
이 문제를 해결하기 위해서는 이런식으로 해결할것이다
AVG집계함수를 사용하여 평균을 구하기
SELECT AVG(price) FROM products; - 나온 평균값을 WHERE 뒤에 조건을 넣기
SELECT *
FROM products
WHERE price > 평균값;이렇게 두번의 쿼리를 통해 원하는 결과를 얻을 수 있지만
매번 이렇게 쿼리를 실행하면 번거롭고, 1단계와 2단계의 쿼리를 실행하는 순간에도 값이 변할 수 있어서
데이터를 잘못 조회할 수도 있다
이러한 이유로 하나의 작업 단위로 묶기 위해서 서브쿼리 를 사용한다
✅ 서브쿼리의 종류
- 단일행 서브쿼리 (스칼라 서브쿼리)
- 다중행 서브쿼리
- 다증컬럼 서브쿼리
- 상관 서브쿼리
- SELECT 서브쿼리
- 테이블 서브쿼리
✅ 단일행 서브쿼리 (스칼라 서브쿼리)
- 서브쿼리를 실행했을 때, 결과가 오직
하나의 행과 컬럼으로 나오는 경우 - 결과가 하나의 값이기 때문에 비교 연산자 ( = > < >= <= <>) 과 함께 사용할 수 있다
💡 스칼라 : 수학용어로 '단 하나의 값' 을 의미
EX) 특정 주문을 (order_id = 1) 인 고객과 같은 도시에 사는 모든 고객을 찾기
우선 서브쿼리 없이 1,2 단계로 문제를 해결하기
- order_id 가 1인 고객의 도시 알아내기
SELECT u.address
FROM users u
JOIN orders o ON u.user_id = o.user_id
WHERE o.order_id = 1; - 해당 도시에 사는 모든 고객 찾기
SELECT name, address
FROM users
WHERE address = 고객의 도시;위 단계처럼 두개의 단계를 서브쿼리로 해결할 수 있다
SELECT name, address
FROM users
WHERE address = (SELECT u.address
FROM users u
INNER JOIN orders o ON u.user_id = o.user_id
WHERE o.order_id = 1);이처럼 서브쿼리를 사용하면 여러 번의 쿼리를 하나로 합쳐서 코드를 간결하게 하고
애플리케이션과 데이터베이스의 통신 횟수를 줄여 성능상 이점을 얻을 수 있다
하지만 서브쿼리의 결과가 반드시 하나의 행만 반환해야만 쿼리가 정상적으로 동작된다
만약 두개 이상의 행을 반환하는 서브쿼리라면?
Subquery returns more than 1 row 에러를 발생시키며 실행을 멈춘다
✅ 다중행 서브쿼리
- 서브쿼리의 결과가
다중 행하나의 컬럼으로 반환될 때 사용 - 다중행 서브쿼리의 결과를 처리하기 위해서는
=와 같은 단일 행 연산자가 아닌
목록을 다룰 수 있는INANYALL을 사용한다
IN 은 목록에 포함된 값과 일치하는지 확인하는 연산자로
가장 흔하게 사용되며, 특정 컬럼의 값이 목록 중 하나라도 일치하면 참을 반환
IN 의 예시는 위에 단행일 서브쿼리와 예시와 비슷함
ANY : 목록의 일부 값과 비교
ALL : 목록의 모든 값과 비교
ALL 과 ANY 는 비교 연산자와 함께 사용되며, 서브쿼리가 반환한 여러 값들과 비교하는 역할을 함
> ANY : 서브쿼리가 반환한 여러 결과값 중 어느 하나보다만 크면 참 = 최소값보다 크면 참
> ALL : 서브쿼리가 반환한 여러 결과값 모두보다 커야만 참 = 최대값보다 커야 참
< ANY : 최대값보다 작으면 참
< ALL : 최소값보다 작으면 참
= ANY : IN 과 완전히 동일한 의미 = 목록 중 어느 하나와 같으면 참
EX) 전자기기 카테고리의 어떤 상품보다도 비싼 상품을 찾기
SELECT name, price
FROM products
WHERE price > ANY (SELECT price FROM products WHERE category = '전자기기');서브쿼리의 결과가 (75000, 12000, 35000, 28000) 의 가격 목록을 반환된다
즉 위 결과는 WEHRE price > 75000 의 결과와 동일하다
실무에서는 ANY 와 ALL 보다는 MIN 과 MAX 를 더 많이 사용한다
코드를 더 이해하기 쉽기 때문이다
위 예시를 MIN 으로 사용하여 바꾸면
SELECT name, price
FROM products
WHERE price > (SELECT MIN(price) FROM products WHERE category = '전자기기');✅ 다중컬럼 서브쿼리
- 서브쿼리의 조회 값 중 컬럼이
두개이상이 포함되는 경우를 말한다 - 이 기법은 메인쿼리의
WHERE절에서 여러 컬럼을 동시에 비교해야할 때 유용
EX) 한 쇼핑몰의 고객이 주문한 주문ID가 있다 (order_id = 3)
이주문과 동일한 고객이면서 주문 처리 상태도 같은 모든 주문을 찾기
- 비교 기준이 될 고객 ID와 주문상태를 조회
SELECT user_id, status FROM orders WHERE order_id = 3; // 2개의 열(컬럼) 이 조회됨- 다중 컬럼 비교
SELECT order_id, user_id, status, order_date
FROM orders
WHERE (user_id, status) = (SELECT user_id, status // WHERE 절에 비교할 컬럼들을 괄호로 묶어서 비교
FROM orders
WHERE order_id = 3);서브쿼리의 결과값이 (2, 'SHIPPED') 라고 조회됬을 때 위 결과는
WHERE user_id = 2 AND status = 'SHIPPED' 와 논리적으로 같다.
위 예시는 하나의 행일 경우의 예시이며
두개이상의 행일 때는 IN 연사자를 사용하여 동일하게 처리하면 된다
✅ 상관 서브쿼리
- 서브쿼리를 독립적으로 실행할 수 없음
- 메인쿼리와 서브쿼리가 서로 '연관' 관계를 맺고 동작하는 서브쿼리
💡 상관 : 메인쿼리와 서브쿼리가 서로 영향을 준다는 뜻
위에서 나왔던 서브쿼리들은 독립적으로 단 한번 실행된 후 그 결과를 메인쿼리에 사용했다
그 서브쿼리들을 비상관 서브쿼리라고 한다
하지만 상관 서브쿼리 는 다음과 같이 동작한다
1. 메인쿼리가 한 행을 읽는다
2. 읽혀진 행의 값을 서브쿼리에 전달하여, 서브쿼리가 실행된다
3. 서브쿼리 결과를 이용해 메인쿼리의 WHERE 조건을 판단한다
4. 메인쿼리가 다음 행을 읽고, 그 과정을 반복한다
즉 서브쿼리가 메인쿼리의 행 수만큼 반복 실행된다
아래 예제를 보면서 확인하자
각 상품별로, 자신이 속한 카테고리의 평균 가격 이상의 상품들을 찾기
이 문제의 핵심은
전체 평균 가격이 아닌, 자신이 속한 바로 카테고리의 평균 가격과 비교해야 한다는 점이다
이처럼 서브쿼리가 메인쿼리에서 처리중인 특정 값을 알아야한 계산을 수행할 수 있을 때
상관서브쿼리 를 사용해야 한다
정리하면 메인쿼리의 각 행마다 다음 서브쿼리를 실행해야 한다
{catrgory} 값은 메인쿼리의 각 행마다 다른 category 값을 사용해야한다
SELECT AVG(price) FROM products WHERE category = {category}
위 문제를 해결하면
select product_id,
name,
category,
price
from
products p1
where price >= (select AVG(price)
from products p2
where p2.category = p1.category);여기서 가장 중요한 부분은 WHERE p2.category = p1.category 이다
서브쿼리에서 비교하는 부분을 메인쿼리의 p1.category 를 대상으로 하고 있다
이부분이 바로 연관 의 핵심이다
p1 한행 읽음
↓
그 행의 category 확인
↓
같은 category 평균 가격 구함
↓
p1의 price >= p1 카테고리의 평균가격 비교동작순서는 메인쿼리의 각 행을 수 만큼 서브쿼리를 반복하여
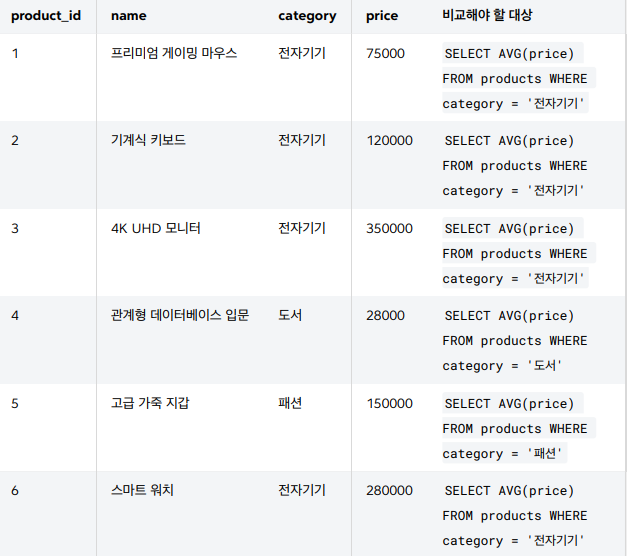
WHERE 75000 >= 206250
WHERE 120000 >= 206250
WHERE 350000 >= 206250
WHERE 28000 >= 28000
... 이런식으로 반복된다
하나의 문제를 더 풀어보자
한번이라도 주문된 상품 조회하기
이 문제를 일반 서브쿼리 문제로 해결하면 아래와 같이 해결이 가능하다
select * from products p
where p.product_id in (select product_id // IN으로 해결한 방법
from orders o
where order_id is not null);이렇게 IN 방식으로 문제를 해결하면 원하는 결과를 직관적으로 얻을 수 있다
하지만 주문 테이블(orders) 테이블의 로우 개수가 수천만, 수억 건이 넘으면 성능상 문제가 생긴다
그럴 때는 EXISTS 를 사용하면 더 효율적이다
EXISTS 는 서브쿼리 결과 행이 1개 이상이면 TRUE , 0개이면 FALSE 가 된다
즉 EXISTS 는 서브쿼리가 반환하는 결과값 자체에는 관심이 없고 서브쿼리의 결과로
행이 하나라도 존재하는지의 여부만 체크한다
💡 반대로 특정 조건의 데이터가 존재하지 않는 것을 확인하고 싶을 때는 NOT EXISTS 를 사용
select *
from products p
where exists ( // EXISTS 로 해결한 방법
select 1
from orders o
where o.product_id = p.product_id); // 메인쿼리의 행 수만큼 서브쿼리를 반복위 방법은 o.product_id = p.product_id 라는 조건이 있으며, 서브쿼리가 독립적으로 실행되지않고
메인쿼리의 p 테이블의 값 (p.product_id) 에 의존하여 실행되고 있으므로 상관 서브쿼리 방식이다
서브쿼리의 SELECT 1 은 서브쿼리의 결과값이 의미가 없고, 행이 존재하는지 여부만 보기때문에
관례적으로 1 과 같은 상수를 사용해서 불필요한 데이터 조회를 피하는 것이 좋다
예를들어 product_id 가 1인 주문이 10000개가 존재해도, 1개만 먼저 발견하면 바로 TRUE 를 리턴하기 때문에 나머지 9999개를 찾지 않아도 되는 효율을 갖고 있다
그럼 실무에서의 IN vs EXISTS 중 언제 사용해야하나?
IN 의 경우 서브쿼리의 결과 데이터의 개수가 작을 때 사용하는 것이 좋고
EXISTS 의 경우 서브쿼리의 결과 데이터가 클때와 메인쿼리의 행 수가 적을 때 효율적이다
✅ SELECT 서브쿼리
- 서브쿼리를 SELECT 절에다 사용
- 서브쿼리는 필터용이 아닌, 그 자체가 하나의 컬럼처럼 동작
- 하나의 행과 하나의 컬럼을 반환하는
스칼라 서브쿼리를 사용해야 한다
SELECT 서브쿼리 에서도 비상관, 상관 서브쿼리로 나눌 수 있다
우선 비상관 서브쿼리 의 경우
모든 상품 목록을 조회하는데, 각 상품의 가격과 함께 전체 상품의 평균 가격을 모든 행에 함께 표시
여기서 전체 상품의 평균 가격은 어떤 특정 상품 행에 종속되는것이 아니라, 모든 상품에 대해
동일하게 적용되는 고정 값이다
SELECT
name,
price,
(SELECT AVG(price) FROM products) AS avg_price // 모든행에 대한 고정값
FROM products;이렇게 비상관 서브쿼리로 작성하는 경우
데이터베이스는 메인서브쿼리를 실행하기 전에, SELECT 절의 서브쿼리를 단 한번 먼저 실행한다
그 값을 기억해뒀다가 메인쿼리를 실행하고 각 행을 가져올때마다 값들을 추가해준다
하지만 상관 서브쿼리 의 경우는 어떨까?
전체 상품 목록을 조회하면서, 각 상품별로 총 몇 번의 주문이 있었는지 '총 주문 횟수' 표시
이 문제는 각 행마다 주문 횟수 값이 달라져야 한다
SELECT
p.product_id,
p.name,
p.price,
(SELECT COUNT(*) FROM orders o WHERE o.product_id = p.product_id) AS order_count
FROM products p;여기서 WHERE o.product_id = p.product_id 이 부분은 메인쿼리 테이블인 p에 종속받고 있기 때문에
상관서브쿼리이다
위에서도 말했지만, 상관서브쿼리의 경우 메인 쿼리가 반환하는 행의 수만큼 반복 실행하기 때문에
메인쿼리의 행의 수가 많으면 성능저하가 일어날 수 있다
지금까지 서브쿼리는 WHERE 절에서는 동적필터로 SELECT 절에는 새로운 컬럼으로 추가되는 것을
확인하였다. 이번에는 FROM 절에서 사용하는 방법을 알아본다
✅ 테이블 서브쿼리 (인라인 뷰)
FROM절에 위치하는 서브쿼리로, 실행결과가 마치 하나의 독립된 가상 테이블처럼 사용됨FROM절에 들어가는 서브쿼리는 반드시 별칭을 붙여줘야 활용이 가능하다- 복잡한
SELECT문의 결과를 하나의 명확한 데이터 집합으로 만들어놓고, 그 집합을 대상으로
다시 한번SELCET할 수 있게 해준다
EX) 각 상품 카테고리별로, 가장 비싼 상품의 이름과 가격을 조회
SELECT p.product_id,
p.name,
p.price
FROM products p
JOIN ( // 원본테이블과 가상테이블을 조인
SELECT category,
MAX(price) AS max_price // 카테고리별 최고가격을 서브쿼리로 미리 구하기
FROM products
GROUP BY category) AS cmp // cmp 라는 임시 테이블을 메모리에 생성
ON p.category = cmp.category AND p.price = cmp.max_price;위 쿼리의 동작방식은 다음과 같다
데이터베이스에서 FROM 절의 서브쿼리(인라인 뷰)를 먼저 실행 후, cmp라는 임시테이블을 메모리에 생성
그 다음 메인쿼리가 실행되면서, 상품테이블과 임시테이블을 조인하여
임시테이블의 값으로 필터를 할 수 있다
그럼 실무에서의 JOIN 과 서브쿼리 중 어떤것을 사용해야 좋을까?
정확한 답은 없지만 이러한 가이드로 진행하자
JOIN을 우선 고려
일반적으로 데이터베이스는 JOIN이 서브쿼리 보다 성능이 더 좋거나, 최소한 동일한 경우가 많다
JOIN으로 표현하기 복잡하거나,서브쿼리의 가독성이 더 좋을 땐서브쿼리로 사용
성능이 중요하지 않은 쿼리의 경우, 동료가 이해하기 쉬운 코드를 작성하는것이 좋다
EXISTS를 활용
서브쿼리를 활용할 때 IN 연산자 대신 EXISTS 를 사용하면 더 효율적으로 동작할 때가 있다
- 성능의 의심될 때는 측정하기
JOIN 서브쿼리 등 여러 방법으로 쿼리를 작성해보고, EXPLAIN 과 같은 도구로 실행시간을 측정하자
