앞서 하나의 컬럼으로 구성된 단일 인덱스 에 대해서 정리했다
이번에는 여러 조건을 조합하여 쿼리의 성능을 최적화하는 다중 컬럼 인덱스 다른 말로 복합 인덱스 를 정리하겠다
✅ 다중컬럼 인덱스 : 두 개 이상의 컬럼을 묶어서 하나의 인덱스로 만드는 것
다중컬럼 인덱스 원칙 3가지
- 인덱스는 순서대로 사용하기
- 등호(=) 조건을 앞으로, 범위(>, <) 조건은 뒤로 보내기
- 정렬(ORDER BY)도 인덱스의 순서를 따르기
ex) category와 price 순으로 복합 인덱스 생성하기
CREATE INDEX idx_items_category_price ON items (category, price);
이렇게 인덱스를 생성하고 조회하면 -> SHOW INDEX FROM items;
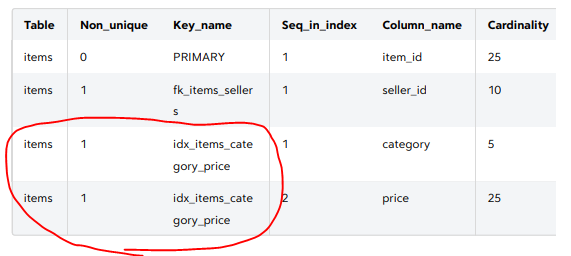
사진과 같이 2개의 인덱스가 생성된것을 볼 수 있다 여기서 Seq_in_index 는 컬럼 순서이다
이제 복합 인덱스를 사용하는 조회 쿼리를 날려보자
카테고리가 '전자기기'이면서, 가격이 정확히 120,000원인 상품을 찾기
EXPLAIN SELECT * FROM items WHERE category = '전자기기' AND price = 120000;
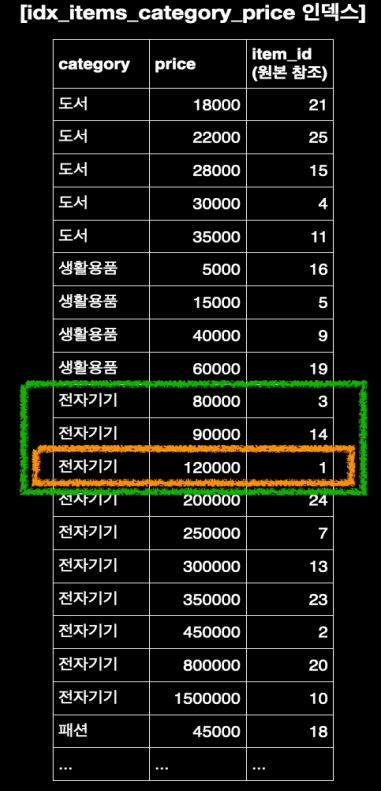
사진처럼 인덱스를 생성할 때 Category와 price 순으로 이미 정렬이 되어있다
만약 category가 동일하면 price 순으로 정렬이 된다
카테고리가 전자기기 인 섹션을 찾고, 그 안에서 price 가 12000 인 지점을 탐색하게 된다
전자기기 섹션 내부에 이미 price 순으로 정렬되어 있어서, 데이터를 빠르게 접근할 수 있다
만약 그러면 카테고리가 '전자기기'이면서 100,000원 초과인 상품을 가격 오름차순으로 정렬
가격 순으로 정렬해서 조건을 추가해서 EXPLAIN 하면 어떻게 될까?
EXPLAIN SELECT * FROM items WHERE category = '전자기기' AND price > 100000 ORDER BY price;
-> category = '전자기기' 인 것들을 찾음 -> '패션' 전 까지만 찾음 -> 그 찾은것들 중에서 가격 100000 찾기 -> 찾은 가격보다 비싼 데이터들만 찾기 -> 가격 순으로 정렬 = 이미 정렬이 되어있음
이미 인덱스가 생성될 때 price 순으로 이미 정렬되어 있기 때문에, Using filesort 가 보이지 않는다
하지만 만약 인덱스의 순서와 무관한 컬럼으로 정렬을 하면? => ORDER BY stock_quantity
그러면 결과를 가져온 뒤 별도로 정렬해야하는 불필요한 작업을 해야한다
이번에는 복합 인덱스를 실패하는 경우를 알아보겠다
첫번째로 인덱스 순서 무시 상황이다
만약 복합 인덱스의 첫번째 컬럼인 category를 건너뛰고, 두번째 컬럼인 price 만으로 데이터를 검색하면
어떻게 될까? => 카테고리와 상관없이 가격이 80,000원인 상품을 찾기
EXPLAIN SELECT * FROM items WHERE price = 80000;
결과는 인덱스가 있음에도 옵티마이저는 풀 테이블 스캔 을 선택한다
그 이유는 인덱스 왼쪽 접두어 규칙 때문이다.
가격이 80000인 상품은 '전자기기' 에도 ' 패션' 에도 존재할 수 도 있기 때문이다
price 값이 인덱스 전체에 흩어져 있기 때문이다
결국 데이터베이스 입장에서 price 만으로 데이터를 찾으려면, '도서' 카테고리부터 '패션' 카테고리 까지
모든 섹션을 다 뒤져봐야한다. 이는 인덱스 전체를 스캔하는 작업으로, 차라리 풀 테이블 스캔이 나을것이다
쉽게말하면 전화번호부에서 성은 모르지만 이름이 '주영' 이라는 사람을 찾으려면
성이 ㄱ부터 ㅎ까지 다 찾아봐야 하는 경우이다. 이처럼 복합인덱스는 선행 컬럼 조건 없이는 제 역할을 하지 못한다
💡 (category, price) 이렇게 두개의 복합 인덱스를 만들면 (categry) 의 단일 인덱스를 만들 필요 없음
-> 이미 복합인덱스에서 category를 기준으로 정렬이 되어있기 때문이다
두번째 실패하는 경우
범위 조건을 먼저 사용 하는 경우이다
선행컬럼에 범위조건을 사용하면 그 뒤에오는 컬럼은 인덱스를 제대로 활용할 수 없다
카테고리명이 '패션' 이상인 상품들 중에서, 가격이 정확히 20,000원인 상품을 찾기
라는 조건이 있다고 가정하자
EXPLAIN SELECT * FROM items WHERE category >= '패션' AND price = 20000 와 같이 작성할 것이다
이것을 실행하면 카테고리가 이름순으로 패션보다 같거나 큰 카테고리 들로 1차 필터링을 한다
하지만 각 카테고리마다 가격들이 정렬되어있기 때문에 두번째로 나와있는 price는 인덱스를 사용하지 않고 직접 price = 20000 을 필터링해서 하나하나 검사한다
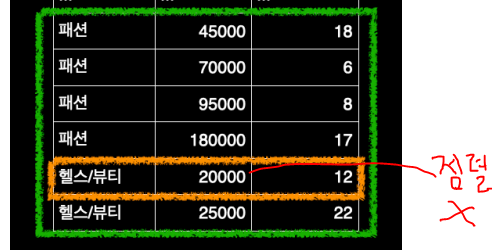
따라서 인덱스를 설계할 때는 = 조건으로 사용될 컬럼을 범위 조건으로 사용될 컬럼보다
앞에 배치하는것이 최적화 전략이다
ex) CREATE INDEX idx_items_price_category_temp ON items (price, category);
위 예시처럼 price가 동등조건이기 때문에 인덱스를 생성할 때 첫번째 컬럼으로 넣으면 된다
위에서 원칙 중 2번째 원칙에 해당한다 (등호(=) 조건은 앞으로, 범위조건은 뒤로)
하지만 이방법도 있지만 실무에서는 IN 절을 활용하여 많이 해결한다
WHERE category >= "패션" 이 부분을 WHERE category IN ('패션', '헬스/뷰티') 로 바꾸면 된다
왜냐하면 IN 절은 여러 개의 개별 지점에 대해 동등(=) 비교의 묶음으로 처리되기 때문이다
✅ 인덱스 설계 가이드라인
첫 번째로
인덱스를 만들때 중요한 것은, 어디에 인덱스를 만들어야 하는지 아는 것이다
잘못된 인덱스는 오히려 시스템 성능을 떨어뜨릴 수 있다
인덱스를 어디에 걸지 판단하는 가장 중요한 기준은 카디널리티 이다
카디널리티 는 컬럼에 저장된 값들의 고유성 을 나타내는 지표로
EX) category 컬럼에 '도서' '패션' '운동' '차량' 이렇게 있다면 카디널리티 는 4이다
EX) is_active 컬럼에 'true' 'false' 이렇게 있다면 카티널리티 는 2이다
이 카티널리티 가 높은 컬럼에 생성하는 것이 좋다
왜냐하면, 특정키워드를 찾았을 때 검색범위가 확 줄어야 효율적이므로
비교하는 대상의 값이 여러개로 분포되어있어야 한쪽에 몰리지 않기 때문이다
만약 where is_active = true 의 데이터가 전체의 80%라고 가정하면
is_active 컬럼에 인덱스가 있더라도 풀테이블 스캔이 나을수도 있다
💡 카디널리티 높다 = 중복도가 낮다
두 번째로
JOIN 의 연결고리가 되는 컬럼(외래키) 에 인덱스를 생성해야한다
EXPLAIN SELECT
s.seller_name,
i.item_name,
i.price
FROM items i
JOIN sellers s ON i.seller_id = s.seller_id
WHERE s.seller_name = '행복쇼핑';위 예제를 보면 seller_id 컬럼을 대상으로 조인이 되고 있다
MYSQL 에서는 외래키 제약조건을 설정하면 자동으로 외래키 인덱스가 생성된다
하지만 ORACLE의 경우 자동으로 생성되지 않는다
💡 PK는 ORACLE, MYSQL 둘다 자동으로 인덱스가 생성됨
현재 sellers 테이블의 pk가 seller_id 이고 items 테이블의 fk가 seller_id 이다
따라서 oracle의 기준으로 조인을할때 풀테이블 스캔을 피하기 위해서 외래키 인덱스를 생성해줘야한다
CREATE INDEX idx_items_seller_id ON items(seller_id); : 외래키 인덱스 생성 (JOIN용 = 자식테이블)
추가로 WHERE 절에 seller_name 컬럼도 인덱스를 추가해줘야한다
CREATE INDEX idx_sellers_name ON sellers(seller_name); : WHERE 절용
세번째로
ORDER BY 에 사용된 컬럼에 인덱스를 추가하자
정렬은 데이터의 양이 많을수록 매우 비용이 큰 작업이다.
ORDER BY 대상컬럼 -> 대상컬럼에 대해서 인덱스를 만들어 놓으면, 이미 데이터가 정렬된 상태로
저장되어 있기 때문에 ORDER BY 대상 컬럼 작업을 진행해도, 굳이 정렬작업 없이, 인덱스에
저장된 순서 그대로 데이터를 읽기만 하면 된다.
EX) ORDER BY registered_date DESC LIMIT 10
여기에서는 대상 컬럼이 registered_date 이므로
registered_date 컬럼에 인덱스를 생성해야한다
✅ 인덱스의 단점과 주의사항
인덱스는 공짜가 아님 = 인덱스를 생성하고 유지하는 비용이 큼
인덱스의 단점으로는 첫번째로 저장공간 이다
인덱스는 원본테이블과 별개로, B-Tree 구조를 가진 물리적인 파일로 디스크에 저장된다
두번째로는 쓰기성능(INSERT, UPDATE, DELETE) 이다
인덱스는 SELECT 의 속도를 높이지만, INSERT, UPDATE, DELETE 의 속도를 희생시킨다
그 이유는 데이터의 변경이 일어날 때 마다 원본 테이블 뿐 아니라 이와 관련된
모든 인덱스를 함께 수정해야 하기 때문이다
EX) items 테이블을 추가하면, 이 테이블에 생성된 모든 인덱스를 추가해야한다
만약 인덱스가 5개라면, 테이블 삽입 1번에 인덱스 삽입 5번의 작업이 추가되는 것이다
실무에서는 이런식으로 사용한다
1. 조회가 빈번한 기능이라면, 인덱스를 자유롭게 생성해도 좋다
2. INSERT, UPDATE 가 빈번한 기능이라면, 인덱스 생성에 신중하게 해야한다
혹시 나중에 필요할까봐? 인덱스를 미리 만들지말고, 나중에 필요하면 만들자
사용하지 않는 인덱스를 주기적으로 정리하자
💡 인덱스 컬럼은 가공하면 안된다
인덱스는 가공되지 않은 원본 값을 기준으로 만들어지기 때문이다
WHERE SUBSTRING(item_name, 1, 5) = '게이밍'
WHERE indexed_column * 10 = 100
위 예시처럼 인덱스가 적용된 컬럼을 함수로 감싸거나, 계산식을 넣으면서 가공을 하면
인덱스가 적용되지 않는다
