( 코드 및 데이터 열람 : https://github.com/Basara-hj/Data-analysis_project- )
0. 개요
K-디지털 트레이닝 훈련과정 중 멀티캠퍼스에서 주관하는 '데이터 시각화 & 분석 취업캠프_4회차' 과정 중 세미프로젝트를 진행했다. 그 후기 겸 정리글을 남긴다.
우리 과정엔 16명이 참여하고 있는데, 총 다섯 조로 나눠 팀 프로젝트를 진행했다. 주제는 '패턴의 변화'를 담아 낸다면 자유롭게 선정할 수 있었다.
1. 가설 설정
주제 : 기업의 가치에 영향을 주는 변수
내가 속한 조는 '기업의 가치에 영향을 주는 변수 탐색'을 주제로 잡았다. 기업의 가치에 영향을 주는 변수는 매우매우 많다. 변수들 간의 관계 또한 이루 다 헤아릴 수 없을 정도로 복잡하게 얽혀있어서 변수 딱 하나의 영향력을 정확하게 헤아리기란 사실상 불가능에 가까운 작업이다.
그럼에도, '천 리 길도 한 걸음부터' 라는 말이 있지 않은가. 변수 하나하나 '간접적이나마' 그 특성과 영향력을 헤아려나가다보면 언젠가 목표한 지점에 도달하는 기적이 일어날 것이라는 믿음을 갖고 작은 밍기적거림을 시도해보기로 했다.
우선 용어들을 정량적으로 정의할 필요가 있었다. 기업의 가치는 무엇으로 나타내며, 변수는 어떤 것의 무슨 값으로 나타낼 것인가.
기업의 가치는 이미 우리에게 너무나도 친숙한 (근데 이제 친해지기는 싫은) 주식 정보를 이용해 정의했다. 하루하루 '종가' 값이 해당 기업의 그날그날 가치를 나타낼 것이라고 정의했다.
변수의 경우 코로나19를 선정했다. 누가 봐도 영향을 줬을 것으로 생각되는 변수로서 코로나19만한 것이 없을 것이라고 판단했다. 영향력의 정도는 확진자 수에 비례하여 증가할 것이라고 가정했다.
코로나19(확진자 수)와 기업의 주식(종가) 간에 상관이 있을 것이다.
여기에 하나 남은 것이 있다. 기업은 어떤 기업을 대상으로 할 것이냐? 우리 조는 KOSPI200에 속해있는 200개의 기업을 대상으로 하기로 했다. 한국 주식 시장의 흐름을 대표하며 선도하는 기업들이기 때문이다.
2. 데이터베이스 구축
정량적 정의를 완료했고, 이제 이에 알맞는 데이터를 긁어모을 차례다.
보건복지부_코로나19 확진자 성별 연령별 현황
네이버 증권 사이트
위 두 사이트를 통해,

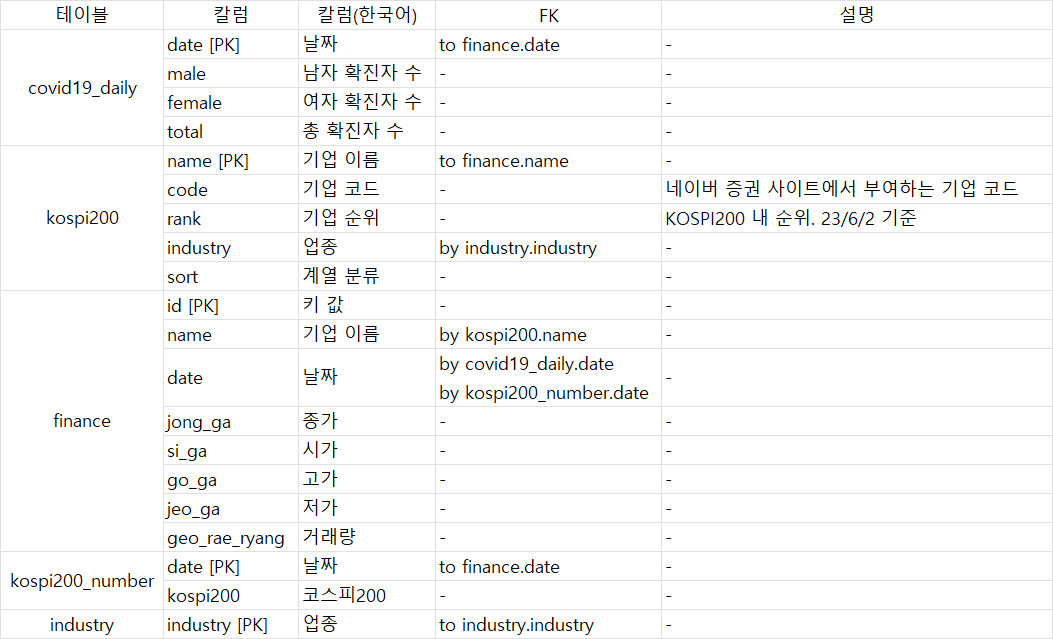
위 그림과 같은 데이터베이스를 구축했다.
모든 데이터는 requests, BeautifulSoup 라이브러리와 scrapy 프레임워크를 이용한 크롤링을 통해 수집했다.
3. EDA 및 전처리
분석 대상 기간은 코로나 확진자가 최초로 발생한 2020/1/20부터 포스팅 기준 최신 날짜인 2023/5/31로 잡았다.
코로나19 확진자 수 추세를 확인해보니(covid19_daily) 아래 그래프와 같은 모양새였다.
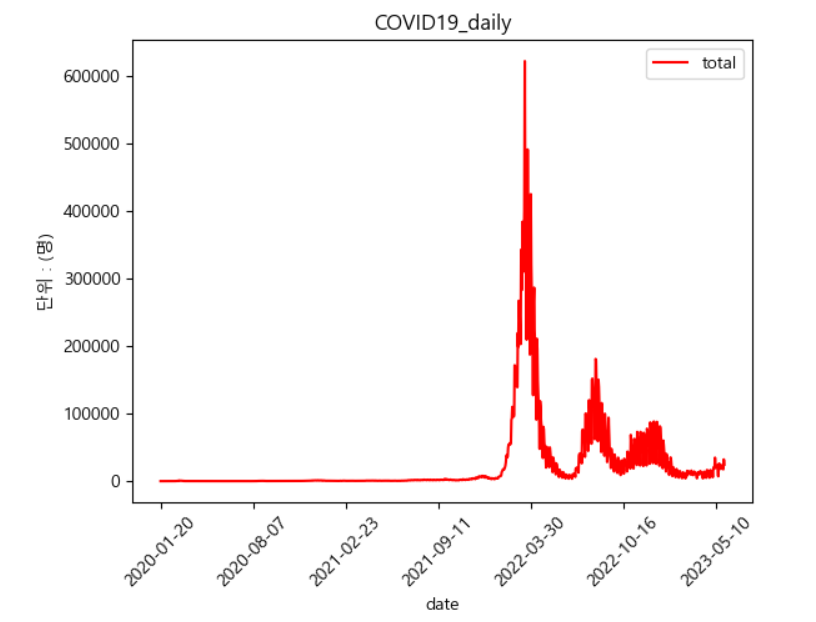
최초 발생 후 2년 동안은 어느 정도 선을 유지하다가(사실 저 안에서 수많은 오르내림이 발생하고 있지만), 어느 시점을 기준으로(2022/1/26 내외) 확진자 수가 폭발적으로 증가함을 알 수 있다.
2년 동안은 정말 철저하게 사회적 거리두기 등 제재 조치와 백신 투여 등을 통해 코로나19 대량 확진에 대한 면역을 준비했고, 그 이후 제재 조치를 해제하면서 발생한 양상이다.
우리 조는 이렇게 양상이 바뀌는 시점을 기준으로 코로나 확진자 수가 많아진다고 해서 더이상 코로나의 영향력도 마찬가지로 강해지진 않을 것으로 판단하여, 이 시점을 기준으로 데이터를 나눴다.
전반기 : 2020/1/20 ~ 2022/1/19
후반기 : 2022/1/26 ~ 2023/5/31
상관분석을 진행하기 위해 finance 테이블을 변환해줄 필요가 있었다. 날짜를 기준으로 각 기업들의 특정 값(종가)이 얼마인지 피벗 테이블로 나타내주었다.
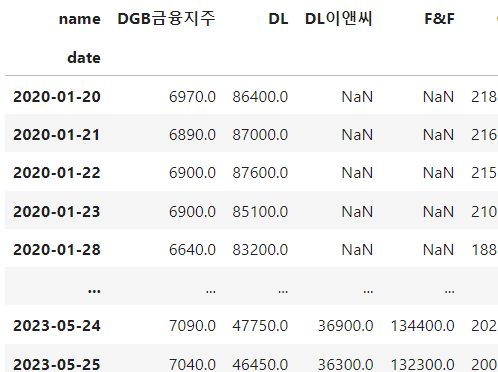
그런데 이 과정에서 결측값이 발견되었는데, 확인 결과 분석 대상 기간 동안 주식 시장에 새로 진입한 신생 기업들이 결측값을 발생시키고 있었다. 신생 기업들은 허니문 효과, 즉 신생 기업이라는 특성으로 인해 외부 변수의 영향이 다른 기업들에 비해 적을 것이라고 판단하여, 16개 신생 기업의 데이터는 삭제처리해줬다.
4. 분석 및 시각화
전반기, 후반기 같은 작업을 진행해줬다. 전반기 작업을 기준으로 설명을 진행하겠다.
먼저 개략적인 파악을 위해 KOSPI200 지수와 확진자 수 간의 상관관계를 파악해보았다.
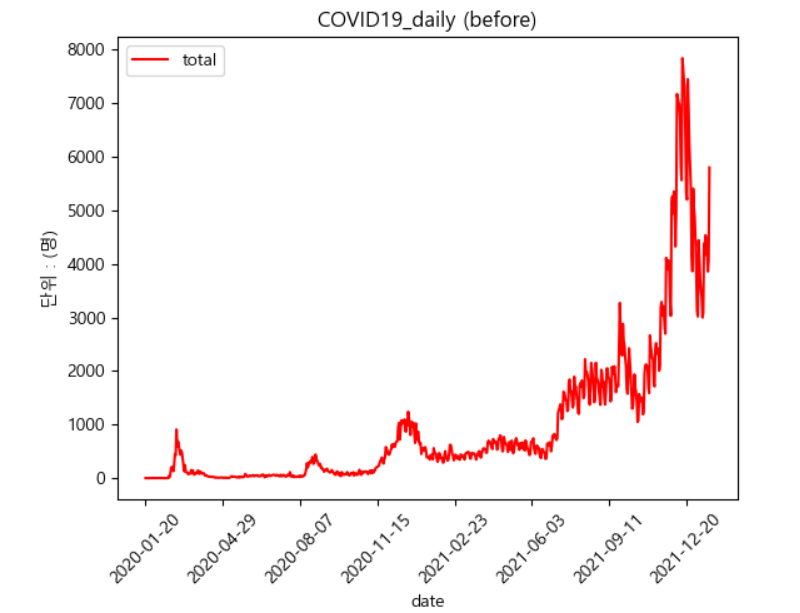
코로나19는 분명 주식 시장에 부정적인 영향을 끼쳤을 것이다. 그럼으로 확진자 수가 늘어나는 양상인 전반기엔 KOSPI200 지수와 음의 상관관계를 나타낼 것이다.
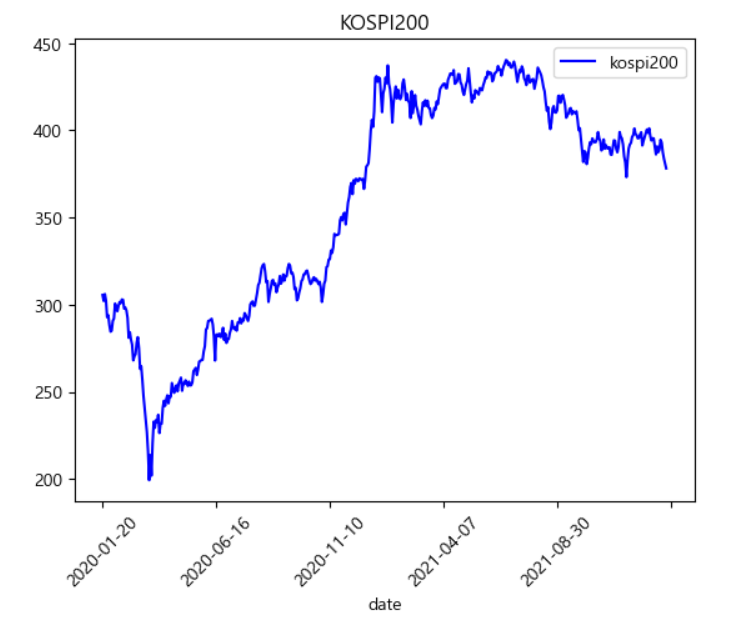
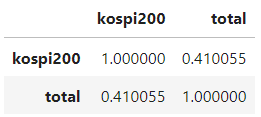
그런데 양상은 우리의 예상과 달랐다. KOSPI200 지수 그래프를 보면 알겠지만, 얼추 확진자 수 그래프와 비슷한 모양이지 않은가? 실제 상관계수를 계산해본 결과 또한 0.410055로 어느 정도 정적 상관이 있는 것으로 드러났다.
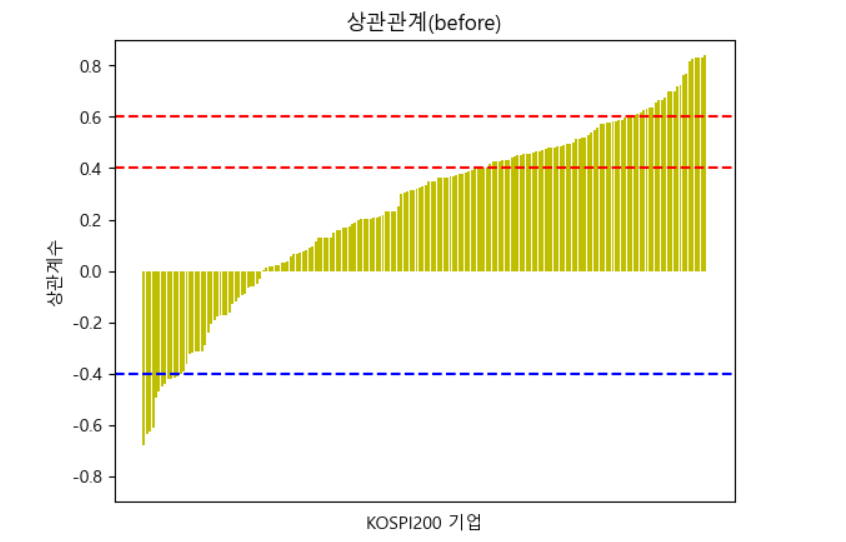
KOSPI200 각 기업과 확진자 수 간의 상관계수를 계산해본 결과 또한 정적 상관관계를 보이는 기업의 수가 많음을 나타내줬다.
'비철금속', '섬유,의류,신발,호화품', '우주항공과국방', '전기유틸리티', '전자장비와기기' 업종의 기업이 특히 강한 정적 상관을 보였으며,
'무선통신서비스', '상업서비스와공급품' 업종의 기업은 약한 부적 상관을 보였다.
후반기 또한 전반기와 똑같이 정적 상관관계가 있는 것으로 드러났다.
5. 한계점 및 개선 방향
전반기 후반기 모두 기업들의 부진을 예상하여, 확진자 수가 상승폭을 그리는 전반기엔 부적 상관, 하락폭을 그리는 후반기엔 정적 상관을 예상했으나, 결과는 달랐다. 왜 이런 결과가 나왔는지 고민해본 결과 다음과 같은 점들을 간과했을 수 있음을 알 수 있었다.
1)
KOSPI200에 속하는 기업들은 대기업들이다.
펜데믹이라는 외부 변수로부터 받은 영향이 중소기업에 비해 훨씬 덜했을 것이다.
2)
KOSPI200 기업 목록은 1년마다 갱신이 된다.
펜데믹 상황에서 풍파를 맞은 기업은 아마 기업 목록에서 제외가 되었을 수도 있다.
즉, 펜데믹 상황을 잘 이용한 기업들이 생존했다는 것.
3)
지금의 상관은 코로나19가 아닌 다른 변수들의 작용에 의한, 우연의 결과일 수 있다.경제가 무너지면 그 타격은 하위 계층부터 받는다고 한다. 중소기업을 대상으로 상관관계를 파악했다면, 코로나19로 인한 타격을 좀 더 엄밀히 살펴볼 수 있었을 것이라는 아쉬움이 남았다.
또한 높은 상관관계를 보인 업종에 속하지만, KOSPI200에 속하지 않는 다른 기업들과의 상관관계를 분석해봤다면 어땠을까 하는 아쉬움이 남았다. 상관계수 분석을 넘어 왜 해당 업종들이 코로나19 상황 속에서 그러한 상관관계를 보였는지 정성적 분석도 했다면, 좀 더 가치있는 분석 결과가 나왔을 수 있었을 것이다.
그리고 우리 조가 구축한 주식 데이터는 전형적인 시계열 데이터로서, 상관관계 분석이 아닌 다른 유용한 분석 방법이 존재하는데, 그 분석 방법을 이용해보지 못한 것이 뼈아팠다.
6. 후기
세미 프로젝트를 KDT 훈련 시작한지 한달밖에 지나지 않은, 아직 pandas나 matplotlib에 대해서 제대로 배우지도 않은 너무 이른 시점에 하는 게 아닌가 하는 우려가 있었는데, 결국 여러가지 뼈아픈 방관을 하게 되었다.
그래도 1주일이란 기간 동안, 생각지도 못한 곳에서의 딜레이가 주는 빡침부터 시행착오를 거치며 배우는 배움의 달콤함까지 많은 것을 깨우칠 수 있었다. 성의가 없어보일 정도로 간단해보이는 데이터 분석 포트폴리오 안에 '눅진하게' 녹아있을 데이터 분석가들의 심정이 어떨지 어느 정도 이해할 수 있게 되었다. 데이터는 내 생각보다 훨씬 불친절한 존재들이었다. 그러나 그래서 그런지 개인 프로젝트를 해보고 싶다는 도전 의식도 생겨났다. 챗GPT랑 더 친해지면 한번 조심스럽게 시도해보기로 했다.
