공부 목적으로 작성한 것임으로, 오류가 존재할 수 있다는 점을 말씀드리고 싶습니다
https://arxiv.org/pdf/1802.00934.pdf
Abstract
KG(Knowledge Graph)는 엔티티(entity), 관계(relation)으로 구성된다.
하지만 본 논문에서는 엔티티, 관계 그리고 리터럴(lieral) 노드로 구성된다
리터럴 노드는 엔티티의 attribute로 엔티티간의 관계만으로 나타낼 수 없는 정보를 인코딩한다.
관계 예측을 위해서 리터럴을 포함한 모듈을 LiteralE라고 한다.
LiteralE는 학습 가능한 매개 변수화된 함수를 통해 리터럴 정보로 임베딩을 직접 강화한다.
기존의 score function에 쉽게 통합되며 end-to-end 방식으로 엔티티 임베딩과 함꼐 학습할 수 있다.
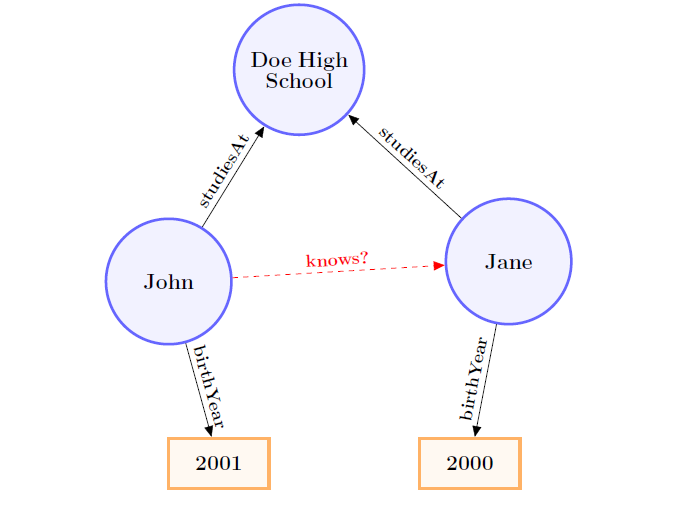
본 논문에서는 KG는 triple의 집합이다. triple은 관계를 통해 엔티티(원)나 리터럴(직사각형)을 다른 엔티티에 연결한다.
첫번째 triple은 엔티티와 엔티티간의 관계를 나타내고 두번째는 엔티티와 리터럴간의 관계를 나타낸다.
위에 그림에서는 구조적인 정보(같은 학교)와 문자 그대로의 정보(생년)을 보여준다.
이러한 노드들 사이에서 관계를 예측의 정확성을 극대화시키기 위해서는 같은 학교이고 비슷한 나이여야지 서로 알 확률이 높은 경향이 있기에 결합되어야한다.
리터럴 정보로 엔티티 임베딩을 강화하는 LiteralE를 소개하겠다.
기존의 임베딩과 엔티티의 리터럴을 입력으로 얻은 임베딩으로 학습 가능한 매개 변수 함수를 사용하여 해당 리터럴을 통합한다. score function을 변경하지 않고 잠재 기능 모델에서 기존 임베딩을 대체할 수 있으며, 결과 시스템은 확률적 gradient descent나 다른 gradient 기반 알고리즘과 end-to-end방식으로 공동 훈련할 수 있다.
따라서 LiteralEsms 기존 방법과 보편적으로 결합할 수 있는 확장 모듈로 볼 수 있다.
추가 입력으로 이미지, 텍스트의 저차원 벡터 표현으로 직접 일반화될 수 있다.
링크 예측 함수
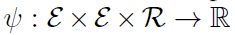
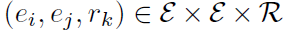
각각의 가능한 score 값을 매핑한다.
값이 클수록 참일 가능성이 높다.
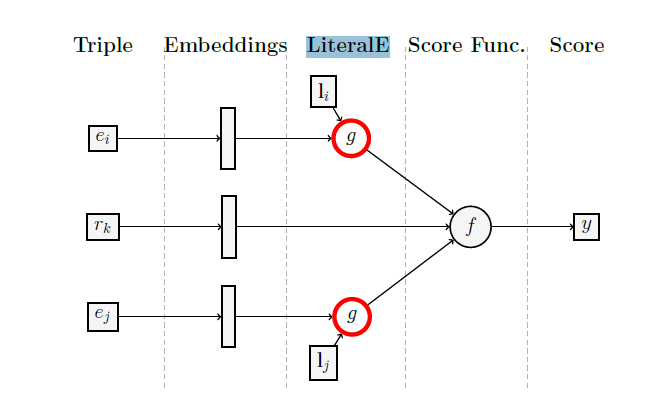
score function
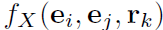
위의 함수를 밑처럼 대체하는 것을 제안한다.
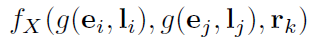
이전과 동일한 훈련 절차를 사용하여 gradient descent기반 최적화를 통해 훈련한다.
기본모델 (DistMult, Complex 및 ConvE)을 개선했다.
end-to-end
처음부터 끝까지라는 의미로, 입력부터 출력까지 '파이프라인 네트워크'없이 한 번에 처리한다는 뜻.
파이프라인 네트워크 : 전체 네트워크르 이루는 부분적인 네트워크
한계 : 신경망에 너무 낳은 계층의 노드가 있거나, 메모리가 부족할 경우 사용할 수 없다,
문제가 복잡할 수록, '전체 네트워크'를 '파이프라인 네트워크'로 나눠서 해결하는 것이 더 효율적일 때도 있다.
데이터의 정보가 나눠진 각각의 파이프라인에 더 적합하게 사용될 수 있기 때문이다.