리스트, 튜플
리스트와 튜플은 모두 여러 타입의 데이터를 담는 컨테이너형 변수
templist = [‘a’, ‘b’, ‘c’, 1, 2]
temptuple = (‘a’, ‘b’, ‘c’, 1, 2)
temptuple = (1,2,[3,4])공통점
- 인덱싱과 슬라이싱
- 순회가능(iterable)
- for 문을 이용해 순회 가능
- max, min 등의 순회 가능한 요소를 입력 받는 함수의 입력으로 사용 가능
차이점
- 리스트의 요소는 바꿀 수 있으나, 튜플의 요소는 바꿀 수 없음
- 리스트는 사전의 key로 사용할 수 없지만, 튜플은 사전의 key로 사용 가능
- 불변의 자료형(int, float, str etc.)만 사전의 key로 사용 가능
- 순회 속도는 리스트보다 튜플이 약간 더 빠름
- 따라서 요소를 변경할 필요가 없고, 요소에 대한 연산 결과만 필요한 경우 튜플이 더 적합
- 데이터가 큰 경우에 한해서, 리스트로 작업 후 튜플로 자료형을 바꾼 후 순회
tuple(list)
리스트 관련 함수
list.append(x) : x를 리스트 맨 뒤에 추가
list.insert(idx, x) : x를 idx 위치에 추가 (기존에 있던 요소들은 뒤로 한 칸씩 밀림)
list.remove(x) : x를 제거 (여러 개면 맨 앞의 하나만 지워지고, 없으면 ERROR)
list.pop() : 맨 마지막 요소를 출력 및 삭제 (스택)
list.index(x) : x 위치 반환 (여러 개면 맨 앞의 인덱스만 반환, 없으면 ERROR)
list.extend(list) : 두 리스트를 그대로 이어 붙임 (튜플도 가능) = list + list
튜플 관련 함수
- 튜플은 요소 변경이 불가능하므로, 추가/제거 관련 함수 미지원
- 함수의 가변인자 및 여러개의 출력을 받는데 많이 사용
사전
- 키, 값의 쌍으로 이뤄진 해시 테이블
- 키는 불변의 값을 사용
사전 관련 함수
del(dict[key]) : 사전 요소 삭제
dict.keys()
dict.values()
dict.items() : key, value 쌍 얻기
반복문과 comprehension
이터레이터 객체
- 값을 차례대로 꺼낼 수 있는 객체 like 리스트, 튜플
- range, itertools 모듈에 있는 주요 함수를 통해 이터레이터 생성 가능
단, 이러한 이터레이터 객체는 리스트/튜플과 달리 순회만 가능한 객체
range(start, end, step)
- start 인덱스부터 end 인덱스까지 step으로 건너 뛴 부분 이터레이터 객체를 반환
- 값을 하나만 넣으면 end로 인식됨
range(end) = range(0, end, 1) - 값을 두개 넣으면 start, end로 인식됨
range(start, end) = range(start, end, 1)
itertools 모듈 함수
itertools.product(*L) : 순회 가능한 여러 개의 객체를 순서대로 순회하는 이터레이터 생성
itertools.combinations(p,r) : 이터레이터 객체 p에서 크기 r의 가능한 모든 조합을 갖는 이터레이터 생성
itertools.permutations(p,r) : 이터레이터 객체 p에서 크기 r의 가능한 모든 순열을 갖는 이터레이터 생성
# itertools.product()
for v1, v2, v3 in itertools.product(l1, l2, l3):
#
for v1 in l1:
for v2 in l2:
for v3 in l3:list comprehension
for문을 사용해 한 줄로 리스트를 효과적으로 생성
# format
[output for element in iterator if condition]
# list comprehension
L = [x**2 for x in range(10) if x%2 == 0]
#
L = list()
for x in range(10):
if x%2 == 0: L.append(x**2)dictionary comprehension
for문을 사용해 한 줄로 사전을 효과적으로 생성
# format
{key:value for key, value in iterator if conditon}
# dic comprehension
dic = {x:y**2 for x, y in zip(range(10), range(10)) if x%2 == 0}
#
dic = dict()
for x, y in zip(range(10), range(10)):
if x%2 == 0: dic[x] = y**2Numpy 데이터 구조
numpy 자료형은 ndarray로 효율적인 배열 연산을 하기 위해 개발되었음
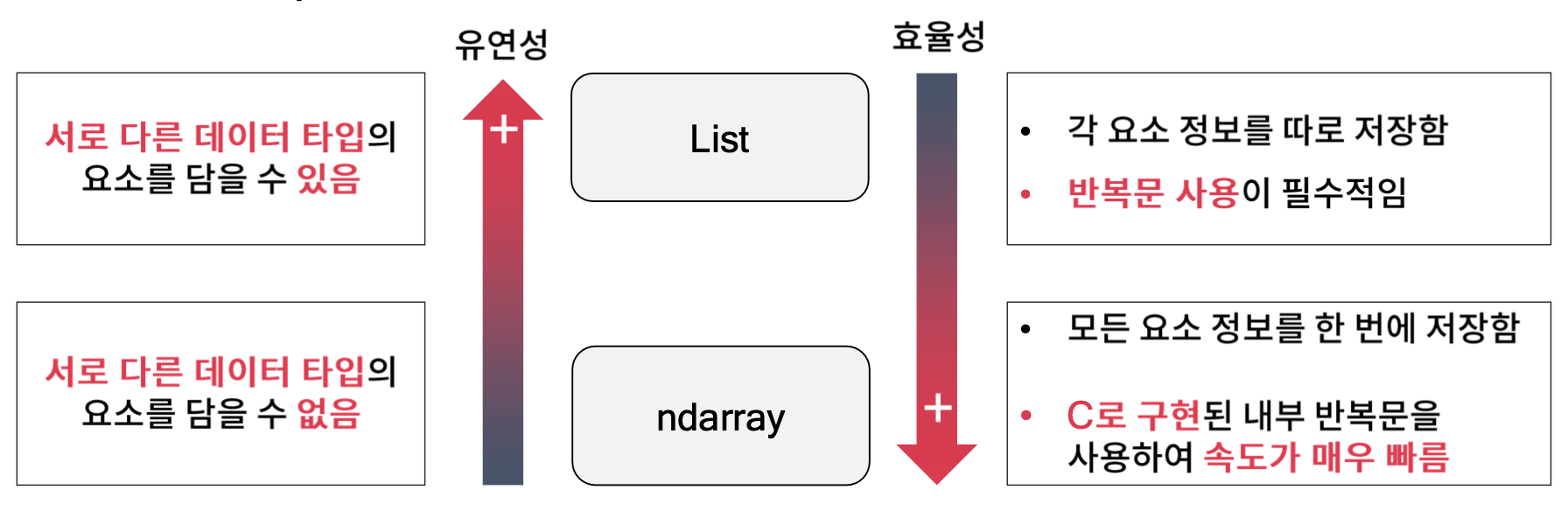
리스트 vs. ndarray
- 리스트와 ndarray는 유연성, 효율성 측면에서 비교 가능
넘파이 배열 생성 함수
np.array([1,2,3,4])
np.zeroes(shape) : shape(tuple) 모양을 갖는 영벡터/영행렬 생성
np.arange(start, stop, step) : start부터 stop까지 step만큼 건너뛴 ndarray를 반환(start, step은 생략 가능)
np.linspace(start, stop, num) : start부터 stop까지 num 개수의 요소를 갖는 등간격의 1차원 배열 반환
#(10,2) 크기의 영행렬 생성
np.zeros((10,2))
#ndarray([1, 1.1, 1.2, ...., 4.9])
np.arrange(1, 5, 0.1)
#ndarray([0., 0.125, 0.25, 0.375, 0.5, 0.625, 0.75, 0.875, 1.0])
np.linspace(0, 1, 9)인덱싱, 슬라이싱
- 리스트와 유사
- 2차원 배열의 경우, X[i,j]는 i행 j열에 있는 요소를 의미
- 리스트인 경우, X[i][j]로 접근 - boolean 리스트도 인덱스로 사용 가능, True인 요소와 대응되는 요소만 가져옴
X = [1, 2, 3, 4, 5]
B = [True, True, False, False, True]
X[B] = [1, 2, 5]유니버셜 함수
- ndarray의 개별 요소에 반복된 연산을 빠르게 수행하는 것을 주 목적으로 하는 함수
- ndarray x, y에 대해 다양한 배열 간 이항 연산을 지원
- 벡터간 + : x + y = [x1+y1, x2+y2, x3+y3, ..., xn+yn]
- 벡터간 * : x * y = [x1*y1, x2*y2, x3*y3, ..., xn*yn]
- 벡터간 ** : x**y = [x1**y1, x2**y2, x3**y3, ..., xn**yn]유니버설 함수는 단순 반복문에 비해, 매우 빠르다.
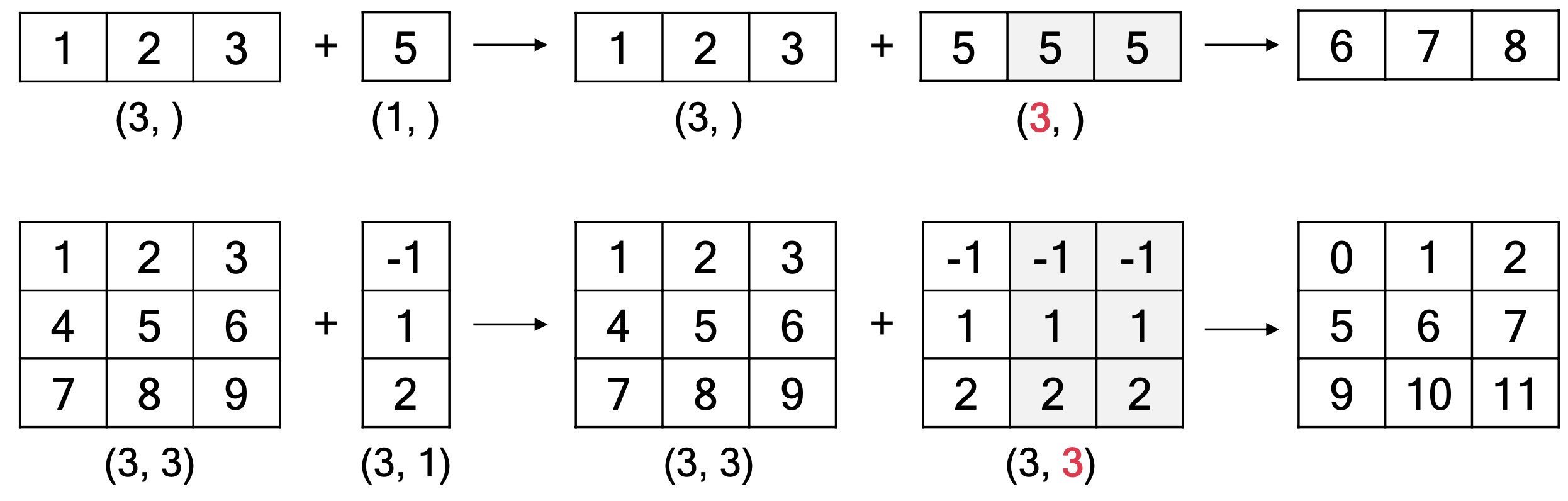
브로드캐스팅
- 다른 크기의 배열에 유니버셜 함수를 적용하는 규칙 집합
- 큰 차원의 배열에 맞게 작은 배열이 확장됨
비교 연산자
- 비교 연산자의 결과는 항상 Boolean 타입의 배열
[1, 2, 3, 4, 5] >= 3
# [False, False, True, True, True]- 비교 연산자의 결과를 바탕으로 조건에 맞는 요소 탐색에 활용 가능
L = np.array([1, 2, 3, 4, 5])
cond = L >= 3
# 조건을 만족하는 요소의 개수 반환
sum(cond)
# 조건을 만족하는 요소만 반환
L[cond]Pandas 데이터 구조
Series
- 시리즈는 1차원 배열 자료형으로서 인덱스와 값의 쌍으로 구성
#사전을 이용한 정의
pd.Series({'a':1, 'b':2})
#리스트를 이용한 정의
pd.Series([1,2,3,4], index=['a','b','c','d'])- 시리즈는 ndarray에 인덱스가 부여된 형태의 데이터
- 시리즈에도 유니버셜 함수와 브로드캐스팅 등이 적용됨
DataFrame
- 데이터프레임은 2차원 배열 자료형으로서 행과 열 인덱스, 값으로 구성
#사전을 이용한 정의
pd.DataFrame({'col1':[1,2,3,4], 'col2':[5,6,7,8]}, index=['a','b','c','d'])
#데이터, 컬럼명, 인덱스 따로 정의
pd.Series([[1,2,3,4], [5,6,7,8]], columns=['col1', 'col2'], index=['a','b','c','d'])- ndarray에 행, 열 인덱스가 부여된 형태의 데이터
- 하나 이상의 시리즈의 집합
인덱싱, 슬라이싱
- 판다스 객체는 두 종류의 인덱스 존재
- 암묵적인 인덱스(위치 인덱스) : iloc
df.iloc[2] = 3 - 명시적인 인덱스 : loc
df.loc['a']=1
- 암묵적인 인덱스(위치 인덱스) : iloc
loc의 슬라이싱에서는 맨 뒤 값을 포함 : df.loc['a':'c'] = [1,2,3]
iloc의 슬라이싱에서는 맨 뒤 값을 포함 안 함 : df.iloc[1:3] = [2,3]
값 조회시 TIP
- pd.set_option('display_max_rows', None)
- 모든 행을 보이게 할 수 있음- None 대신 숫자가 들어가면 출력되는 행의 개수 설정
- pd.set_option('display_max_columns', None)
- 모든 열을 보이게 할 수 있음- None 대신 숫자가 들어가면 출력되는 열의 개수 설정
