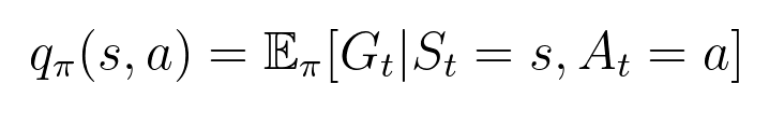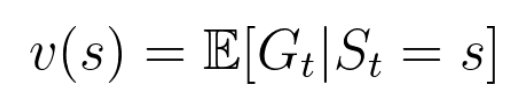
상태 가치 함수(State value function)
현재 상태가 얻을 Return의 기댓값 -> 현재 State에 대한 가치를 내놓는 함수
- 가치(value) = 어떤 상태가 얼마나 좋은 상태인지
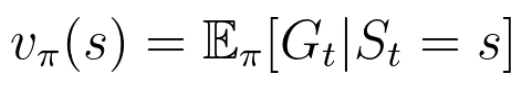
= Agent가 state s에서 탐험을 시작할 경우, 평균적으로 v(s)만큼의 감가율이 적용된 reward를 받을 것이다
-> 가치가 높은 상태일 경우 장기적인 보상이 클 가능성이 높다
Return vs Value
- Return Gt : 현재 정책을 따랐을 때 얻을 수 있는 return 값의 한 예시
= Agent가 정책을 따라 경험/탐험/시행착오를 통해 실제로 얻은 보상의 합 -> 이게 잘한 탐험인지 평가할 수 없다. 현재 정책에 대한 '평가'라기 보다는 그저 한 예시이다.- Value(가치) : 큰수의 법칙을 따라 예상되는 모든 return의 평균으로써 가치함수를 정의
-> 몬테카를로 방식(반복된 무작위 샘플링으로 함수의 값을 수리적으로 근사하려는 방식)을 이용
-> MDP의 알지 못하는 요소를 근사해서 학습에 사용 = model-free 강화학습의 근간
행동 가치 함수(Action value function)
지금 행동으로부터 기대되는 Return = 어떤 state s에서 행한 행동(action)에 대한 가치를 평가