Reinforce Learning
1.[강화학습] 0. Introduction, 용어 정리
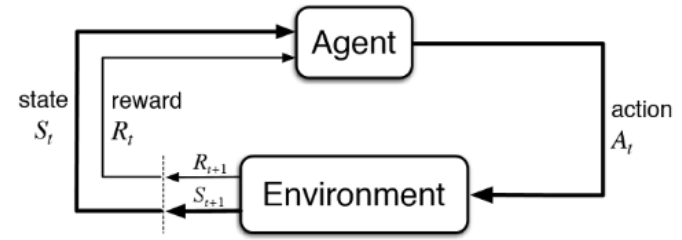
강화학습은 discrete time 에서 stochastic 하게 agent를 control하는 문제이다.Agent는 Policy에 따라 행동을 결정한다Agent의 행동에 따라 상태가 전이된다전이된 상태에서의 Reward를 Agent에게 준다Agent는 Reward에
2023년 1월 1일
2.[강화학습] 1. Markov Decision Process (MDP)
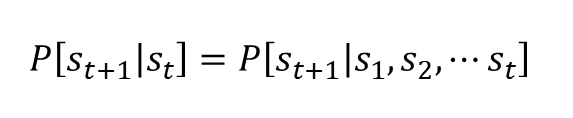
State에서 action을 해서 그에 대한 reward를 받고 새로운 state로 나아간다S - A - R - S' 가 계속 반복된다 / S0 A0 R1 S1 A1 R2 S2 A2 ....Agent : MDP에서 문제를 학습하고 행동을 결정하는 주체Environmen
2023년 1월 6일
3.[강화학습] 상태 가치 함수 vs 행동 가치 함수
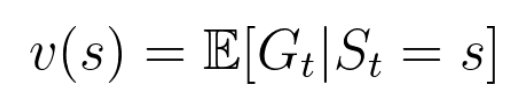
현재 상태가 얻을 Return의 기댓값 -> 현재 State에 대한 가치를 내놓는 함수 가치(value) = 어떤 상태가 얼마나 좋은 상태인지= Agent가 state s에서 탐험을 시작할 경우, 평균적으로 v(s)만큼의 감가율이 적용된 reward를 받을 것이다\->
2023년 1월 9일