
>⛹️♀️ 제로베이스 데이터취업스쿨 15기 스터디노트 25(6.8.)
🗂️ 오늘(6.8.) 수강한 분량
유가분석 4~5, Naver API
🗂️ 유가분석 4~5(23.6.8.기준), Naver API 핵심 내용 정리
Selenium으로 접근
from selenium import webdriver def main_get(): #페이지 접금 url = "https://www.opinet.co.kr/searRgSelect.do" driver = webdriver.Chrome("../driver/chromedriver.exe") driver.get(url) main_get() driver.set_window_to_window(driver.window_handles[-1]) #팝업창 화면 전환 후 닫아주기 driver.colse() #팝업창 닫음 driver.get(url) 화면 전환 options = webdriver.ChromeOptions() options.add_experimental_option("excludeSwitches", ["enable-logging"]) driver = webdriver.Chrome(chromedriver, options=options - html 내용 다듬기 : `element`사용시 한개가 아니면 무조건 `elements`로 나타내기 - ```python sido_list = sido_list_raw.find_elements_by_tag_name("option") len(sido_list), sido_list[17].text- 속성 전체 값 가져오고, 내용 반복하기
sido_list[1].get_attribute("value") #속성값 전체 가져오기 sido_names = [] for option in sido_list: sido_names.append(option.get_attribute("value")) sido_names #=sido_names = [option.get_attribute("value") for option in sido_list] sido_names[:5]- 구 리스트 가져오기
gu_list_raw = driver.find_element_by_id("SIGUNGU_NM0") #부모태그 gu_list = gu_list_raw.find_elements_by_tag_name("option") #자식태그 gu_names = [option.get_attribute("value") for option in gu_list] gu_names = gu_names[1:] gu_names[:5], len(gu_names)- 데이터 저장하기
import time from tqdm import tqdm_notebook for gu in tqdm_notebook(gu_names): element = driver.find_element_by_id("SIGUNGU_NM0") element.send_keys(gu) time.sleep(3) element_get_excel = driver.find_element_by_css_selector("#glopopd_excel").click() time.sleep(3)- 데이터 정리하기
import pandas as pd from glob import glob glob('../data/지역_*.xls') #파일 목록 한번에 가져오기concat: 형식이 동일하고 연달아 데이터를 붙일 때 사용
- ex_
stations_raw = pd.concat(tmp_raw)- 구 주소를 기준으로 어느 구에 해당하는지 만들기
stations["구"] = [eachAddress.split()[1] for eachAddress in stations['주소']]- 주유 가격 정보 시각화
import matplotlib.pyplot as plt import seaborn as sns import platform from matplotlib import rc,font_manager get_ipython().run_line_magic("matplotlib", "inline") path = "C:/Windows/Fonts/malgun.ttf" if platform.system() == "Darwin": #폰트 설정 여부 확인 rc("font", family="Arial Unicode Ms") elif platform.system() == "Windows": font_name = font_manager.FontProperties(fname=path).get_name() rc("font",family = font_name) else: print("Unkown system.") -Seborn 활용하여 boxplot으로 나타내기 ```python plt.figure(figsize = (12,8)) sns.boxplot(x="상표",y="가격",hue = "셀프", data=stations, palette="Set3") plt.grid(True) plt.show()지도 시각화
import json import folium import warnings #오류 무시 코드 warnings.simplefilter(action="ignore", category=FutureWarning) geo_path = "../data/02. skorea_municipalities_geo_simple.json" geo_str = json.load(open(geo_path, encoding="utf-8")) my_map = folium.Map(location=[37.5582, 126.982], zoom_start=10.5, tiles="Stamen Toner") my_map.choropleth(geo_data=geo_str, data=gu_data, columns=[gu_data.index,"가격"], key_on = "feature.id", fill_color="PuRd") my_map
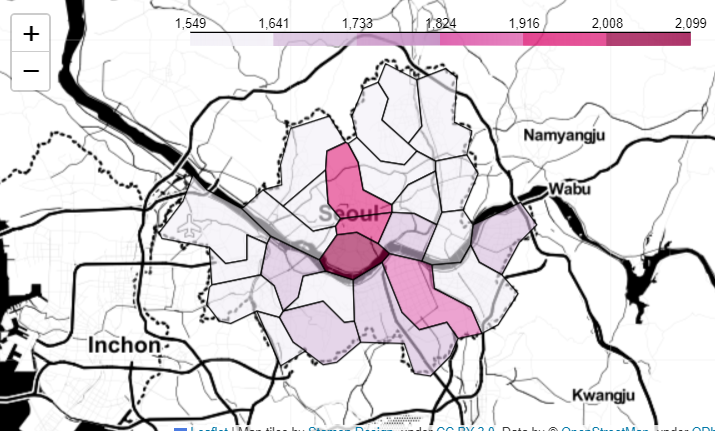
- Naver API
- 네이버 API 사용 등록
- 네이버 검색 API 사용 하기
import os import sys import urllib.request client_id = "0Oc3nDcszUYMKlcYRP09" client_secret = "TUNc298X3b" encText = urllib.parse.quote("ex") # ex 검색어 변경으로 원하는 값 넣을수 있음 url = "https://openapi.naver.com/v1/search/blog?query=" + encText # JSON 결과, 블로그 검색 (검색시 블로그 내용 삭제 후 해당 이름을 넣기 ex: shop, book, encyc등) request = urllib.request.Request(url) request.add_header("X-Naver-Client-Id",client_id) request.add_header("X-Naver-Client-Secret",client_secret) response = urllib.request.urlopen(request) rescode = response.getcode() if(rescode==200): response_body = response.read() print(response_body.decode('utf-8')) else: print("Error Code:" + rescode)- 상품검색 데이터 프레임 만들기
import pandas as pd def get_fields(json_data): title = [each["title"] for each in json_data["items"]] link = [each["link"] for each in json_data["items"]] lprice = [each["lprice"] for each in json_data["items"]] mall_name = [each["mallName"] for each in json_data["items"]] result_pd = pd.DataFrame({ "title" : title, "link" : link, "lprice" : lprice, "mall" : mall_name }, columns =["title","lprice","link","mall"]) return result_pd - 태그 지우기 - ```python def delete_tag(input_str): input_str = input_str.replace("<b>","") input_str = input_str.replace("</b>","") return input_str import pandas as pd def get_fields(json_data): title = [delete_tag(each["title"]) for each in json_data["items"]] link = [each["link"] for each in json_data["items"]] lprice = [each["lprice"] for each in json_data["items"]] mall_name = [each["mallName"] for each in json_data["items"]] result_pd = pd.DataFrame({ "title" : title, "link" : link, "lprice" : lprice, "mall" : mall_name }, columns =["title","lprice","link","mall"]) return result_pd - 데이터 모으기 - ```python result_mol = [] for n in range(1,1000,100): url = gen_search_url("shop","몰스킨", n, 100) #shop에 요청 첫페이지부터 5페이지까지 json_result= get_result_onpage(url) pd_result= get_fields(json_result) result_mol.append(pd_result) result_mol = pd.concat(result_mol) -데이터 엑셀로 저장하기 - ```python writer = pd.ExcelWriter("../data/06_molskin_diary_in_naver_shop.xlsx",engine="xlsxwriter") result_mol.to_excel(writer,sheet_name="Sheet1") #엑셀로 자동 반복하여 작업하는 방식 workbook=writer.book worksheet = writer.sheets["Sheet1"] worksheet.set_column("A:A",4) worksheet.set_column("B:B",60) worksheet.set_column("C:C",10) worksheet.set_column("D:D",10) worksheet.set_column("E:E",50) worksheet.set_column("F:F",10) worksheet.conditional_format("C2:C1001",{"type":"3_color_scale"}) #엑셀에서 쓰이는 색 및 타입 지정 writer.save() -시각화 - ```python import matplotlib.pyplot as plt import seaborn as sns import platform import matplotlib.font_manager as fm plt.figure(figsize=(15,6)) sns.countplot( x = result_mol["mall"], data=result_mol, palette="RdYlGn", order=result_mol["mall"].value_counts().index #쇼핑목 숫자 ) plt.show()
👩🚀 스터디 감정 노트
Naver API 자꾸 오류나서 지금 좀 슬픈 그 상황인데여,,
왜 자꾸 오류나는 건가여,,,,
[이미지 출처 : 미리캔버스]

데이터가 궁금한 비전공자의 데이터스터디🫠