파일이란 지속적으로 저장되어있는 바이트의 배열이다.
파일은 사람이 이해할 수 있는 이름과 os가 식별하기 위한 식별번호로 되어있으며 리눅스 기반에서는 inode number로 식별한다. (Inode number는 파일 시스템 안에서 유일해야한다)
디렉토리는 무엇인가
디렉토리는 파일과 서브 디렉토리들을 담아놓은 가방이다. 그리도 대부분의 시스템에서 디렉토리는 파일처럼 저장된다. 이러한 관점에서 보면 디렉토리는 파일 이름과 inode number가 잔뜩 적혀져 있는 하나의 파일이다.
디렉토리는 루트로 “/“을 가지는 트리구조체이다.
파일과 관련된 작업들
1. 파일을 생성한다.
open()시스템콜을 이용해 파일을 생성한다.(open()의 인자로 파일명과 함께, 해당 이름의 파일이 없다면 파일을 생성하라는 플래그를 전달한다)
2. 파일을 연다.
역시 open()을 이용한다.
open()은 return 값으로 file descriptor를 반환하는데 앞으로 파일과 관련된 작업은 전부 file descriptor로 이루어진다.
File descriptor는 정수로 된 값이고 특정한 파일에 접근하기 위해 추상화 된 키(key)이다. 전통적으로 posix 운영체계에서 커널은 프로세스에 어떤 파일이 열려있는가 관리하기 위해 각각의 프로세스마다 file descriptor table을 만들어 file descriptor를 관리한다.
-
파일을 닫는다.
close() 시스템 콜 -
파일의 내용을 읽고, 쓴다.
read()와 write() 시스템 콜을 이용한다. 읽기와 쓰기는 파일에서 일정 지점부터 일정 크기를 읽어오거나 쓴다. 기본적으로 read()와 write()는 다음에 이 파일에 접근해서 읽거나 쓸때 어디서부터 시작해야하는지를 기록하기 때문에(offset) 파일의 읽기는 연속적으로 일어난다. -
파일의 어느 부분부터 읽거나 쓸 것인지를 결정한다.
lseek() 시스템콜을 이용한다. 기존에 파일에 기록되어있던 offset이 아닌 임의의 지점으로 이동해 읽기와 쓰기를 시작하기 위해 사용한다.
파일에 내용을 적을 때 write()는 일단 받은 내용을 메모리에 있는 buffer에 저장했다가 파일에 옮겨적기 때문에 write()를 했다고 해서 변경된 내용이 파일에 저장되었다는 것을 장담할 수 없는 상태가 된다. 이때 fsync()를 이용하면 버퍼에 적혀있는 내용이 파일에 저장된다.
이외에도 파일의 이름을 변경하거나, 파일을 삭제하거나(파일의 링크를 제거하는 것이지 디스크에서 파일을 물리적으로 삭제하는 것은 아니다), 파일의 상태정보를 가져오는 것도 가능하다.
디렉토리 또한 파일이기 때문에 위의 작업들을 할 수 있으며, 대표적인 예가 ‘ls’이다.

ls는 실행가능하게 만들어진 c프로그램이며, 디렉토리 파일을 열어서 안에 있는 내용을 전부 읽어서 사용자에게 보여주는 기능이 들어있다.
파일을 링크하는 방식
하드링크
하드링크는 같은 inode number를 가지는 새로운 파일을 만든다. 사람 입장에서는 다른 식별자를 가지지만 os입장에서는 파일 시스템 안에서 같은 내용을 지칭하는 것이기 때문에 파일의 내용은 두 파일이 같고, 한 개의 파일을 지워도, 다른 파일을 통해 같은 내용에 접근하는 것이 가능하다.
inode에는 이 데이터을 링크하고 있는 파일이 몇 개인가를 기록하는 link count를 가지고 있고, 데이터에 접근하는 모든 링크가 사라지면 시스템은 inode를 삭제한다. 때문에 사용자는 링크를 삭제하는 것만 가능하고, 모든 링크가 사라지면 시스템이 파일을 삭제한다.
소프트링크 혹은 심볼릭링크
소프트링크는 파일에 새로운 링크를 만드는 것이 아니라 두 가지 다른 파일 이름을 매핑하는 것이다. 때문에 소프트링크 파일은 매우 크기가 작다. 파일에 접근하기 위한 링크를 가지고 있지 않기 때문에 원본 파일링크가 삭제되면 소프트링크로는 데이터에 접근할 수 없어진다.
파일시스템 마운팅
한 파일 시스템의 루트를 다른 파일 시스템의 트리에 이어붙이는 방식으로 다른 파일 시스템에서 접근하게 만들 수 있다. 보통의 시스템은 여러 파일 시스템이 마운트 되어있는 상태이다.
파일을 메모리 매핑하기
이전까지의 설명은 모두 파일을 열어서 file descriptor로 파일에 접근하고 있었는데 이외에도 메모리 매핑을 통해 파일을 읽고 쓰는 것이 가능하다.
mmap() 시스템콜을 이용하면 가상주소에 페이지를 만들어준다(code, stack, heap 어디에도 포함되지 않는 영역에 할당해준다)
mmap을 통해 생성된 페이지를 두 가지로 구분할 수 있는데 프로그램 데이터를 저장하기 위한 일반적인 페이지인 anonymous page와, 디스크에 있는 파일에서 내용을 가져오는 file-backed page로 구분할 수 있다.
이렇게 mmap()을 하고 나면 파일 안에 있는 내용을 마치 프로그램의 내용처럼 읽고 쓰는 것이 가능해진다(큰 데이터 배열처럼 여기고 임의의 장소부터 읽고 쓰는것이 가능해진다).
파일시스템이란
디스크안의 파일과 디렉토리를 관리하는 방식이다.
디스크는 블록들로 이루어져있는데 한 블록은 대개 512b다. 파일시스템은 파일들을 블록으로 관리하고, 읽고 쓰는 작업은 블록을 매핑하는 것과 연관되어있다.
os에는 하나 이상의 파일시스템이 구현되어있고, 각각 세부사항에서 차이가 있지만 파일 시스템에서 중요하게 봐야 차이는 크게 두 가지 이다.
1. 데이터와 메타 데이터(데이터에 대한 내용을 담은 데이터 ex.파일의 크기나 최근 변경일자 등)를 관리하는 자료구조
2. 자료구조를 이용하는 시스템 콜의 구현방식
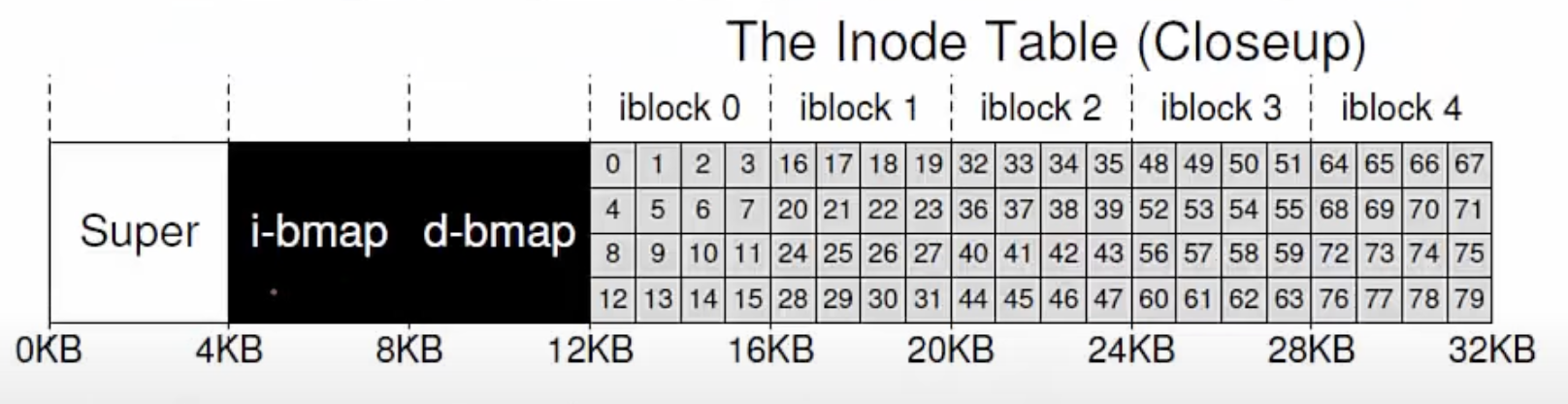
단순화된 파일시스템
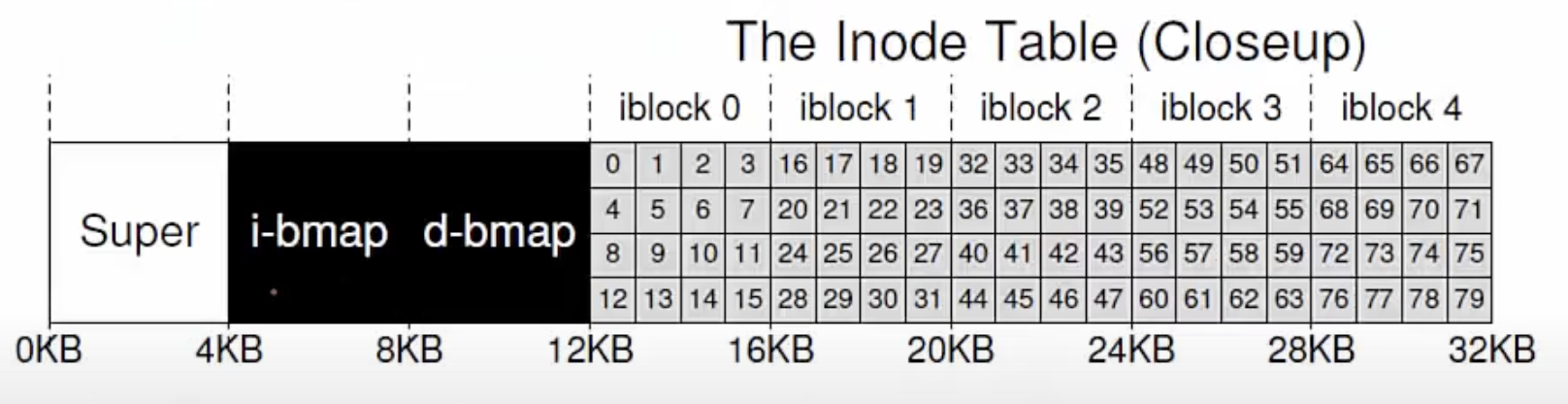
Data region은 파일의 데이터를 저장하는 부분이다.
inode block에는 파일들의 메타데이터가 저장된 inode가 저장된다.
bitmap은 디스크 안에서 어느 부분이 할당 되어있고, 어디가 가용 상태인지 확인하기 위한 용도로 저장된다.
Super block 모든 파일 시스템의 시작 블럭. 파일시스템이 어떤 식으로 저장될 것인가 계획을 저장해놓은 블럭
Inode block은 inode 크기로 쪼개져있어서 inode의 크기와 inode block의 크기를 통해 inode number가 몇 까지 할당가능한지 알 수 있다. 각각의 inode는 고유한 번호를 가지고 있고, 파일이 특정 inode 번호를 할당 받으면 그 번호가 inode table에서 inode의 index 번호가 된다.
inode는 파일의 메타데이터(권한이나 크기 등) 뿐만 아니라, 파일이 어느 블럭에 저장되어있는지를 가리키는 포인터를 저장하고 있다.
파일은 디스크상에서 연속적인 블럭에 저장되어있지 않기 때문에 inode는 파일이 저장된 모든 블럭을 기록하고 있다. 때문에 파일이 매우 커지면 한 블럭안에 모든 내용을 저장할 수 없어져서 multi-level index로 관리하게 된다. 즉 첫 몇 개의 블록은 inode에 직접 기록하지만, 크기가 커지면 다른 블록을 정해서 미처 다 기록하지 못한 블록들을 기록해둔 뒤, 다른 블록들이 저장된 블록을 가리키는 포인터만 저장하는 방식을 모든 블록이 기록될 때까지 2중 3중으로 반복한다.(linux에서 사용하는 방식)
File allocation table 방식
옛날 windows에서 사용하던 방식으로 multi-level과는 다른 방식.
파일을 저장할 때 inode에 블록의 entry만 저장하고, 각 블록에 파일을 저장하면서 파일의 다음 내용을 저장한 블록의 entry를 함께 저장해 다음 블록을 찾아가는 방식.
Directory 관리
디렉토리는 file name과 inode number를 매핑해놓은 특별한 종류의 파일이다. 디렉토리가 어떤 자료구조를 가지는지는 파일시스템에따라 다른데 단순히 연결리스트로 관리하거나 해시테이블이나 이진탐색트리같은 복잡한 구조로 만들수도 있다.
가용 블럭을 관리하는 법
비트맵
디스크 상의 모든 블럭 수만큼의 비트를 이용해 할당되어있으면 1, 가용상태면 0으로 저장해 블록의 상태를 확인한다.
Free list
Super block에 첫 가용 블럭을 저장하고, 각 가용 블럭에 다음 가용블럭을 가리키는 포인터를 저장하는 방식으로 가용블럭을 관리하는 방식.
이외에도 더 복잡한 방식으로 관리 가능하다.
