What is eBPF, and why is it important
eBPF는 custom code를 작성하여 kernel에 동적으로 적재하여 kernel의 동작을 변경할 수 있다. 이를 통해서 좋은 성능의 네트워킹, observability, security tool 등이 가능하다. 또한, eBPF로 이러한 추가 기능을 제공하는데에 있어서 기존 application은 어떠한 동작의 변경이 없어도 된다는 장점이 있다.
몇가지 eBPF에서 제공하는 것들을 정리하면 다음과 같다.
1. 다각도의 성능 tracing 제공
2. 내장된 시각화와 함께 높은 성능의 네트워킹 제공
3. 잘못된 activity에 대한 감지 또는 수정 제공
eBPF(The Berkeley Packet Filter)
eBPF의 뿌리는 BSD Packet Filter로부터 시작된다. 이는 1993년에 쓰여진 논문으로, pseudomahcine으로 작성된 filter에 대하여 논의하고 있는데, filter는 network packet을 거부하거나 수용할지 말지에 대한 program이다. 이 pseudomachine program은 BPF 명령어셋으로 쓰여졌는데, assembly를 재조합한 32-bit 명령어셋에 가깝다.
ldh [12]
jeq #ETHERTYPE IP, L1, L2
L1: ret #TRUE
L2: ret #0다음의 code는 IP packet이 아닌 것들을 filter하는 기능을 제공한다. input은 ethernet packet이고 첫번째 명령어인 ldh는 packet의 12번째 byte에서 2byte값을 적재한다는 것이고, jeq는 앞에서 load한 값이 IP packet을 나타내는 값과 일치하는 지 확인한다. 만약 일치하면 L1으로 점프하고, Non-zero값을 반환하여 TRUE를 표현한다. 만약 일치하지 않으면 packet은 IP packet이 아니므로 0으로 return한다.
custom한 program을 kernel에 적재하여 원하는대로 동작하게 할 수 있는 것, 이것이 바로 filter program의 동작이 바로 eBPF의 핵심이다.
BPF는 Berkeley Packet Filter로 Linux 1997년에 kernel version 2.1.75로 먼저 소개되었다. 이때에는 효율적으로 packet들을 캡쳐하여 추적하기 위해 tcpdump utility로 사용하였다.
2012년 seccomp-bpf가 version 3.5 kernel에 등작하였는데, 덕분에 BPF program으로 user space application이 system call을 실행하는 것을 허용하거나 허용하지 않거나하는 것이 가능해졌다. 이것이 바로 eBPF로의 첫번째 단계로 narrow한 packet filter기능에서 general-purpose platform으로의 발전이 가능해졌다.
BPF에서 eBPF로
eBPF라고 정식으로 불리는 것은 2014년 kernel version 3.18부터였다. 여기에는 눈에 띄는 몇가지 변화들이 있었다.
- BPF 명령어 셋이 효율적으로 64-bit기계에 사용될 수 있게 완전히 개편되었다. 또한, interpreter가 완전히 다시 쓰여졌다.
- eBPF maps가 도입되었는데, 이는 자료구조로 BPF program와 user space application에 의해 접근이 가능하므로, 이들 간의 data 공유가 가능해졌다.
bpf()system call이 추가되어 user space program들이 kernel의 eBPF program과 상호작용할 수 있게 되었다.- 여러 BPF helper function이 추가되었다.
- eBPF verifier가 추가되어 eBPF program이 동작하기에 안전한지 에 대해서 보장받을 수 있게 되었다.
이 이후로 eBPF에 대해서 상당한 발전이 이루어졌다.
production system으로의 eBPF 발전
2005년에 kprobes(kernel probes)라고 불리는 feature가 linux kernel에 등장했다. 이는 kernel code의 대부분의 명령어에 trap들을 설정할 수 있도록 도와줬다. 개발자들은 디버깅이나 성능 측정 목적으로 kprobes에 함수를 추가하는 kernel modules을 작성할 수 있었다.
2015년에 kprobes에 eBPF program을 추가하는 기능이 등장하였고, 이것은 linux system에서 trace가 이루어지는 방식에 혁명을 일으킨 시작점이었다. 같은 시기에 hooks도 kernel의 networking stack에 추가되기 시작하여 eBPF program이 networking 기능의 관점에 대해서 신경쓸 수 있게 되었다.
2016년에는 eBPF-based tool들이 상용 시스템에 사용되기 시작했다. 대표적으로 netflix app을 tracing하는 작업들이 널리 퍼지게 되면서 eBPF가 linux에 엄청난 기회를 줄것이라는 의견들이 나왔다. 같은 해에 cilium project가 발표되고 첫번째로 eBPF를 사용하여 container 환경에서의 전체 datapaht를 대체하였다.
다음해에는 Facebook이 layer 4 load balancer인 Katran을 만들면서 facebook의 higly scalable and fast solution에 대한 needs를 충족했다. 2017년 이후로 Facebook의 모든 단일 packet들은 eBPF/XDP를 통하게 되는 것이다.
2018년 eBPF는 linux kernel에 있어서 분리된 subsystem이 되었다. 같은 해에 BPF Type Format(BTF)가 등장하면서 eBPF program을 더욱 portable하게 만들었다.
2020년에 LSM BPF가 등장하여, eBPF program들이 Linux Security Module(LSM) kernel interface에 붙을 수 있도록 하였다. 이는 eBPF program의 효율성을 증명한 3번째 application이 되었다. LSM BPF이후로 eBPF가 security tool로서 좋은 platform이라는 것이 증명되었고 더 나아가 networking과 observability에 대해서도 eBPF가 효율성이 있다는 것이 밝혀졌다.
해를 거듭하면서 eBPF의 능력은 점진적으로 상승하고 있다. 300명 이상의 kernel 개발자와 user space tool, compiler, programming language library와 관련된 contributor들 덕분이다. 이전에 program은 4096개의 명령어로 제한되었지만 현재는 1백만개의 검증된 명령어셋으로 증가했고, 명령어 제한은 사실상 오늘날에 다양한 함수의 지원 덕분에 더욱 의미가 없어졌다.
사실 eBPF라는 명칭은 Enhanced Berkely Packet Filter라는 의미를 가지지만, 크게 단어 자체에는 의미가 많지 않다. packet filter라는 말도 처음에 나온 논문 때문에 그렇게 지어진 것이지 실제로는 packet filter보다 더 다양한 일을 할 수 있으므로 오늘날에는 큰 의미가 없다. 또한, eBPF랑 BPF는 서로 잘 구분하지 않는다. 실제로 eBPF programming에서 흔히 사용되는 기술이 BPF이다. 가령 eBPF와 상호작용하기 위한 system call이 bpf()이고 helper 함수들은 모두 bpf_로 시작한다.
Linux Kernel
eBPF를 이해하기위해서 linux의 kernel과 user space에 대해서 이해할 필요가 있다.
Linux Kernel은 application와 application이 동작하고 있는 hardware 사이의 software layer이다. hardware에 직접 접근할 수 없는 user space라고 불리는 unprivileged layer에서 application이 동작한다. 대신에 application은 system call(syscall)을 호출하여 kernel에게 hardware를 대신 접근할 것을 요청한다. kernel을 호출해 hardware 동작을 명령하는 것은 file을 쓰거나 읽는 동작, network traffic을 전송하거나 받는 동작, memory에 접근하는 동작 등이 있다. kernel는 또한 여러 application들이 동시에 동작하도록 하여 concurrent processes를 조정하는 역할도 가지고 있다.
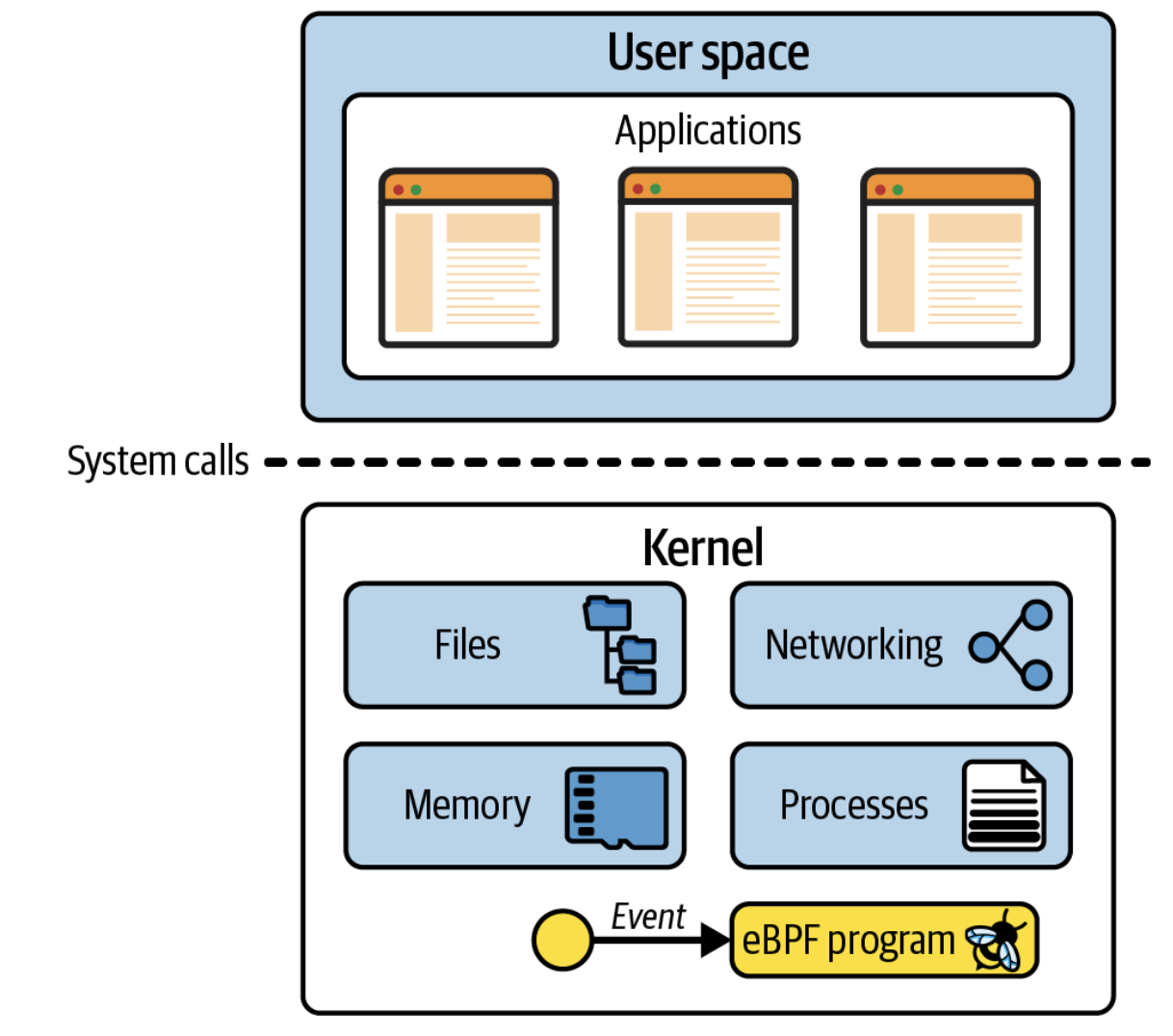
Application 개발자로서 system call interface를 직접 호출하지 않는데 이는 programming language에서 개발자에게 높은 수준의 추상화를 제공하고 쉽게 접근할 수 있는 interface를 제공하기 때문이다. 때문에 수많은 application 개발자들이 우리의 program이 동작하는 동안에 kernel이 얼마나 동작하고 있고, 어떻게 동작하는지 모르는 상태에서 개발이 가능한 것이다. 만약 application이 만든 system call이 kernel에 얼마나 많이 관여되고 동작하고 있는 지 알고 싶다면 strace tool을 사용하면 된다.
echo를 사용하여 hello 라는 word를 화면에 보여줄 때 100가지가 넘는 system call이 호출된다.
strace -c echo "hello"
hello
% time seconds usecs/call calls errors syscall
------ ----------- ----------- --------- --------- ----------------
24.62 0.001693 56 30 12 openat
17.49 0.001203 60 20 mmap
15.92 0.001095 57 19 newfstatat
15.66 0.001077 53 20 close
10.35 0.000712 712 1 execve
3.04 0.000209 52 4 mprotect
2.52 0.000173 57 3 read
2.33 0.000160 53 3 brk
2.09 0.000144 48 3 munmap
1.11 0.000076 76 1 write
0.96 0.000066 66 1 1 faccessat
0.76 0.000052 52 1 getrandom
0.68 0.000047 47 1 rseq
0.65 0.000045 45 1 set_robust_list
0.63 0.000043 43 1 prlimit64
0.61 0.000042 42 1 set_tid_address
0.58 0.000040 40 1 futex
------ ----------- ----------- --------- --------- ----------------
100.00 0.006877 61 111 13 totalapplication들은 kernel에 상당히 많이 의존하기 때문에, 만약 우리가 kernel과의 상호작용을 할 수 있다면, 어떻게 application이 동작하는 상당히 많은 부분을 알 수 있다. 이러한 통찰력을 얻기 위해서 eBPF를 사용하여 kernel에 계측 코드를 추가할 수 있다.
가령 file을 여는 동작에 관한 system call을 intercept할 수 있다면, 어떤 file이 application이 동작하는데 접근하였는지 확실히 알 수 있다. 그렇다면 이렇게 intercept 등과 같은 기능들이 kernel에 들어가기 위해서는 어떻게 해야할까?
kernel에 새로운 기능 추가하기
linux kernel은 굉장히 복잡하다 무려 30백만 line의 code가 있으며 내용도 꽤 어렵기 때문이다.
또한, linux kernel에 새기능을 추가한다는 것은 기술적인 문제 뿐만 아니라, 커뮤니티적인 문제들도 해결해야한다. linux는 general purpose를 위한 open source이기 때문에 community에서 이를 이해하고 적용해야한다. 따라서, 개인의 문제나 특정 company의 문제를 linux kernel에 추가하는 일은 거의 불가능하다.
또한, 기능이 추가되었다해도 linux kernel이 새로 빌드되고 배포되기 까지 매우 오랜시간이 걸린다. linux kernel에 관해서 여러 linux distribution들이 나오게 된 이유가 바로 이러한 이유 때문이다. Debian, Red Hat, Alpine, Ubuntu와 같은 회사들은 linux kernel을 자신의 회사들 정책에 따라서 version을 관리하기 때문이다. 재밌는 것은 linux kernel에 추가한 기능을 linux distribution에서 받아들이기 가지 꽤 오랜시간이 지난다는 것이다.
다음의 만화는 위의 내용을 유쾌하게 풀어내었다.

Kernel modules
위와 같이 kernel에 기능을 추가하는데 있어 오랜 시간이 걸리는 문제를 살펴보았다. 이러한 문제가 생기지 않도록 linux에서는 module 기능을 제공한다. linux kernel는 개발자가 원하는 상황에 따라 linux module을 적재하고, 빼낼 수 있는 module system을 제공하도록 설계되었다. 만약 linux kernel의 동작을 변경하고싶거나 확장하고 싶다면 module을 작성하는 것이 하나의 방법이다. kernel module은 official linux kernel release와 무관하게 사용하기 위해 배포되므로 kernel module이 main upstream codebase에 받아들여지는 일은 없다.
문제는 kernel module을 만드는 것은 kernel programming에 관련된 일이었고, 이것은 너무 어렵기 때문에 kernel에 문제가 생기면 전체 시스템을 망가뜨리는 일이 빈번했다. 어떻게하면 개발자들이 안전하게 kernel module을 만들고 이를 kernel system에 적재할 수 있을까?
'안전하게 동작'한다는 것은 단지 crashing을 의미하는 것이 아니다. 개발자는 또한 kernel module이 보안적으로 안전하게 동작하기를 바란다. 왜냐하면 kernel module을 해킹한다면 시스템 전체를 해킹하여 데이터를 갈취할 수 있기 때문이다. 또한, 신뢰할 수 없는 kernel module 개발자가 작성한 module을 적용했을 때 시스템을 의도적으로 다운시키거나 바이러스를 주입할 수도 있다.
기존의 방법은 그저 다양한 linux kernel version으로 오랜동안 써보면서 검증하는 것이 전부였다. 하지만 eBPF는 다른 방법으로 safety를 제공하는데 the eBPF verifier이다. 이는 eBPF program이 동작하는데 오직 안전한 상태에 있어야만 적재가 되도록 한다. 이는 module이 machine을 crashing내지 않도록 하거나 hard loop안에 가두어버린다. 또한 data가 손상되지 않도록 한다.
eBPF Program의 동적 로딩
eBPF program들은 kernel에 동적으로 로딩되거나 삭제될 수도 있다. 일단 eBPF program이 특정 event에 달라붙으면, event가 발생할 때 eBPF program이 실행된다. 가령 만약 eBPF program을 file들을 여는 syscall에 붙여놓으면, process가 file을 열 때마다 eBPF program이 실행된다. 이는 eBPF program이 로딩되었을 때, process가 먼저 동작중과는 상관없다. 이는 kernel 자체를 upgrade하는 것과 새로운 기능을 추가하기위해서 machine을 재부팅해야하는 것과는 비교도 안될 정도로 좋은 장점이다.
이는 eBPF를 사용하는 observability 또는 security tooling의 가장 큰 장점을 이끈다. eBPF가 시작되는 즉시 machine에 대해서 관찰이 가능하기 때문이다. container가 동작하는 환경에서는 host machine뿐만 아니라 container에서도 동작하는 모든 rpocess에 대해서 가시성을 확보할 수 있다.
추가적으로 eBPF를 통해서 새로운 kernel 기능을 빠르게 사용할 수 있는 것을 보여준다.

eBPF program의 높은 성능
eBPF program은 분석(계측) 기능을 추가하는데 있어 매우 효율적인 방법이다. 일단 적재되면 JIT-compiled되면 eBPF program은 CPU에 native machine 명령어로 동작한다. 추가적으로 각 event를 처리하기이해서 kernel과 user space 간의 전환에 따른 비용을 부담할 필요가 없다.
2018년에 출간된 eXpress Data Path(XDP)를 설명하는 논문에는 eBPF가 networking에서 성능 향상을 어떻게 가져오는 지에 대한 몇가지 예시가 나와 있다. 가령, XDP에 routing을 구현하는 것이 기존 linux kernel 구현보다 2.5배 빠르다고하며 XDP는 IPVS에 대해 load balancing으로 4.3배 성능 향상이 있다고 한다.
성능 추적과 security 관측에 있어서, eBPF의 장점은 관련된 event가 user space로 전달되어 발생하는 비용이전에 kernel에서 event를 filtering할 수 있다는 것이다. 필터링 뿐만 아니라 현재 eBPF program은 system의 모든 event에 대한 정보를 수집할 수 있으며, 복잡한 사용자 프로그래밍 filter를 사용하여 오직 관련된 정보의 하위 집합을 user space로 전달할 수 있다.
eBPF in cloud native environment
docker와 같은 container는 host machine의 kernel을 공유하고 있기 때문에 이들은 모두 os로부터 같은 기능을 제공받는다. kubernetes에서는 host node에 있는 모든 pod들과 그 안의 conatiner들이 같은 kernel을 사용하고 있다는 것이다. 우리가 eBPF로 해당 kernel을 조율하면 해당 node에 containerized된 모든 workload들은 eBPF program에 보여지게 된다. 다음의 그림을 보도록 하자.
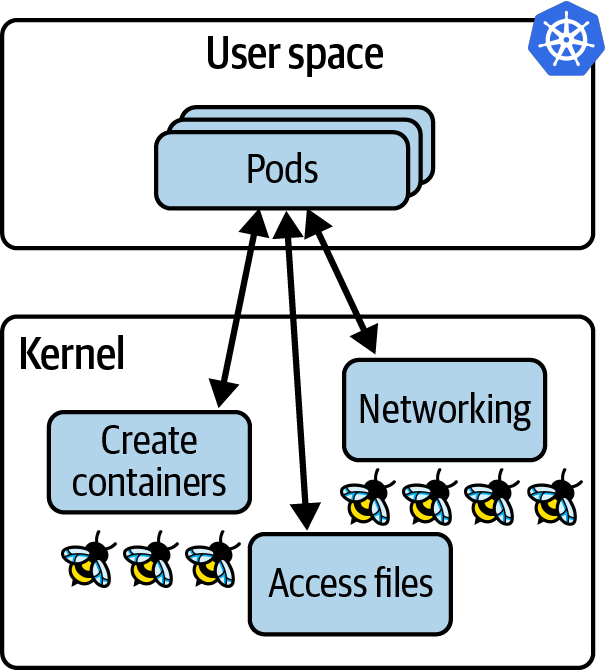
이는 다음의 장점을 가져다 준다.
1. eBPF tooling을 사용하여 pod들에 추가적인 기능을 주기위해서 우리의 application을 수정하거나 configuration을 변경할 필요가 없다.
2. kernel에 적재되고 event에 eBPF program이 붙자마자 eBPF program은 application에 대한 관찰을 시작한다.
이와 가장 대비되는 모델이 바로 sidecar model이다. sidecar model은 kubernetes app에게 logging, tracing, security와 같은 service mesh 기능을 추가하기 위해 사용되었다. sidecar 접근 방법에서는 instrumentation이 container로서 동작하여 각 application pod에 주입되었다. 이 과정은 application pod를 정의하는 YAML 파일을 수정하여야 하고, sidecar definition을 YAML 파일에 추가해야했다. sidecar 방법은 eBPF가 등장하기 이전까지만 해도 가장 스마트한 해결책으로 application source code를 변경하지 않아도 여러 instrumentation을 추가할 수 있어 선호되었다. 가장 유명한 service mesh program으로 istio, linkerd 등이 있다.
그러나 sidecar 방법론은 몇가지 문제점이 있었는데, 다음과 같다.
1. sidecar가 추가된 다음 application pod가 배포되어야 하므로, sidecar가 주입되면 application pod를 재시작해야한다.
2. 보통 pod에 label을 통해 sidecar container를 pod에 주입하는 방식을 사용하므로 yaml파일을 수정해야한다. 문제는 특정 application들은 권한 문제가 있거나, label이 삭제되는 등의 문제로 sidecar가 주입되지 않은 경우가 있었다.
3. 한 pod에 여러개의 container들이 있을 때, readiness(준비상태)에 이르는 시간이 다르며 이들의 순서는 예측이 불가능할 수 있다. sidecar의 주입으로 인해 pod 시작 시간이 현격히 감소할 수 있으며, 더 나쁜 경우는 race condition이나 불안정성이 발생할 수 있다. 가령 Open Service Mesh에서는 application container가 Envoy proxy container(sidecar container)가 준비될 때까지 모든 traffic이 삭제되는 것에 대해서 탄력적으로 대응해야한다고 한다. 즉 알아서 하라는 것이다.
4. service mesh와 같은 networking 기능이 sidecar로 구현되었을 때, 모든 application traffic이 sidecar로 주입된 network proxy container를 거쳐야 한다는 것을 의미한다. 이는 latency를 늘리는데, 다음의 그림을 참고하면 이해하기 쉽다.
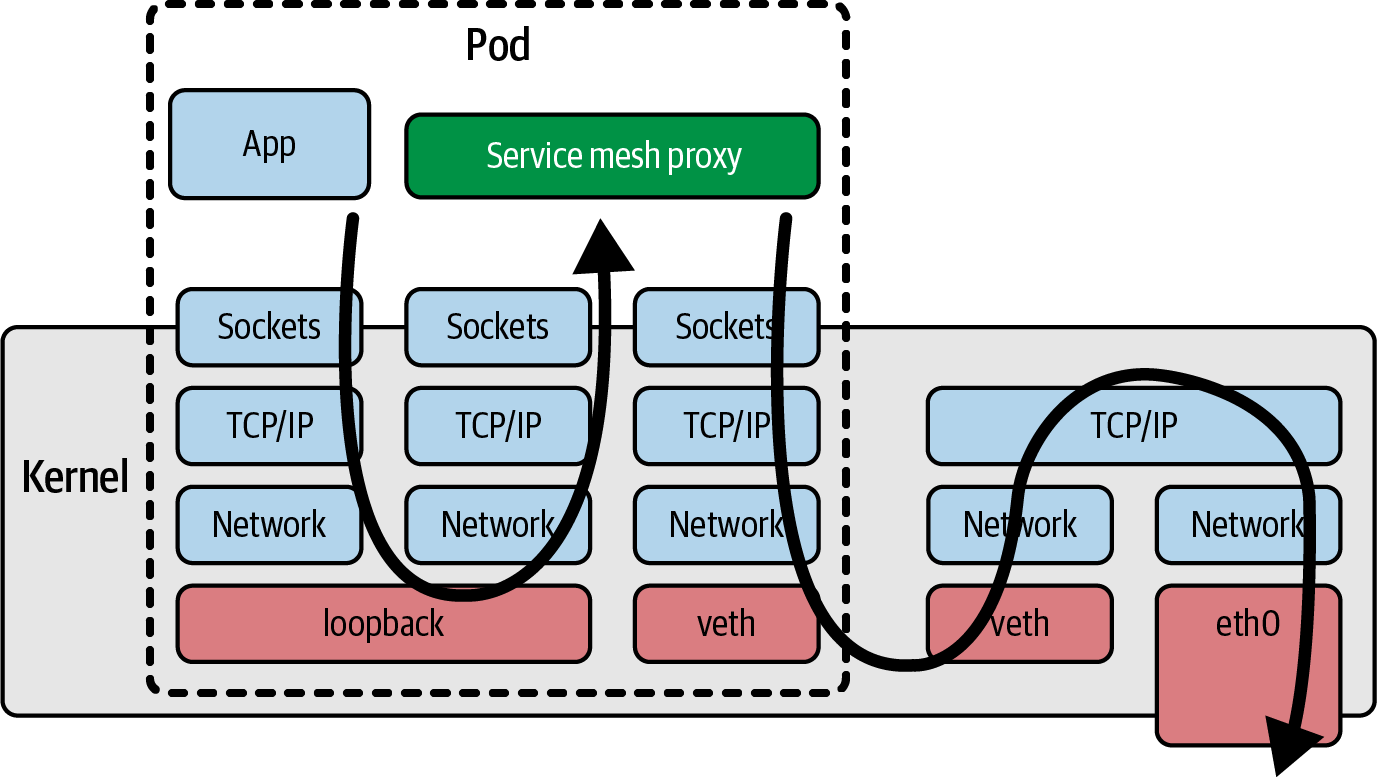
이 모든 issue들은 사실 sidecar가 가진 문제들이다. eBPF에서는 platform으로서 동작이 가능하고, 이러한 issue를 피할 수 있는 새로운 모델들을 가지고 있다. 추가적으로 eBPF기반 툴들은 machine에서 발생하는 모든 event들을 관측할 수 있다. 이는 악의적인 행위를 하는 사람이 우회하는 것을 더 어렵게하는 것을 의미한다.
가령, 만약 공격자가 host machine에 체굴 프로그램을 설치하려고 한다면, eBPF에서는 host machine에 오는 모든 traffic을 감시할 수 있어 설치가 불가능하다. 반면 sidecar는 host machine에 sidecar가 주입되는 것이 아니기 때문에 이러한 문제를 해결할 수 없다.
