일대다 맵핑과 Join
'사용자'와 '주문' 테이블이 있다고 하자. 사용자는 여러 개의 주문을 만들 수 있고, 주문 한 개는 한 사람에게 연계된다. 따라서 이 관계는 일대다 관계를 만족한다.
이들을 처음부터 하나의 table로 만드는 것은 좋은 아이디어가 아니다. 두개의 다른 table의 관계를 보도록 하자.
Customers(customer_id, first_name, last_name, email);
Orders(order_id, order_date, amount, customer_id);이 두 테이블의 연결점은 customer_id이다. 이 연결점을 중심으로 두 table의 데이터들을 연결해줄 수 있다. 잘 보면 customer_id는 Customer의 Primary Key(PK)라는 것이다. 따라서, 고유성이 있고 Order table은 customer_id에 해당하는 정확히 딱 하나의 row에 Order의 row들이 매칭된다는 것이다.
Order 입장에서 customer_id는 하나의 외부 table과 join하는 Foreign Key(FK, 외래키)가 된다. 따라서 Foreign key의 대상이 되는 값은 반드시 다른 table의 Primary Key여야 한다.
이제 Customer와 Order table을 만들어보도록 하자.
CREATE TABLE customers (
id INT PRIMARY KEY AUTO_INCREMENT,
first_name VARCHAR(50),
last_name VARCHAR(50),
email VARCHAR(50)
);
CREATE TABLE orders (
id INT PRIMARY KEY AUTO_INCREMENT,
order_date DATE,
amount DECIMAL(8,2),
customer_id INT
);위와 같이 만들 수 있다. orders table의 customer_id field는 customers의 id값을 의미하는 field이므로 동일한 타입인 INT로 넣어야 한다.
이제 data들을 넣어보도록 하자.
INSERT INTO customers (first_name, last_name, email)
VALUES ('Boy', 'George', 'george@gmail.com'),
('George', 'Michael', 'gm@gmail.com'),
('David', 'Bowie', 'david@gmail.com'),
('Blue', 'Steele', 'blue@gmail.com'),
('Bette', 'Davis', 'bette@aol.com');
INSERT INTO orders (order_date, amount, customer_id)
VALUES ('2016-02-10', 99.99, 1),
('2017-11-11', 35.50, 1),
('2014-12-12', 800.67, 2),
('2015-01-03', 12.50, 2),
('1999-04-11', 450.25, 5);제대로 값들이 입력되었는 지 확인해보도록 하자.
SELECT * FROM orders;
+----+------------+--------+-------------+
| id | order_date | amount | customer_id |
+----+------------+--------+-------------+
| 1 | 2016-02-10 | 99.99 | 1 |
| 2 | 2017-11-11 | 35.50 | 1 |
| 3 | 2014-12-12 | 800.67 | 2 |
| 4 | 2015-01-03 | 12.50 | 2 |
| 5 | 1999-04-11 | 450.25 | 5 |
+----+------------+--------+-------------+제대로 데이터들이 입력된 것을 볼 수 있다.
orders table에 새로운 데이터를 넣어보되, customer_id값을 현재 없는 값으로 넣어보도록 하자.
INSERT INTO orders (order_date, amount, customer_id)
VALUES ('2022-11-11', 50.68, 975);975는 현재 customers table에 없지만, 문제없이 추가될 것이다. 그러나 customers table에 없는 customer_id를 지칭하는 것이 실제 존재하지 않는 customer를 지칭하는 것인지, 또는 있었는 데 사라진 customer를 지칭하는 것인지 구분이 안된다. 따라서, cusomter_id는 실제로 customers table에 존재하는 id 값을 지칭하도록 제약 조건을 붙여야한다.
이것이 바로 외래키 제약 조건이라고 한다. mysql에서는 table 설정 시에 외래키 제약 조건을 설정할 수 있는데 문법은 다음과 같다.
FOREIGN KEY (FK) REFERENCES customers(PK);orders table을 다음과 같이 만들 수 있다.
CREATE TABLE orders (
id INT PRIMARY KEY AUTO_INCREMENT,
order_date DATE,
amount DECIMAL(8,2),
customer_id INT,
FOREIGN KEY (customer_id) REFERENCES customers(id)
);이제 orders는 customer_id를 추가할 때 customers table에 실제로 존재하는 id값을 지칭해야만 한다.
외래키 제약 조건을 반영하기 위해서 orders table을 없애주도록 하자.
DROP TABLE orders;
CREATE TABLE orders (
id INT PRIMARY KEY AUTO_INCREMENT,
order_date DATE,
amount DECIMAL(8,2),
customer_id INT,
FOREIGN KEY (customer_id) REFERENCES customers(id)
);
INSERT INTO orders (order_date, amount, customer_id)
VALUES ('2016-02-10', 99.99, 1),
('2017-11-11', 35.50, 1),
('2014-12-12', 800.67, 2),
('2015-01-03', 12.50, 2),
('1999-04-11', 450.25, 5);문제없이 데이터가 들어갈 것이다. customer_id가 1, 2, 5는 실제 customers table에 있는 값이기 때문이다.
다음으로 customers table에 없는 id값을 가진 customer_id 값을 추가하자.
INSERT INTO orders (order_date, amount, customer_id)
VALUES ('2022-11-11', 50.68, 975);
ERROR 1452 (23000): Cannot add or update a child row: a foreign key constraint fails (`gyu`.`orders`, CONSTRAINT `orders_ibfk_1` FOREIGN KEY (`customer_id`) REFERENCES `customers` (`id`)) foreign key constraint에 의해서 실패한 것을 볼 수 있다. foreign key 제약조건에 의해서 FK는 실제로 존재하는 PK값을 지칭해야한다는 것이 된다. 이를 데이터베이스에서 데이터 무결성 유지라고 한다.
Cross Join
이제 FK를 설정하여 orders table와 customers table을 연결하였으니 어떻게 이 서로 다른 table이 하나의 table로 만들어지는 지 보도록 하자.
가령 George가 주문한 주문 내역을 보고 싶다고 하자. 먼저 George의 PK인 id값을 찾아내도록 하자.
SELECT id FROM customers WHERE last_name = 'George';
+----+
| id |
+----+
| 1 |
+----+id값으로 1이 나오는 것을 알 수 있다. 이 id값에 해당하는 customer_id값을 가진 order를 가져와보도록 하자.
SELECT * FROM orders WHERE customer_id = 1;
+----+------------+--------+-------------+
| id | order_date | amount | customer_id |
+----+------------+--------+-------------+
| 1 | 2016-02-10 | 99.99 | 1 |
| 2 | 2017-11-11 | 35.50 | 1 |
+----+------------+--------+-------------+George가 가진 order들이 두 개 있는 것을 볼 수 있다. 이 과정을 하나의 sql문으로 만들면 다음과 같다.
SELECT * FROM orders
WHERE customer_id = (SELECT id FROM customers WHERE last_name = 'George');
+----+------------+--------+-------------+
| id | order_date | amount | customer_id |
+----+------------+--------+-------------+
| 1 | 2016-02-10 | 99.99 | 1 |
| 2 | 2017-11-11 | 35.50 | 1 |
+----+------------+--------+-------------+그러나 orders table과 customers table의 정보가 함께 나오지 않고 있다. 이를 위해서 JOIN을 사용하는 것이다.
JOIN 문법을 사용하기 이전에 많이 사용되지는 않지만 가장 기본적인 JOIN인 cross join(cartesian join)에 대해서 알아보도록 하자. 이는 join하려는 두 테이블의 모든 field의 조합을 하는 것을 말한다. 예시를 보는 것이 더 쉽다.
SELECT * FROM customers, orders;
+----+------------+-----------+------------------+----+------------+--------+-------------+
| id | first_name | last_name | email | id | order_date | amount | customer_id |
+----+------------+-----------+------------------+----+------------+--------+-------------+
| 5 | Bette | Davis | bette@aol.com | 1 | 2016-02-10 | 99.99 | 1 |
| 4 | Blue | Steele | blue@gmail.com | 1 | 2016-02-10 | 99.99 | 1 |
| 3 | David | Bowie | david@gmail.com | 1 | 2016-02-10 | 99.99 | 1 |
| 2 | George | Michael | gm@gmail.com | 1 | 2016-02-10 | 99.99 | 1 |
| 1 | Boy | George | george@gmail.com | 1 | 2016-02-10 | 99.99 | 1 |
| 5 | Bette | Davis | bette@aol.com | 2 | 2017-11-11 | 35.50 | 1 |
| 4 | Blue | Steele | blue@gmail.com | 2 | 2017-11-11 | 35.50 | 1 |
| 3 | David | Bowie | david@gmail.com | 2 | 2017-11-11 | 35.50 | 1 |
| 2 | George | Michael | gm@gmail.com | 2 | 2017-11-11 | 35.50 | 1 |
| 1 | Boy | George | george@gmail.com | 2 | 2017-11-11 | 35.50 | 1 |
| 5 | Bette | Davis | bette@aol.com | 3 | 2014-12-12 | 800.67 | 2 |
| 4 | Blue | Steele | blue@gmail.com | 3 | 2014-12-12 | 800.67 | 2 |
| 3 | David | Bowie | david@gmail.com | 3 | 2014-12-12 | 800.67 | 2 |
| 2 | George | Michael | gm@gmail.com | 3 | 2014-12-12 | 800.67 | 2 |
| 1 | Boy | George | george@gmail.com | 3 | 2014-12-12 | 800.67 | 2 |
| 5 | Bette | Davis | bette@aol.com | 4 | 2015-01-03 | 12.50 | 2 |
| 4 | Blue | Steele | blue@gmail.com | 4 | 2015-01-03 | 12.50 | 2 |
| 3 | David | Bowie | david@gmail.com | 4 | 2015-01-03 | 12.50 | 2 |
| 2 | George | Michael | gm@gmail.com | 4 | 2015-01-03 | 12.50 | 2 |
| 1 | Boy | George | george@gmail.com | 4 | 2015-01-03 | 12.50 | 2 |
| 5 | Bette | Davis | bette@aol.com | 5 | 1999-04-11 | 450.25 | 5 |
| 4 | Blue | Steele | blue@gmail.com | 5 | 1999-04-11 | 450.25 | 5 |
| 3 | David | Bowie | david@gmail.com | 5 | 1999-04-11 | 450.25 | 5 |
| 2 | George | Michael | gm@gmail.com | 5 | 1999-04-11 | 450.25 | 5 |
| 1 | Boy | George | george@gmail.com | 5 | 1999-04-11 | 450.25 | 5 |
+----+------------+-----------+------------------+----+------------+--------+-------------+정말 customers에 있는 모든 row들과 orders table에 있는 모든 row들에 대해서 cartesian 곱 연산을 한 것이다. cross join이라고 불리는 이유도 vector의 cross와 같은 의미라서이다.
customers table에 5개의 row가 있고 orders에 5개의 row가 있으니 이들의 cross join 결과는 모든 row들 끼리의 join이므로 5*5이다.
실제로 cross join은 사용되지 않는다. 연산 부하가 너무 많고 이렇게 join해서 쓸 일도 없기 때문이다.
Inner Join
Inner Join은 A table와 B table이 있다면 두 table의 공통부분을 남기는 JOIN이다.

그럼 우리의 customers table과 orders table을 분석해보도록 하자.
SELECT * FROM customers;
+----+------------+-----------+------------------+
| id | first_name | last_name | email |
+----+------------+-----------+------------------+
| 1 | Boy | George | george@gmail.com |
| 2 | George | Michael | gm@gmail.com |
| 3 | David | Bowie | david@gmail.com |
| 4 | Blue | Steele | blue@gmail.com |
| 5 | Bette | Davis | bette@aol.com |
+----+------------+-----------+------------------+
SELECT * FROM orders;
+----+------------+--------+-------------+
| id | order_date | amount | customer_id |
+----+------------+--------+-------------+
| 1 | 2016-02-10 | 99.99 | 1 |
| 2 | 2017-11-11 | 35.50 | 1 |
| 3 | 2014-12-12 | 800.67 | 2 |
| 4 | 2015-01-03 | 12.50 | 2 |
| 5 | 1999-04-11 | 450.25 | 5 |
+----+------------+--------+-------------+customer_id가 1,2,5만 있는 것을 볼 수 있다. 즉, 3,4 는 없으므로 이들 간의 결합에서는 customers의 3과 4는 빠지게 된다.
INNER JOIN 문법은 다음과 같다. A table과 B table을 Inner join한다면 다음과 같다.
SELECT * FROM A
JOIN B ON A.PK = B.FK;A와 B 테이블의 위치를 바꿔도 된다. 단, FROM 절에 쓰인 table의 data가 더 먼저 나온다는 특성이 있다. ON에는 조건을 써주면 되는 데 join의 조건은 PK와 FK가 서로 일치하는 값을 써주면 된다.
orders와 customers table의 join은 다음과 같이 할 수 있다.
SELECT * FROM customers
JOIN orders ON orders.customer_id = customers.id;
+----+------------+-----------+------------------+----+------------+--------+-------------+
| id | first_name | last_name | email | id | order_date | amount | customer_id |
+----+------------+-----------+------------------+----+------------+--------+-------------+
| 1 | Boy | George | george@gmail.com | 1 | 2016-02-10 | 99.99 | 1 |
| 1 | Boy | George | george@gmail.com | 2 | 2017-11-11 | 35.50 | 1 |
| 2 | George | Michael | gm@gmail.com | 3 | 2014-12-12 | 800.67 | 2 |
| 2 | George | Michael | gm@gmail.com | 4 | 2015-01-03 | 12.50 | 2 |
| 5 | Bette | Davis | bette@aol.com | 5 | 1999-04-11 | 450.25 | 5 |
+----+------------+-----------+------------------+----+------------+--------+-------------+결과를 보면 서로 일치하는 공통 부분(교집합)만 join의 결과로 나오는 것을 볼 수 있다. 잘보면 id와 customer_id가 동일한 것을 볼 수 있다.
반대로 이번에는 orders를 FROM에 넣고, JOIN에 customers를 넣도록 하자.
SELECT * FROM orders
JOIN customers ON customers.id = orders.customer_id;
+----+------------+--------+-------------+----+------------+-----------+------------------+
| id | order_date | amount | customer_id | id | first_name | last_name | email |
+----+------------+--------+-------------+----+------------+-----------+------------------+
| 1 | 2016-02-10 | 99.99 | 1 | 1 | Boy | George | george@gmail.com |
| 2 | 2017-11-11 | 35.50 | 1 | 1 | Boy | George | george@gmail.com |
| 3 | 2014-12-12 | 800.67 | 2 | 2 | George | Michael | gm@gmail.com |
| 4 | 2015-01-03 | 12.50 | 2 | 2 | George | Michael | gm@gmail.com |
| 5 | 1999-04-11 | 450.25 | 5 | 5 | Bette | Davis | bette@aol.com |
+----+------------+--------+-------------+----+------------+-----------+------------------+결과는 이전과 똑같지만 field의 순서만 달라진다는 것을 알 수 있다. 궁극적으로 inner join은 둘의 공통 부분을 가져온다는 것을 알 수 있다.
필요한 field들만 추출해서 출력하는 것도 가능하다.
SELECT orders.id, amount, last_name, email FROM orders
JOIN customers ON customers.id = orders.customer_id;
+----+--------+-----------+------------------+
| id | amount | last_name | email |
+----+--------+-----------+------------------+
| 1 | 99.99 | George | george@gmail.com |
| 2 | 35.50 | George | george@gmail.com |
| 3 | 800.67 | Michael | gm@gmail.com |
| 4 | 12.50 | Michael | gm@gmail.com |
| 5 | 450.25 | Davis | bette@aol.com |
+----+--------+-----------+------------------+id같은 경우는 조심해야하는데, customers와 orders가 같은 id라는 field 이름을 가지고 있으니, 이들을 구분할 수 있도록 orders.id로 써주어야 한다.
Inner join을 사용하여 어떤 것들을 할 수 있는 지 알아보자. 먼저 customers와 orders를 join해보도록 하자
SELECT first_name, last_name, order_date, amount FROM customers
JOIN orders ON orders.customer_id = customers.id;
+------------+-----------+------------+--------+
| first_name | last_name | order_date | amount |
+------------+-----------+------------+--------+
| Boy | George | 2016-02-10 | 99.99 |
| Boy | George | 2017-11-11 | 35.50 |
| George | Michael | 2014-12-12 | 800.67 |
| George | Michael | 2015-01-03 | 12.50 |
| Bette | Davis | 1999-04-11 | 450.25 |
+------------+-----------+------------+--------+각 customer가 구입한 amount 총량을 계산하고 싶다. 이럴 때 사용할 수 있는 것이 바로 group by이다. first_name, last_name을 함께 그룹으로 묶은 다음 amount를 sum으로 더하는 것이다.
SELECT first_name, last_name, SUM(amount) AS total
FROM customers
JOIN orders ON orders.customer_id = customers.id
GROUP BY first_name , last_name
ORDER BY total;
+------------+-----------+--------+
| first_name | last_name | total |
+------------+-----------+--------+
| Boy | George | 135.49 |
| Bette | Davis | 450.25 |
| George | Michael | 813.17 |
+------------+-----------+--------+Boy George, Bette Davis, George Michael을 묶어내어 주문한 금액의 총량인 total을 알아낸 것이다.
Left Join
left join은 inner join에서 공통 부분만이 아니라 왼쪽 부분의 모든 row들도 출력하도록 하는 것이다.
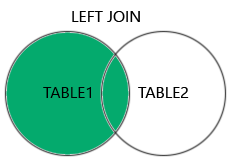
즉, A table과 B table 공통 부분인 FK와 PK가 일치하는 row들만 뽑아내는 것이 아니라, A table에 있는 row들도 모두 뽑아낸다. 단, FK와 PK가 일치하지 않는 row들에 대해서는 B table의 field에 대해서 NULL 값을 채워준다.
left join은 Inner join에서 LEFT만 붙이면 된다.
SELECT * FROM A
LEFT JOIN B ON B.FK = A.PK;A table이 왼쪽에 위치하게 되므로 A table의 모든 row들이 나오게 된다.
customers와 orders의 left join을 시켜보도록 하자. 먼저 inner join 결과를 만들고, left join 결과와 비교해보도록 하자.
SELECT first_name, last_name, order_date, amount FROM customers
JOIN orders ON orders.customer_id = customers.id;
+------------+-----------+------------+--------+
| first_name | last_name | order_date | amount |
+------------+-----------+------------+--------+
| Boy | George | 2016-02-10 | 99.99 |
| Boy | George | 2017-11-11 | 35.50 |
| George | Michael | 2014-12-12 | 800.67 |
| George | Michael | 2015-01-03 | 12.50 |
| Bette | Davis | 1999-04-11 | 450.25 |
+------------+-----------+------------+--------+
SELECT first_name, last_name, order_date, amount FROM customers
LEFT JOIN orders ON orders.customer_id = customers.id;
+------------+-----------+------------+--------+
| first_name | last_name | order_date | amount |
+------------+-----------+------------+--------+
| Boy | George | 2016-02-10 | 99.99 |
| Boy | George | 2017-11-11 | 35.50 |
| George | Michael | 2014-12-12 | 800.67 |
| George | Michael | 2015-01-03 | 12.50 |
| David | Bowie | NULL | NULL |
| Blue | Steele | NULL | NULL |
| Bette | Davis | 1999-04-11 | 450.25 |
+------------+-----------+------------+--------+inner join은 row가 5개인데, left join은 7개이다. inner join의 경우 공통 부분만 추출된 것이지만 left join은 공통 부분 외에도 customers의 모든 row들을 추출한다. 단, orders와 맵핑되지 않은 row들에 대해서는 orders의 field 값을 NULL로 채워준다.
이를 통해서 알 수 있는 것은 David Bowie와 Blue Steele는 아무런 주문을 하지 않았다는 것이다.
그럼 왼쪽 테이블의 순서를 바꿔보도록 하자.
SELECT first_name, last_name, order_date, amount FROM orders
LEFT JOIN customers ON orders.customer_id = customers.id;
+------------+-----------+------------+--------+
| first_name | last_name | order_date | amount |
+------------+-----------+------------+--------+
| Boy | George | 2016-02-10 | 99.99 |
| Boy | George | 2017-11-11 | 35.50 |
| George | Michael | 2014-12-12 | 800.67 |
| George | Michael | 2015-01-03 | 12.50 |
| Bette | Davis | 1999-04-11 | 450.25 |
+------------+-----------+------------+--------+이번에는 왼쪽이 orders table이므로 PK, FK가 일치한 row들 뿐만 아니라 orders table의 모든 row들이 함께 나온다. 그러나, 생각해보면 orders는 FK를 가진 table이므로 PK를 가진 customers table에 id값이 있는 값만 존재할 것이다. 따라서, orders table의 left join은 PK와 FK가 일치한 공통 부분이 나오는 것이 맞고 이는 inner join과 동일하다.
groupby를 하기 전에 left join으로 결과를 확인해보도록 하자.
SELECT first_name, last_name, amount FROM customers
LEFT JOIN orders ON customers.id = orders.customer_id;
+------------+-----------+--------+
| first_name | last_name | amount |
+------------+-----------+--------+
| Boy | George | 99.99 |
| Boy | George | 35.50 |
| George | Michael | 800.67 |
| George | Michael | 12.50 |
| David | Bowie | NULL |
| Blue | Steele | NULL |
| Bette | Davis | 450.25 |
+------------+-----------+--------+David Bowie와 Blue Steele의 경우는 NULL이 나오는 것을 알 수 있다. 이들은 구매한 내역이 없기 때문이다. 그런데 이 값은 보기가 좋지 않다. 같은 산수들끼리 연산을 하는 것이 좋기 때문이다. 그래서 NULL을 0으로 바꿔주도록 하자.
IFNULL을 사용하여 NULL이 나오면 0으로 바꿔보도록 하자. 사용 방법은 다음과 같다.
IFNULL(SUM(amount), 0)SUM(amount)에 NULL이 있다면 0으로 바꾸라는 것이다. 이제 groupby를 해보도록 하자.
SELECT first_name, last_name, IFNULL(SUM(amount), 0) AS money_spent FROM customers
LEFT JOIN orders ON customers.id = orders.customer_id
GROUP BY first_name, last_name;
+------------+-----------+-------------+
| first_name | last_name | money_spent |
+------------+-----------+-------------+
| Boy | George | 135.49 |
| George | Michael | 813.17 |
| David | Bowie | 0.00 |
| Blue | Steele | 0.00 |
| Bette | Davis | 450.25 |
+------------+-----------+-------------+결과를 확인하면 다음과 같다. NULL로 나온 값들이 0으로 치환되었다.
Right Join
이번에는 right join이다. A table과 B table이 있을 때 겹치는 부분과 함께 오른쪽 B table의 row들을 모두 가져오는 것이다.
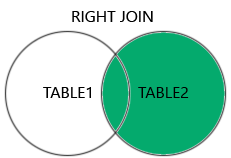
먼저 일반적인 inner join을 해보자.
SELECT first_name, last_name, order_date, amount FROM customers
JOIN orders ON customers.id = orders.customer_id;
+------------+-----------+------------+--------+
| first_name | last_name | order_date | amount |
+------------+-----------+------------+--------+
| Boy | George | 2016-02-10 | 99.99 |
| Boy | George | 2017-11-11 | 35.50 |
| George | Michael | 2014-12-12 | 800.67 |
| George | Michael | 2015-01-03 | 12.50 |
| Bette | Davis | 1999-04-11 | 450.25 |
+------------+-----------+------------+--------+공통부분들만 잘 오는 것을 볼 수 있다. 이제 RIGHT join을 사용해보도록 하자. join 앞에 RIGHT를 사용하면 된다.
SELECT first_name, last_name, order_date, amount FROM customers
RIGHT JOIN orders ON customers.id = orders.customer_id;
+------------+-----------+------------+--------+
| first_name | last_name | order_date | amount |
+------------+-----------+------------+--------+
| Boy | George | 2016-02-10 | 99.99 |
| Boy | George | 2017-11-11 | 35.50 |
| George | Michael | 2014-12-12 | 800.67 |
| George | Michael | 2015-01-03 | 12.50 |
| Bette | Davis | 1999-04-11 | 450.25 |
+------------+-----------+------------+--------+Inner join과 동일한 결과가 나온다. 이는 모든 손님들은 주문을 할 수도 안할 수도 있지만, 주문은 손님이 없을 수가 없기 때문이다. 이것이 바로 FK 제약 조건 때문에 발생한 문제이다.
그런데 사실 FK 제약 조건에는 customer_id가 실제로 customers table에 없어도 들어가는 값이 하나있다. 이는 NULL이다.
INSERT INTO orders (amount, order_date)
VALUES (100, CURDATE());customer_id를 주지 않았는데도 불구하고 데이터가 들어간다. 한번 orders table을 확인해보도록 하자.
SELECT * FROM orders;
+----+------------+--------+-------------+
| id | order_date | amount | customer_id |
+----+------------+--------+-------------+
| 1 | 2016-02-10 | 99.99 | 1 |
| 2 | 2017-11-11 | 35.50 | 1 |
| 3 | 2014-12-12 | 800.67 | 2 |
| 4 | 2015-01-03 | 12.50 | 2 |
| 5 | 1999-04-11 | 450.25 | 5 |
| 6 | 2025-04-10 | 100.00 | NULL |
+----+------------+--------+-------------+6번째 id를 가진 row가 NULL인 것을 볼 수 있다.
이제 RIGHT join을 해보도록 하자.
SELECT first_name, last_name, order_date, amount FROM customers
RIGHT JOIN orders ON customers.id = orders.customer_id;
+------------+-----------+------------+--------+
| first_name | last_name | order_date | amount |
+------------+-----------+------------+--------+
| Boy | George | 2016-02-10 | 99.99 |
| Boy | George | 2017-11-11 | 35.50 |
| George | Michael | 2014-12-12 | 800.67 |
| George | Michael | 2015-01-03 | 12.50 |
| Bette | Davis | 1999-04-11 | 450.25 |
| NULL | NULL | 2025-04-10 | 100.00 |
+------------+-----------+------------+--------+right join을 하니 customer_id가 NULL이었던 row에서 first_name과 last_name이 NULL로 나왔다.
그런데, 생각해보면 어떻게 FK가 NULL을 갖도록 허용할 수 있는 것일까?? 이에 대해서는 사실 DB의 설계와 정책에 따라 다르다.
Foreign Key와 데이터 삭제
주문이 없는 고객이 있을 순 있지만, 고객이 없는 주문은 없다. 그러나, 고객이 사라질 수도 있다. 가령 다음의 예제를 보도록 하자.
SELECT first_name, last_name, order_date, amount FROM customers
JOIN orders ON customers.id = orders.customer_id;
+------------+-----------+------------+--------+
| first_name | last_name | order_date | amount |
+------------+-----------+------------+--------+
| Boy | George | 2016-02-10 | 99.99 |
| Boy | George | 2017-11-11 | 35.50 |
| George | Michael | 2014-12-12 | 800.67 |
| George | Michael | 2015-01-03 | 12.50 |
| Bette | Davis | 1999-04-11 | 450.25 |
+------------+-----------+------------+--------+Body George를 삭제하면 어떻게 될까??
DELETE FROM customers WHERE last_name='George';
ERROR 1451 (23000): Cannot delete or update a parent row: a foreign key constraint fails (`gyu`.`orders`, CONSTRAINT `orders_ibfk_1` FOREIGN KEY (`customer_id`) REFERENCES `customers` (`id`))error가 발생하는 것을 볼 수 있다. 이 error 내용을 보면 'foregin key constraint'라는 것을 볼 수 있다. 외래키 제약 조건에 의해서 삭제가 안되는 것을 볼 수 있다. 원래는 FK를 가진 orders의 row들이 먼저 삭제되고 고객인 George가 삭제되어야 한다.
이를 처리하는 몇 가지 방법들이 있다. 이는 website를 어떻게 구축하냐에 따라 다르다. 가령 어떤 사이트는 삭제된 회원의 리뷰를 없애지만, 어떤 사이트는 삭제된 유저라고만 남기고 리뷰를 남긴다. 우리는 customers의 row를 삭제하면 연계된 orders row들도 삭제해주도록 하자.
CREATE TABLE customers (
id INT PRIMARY KEY AUTO_INCREMENT,
first_name VARCHAR(50),
last_name VARCHAR(50),
email VARCHAR(50)
);
CREATE TABLE orders (
id INT PRIMARY KEY AUTO_INCREMENT,
order_date DATE,
amount DECIMAL(8 , 2 ),
customer_id INT,
FOREIGN KEY (customer_id) REFERENCES customers (id) ON DELETE CASCADE
);'FOREIGN KEY (customer_id) REFERENCES customers (id) ON DELETE CASCADE'에 집중하도록 하자. ON 조건으로 삭제 시에 CASCADE 시키겠다는 것이다. FK와 연결된 PK를 가진 row가 삭제되면 이 FK를 가진 row도 삭제하겠다는 것이다.
이를 적용하기 위해서 처음부터 table을 만들도록 하자.
DROP TABLE orders;
DROP TABLE customers;
CREATE TABLE customers (
id INT PRIMARY KEY AUTO_INCREMENT,
first_name VARCHAR(50),
last_name VARCHAR(50),
email VARCHAR(50)
);
CREATE TABLE orders (
id INT PRIMARY KEY AUTO_INCREMENT,
order_date DATE,
amount DECIMAL(8 , 2 ),
customer_id INT,
FOREIGN KEY (customer_id) REFERENCES customers (id) ON DELETE CASCADE
);
INSERT INTO customers (first_name, last_name, email)
VALUES ('Boy', 'George', 'george@gmail.com'),
('George', 'Michael', 'gm@gmail.com'),
('David', 'Bowie', 'david@gmail.com'),
('Blue', 'Steele', 'blue@gmail.com'),
('Bette', 'Davis', 'bette@aol.com');
INSERT INTO orders (order_date, amount, customer_id)
VALUES ('2016-02-10', 99.99, 1),
('2017-11-11', 35.50, 1),
('2014-12-12', 800.67, 2),
('2015-01-03', 12.50, 2),
('1999-04-11', 450.25, 5);
SELECT * FROM orders;
+----+------------+--------+-------------+
| id | order_date | amount | customer_id |
+----+------------+--------+-------------+
| 1 | 2016-02-10 | 99.99 | 1 |
| 2 | 2017-11-11 | 35.50 | 1 |
| 3 | 2014-12-12 | 800.67 | 2 |
| 4 | 2015-01-03 | 12.50 | 2 |
| 5 | 1999-04-11 | 450.25 | 5 |
+----+------------+--------+-------------+이제 George를 삭제해보도록 하자.
DELETE FROM customers WHERE last_name='George';실행해보면 성공하는 것을 볼 수 있다. orders table의 결과를 확인해보자.
SELECT * FROM orders;
+----+------------+--------+-------------+
| id | order_date | amount | customer_id |
+----+------------+--------+-------------+
| 3 | 2014-12-12 | 800.67 | 2 |
| 4 | 2015-01-03 | 12.50 | 2 |
| 5 | 1999-04-11 | 450.25 | 5 |
+----+------------+--------+-------------+George를 FK로 가지고 있던 Order row들이 삭제된 것을 볼 수 있다.
중요한 것은 항상 ON DELETE CASECADE를 하는 것은 아니고 각자의 비지니스 로직에 맞게 설정하면 된다. FK와 연결된 PK를 가진 row를 삭제하면 FK를 가진 row들에 대해서 NULL값으로 채워주는 제약조건도 있고, 수동으로 Deleted 문자로 바꿔주는 방식도 있다. 이러한 동작은 app의 비즈니스 로직을 어떻게 설정하고 생각하냐에 따라 다르다.
