CQRS
CRQS는 Command and Query Responsibility Segtregation을 의미한다. 일반적으로 database에 저장된 data가 포함된 시스템에서 명령 및 쿼리 책음 구분을 의미하는 것이다.
즉, 동일한 data에 대한 두 가지 명령에 대해서 구분하는 것이다.
1. Command: command는 하나의 action으로 우리의 data에 대해서 결과적으로 변화를 일으키는 작업을 수행하는 것을 말한다. 이러한 작업은 새로운 레코드를 삽입하거나, 수정, 삭제하는 경우를 말한다.
2. Query: query는 data를 읽기만하고 변화를 일으키지 않는 read, sort와 같은 기능을 말한다. 또한, read만을 위한 view, table를 만들어 관리할 수 있다.
CQRS는 microservice 상에서 command 및 query에 대한 책임(responsibility)를 분리하는 기법을 사용하여, 시스템의 명령 부분을 위한 코드와 저장소를 분리하거나, 분할하는 것이다.
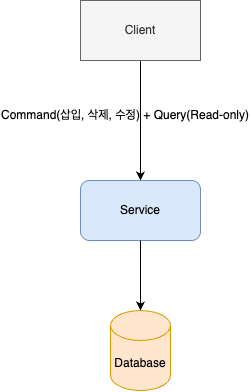
우리의 시스템이 다음과 같다고 하자, service는 하나의 application으로 transaction을 실행하는 주체라고 생각하면 된다. 이 service는 database의 data에 대해서 command와 query를 실행하는 주체인 것이다.
이를 microservice의 CQRS pattern을 사용하여 분리하면 다음과 같이 된다.
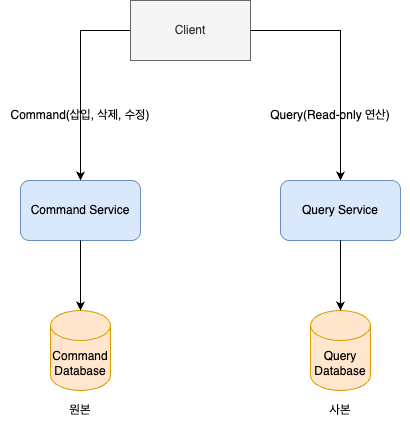
다음과 같이 CQRS 기법을 사용하여, 시스템의 command 부분과 query부분을 분리하거나, 분할하는 것이다.
모든 data 수정, 삭제, 삽입에 대한 command들은 command service를 통해서 command database를 수정하고, data를 읽는 query의 경우는 query service를 통해서 query database에서 수행된다. 이때, query database는 command database와의 동기화가 계속 맞아야한다.
따라서, query database는 command database의 사본으로서 계속해서 data 동기화를 위한 작업이 수행되어야 한다는 것이다.
event driven architecture를 통해서 이러한 동기화 문제를 해결해줄 수 있다.
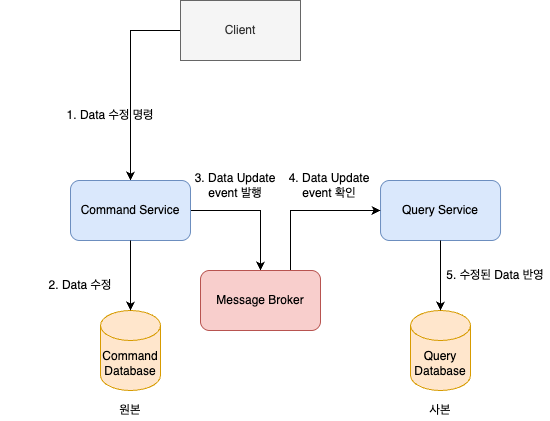
먼저 data를 수정하는 command가 만들어지고 command service가 이를 처리한다. command database에 data 수정이 반영되고, command service는 data 수정이 발생했다는 event를 message broker에 전달한다. query service는 해당 event를 확인하여, 어떤 data가 수정되었는 지 확인하고 query database에 해당 수정 data를 반영한다.
CQRS의 장점
-
SRP: command service와 query service를 분리시켰기 때문엗 단일 책임 원칙(SRP)이 매우 잘 지켜지게 된다. 이러한 책임의 분리는 곧, 비지니스 로직의 분리로 command service의 비지니스 로직 변경이 query service에게 영향이 가지 않는다. 즉, command service의 변경으로 query service도 CI/CD를 따르고 재배포될 필요가 없다는 것이다.
-
높은 성능: 이러한 분리를 통해서 우리는 성능을 더 향상시킬 수 있는데, command service의 경우 write에 더 특화된 database나 schema를 쓸 수 있고, query service의 경우는 read에 더 최적화된 database와 schema를 쓸 수 있게 된다.
-
높은 확장성: database의 경우 traffic의 양에 따라 write보다 read가 훨씬 더 많다면, read database들의 instance 수를 더 높일 수 있다.
-
관심사의 분리(separation of concerns): write와 read에 대한 관심사가 서로 분리되었으므로, 이를 통해서 microservice에서 사용하기 어려운 기법들을 사용할 수 있다. 가령, A microservice와 B microservice 각각의 database에서 join을 한다고 생각해보자.
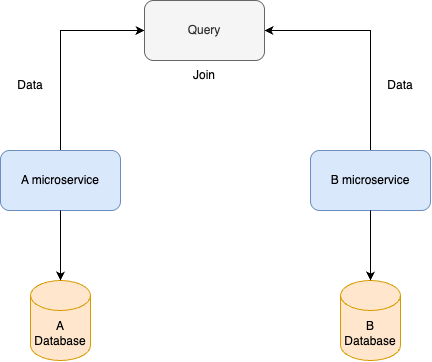
다음과 같이 각 서비스에 대해서, REST API와 같은 API를 호출한 다음, data를 받아와 join하는 수 밖에 없다. 이와 같은 연산은 오류가 발생하기 쉽고, 매우 느리다는 단점이 있다.
CQRS pattern으로 디자인하면 read하는 query service부분이 따로 나오게되므로 훨씬 더 join에 있어서 효율적이다.
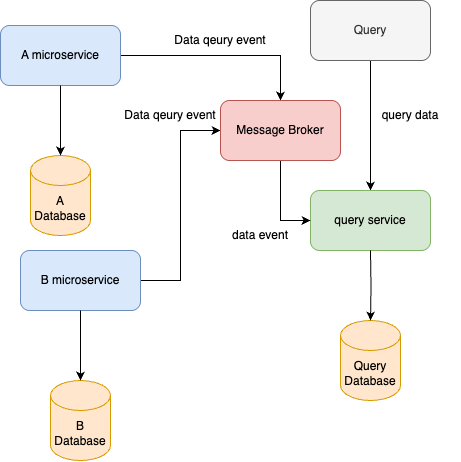
다음과 같이, A microservice, B microservice에서의 query command로 인한 data변롸를 message broker를 통해 얻어와서 query database를 업데이트하도록 한다. client의 경우 join 연산과 같이 read에 특화된 작업을 분산된 database가 아니라 query service를 통해서 손 쉽게 얻을 수 있으므로 관심사의 분리 덕에 효율적인 query문을 만들 수 있게 되는 것이다.
여기서 중요한 것은 CQRS는 최종적인 data에 대한 동기화만을 보장한다는 것이다. 이는 command service와 query service 간 아주 잠시의 데이터 불일치 성이 있을 수 있다는 것이다. 그러나, 최종적으로 event를 발생시켜 data에 대한 동기화를 맞추어, 마지막은 같은 상태를 만든다는 것이다.
실제 예시
우리는 음식점 시스템을 만든다고 하자, 음식점에 대한 정보인 메뉴, 가격, 연락처, 공지사항을 알려주도록 한다. 또한, 음식점에 대한 리뷰 서비스도 제공해야한다.
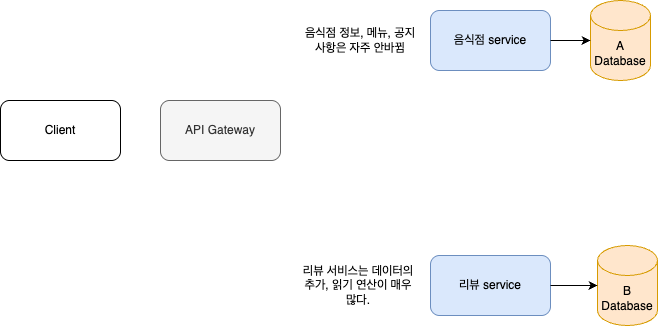
재미난 점은 '음식점 정보'에 대한 data는 자주 바뀌지 않는다는 점이다. 반면에 '리뷰' data는 자주 추가되며 읽기 연산과 검색에 많이 사용된다.
따라서, read와 write에 대한 분리가 필요한 것이다.
여기서 더 나아가서 '음식점' 페이지에 들어갔을 때, '음식점'에 대한 정보와 '리뷰'들을 함께 보여주고 싶을 것이다. 그런데, '음식점'은 상대적으로 부하가 적으므로 데이터를 쉽게 받아올 수 있는 반면에 '리뷰'는 부하도 많고 리뷰 데이터도 받아서, 상대적으로 느리게 전달된다. 또한, 이 두 데이터를 join하여 처리하는 것도 에러가 많이 발생할 수 밖에 없다.
이러한 문제를 해결하기 위해서 CQRS를 도입해보자. 먼저, 이들의 data에 대해서 READ를 담당하는 새로운 service를 만들어주는 것이 필요하다.
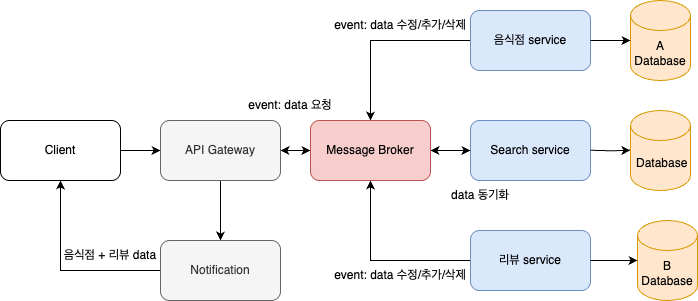
데이터를 읽기에 최적화된 상태로 만드는 Search service를 추가로 만드는 것이다. 이 service에서는 data들을 모두 모아주고, join table을 만들어주며 분석하기 좋은 form으로 변환해주도록 한다.
data 동기화를 위해서 message broker를 만들어 event를 받도록 하여 Serach service가 data를 반영하도록 한다.
이제 client에게 쉽게 '음식점 + 리뷰' data가 join된 data를 정제하여 전달해줄 수 있는 것이다.
