Transaction
microservice를 사용할 때 대부분의 pattern 중 하나는 microservice마다 각자의 database를 사용한다는 것이다. 이렇게 둠으로서 각 service들은 하나의 팀 단위로 application을 개발할 수 있으며, 서로 간의 service에 간섭을 주지 않아도 된다. 또한, 이들 간의 분리를 통해 개별적이고 독립적인 개발이 가능한 것이다.
----------------- ---------
|Payment service| ------ | MySQL |
----------------- ---------
-------------- ---------
|user service| ------ | NoSQL |
-------------- ---------
--------------- ---------
|order service| ------ | MySQL |
--------------- ---------모두 각자의 database를 가지고 있고, 이 database를 공유하지 않는 것을 알 수 있다.
그러나, 이는 문제점을 가지고 있는데 microservice 이전의 monolithic application의 경우는 단일 database를 두고 개발하는 일이 많았다.
-----Monolithic application---- ---------
| Payment, user, order service| ------ | MySQL |
------------------------------- ---------모든 데이터가 하나의 데이터베이스에 있을 때는, 하나의 transaction에 대해서 원자적으로 실행되는 것이 가능했다. 하나의 transaction에 여러 연산들이 이루어져 있지만, 외부 사용자가 보기에는 마치 단일한 연산으로 보이게 되는 것이다.
즉, 결제 transaction 하나로 결제 서비스를 이용하여 잔금을 계산하고, user의 결제 기록을 만들고, 주문 데이터를 만드는 것이 하나의 transaction으로 이루어져 다수의 연산이 마치 단일한 연산 과정으로 보이게 되는 것이다.
transaction은 ACID라는 특징을 지니는데, 다음과 같다.
1. A(atomicity): transaction은 일련의 data 수정 명령어들로 이루어져 있는데, transaction에 있는 명령어들이 모두 수행되거나, 모두 수행되지 않거나 둘 중 하나만 해야한다는 것이다. 즉, 일부만 실행되서는 안된다는 것이다. 이는 transaction을 원자처럼 더 이상 쪼갤 수 없는 하나의 단위로 보는 것으로 transaction의 내용이 모두 반영이 되거나, 반영이 안되거나 둘 중 하나만 해야한다는 것이다.
2. C(Consistency): transaction이 실행되기 전과 후의 데이터의 상태가 항상 일관되어야 한다. 이는 모든 제약 조건(foreign key, unique 제약 조건 등)이 transaction 이후에도 달라지지 않고 일정해야한다는 것이다.
3. I(Isolation): 여러 transaction이 동시에 실행되어도 서로 간섭하지 않아야 한다는 것이다. 격리 수준은 동시에 실행되는 transaction 간의 간섭을 제어하는 수준이다. READ UNCOMMITTED, READ COMMITTED, REPEATABLE READ, SERIALIZABLE 등으로 나뉜다. 높은 격리 수준 일수록 성능은 감소하지만 데이터 정합성은 더 잘 보장된다.
4. D(Durability): transaction이 설공했다면, 그 결과는 어떤 일이 있어도 지속되어야 한다는 것이다. 이는 시스템 내부적으로 로그나 체크포인트를 통해 보장할 수 있다.
transaction의 격리 수준을 말하기 전에, transaction 간에 격리가 이루어지지 않으면 어떤 문제가 생기는 지 알아보도록 하자.
- Dirty Read: 이는 아직 commit되지 않은 data를 다른 transaction이 읽는 상황을 말한다.
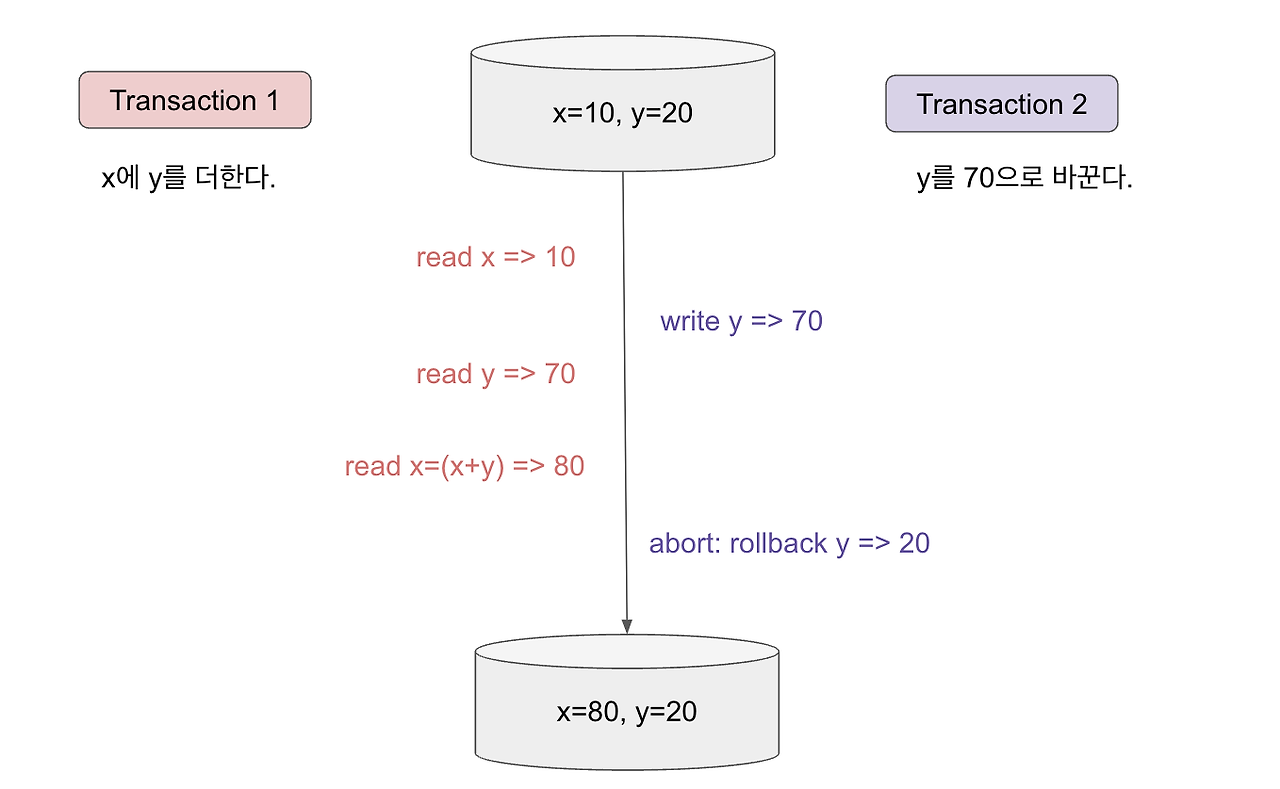
transaction 1은 x=10, y=20을 읽어서 30이 만든어져야하는데, transaction 2의 실행 도중에 y가 바뀌어서 y=70이 된다. 이에 따라 transaction 1의 결과가 80이되어 x=80이 된다. 문제는 transaction 2는 완전히 실행되지 않고 종료되어 transaction의 원자적 특성에 의해 결과를 rollback한다. 이때 y는 다시 20으로 돌아가지면 transaction 1의 결과는 여전히 y를 70으로 읽은 결과로 저장된다.
- Non-repeatable Read: 서로 간에 data 수정이 마음대로 이루어지고 읽을 수 있기 때문에, 같은 transaction 내의 동일한 data도 읽을 때마다 결과가 달라 질 수 있다. 즉, 같은 transaction 내에 동일한 data를 두 번 읽을 때, 값이 달라진다는 것이다. 이는 반복된 READ가 정상적이지 않다는 것이다.
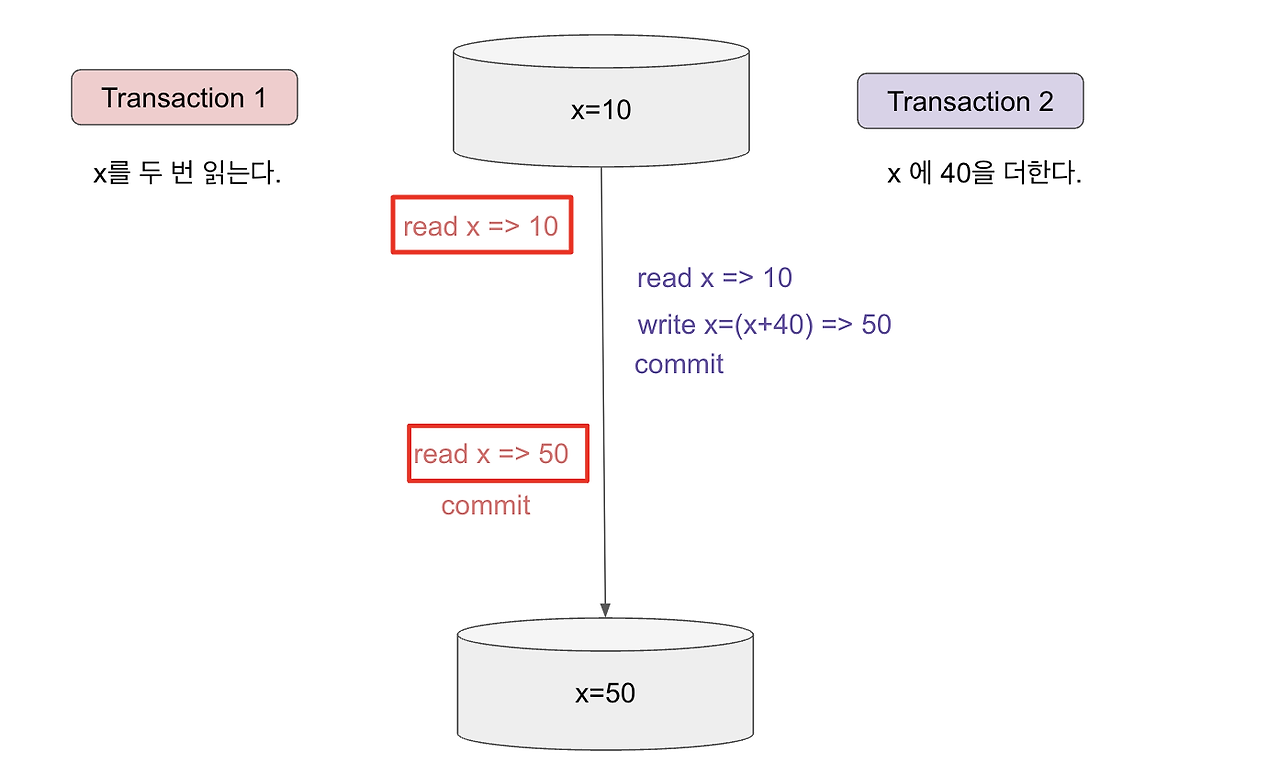
transaction 1이 x를 맨 처음 읽었을 때는 x값이 10이었는데, transaction 2가 완료되면서 x는 50이 된다. 이후 transaction 1이 다시 x를 읽으면 x값이 50이 된다. 이는 동일한 transaction 1에서 두 번의 동일한 READ연산이 발생했는 데 결과가 다르게 나오는 것이다.
- Phantom Read: transaction 중간에 다른 transaction이 데이터를 추가/삭제하면 transaction 내에 같은 query라도 그 결과가 시시 때때로 결과가 달라질 수 있다. Non-repeatable Read는 동일한 값을 읽었을 때, 그 결과가 매번 달라지는 것을 의미하고 Phantom Read는 query 결과 집합에 새로운 row가 추가되거나 삭제되는 것이 마치 유령이 나온 것 같다고 해서 phantom read이다.
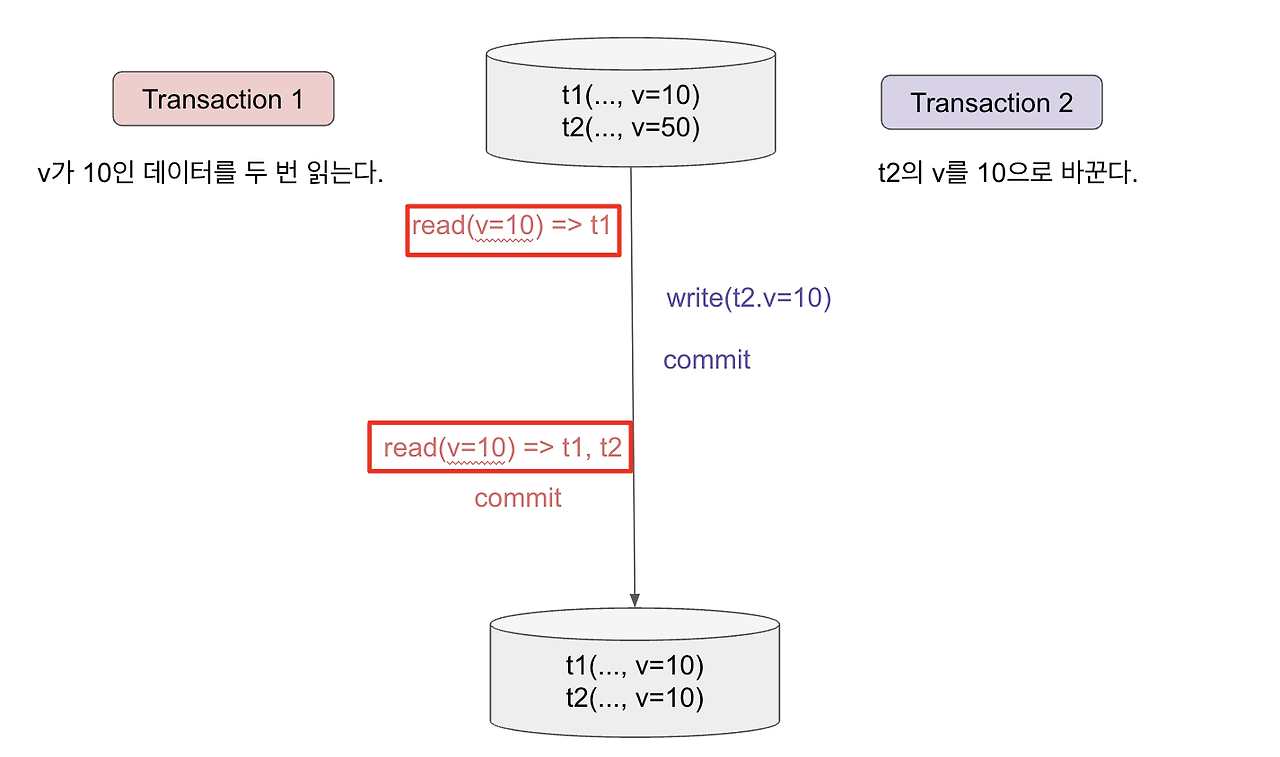
transaction 1에서 v가 10인 row를 query해보니 결과가 t1 하나였다. 이 와중에 transaction 2가 t2라는 row를 새로 추가했는데, 이 t2는 v가 10인 row인 것이었다. 따라서 transaction 1이 다시 v가 10인 row를 query해보니 t1, t2가 나오게 되는 것이다. 이처럼 없는 데이터가 불쑥 생겨나 유령을 본 것 같은 것이 바로 phantom read이다.
격리 수준에 대해서 좀 더 자세히 알아보자면 다음과 같다.
- READ UNCOMMITTED(commit되지 않은 data에 대해서 READ 하용): 가장 낮은 격리 수준으로 다른 transaction이 아직 commit되지 않은 데이터를 읽을 수 있다. 즉, 다른 transaction이 진행 중에 수정 중인 data를 읽을 수 있다는 것이다. 이는 위에서 언급한 Dirty Read, Non-repeatable Read, Phantom Read 모두 발생한다.
- READ COMMITTED(commit된 data에 대해서만 READ 허용): transaction이 commit된 내용만 읽을 수 있게 되는 것이다. 이는 commit되지 않은 data를 읽는 문제인 Dirty Read문제는 사라졌지만, Non-repeatable Read와 Phantom Read는 여전히 발생한다. 왜냐하면 내 transaction이 동작 중인데, 다른 transaction이 완료되어 데이터를 변경하면, 내 transaction에 영향을 미치기 때문이다. 그럼에도 READ COMMITTED 상태는 성능과 정합성에 있어서 어느정도 상응관계가 잘 맞춰져서 대부분의 상용 데이터베이스에서 많이 사용한다.
- REPEATABLE READ(읽기 연산에 대해 동일한 data를 보장한다): transaction이 실행되면 해당 transaction 내에서 동일한 data를 반복적으로 읽어도 동일한 값이 보장된다. 이는 Dirty Read와 Non-repeatable Read문제는 해결했지만, Phantom Read는 여전히 발생한다. 왜냐하면 동일한 data read는 보장했지만, table에 대한 data 추가, 삭제는 여전하므로, query의 결과 집합은 달라질 수 있기 때문이다. mysql이 REPEATABLE READ이다.
- SERIALIZABLE(직렬과 가능): 가장 높은 수준의 격리로 transaction을 순차적으로 실행하는 것과 동일한 결과를 보장한다. 이는 모든 문제를 해결하지만 성능 저하가 너무 심하게 발생하며, transaction 간의 lock system으로 인한 deadlock이 발생할 가능성도 있다.
Microservice Transaction: Saga Pattern
문제는 microservice로 이관하면 해당 transaction을 수행하는 단일 database가 더 이상 없다는 것이다.
----------------- ---------
|Payment service| ------ | MySQL |
----------------- ---------
-------------- ---------
|user service| ------ | NoSQL |
-------------- ---------
--------------- ---------
|order service| ------ | MySQL |
--------------- ---------각 Workflow가 개별적으로만 이루어지기 때문에 전체적으로 단일한 transaction을 구성하기 어렵다는 것이다.
이러한 문제를 해결해주는 것이 바로 Saga pattern이다.
이 pattern은 해당 transaction의 일부인 개별 작업을 각 database에서 local transaction의 연속으로 수행한다.
Transaction Across Microservices
/ \
/ \
operation1 --> Microservice1 --> operation2 --> Microservice2
| |
| |
database1 database2
(Local transaction1) (Local transaction2)각 연산의 성공적인 작업은 sequence에서 그 다음 작업을 트리거하며, 만약 특정 작업이 실패한다면 saga pattern은 이전 작업을 롤백시키기 위해서 반대 효과를 가지는 보상 transaction 작업을 적용한다.
transaction aborted
/ \
/ \
Microservice1 <-- 보상 작업 <-- Microservice2 <-- 실패
| |
| |
database1 database2
(Undo transaction1) (Undo transaction2)일부 microservice의 transaction 실패가 이전 일련의 성공 transaction들을 undo시키는 보상 작업이 이루어지는 것이다.
이러한 saga pattern을 구현하는 두 가지 방식이 있다.
Workflow Orchestration
전체 transaction을 조정하는 state기반 workflow 관리 서비스를 사용하는 것이다.
Subscription service
/
/
client <------> API Gateway --------- Payment service
(Workflow Orchestation service)
\
\
user service중앙화된 Workflow Orchestration Service를 만들어 transaction에 대한 전체적인 제어, 관리를 해주는 것이다. 즉, 시스템 전체에 대한 workflow를 실행하고 rollback하도록 하는 것이다.
Workflow Orchestration Service는 API Gateway와 결합해 존재할 수도 있고, API Gateway와 별로도 독립적으로 존재할 수도 있다. 단지, 주요 목적은 transaction을 올바른 순서대로 조율하고 만약 문제가 발생하는 경우 보상 동작을 반대의 순서로 적용하는 것이다.
동작 예시를 들어보도록 하자, 우리는 여행사 시스템으로 패키지 여행자 상품을 만든다고 하자. 여행 상품을 결제하면 비행기, 호텔, 렌터카 모두 예약해주며 주문 완료 결과와 기록을 사용자에게 보여주어야 한다.
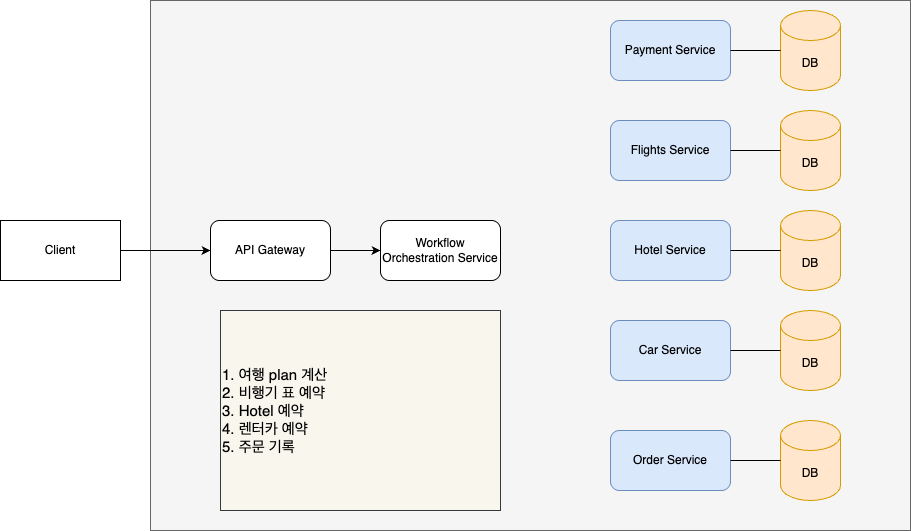
다음과 같이 5개의 transaction들이 있는 것을 볼 수 있다. workflow에서는 이러한 각 transaction을 activity로 표현하는데, 여기서는 편의상 transaction으로 말하도록 하자.
해당 workflow의 각 transaction은 순차적으로 실행되어야하고 하나라도 실패할 시에 이전 transaction에 대해서 보상 transaction을 만들어, microservice 전체에 대한 ACID를 지켜야 한다.
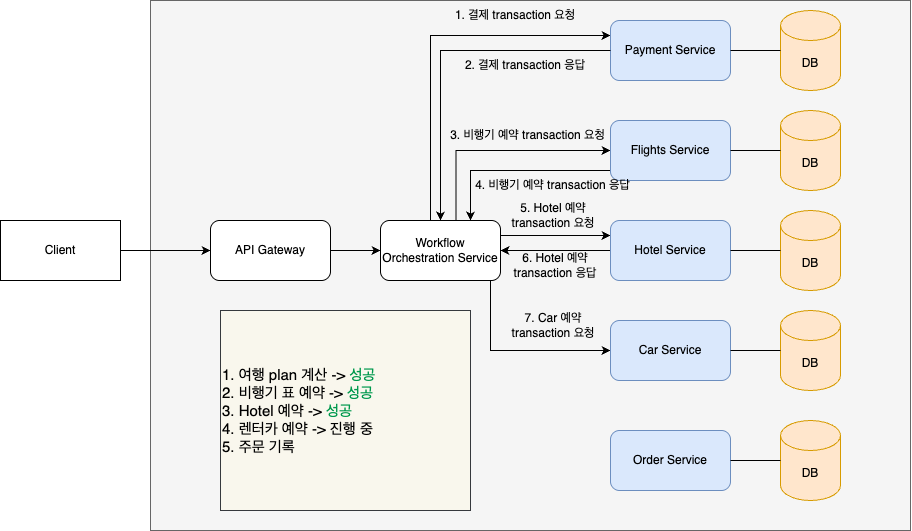
각 local transaction이 일련의 순서대로 실행되고 그 결과를 workflow orchestration service에게 전달하는 것을 볼 수 있다.
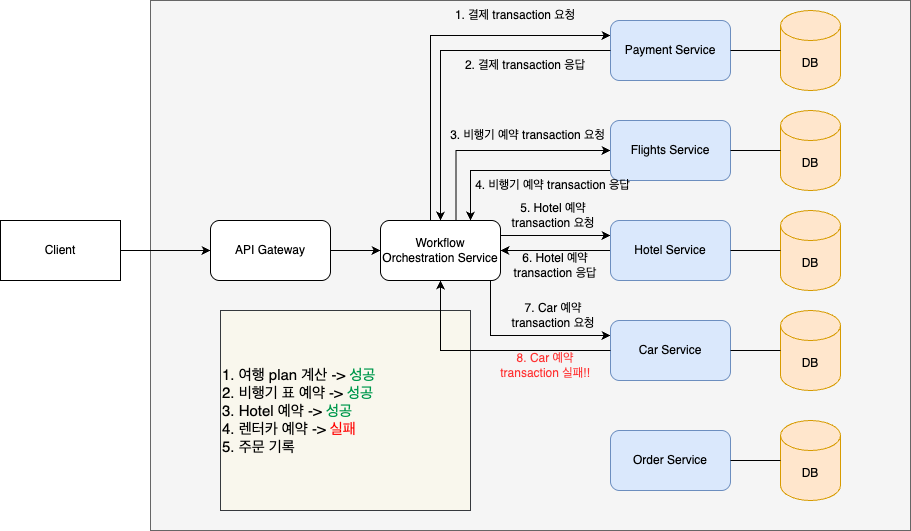
그런데 만약, 해당 일자의 렌터카가 다른 사용자에 의해서 예약이 되어버려서 남은 매물이 없다면 어떻게될까?? 해당 local transaction을 취소하는 수 밖에 없다.
이는 곧 해당 workflow에 대한 rollback을 의미하고, 보상 transaction을 통해서 이전에 실행했던 transaction들을 되돌려야한다.
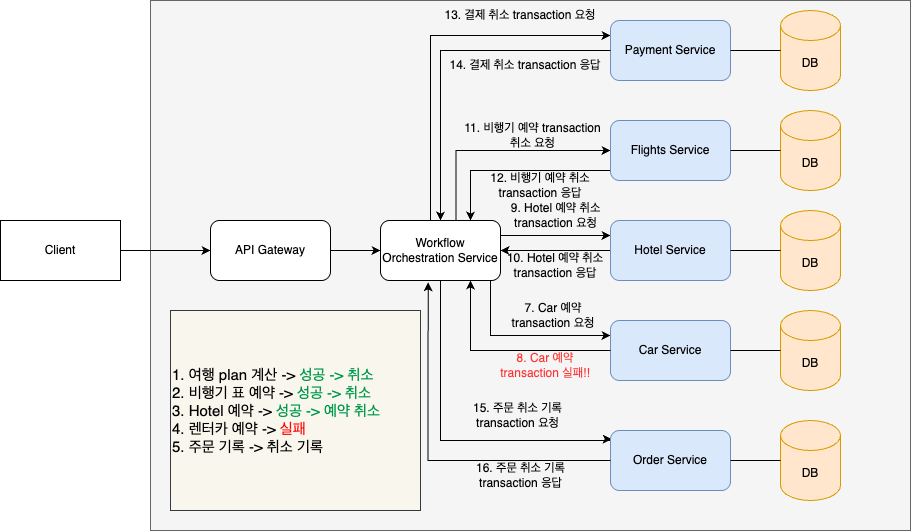
다음과 같이 보상 transaction을 만들어, workflow 내의 transaction 순서에 따라 실행하여 결과를 되돌려 놓아야 한다.
추가적으로 order service에 주문 취소 기록을 남기도록 하여, 해당 transaction이 왜 취소되었는 지 기록하도록 한다.
이렇게, 중앙화된 Workflow Orchestration Service를 이용하여 분산 환경의 microservice transaction을 serial하게 동작시킬 수 있고, 실패에 대한 rollback을 시스템 전체에 반영하여 원래의 상태를 유지시킬 수 있다.
Event Driven Architecture
이 방법은 중앙화된 workflow orchestration service 없이 workflow 제어를 각 microservice들에게 위임하여 이들 간의 통신으로 일련의 transaction이 정상적으로 동작하도록 만드는 것이다.
이러한 동작을 위해서 event를 발급하여 각 microservice의 local transaction이 성공했는 지, 실패했는 지를 알려주어 개별적인 microservice 간의 통신이 이루어져야 한다는 것이다.
client --> API Gateway ---> Microservice1 <----------> DB
| ^
| |
v |
Success event Failure event
| ^
V |
Microservice2 <----------> DB
| ^
v |
Success event Failure event
| ^
v |
Microservice3 <----------> DB다음과 같이 각 Microservice들끼리의 event 교환이 있고, 일련의 event들이 전달되어 각 순서에 맞게 microservice들이 event를 받고 local transaction을 실행하는 것이다. 만약 특정 microservice가 local transaction 실행에 실패한다면 실패 event를 발급하여 일련의 보상 transaction 과정을 모두 거치게 된다.
이는 각 microservice가 서로 간에 event 기반 통신을 해야하고 어떤 event가 성공 event이고, 어떤 event가 실패 event이며 무슨 event를 보내야하는 지도 알고 있어야 한다는 것이다.
이러한 동작을 위한 event message broker가 필요한 것이다.
event driven arhcitecture sage pattern도 예시를 들어 어떻게 동작하는 지 확인해보도록 하자.
위에서 한 번 확인한 '패키지 여행 상품 서비스'를 만든다고 하자. event 기반의 구조로 만들기 위해서는 event를 수신하고 송신해주는 message broker가 필요하다. 이 message broker에 event를 발급하고 확인하는 방식으로 각 mircoservice들이 통신하게 된다. 다음은 성공한 case를 정리한 그림이다.
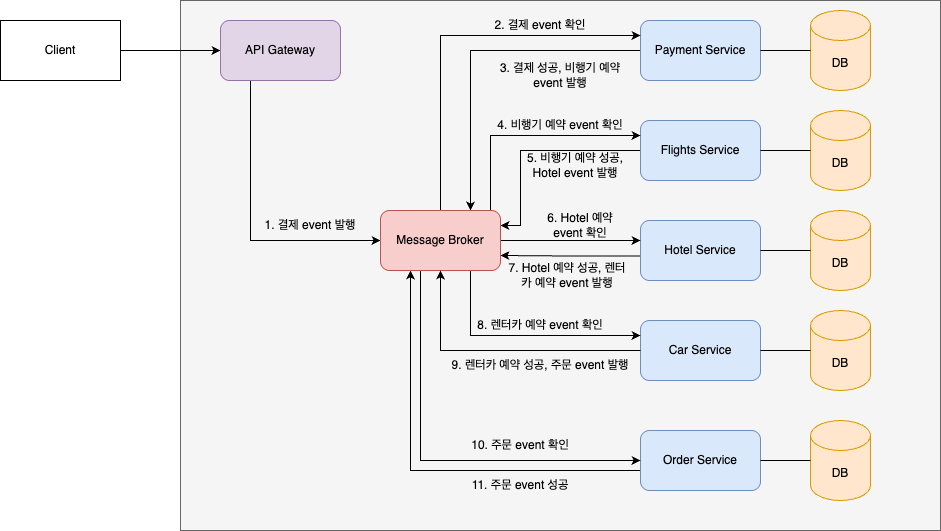
결제 event가 발행되고 payment service에서 local transaction을 실행시킨다. 이를 통해서 결제가 완료되고 결제가 성공했으므로 다음 event인 비행기 예약 event를 보낸다. 이렇게 쭉 가서 마지막을 보면 '주문 event'를 발행하여 order service가 local transaction을 실행시킨다. 주문 정보가 잘 입력되었다면 message broker에 주문 event가 성공했다는 event를 만들어보내주도록 한다.
여기서 주의할 것은 message broker를 통한 event 기반 구조는 비동기적으로 동작하기 때문에 마지막에 order service가 전달한 '주문 완료' event를 받고 응답을 전달해줄 service가 필요하다. 따라서, 이를 위해 notification service를 두도록 하자.
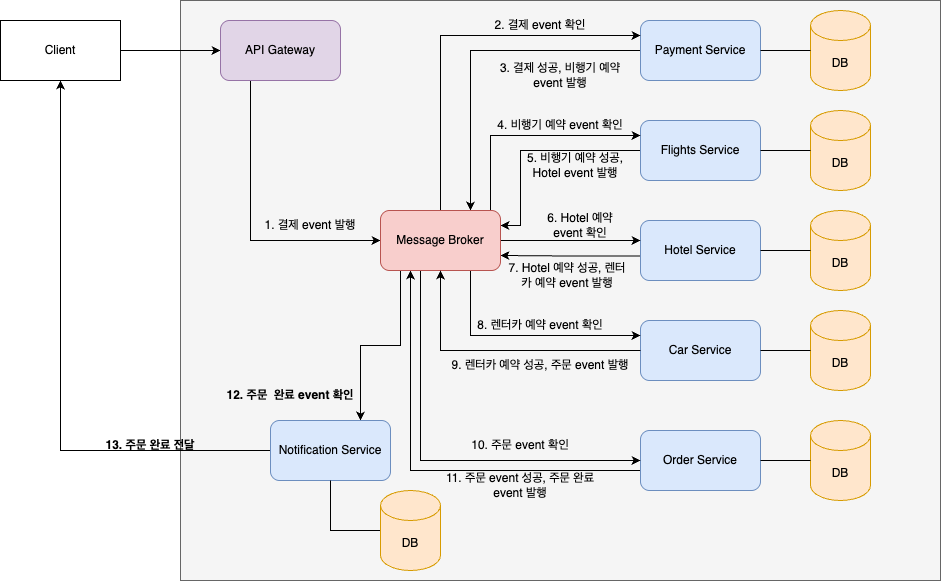
notification service가 '주문 완료 event'를 확인하여 system 전체적인 transaction이 무사히 완료되었음을 client에게 전달한다.
만약, 중간에 실패한다면 어떻게해야하는가?? 중간에 실패한 경우에는 성공한 local transaction에 대해서 보상 transaction을 실행시키는 failure event를 발급해야한다. 이 또한, 성공 case의 반대 순서대로 실행하도록 해야하며, event를 통해 동작해야한다.
가령, hotel을 예약하려고 했는데, 하필이면 딱 사용자가 예약하려는 local transaction을 실행할 때, 다른 사람이 모든 호텔 호실을 주문했다고 하자. 이 경우 호텔 예약 local transaction이 실패하면서 앞에 있었던 '비행기', '결제' local transaction을 취소하는 '보상 트랜잭션'을 실행시켜줘야 한다.
1~5번까지의 동작은 위의 그림처럼 성공했다고 하자, 아래는 6부터 실패하여 보상 transaction이 어떻게 동작하는 지를 보여준다.
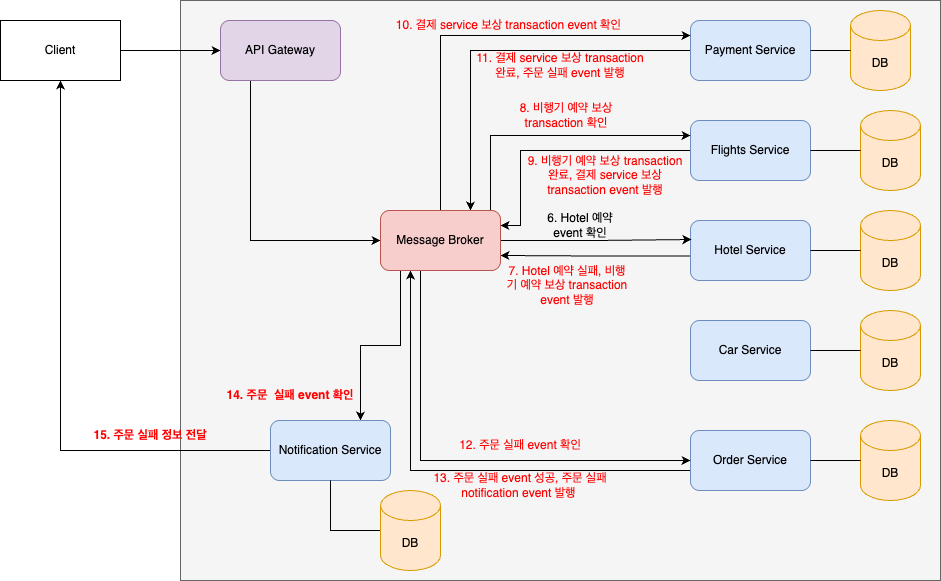
hotel 예약 local transaction이 실패하고, message broker에 '비행기 보상 transaction event'를 발행시킨다. 이를 통해서 'flight service'는 이전에 예매했던 비행기 좌석을 취소할 수 있도록 한다. 다음으로 'flight service'는 'payment service'에게 결제에 대한 보상 transaction event를 발급한다. 이를 통해서 'payment service'는 환불이 실행되는 것이다. 'payment service'는 환불 이후에 주문이 실패했다는 것을 알리기 위해서 'order service'로 '주문 실패 event'를 발급한다. 'order service'는 '주문 실패' event를 받고, 주문 실패에 대한 정보를 기록하는 local transaction을 실행한다. 이후에 client에게 주문이 실패했다는 noti를 주기 위해서 'notification event'를 발행한다.
이렇게 event driven architecture를 이용하여 Saga pattern을 구현하여, 일련의 transaction을 전체 microservice들 간의 event 교환을 통해 실행할 수 있으며, rollback시의 보상 transaction을 발급하도록 할 수 있다. 이는 전체 시스템에 대한 transaction ACID를 보장해주며, 유저에게 동일한 사용자 경험을 보장해줄 수 있다.
