1. Introduction
기존 연구 한계점 : 언어 모델들이 unidirectional하며 이는 pre-training 과정에서 제한적이었다.
Transformer의 경우 이전 token에만 영향을 받으며, 이러한 제한은 sentence level task에선 sub-optimal 이며 QA와 같은 token level task에선 매우 치명적일 수 있음
MLM(Masked Language Model)을 이용해 fine-tuning 개선
MLM은 randomly masked된 mask의 original word를 찾으며 학습하고, 양방향 context를 모두 표현
next sentence prediction task까지 함께 사용
※ feature based : task-specific network에 pre-trained model을 추가적인 feature로 사용
※ transfer learning : pre-trained model의 classifier를 downstream task의 classifier로 교체 후 fine-tuning
2. Related Work
Unsupervised Feature-based Approaches
단어 임베딩은 문장, 문단 임베딩까지 이어졌다. ELMo 및 후속 접근법은 left-to-right와 right-to-left 언어 모델을 통해 context-sensitive feature을 추출한다. 각 토큰의 문맥적 표현은 왼-오, 오-왼 표현의 concatenation이다. ELMo는 SOTA를 달성했으나 feature-based이며 깊은 양방향성이 아니다.
Unsupervised Fine-tuning Approaches
문장 및 문서 인코더들은 unlabeled text로 pre-train되며 supervised downstream task로 fine-tuned.
이러한 접근은 처음부터 학습해야 하는 parameter가 거의 없다.
Transfer Learning from Supervised Data
NLI, 기계 번역, CV에서 모두 large pre-trained model에서 전이 학습의 중요성을 입증하고 있다.
3. 제안 방법론
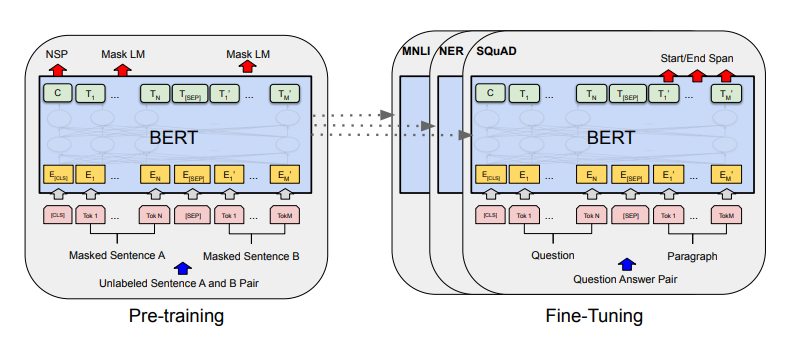
BERT two steps
unlabeled data로 pre-training하는 단계와 downstream task의 labeled data로 fine-tuning 단계
Question-answering 동작 예시
-
output layer를 제외하고 pre-training과 fine-tuning이 같은 아키텍쳐를 사용하고 있다.
-
pre-trained model parameters가 downstream tasks model의 초기화에 사용
-
fine-tuning을 통해 모든 파라미터가 미세 조정됨
-
[CLS] token은 모든 입력 맨 앞에 추가되며, [SEP] token은 분리자 토큰
모델 구조 & Input/Output
multi-layer bidirectional Transformer encoder based 모델
BERT_base는 12 layers, 768 hidden size, 12 attention heads (총 110M parameters),
BERT_Large는 24 layers, 1024 hidden size, 16 attention heads (총 340M parameters)로 구성
input은 단일 또는 여러 문장을 하나의 token sequence로 표현
※ 논문에서 sentence는 언어적 실제 문장을 나타내는 것이 아닌 인접한 text의 임의 span이며, sequence는 input(하나 또는 두 문장)의 token sequence을 나타냄
마지막 hidden state의 [CLS] token은 분류 task의 sequence representation을 집계
문장들은 [SEP] token과 모든 token의 learned embedding이 추가된 형태로 구분
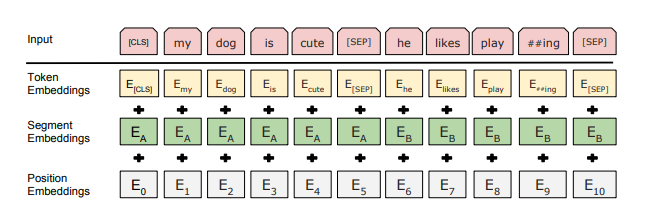
- input embeddings는 token, segment(문장 위치), position(token 위치) embedding의 sum
Pre-training (figure1의 왼쪽)
BooksCorpus에서 800M, English Wikipedia에서 2,500M words 사전 학습
1. Masked LM
input token에서 일부를 random하게 mask하고, masked token을 예측 (논문에선 15%)
일반적인 LM처럼 mask token의 최종 hidden vector를 vocab output softmax 함수에 feeding
[MASK] token이 fine-tuning 과정에선 나타나지 않아 pre-training과 fine-tuning의 mismatch 발생
→ 선택된 i번째 token을 80% 확률로 [MASK] token으로 변형, 10% 확률로 다른 random token으로 변형, 10% 확률로 기존 token으로 유지
i번째 token(figure1의 )은 cross entropy loss를 이용해 예측
2. Next Sentence Prediction
LM으로는 직접 포착할 수 없는 두 문장 사이의 관계를 이해
figure1의 두 문장 A, B에서 50% 확률로 B를 실제 A의 다음 문장으로, 50% 확률로 random sentence
figure1의 는 다음 문장 예측 token으로 사용
이러한 과정으로 BERT는 end-task model parameter 초기화를 위한 모든 parameter transfer 가능
Fine-tuning (figure 1의 오른쪽)
task-specific inputs
- 의역에선 sentence pairs
- entailment에선 가설-전제 쌍
- 질의응답에선 질문-문단 쌍
- 텍스트 분류 및 sequence tagging에선 degenrate text-None 쌍
output representation
- entailment 또는 감정분석에선 [CLS] representation
- sequence tagging 또는 질의응답에선 token-level의 output
4. 실험 및 결과
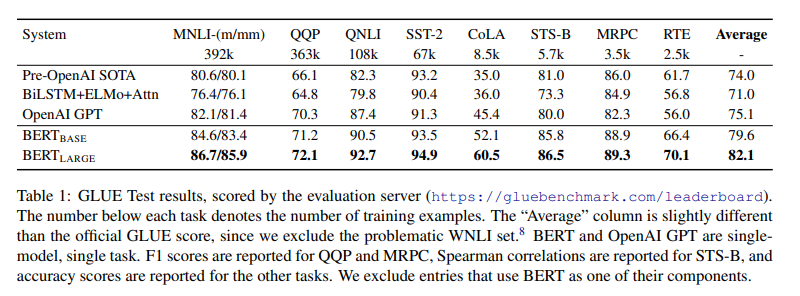
GLUE
input sequence로 단일 문장 또는 문장 쌍을 표현하고, [CLS] token의 final hidden state vector 사용
새로운 파라미터는 (K = num of labels) 이며, 사용
batch-size = 32, fine-tune epoch = 3
Dev set에서 learning rate는 5e-5, 4e-5, 3e-5, 2e-5 사이에서 best select
BERT_Large가 small dataset에서 unstable한 경우가 있어, random restart 추가
- random restart에서 동일한 pre-trained checkpoint를 사용하나 다른 data-shuffling과 classifier layer initialization 사용
BERT는 GLUE의 모든 task에서 SOTA를 달성
BERT Base와 GPT는 attention masking을 제외하고 동일한 모델 구조임에도, 성능 차이가 큼
매우 작은 학습 데이터에도 BERT Large가 BERT Base를 모두 뛰어넘음
SQuAD v1.1
batch-size = 32, fine-tune epoch = 3, learning rate = 5e-5
SQuAD는 100K의 crowd-sourced Q/A pairs
- Wikipedia의 질문과, 답을 포함하는 지문을 받으면, 정답의 위치를 찾는 task
input은 질문과 지문을 하나의 packed sequence로 표현하며 질문에는 A, 지문에는 B 임베딩 적용
fine-tuning 과정에서 start vector S와 end vector E 사용
단어 i가 answer span의 start일 확률은 와의 dot-product로 계산되고, S는 지문의 모든 단어의 softmax를 따른다.
answer span의 end도 유사한 공식이 사용되고, candidate span (j≥i)의 maximum scoring이 prediction
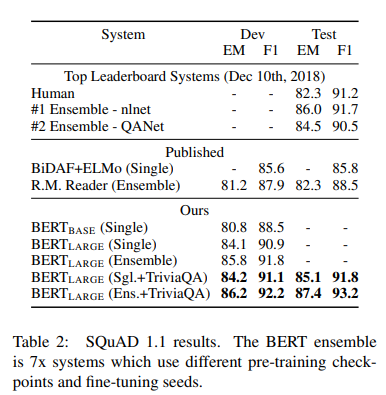
SQuAD fine-tuning 하기 전에 TriviaQA를 먼저 fine-tuning
TriviaQA fine-tuning이 없어도 여전히 큰 폭으로 다른 모든 시스템들을 능가
SQuAD v2.0
batch-size = 48, fine-tune epoch = 2, learning rate = 5e-5
SQuAD 1.1에서 정답이 없는 경우도 존재
정답이 없는 질문에 대해 start와 end를 [CLS] token에 위치
answer span position의 start와 end 확률 공간은 [CLS] token의 위치를 포함
정답이 없는 질문의 score은
정답이 있는 경우 score은 , when
는 F1을 최대화하기 위한 threshold
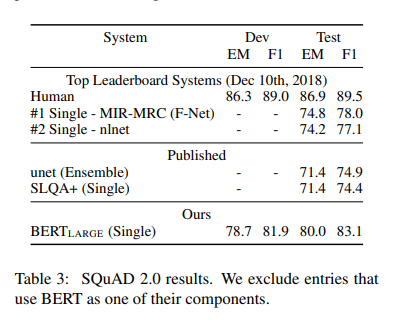
이전 최고 system보다 5.1 F1 improvement
SWAG
batch-size = 16, fine-tune epoch = 3, learning rate = 2e-5
일반적인 추론을 평가하기 위한 113k의 문장 쌍 dataset
문장이 주어지면 네 개의 선택지 중 가장 그럴듯한 답을 고르는 task
각 선택지에 질문을 모두 concatenate해 4개의 input sequences 생성
task-specific parameter은 [CLS] token과 dot product를 수행하는 vector
[CLS] token representation C는 각 choice의 softmax 결과를 나타냄
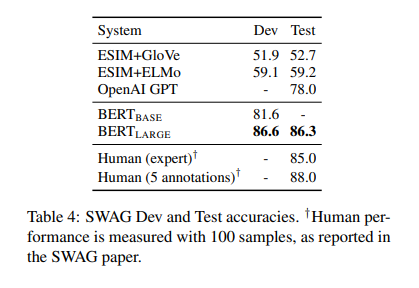
이전 모델보다 월등히 뛰어나며
사람과 비슷한 수준
Ablation Studies
1. Effect of Pre-training Tasks
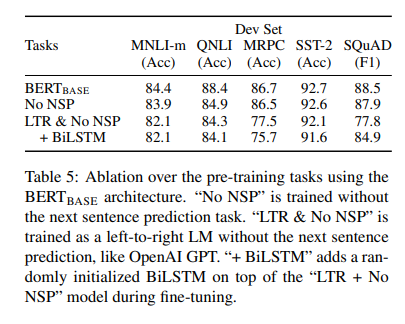
LTR constraint는 fine-tuning 과정에도 적용
- GPT와 dataset, input representation, fine-tuning 스키마를 제외하고 모두 동일한 상태
No NSP는 QNLI, MNLI, SQuAD task 성능을 상당히 저하
LTR model은 MLM model보다 모든 task에서 낮은 성능
SQuAD model에서 randonly initialized BiLSTM을 top에 추가해 상당히 개선된 결과를 얻었지만, pre-trained model보단 여전히 성능이 안 좋음 + BiLSTM은 GLUE tasks에는 안 좋은 영향
ELMo처럼 LTR과 RTL을 concatenate할 수 있지만, 이는 비용이 많이들고, QA같은 task에서 non-intuitive하며, 모든 layer에서 left, right context를 사용할 수 있어 덜 강력하다.
2. Effect of Model Size
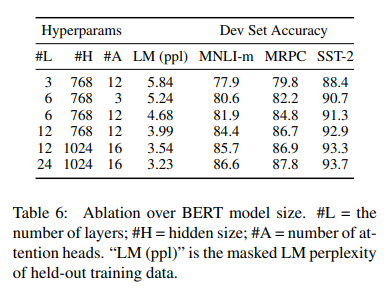
더 큰 model이 모든 dataset에 대해 더 높은 정확도를 보임
MRPC의 경우 3,600개의 labeled training example과 pre-training task와 다른 task임에도 높은 성능
충분히 pre-trained된 model에서, model size가 매우 작은 scale task에도 큰 성능 향상을 입증
3. Feature-based Approach with BERT
pre-trained model의 feature을 고정한 feature-based approach가 갖는 이점도 있음
-
모든 task가 transformer encoder 구조로 쉽게 표현되지 않음
- task specific model 구조가 추가되어야 함
-
training data를 미리 한 번만 계산하고 많은 실험을 cheaper model로 돌리는 연산 관점의 benefit이 존재
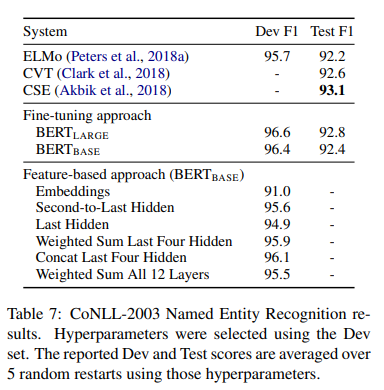
CoNLL-2003 NER task에서 BERT의 input으로 case-preserving WordPiece model을 사용하고, 데이터에서 제공하는 최대의 문서 context를 포함
BERT의 parameter를 fine-tuning하지 않고 한 개 이상의 layer를 추출해 classification layer 이전에 randomly initialized 2-layer 768-dimension의 BiLSTM의 input으로 사용
BERT_Large는 SOTA를 달성
BERT는 fine-tuning, feature-based 모두 좋은 성능을 보임
Conclusion
최근 transfer learning을 통한 LM 향상은 풍부한 비지도학습이 많은 언어 이해 시스템의 통합이라는 것을 증명
특히 low-resource task도 깊은 단방향 구조의 이점을 누릴 수 있게 함
