0. Abstract
Transformer은 recurrence와 convolution 연산 없이 attention에만 기반을 둠
기계 번역 task에서 이 모델은 parallelizable 하며 훈련 시간을 상당히 줄임
English constituency parsing에서 large data와 limited data 모두 성공적임
1. Introduction
1) 논문이 다루는 task
Transformer은 recurrence를 피하고 attention 매커니즘에 전적으로 의존해 입/출력 사이의 global 의존성을 도출한다.
- Input: sequential data
- Output: sequential data
2) 해당 task에서 기존 연구 한계점 (정상적인 논문이라면 introduction에서 간략히 언급함)
RNN 계열을 사용하면 근본적인 sequential computation constraint는 여전히 남아있음
그러나 일부 attention 매커니즘은 rnn과 함께 사용
sequential computation 연산량을 줄이려는 노력은 계속되었지만, 두 입출력 사이의 의존성을 파악하기는 어려움
2. Related Work
Self-attention
https://velog.io/@chanu48/Self-Attention-Multi-head-Attention
3. 제안 방법론
Encoder
-
두 sub-layer를 가지는 동일한 6개의 layer로 구성
-
sub layer은 multi-head-attention layer와 position-wise fully connected feed-forward network
-
각 sub-layer의 output은 LayerNorm(x+Sublayer(x))
-
잔차 연결을 용이하게 하기 위해 임베딩 층을 포함한 모든 층의 output 차원은 512이다.
Decoder
-
Encoder layer와 동일한 layer로 구성되지만 encoder stack output에 multi-head-attention을 적용하는 하나의 층을 더 갖는다.
-
i번째 예측은 i보다 작은 출력에 대해서만 의존성을 갖게 하기 위한 masking을 사용
Attention
- query와 key-value 쌍을 mapping하는 함수 (query, key, value는 모두 벡터)
- output은 value의 가중합으로 계산되며, 각 value의 weight는 query와 일치하는 key의 호환성 함수로 연산된다.
Scaled Dot-Product Attention
-
Q : queries matrix, K : keys matrix, V : values matrix
-
dot-product attention은 additive attention보다 훨씬 빠르고 공간 효율적임
-
d_k가 커질수록 dot products가 softmax function을 매우 작은 gradient로 밀어 넣는다.
- 따라서 dot products를 1/√dk 로 scaling
Multi-head Attention
-
단일 Attention보다 query, key, value를 d_k, d_k, d_v 차원으로 각각 h번 학습하는 것이 좋다.
-
query, key, value 로 투영된 각각은 병렬적으로 attention 함수를 수행하며, 결과물은 d_v 차원을 갖는다.
-
이들은 concatnate되어 한 번 더 linear layer에 투영된다.
-
각 head의 연산을 줄였기 때문에 총 연산량은 full dimension single attention 연산량과 비슷
Applications of Attention in our Model
-
encoder-decoder attention layer에서 query는 이전 decoder에서, key-value는 encoder에서 받는다.
-
decoder의 self-attention layer은 다음 출력을 고려하지 않도록 scaled dot-product를 할 때 모든 다음 input value를 음의 무한으로 만든다.
Position-wise Feed-forward Networks
-
ReLU와 두 개의 선형 변환을 포함
-
encoder, decoder의 모든 layer에서 각각 적용되는 fully-connected feed forward network
Embedding & Softmax
-
input, output token을 d_model 차원 벡터로 변환하기 위해 learned embedding 사용
-
embedding layer weight에 √d_model 곱함
-
encoder, decoder 두 embedding layers와 pre-softmax 선형 변환이 같은 weight share
Positional Encoding
-
sequence의 token의 상대적 또는 절대적 위치 정보가 필요
-
짝수에는 sin, 홀수에는 cos 함수 사용
-
임베딩 벡터와 더해 encoder, decoder input으로 사용
Why Self Attention?
- layer 당 연산량이 적고, 연산이 병렬화될 수 있으며, long-range dependency 학습이 쉽다.
4. 실험 및 결과
Dataset
WMT 2014 English-German dataset , 4.5 million sentence pairs
WMT 2014 English-French dataset, 36M sentences & 32000 word-piece vocabulary
batch size : 25000
Hardware
8 NVIDIA P100 GPUs
Schedule
base model : 100,000 steps or 12 hours
big model : 300,000 steps (3.5 days)
Optimizer
Adam
lr : 첫 번째 warmup_step에서는 증가하지만, 그 후 부분적 감소
Regularization
residual dropout (p=0.1)
label smoothing
결과
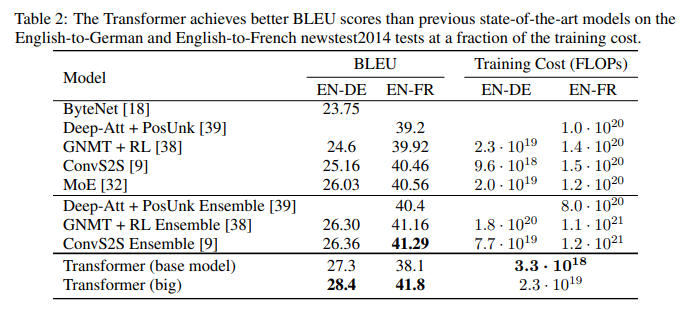
base model, big model 모두 좋은 성능을 보임
head가 많으면 quailty 저하
dk 사이즈 축소 → 성능 저하
결론
Transformer은 recurrence와 convolution을 제외한 attention에만 기반을 둔 모델이다.
Transformer을 text뿐만 아니라 image, video에도 적용 가능하다.
