유일값의 빈도수에 대해 알아보기
수치형 데이터에 이어 범주형 데이터에 대한 EDA에 대해 알아보도록 하겠다.
범주형 데이터의 경우 유일값들로 구성이 되어 있다.즉 숫자형태가 아닌 예를 들어 다이아몬드의 색의 종류가 총 세가지 빨강, 파랑, 검정이 있다면 이 색상이라는 변수안에 빨강, 파랑, 검정이라는 유일값들로 구성이 되어 있다는 것이다.
데이터프레임 속의 유일 값들의 빈도수를 확인해보는 방법으로 다음의 코드를 사용하면 될 것이다.
df.nunique()만약 하나의 변수속에 있는 값속 유일값들의 빈도수를 구하고 싶다면 다음과 같이 실행한다.
df[변수명].value_count()countplot
카운트 플롯을 사용하면 각 유일값들에 대한 빈도수를 시각화하기 용이하다. 코드는 다음과 같다.
sns.countplot(data=df, x=변수명)더 나아가서 2개 이상의 변수에 대한 빈도수를 확인하는 방법은 countplot 속에 hue=변수명 이라는 코드를 넣는 것도 한 방법이다.
groupby
groupby는 pandas에 내장된 함수로 범주형 변수들을 분석할때 매우 용이하게 사용된다. 이름에서도 알 수 있듯이 groupby 함수를 사용하면 특정 변수안에 있는 유일값들을 그룹화하여 원하는 정보를 끌어낼 수 있다.
예를 들어서 다음과 같은 코드를 작성한다면,
df.groupby(['origin','cylinders']).mean()[['mpg']]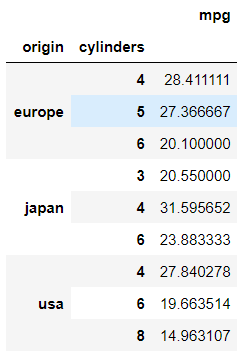
origin이라는 변수와 cylinders라는 변수를 그룹화하고 mpg라는 수치형 변수의 평균을 나타내라는 뜻이 된다.
groupby는 사용법이 정말 다양한데 만약에 마지막 인덱스를 컬럼으로 사용하고 싶다면 .unstack()라는 함수를 사용하면 된다. 예시는 다음과 같다.
df.groupby(['origin','cylinders'])['mpg'].mean().unstack()뿐만 아니라, 예를 들어 나는 origin을 기준으로 그룹화를 진행하고 각 그룹에 속한 mpg 값들의 빈도수, 평균, 합을 구하고 싶다고 한다면 .agg()를 이용하여 원하는 정보를 찾을 수 있다.
df.groupby(["origin"])["mpg"].agg(["count", "mean", "sum"])좀더 심화된 상황을 생각해보면 origin 변수를 기준으로 그룹화하고 mpg의 평균을, horsepower의 빈도수를, cylinders의 sum을 구하고 싶다면 다음과 같이 사용해볼 수 있을 것이다.
df.groupby('origin').agg({"mpg": "mean", "horsepower": "mean", "cylinders":"count"})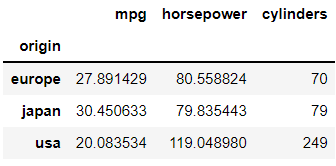
앞서 배운 기술 통계값을 확인하는 것도 가능하다. origin 그룹별 mpg의 기술 통계값을 확인하고자 한다면 다음과 같이 하면 된다.
df.groupby('origin')["mpg"].describe()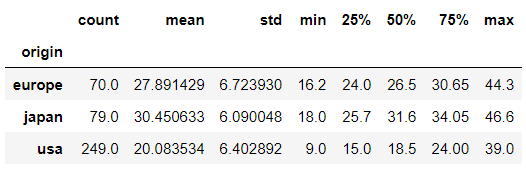
groupby를 적재적소에 이용하여 원하는 형태의 데이터 프레임을 만들면 더 좋은 플롯을 충분히 만들어 낼 수 있다.
pivot_table
pivot table 이란 많은 양의 데이터에서 필요한 자료만을 뽑아서 새롭게 표를 작성하는 기능이라고 생각할 수 있다. 내가 어떻게 정렬하거나 필터링할지에 따라 다양한 표를 만들어낼 수 있다.
pd.pivot_table(df,
index='origin',
)[['mpg']]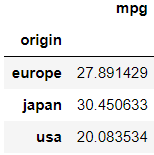
위에서 알 수 있듯 저러한 코드를 작성하면 index는 origin 이면서 mpg에 대한 평균에 대한 정보를 보여주는 테이블이 생성된다. [[ ]] 를 통해 데이터 프레임의 형식으로 확인이 가능한 것이다.
그렇다면 origin과 cylinders 갯수 별 평균 mpg에 대한 테이블은 어떻게 만들면 될까?
pd.pivot_table(df,
index=['origin', 'cylinders']
)[['mpg']]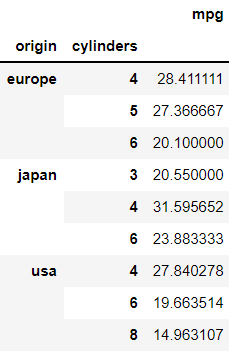
이때의 실린더는 범주형 변수처럼 쓰이면서 위와 같은 결과를 나타낸다. 위에서도 이미 보이지만 pivot_table의 기본 계산 방식은 평균이다.
만약,
pd.pivot_table(df,
index='origin',
)[['mpg']]에서 칼럼은 cylinders 이면서 mpg 평균이 아닌 합계를 확인하고 싶다면 다음과 같이 실행하면 된다.
pd.pivot_table(data=df,
index='origin',
columns='cylinders',
values='mpg',
aggfunc='sum')
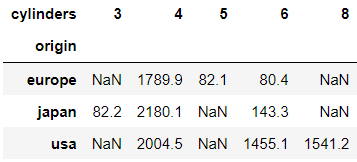
피벗 테이블 역시 원하는 형태의 테이블을 생성하여 원하는 정보를 살펴보기에 매우 유용하기 때문에 적극적으로 활용하도록 해야된다.
crosstab
crosstab도 위에서 만든 테이블들과 매우 유사하다. 범주형 변수를 기준으로 개수를 파악하거나 수치형 데이터를 넣어 계산할 때 사용한다.
예를 들어, origin과 cylinders를 이용하여 crosstab을 생성하면 각 origin별 특정 cylinders개수에 해당하는 값이 몇개인지에 대한 표가 나온다.
pd.crosstab(df['origin'],df['cylinders'])
이러한 기법들을 이용하여 범주형 데이터를 분석하는데 더욱 다양하고 유의미한 정보를 끌어내는데 적극 활용하도록해야 할 것이다.
