Review: Main idea of word2vec
- random word vector로 시작한다. 각 dimension을 0에 가까운 작은 수로 초기화한다.
- Learning : gradient decent algorithm(iterative algorithm)을 사용하여 parameter(word vector)를 업데이트한다.
Word2vec parameters and computations
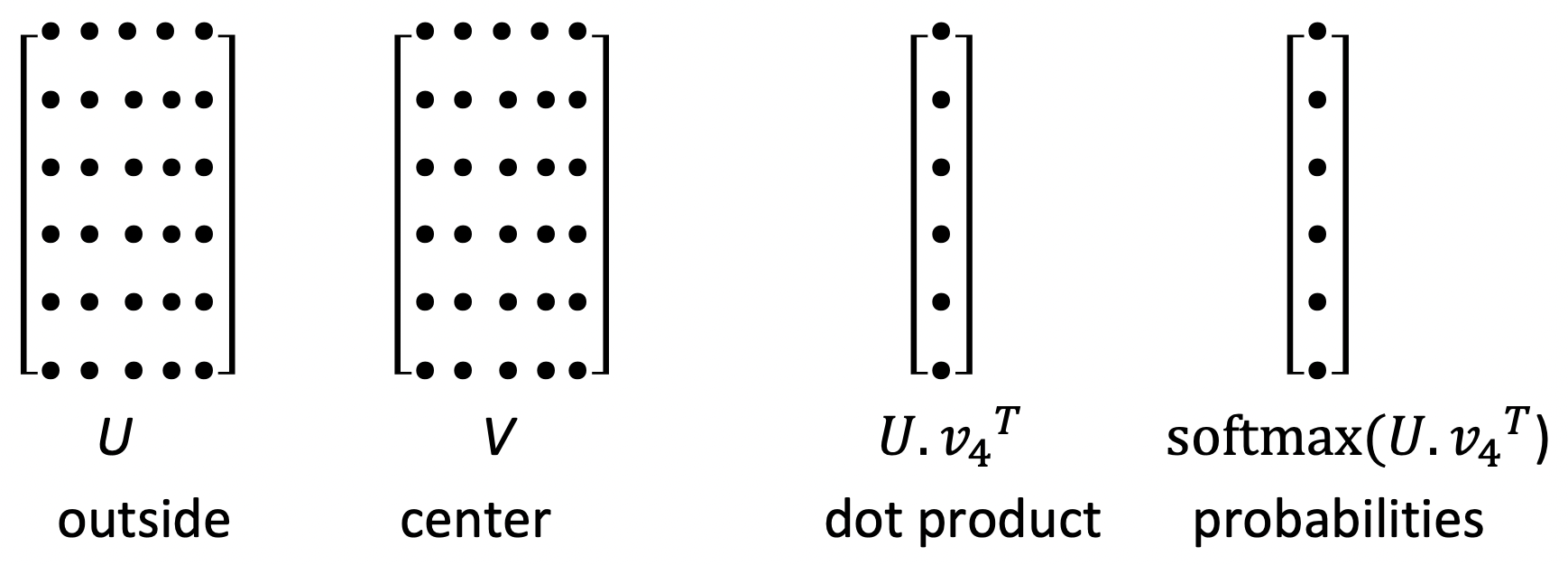
- Model의 parameter는 오직 word vector들이다.
- Computations
- word vector들을 dot product하여 특정 outside word가 center word와 함께 나타날 가능성에 대한 score를 얻는다.
- Softmax transformation을 사용하여 이 score를 probability로 변환한다.
- 이 model은 NLP, a bag of words model이라고 불린다. 이 bag of words model은 word의 순서나 위치를 고려하지 않는다. context 어느 위치에 있던지 간에 같은 probability estimate를 가진다. 그럼에도 word의 properties를 충분히 배운다!
- 우리는 이 model이 context에서 발생하는 모든 word들에 높은 probability estimate를 주기를 바란다. 하지만 context로 많은 word가 나올 수 있기 때문에 각 probability estimate는 작다.
- Learning phase of the model(model이 어떻게 achieve 하는가?)
- 고차원 vector space에서 비슷한 meaning을 가지는 word들을 서로 가깝게 배치한다. 비슷한 meaning을 가지는 word들이 group을 지을 수 있도록 한다.
- word vector는 고차원으로, 여러 다른 특성이 있다. 고차원 공간에서 다른 많은 것들과 가까울 수 있지만, 다른 차원에서 그것들과 가까이 있을 수 있다.
- 고차원 vector space에서 비슷한 meaning을 가지는 word들을 서로 가깝게 배치한다. 비슷한 meaning을 가지는 word들이 group을 지을 수 있도록 한다.
Optimization: Gradient Descent
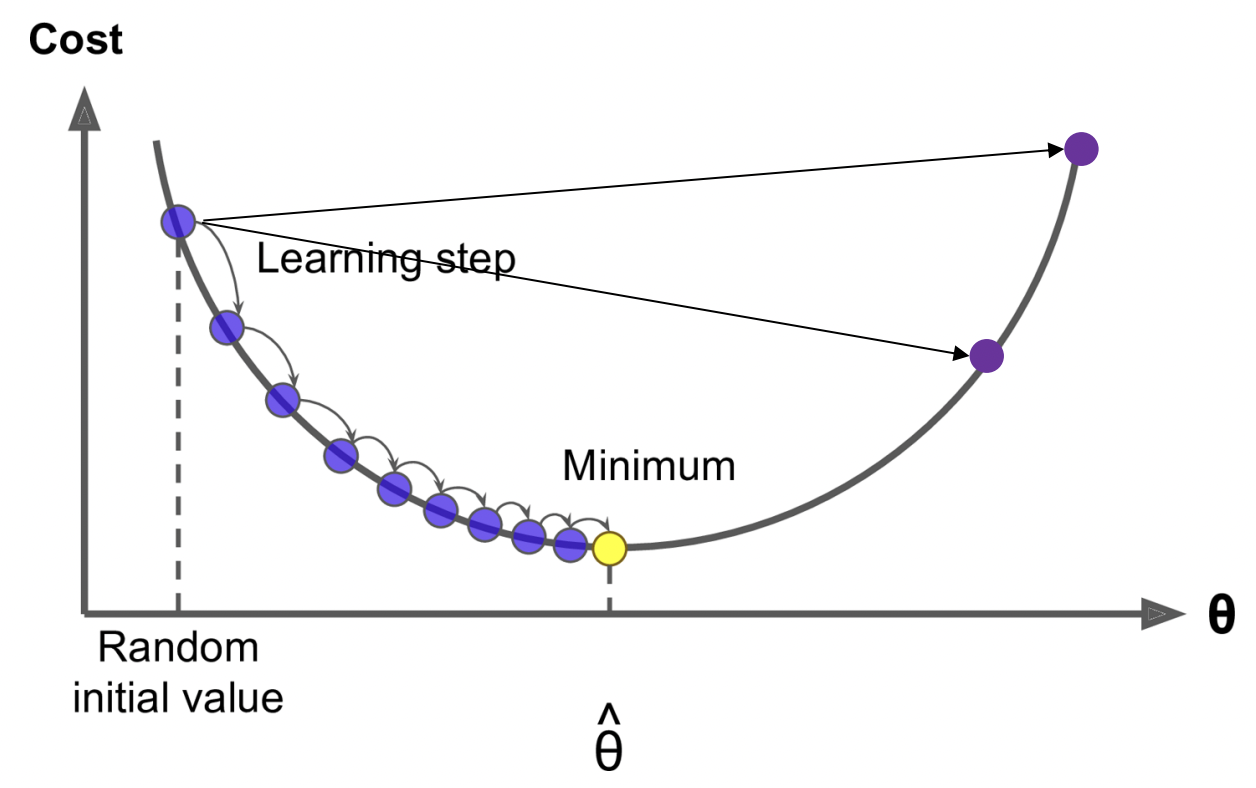
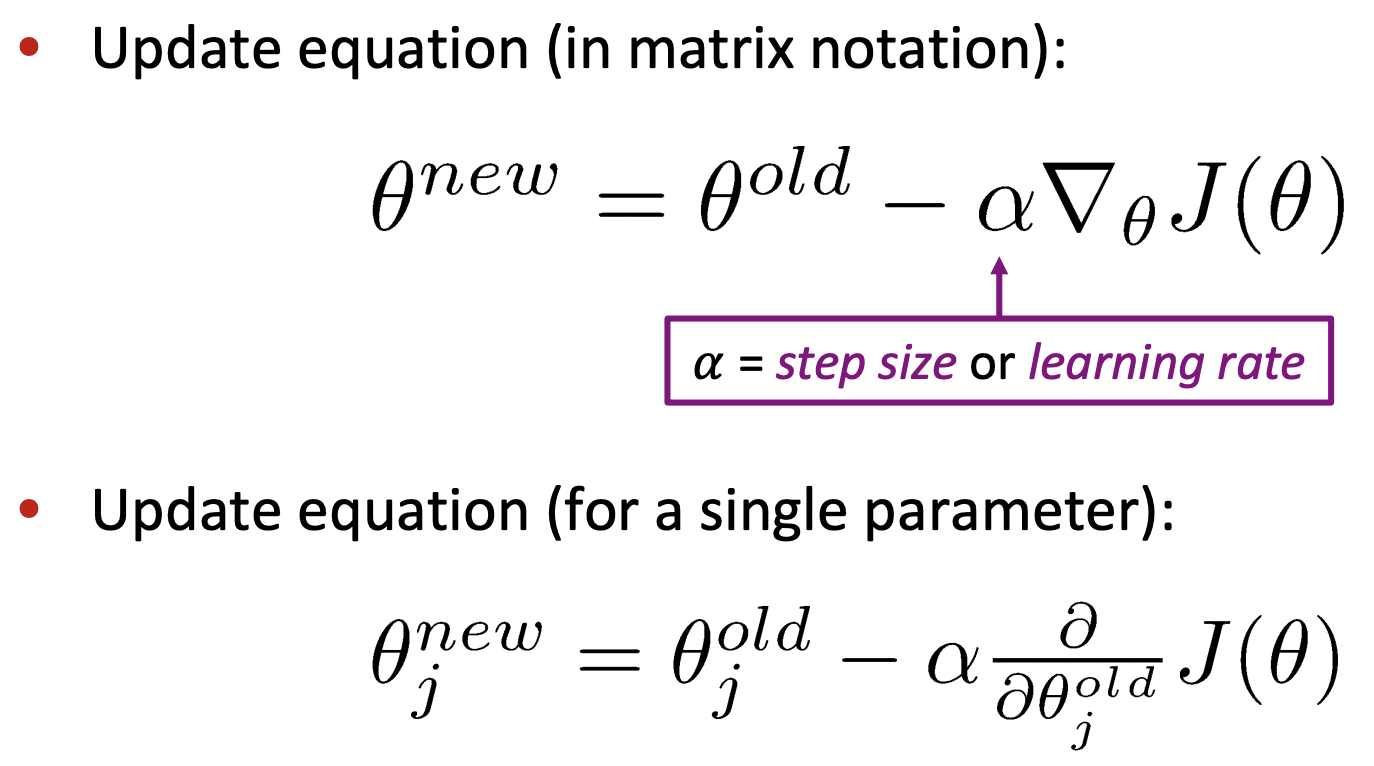
- To learn good word vectors: cost function J(Θ)를 최소화하고 싶다.
- parameter 에 대해 J(Θ)의 gradient를 계산하여, negative gradient 방향으로 small step을 간다. 이를 반복하여 점차적으로 minimum을 향해 내려갈 수 있도록 한다.
- Step size
- Too small : 최소점에 도달하는 데 오래걸린다. wasted computation 비용이 든다.
- Too big : 발산해서 엉뚱한 곳으로 가거나, 약간 아래로 가더라도 이리저리 bounce하여 minimum에 도달하기까지 오래 걸린다.
🔗 Problem
- corpus의 전체 window에 대한 함수인 J(Θ)의 gradient를 구하는 것은 계산 비용이 너무 expensive하다.
- single update를 할때까지 너무 오래 걸린다. optimization이 너무 느리다.
➡️ 거의 모든 neural net에서 gradient descent는 아무도 사용 안한다. 대신에 SGD를 사용한다!
Stochastic Gradient Descent
- 전체 corpus를 기준으로 gradient 추정치를 산출하는 대신, 단순히 하나의 center word나 32개의 center word와 같은 mini batch를 취하여 그것들을 기반으로 gradient 추정치를 산출한다.
- 만약 우리가 10억개의 word corpus를 가지고 있다면, corpus를 통과한 후에 parameters를 한 번 더 정확하게 업데이트하는 것보다 corpus를 한 번 통과하는 동안 parameter를 10억 번 업데이트할 수 있다. 이를 통해 전반적으로, 몇 배의 크기를 더 빨리 배울 수 있다.
- performance가 안좋은 것만도 아니다. neural nets는 counter intuitive properties가 있어 SGD가 noisy하고 bounce around 한다는 특성 때문에, complex한 network에서는 plain gradient descent로 천천히 학습하는것보다 SGD가 더 잘 학습한다.
➡️ So, SGD compute much more quickly and do a better job !`
Aside
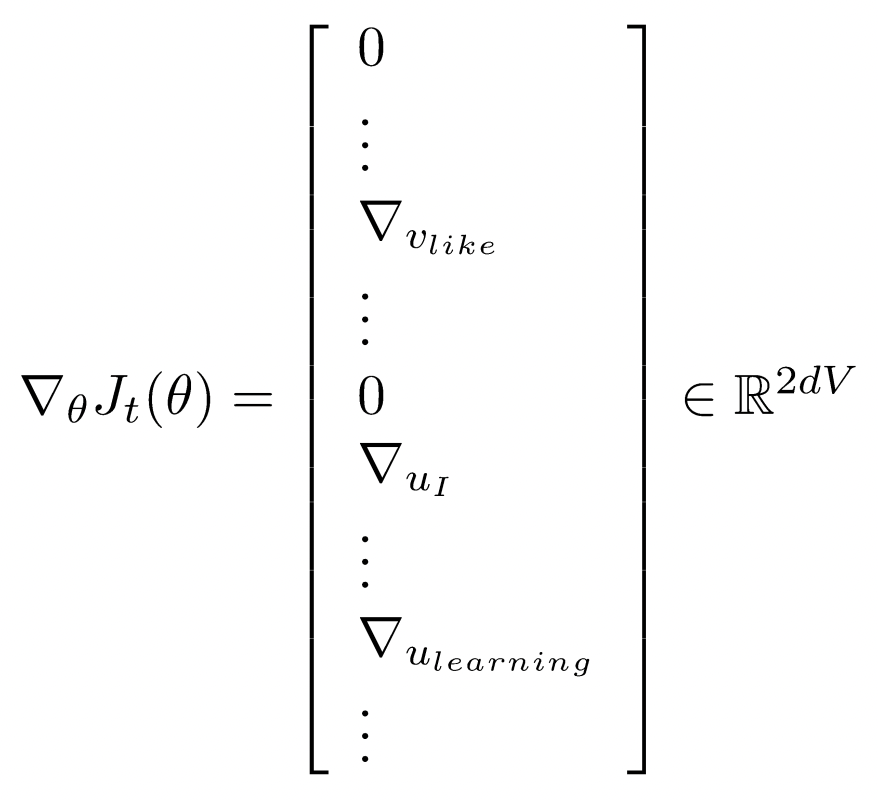
- 각각 window 하나에 대해 SGD를 하면, 각 window에는 2m+1개의 distinct word type 밖에 없기 때문에 2m+1개의 word에 대한 gradient 정보는 알지만 다른 vocabulary에 있는 많은 words는 gradient update information이 없다. 그래서 J(Θ)의 gradient vector는 매우 매우 sparse하다.
- system optimization을 생각하면, a few words에 대해서만 update하고 싶을 것이고 그것이 더 효율적이다.
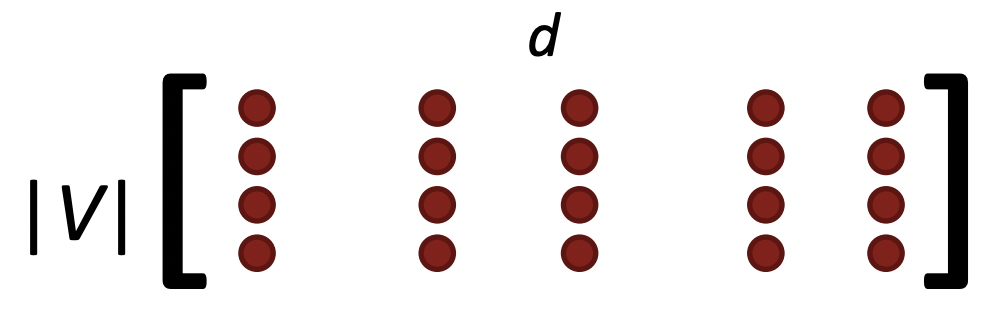
- word vectors는 row vectors로 표현된다. 이유는 row vectors로 표현하면 한 word vector 전체를 연속적으로 접근하기가 쉽다(in Pytorch).
Word2vec algorithm family: More details
- 한 word당 2개의 vector를 사용하는 이유 : easier optimization을 위해서이다. 1개의 vector를 사용하면 계산이 복잡해진다. 이유는 같은 word type을 center word와 context word로 갖는 경우, 해당 word에 대해 XTX를 수행해야 하는데 복잡해진다. 그래서 2개의 vector를 사용하고 마지막에 둘을 average한다. 이 두 vector는 random initialization과 SGD의 이유로 결국 비슷해지지만 같지는 않다.
🔗 Two model variants
- Skip-grams (SG) : center word가 주어지면 context words를 예측, Bag of Words 라고도 한다.
- Continuous Bag of Words (CBOW) : context words로부터 center word를 예측
🔗 Additional efficiency in training
- Negative sampling (Paper에서는 이것을 제안함)
- 위에서 설명한 것은 Naive softmax로, 간단하지만 expensive한 training method
The skip-gram model with negative sampling (SGNS)
🔗 배경
Naive softmax는 normalization term(분모 부분)을 수행하는 것이 expensive하다. vocab에 있는 모든 word에 대해 dot product를 반복해야하기 때문이다.
🔗 Main idea
True pair versus several noise pairs에 대해 binary logistic regression을 학습한다.
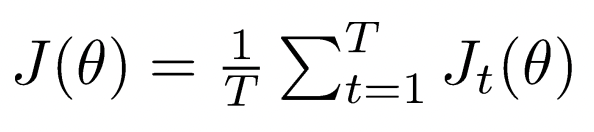
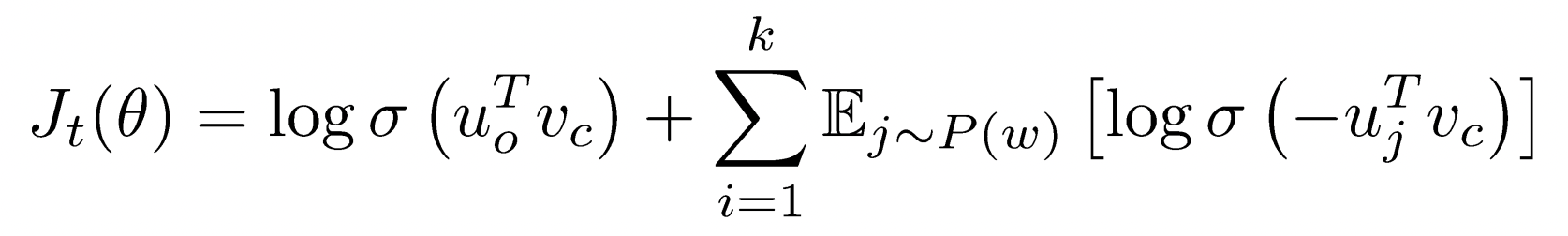
-
각 특정 center word에 대한 loss의 평균을 optimize하고 싶은 것은 동일하다.
-
center word와 context word의 dot product를 softmax에 넣는 것이 아니라 logistic function에 넣는다.
- logistic function(often called sigmoid function) : real value를 0과 1 사이 (0,1) probability로 mapping
-
실제로 co-occuring한 두 words의 probability를 maximize(첫 번째 log term), noise words의 probability를 minimize(두 번째 term)한다.
-
Minimizing the negative log likelihood
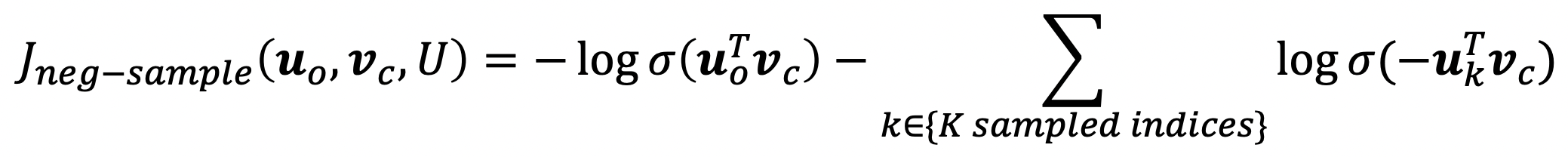
-
k개의 negative samples를 word probabilities에 기반하여 sampling한다.
-
Unigram distribution U(w)
- P(w) = U(w)^3/4 / Z 를 사용하여 sample한다.
- Unigram distribution은 얼마나 자주 words가 big corpus에 나타나는가에대한 probability이다.
- 3/4승을 통해 common word와 rare word의 차이의 기를 꺾는다. less frequent word가 좀 더 자주 sample되지만 uniform distribution에서 sample을 하는 것보다는 적게 sample되도록 한다.
- Z로 probability distribution을 renormalize한다.
Co-occurrence matrix
-
co-occurance matrix를 만드는 두 가지 방법
- window : 각 word마다 window를 사용한다. locality, syntactic 그리고 semantic information을 얻을 수 있다.
- full document : window size를 paragraph 또는 전체 web page로 만들고 그 안에서 co-occurence를 count한다.
- information retrieval이나 latent semantic analysis에 종종 쓰이는 기법이다.
-
Example
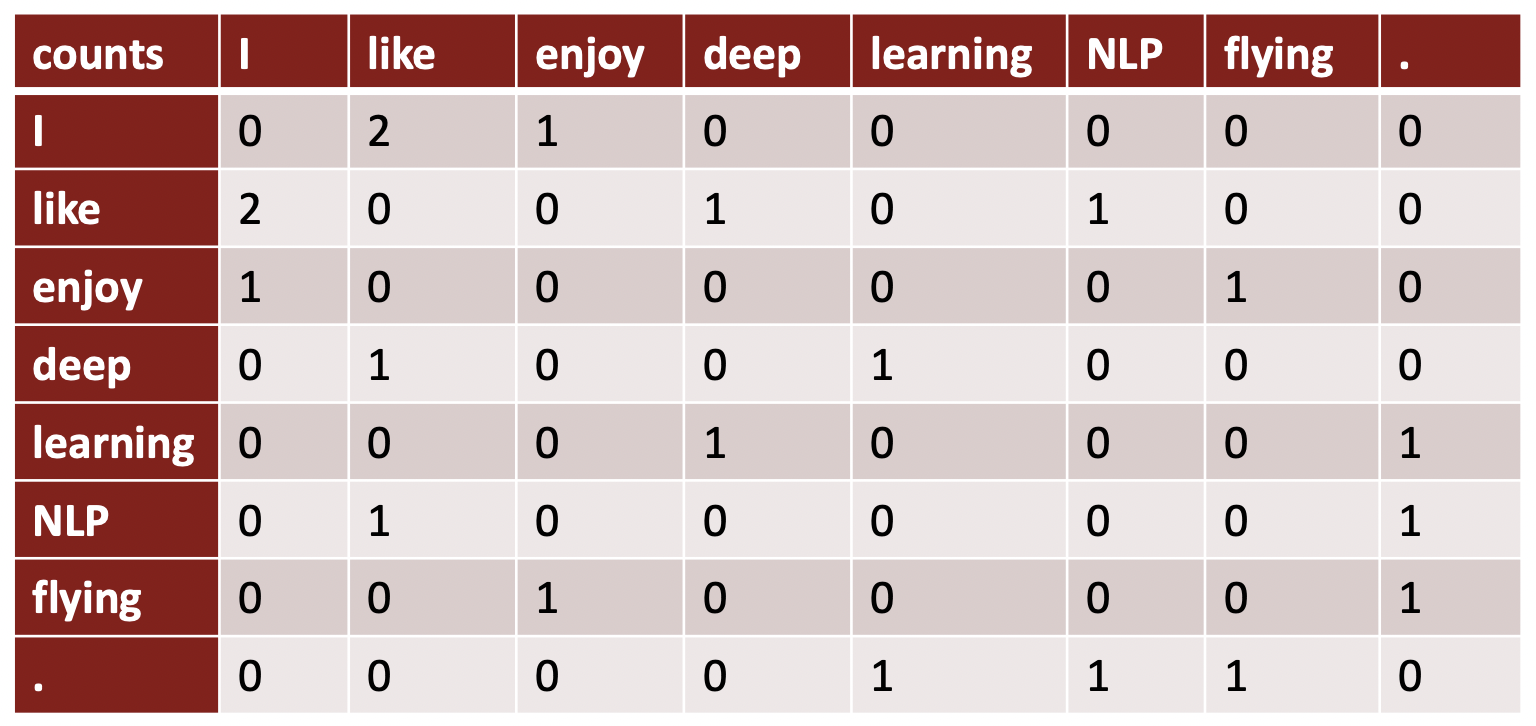
- Window length 1, symmetric
- cell 안에 있는 counts는 window size 1에서 얼마나 자주 co-occur하는지를 뜻한다.
- 이 matrix는 실제로 co-occurence vector 형태로 word들에 대한 representation을 준다.
- word "I"에 대한 reperesentation은 이 row vector이다. 비슷한 meaning과 usage를 가진 words는 비슷한 vector를 가질 것이라고 기대할 것이다. Ex. "I" and "You"
-
Problems
- Huge though very sparse. vocabulary size만큼 고차원이고 많은 sparsity와 randomness를 가지다보니 corpos에 어떤 특정 stuff가 있었냐에 따라 결과가 noiser하고 less robust한 경향이 있다. 많은 저장 공간을 필요로 한다.
-
Low-dimensional vectors
- low-dimensional vector를 사용할 때 더 나은 결과를 얻는다는 것을 알아내었다.
- Idea : 가장 중요한 정보를 작은 차원안에 저장하여 dense vector를 만든다.
- Classic Method: Singular Value Decomposition of co-occurrence matrix X
-
Problem : SVD를 돌린 것을 word vector로 사용하려고 하면 성능이 안좋다.
-
이유 : SVD 가정이 normally distributed error를 가져야하지만, word count는 'a', 'the'와 같이 특히 엄청나게 많이 나오는 단어와 매우 많은 드물게 나오는 단어가 있어 이 가정을 만족하지 못한다.
➡️ 여러 기법을 통해 counts를 scaling하여 co-occurrence matrix를 만들고 SVD를 돌리면 더 useful한 word vector가 나온다.
-
- Interesting semantic patterns emerge In the scaled vectors
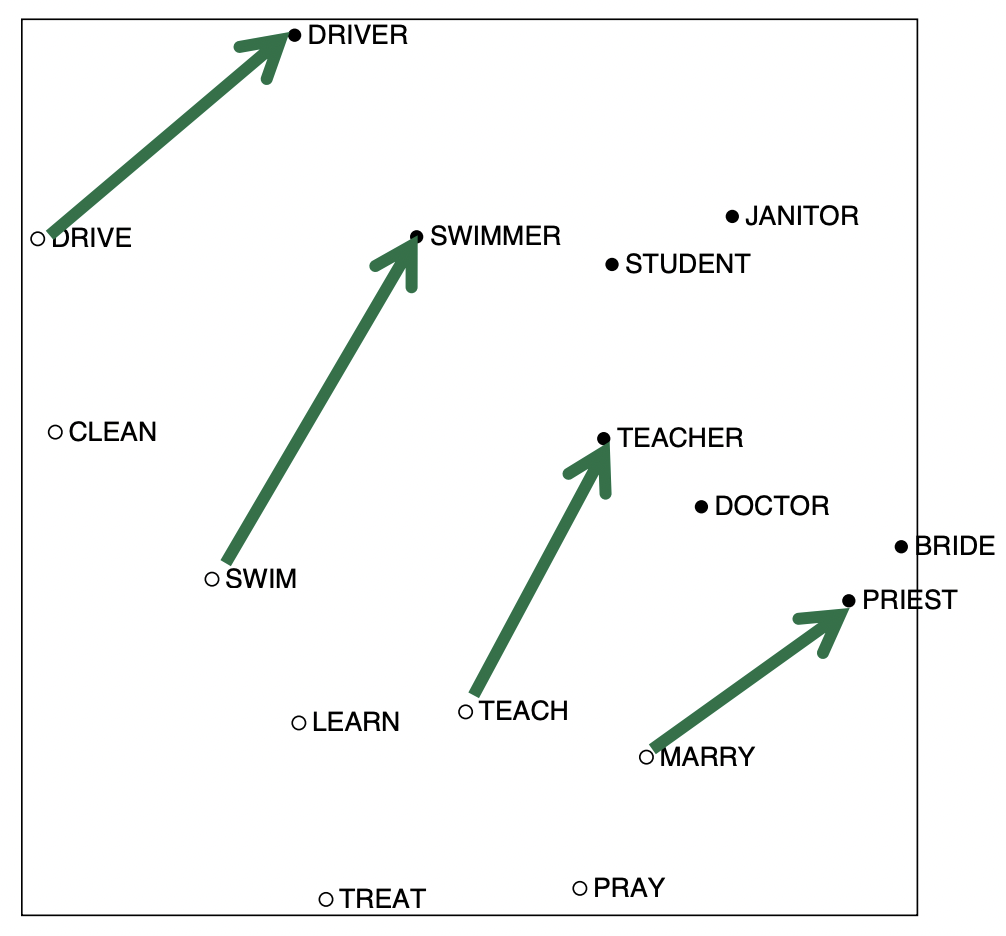
- COALS model : co-occurrence matrix를 향상시킬 수 있는 방안에 대해 연구
- 저번 강의에서 analogy 설명하면서 봤던 semantic components를 가진 같은 linear components를 얻을 수 있다.
- 위의 vector component들이 완벽하진 않지만 대략 평행하고 대략 같은 size를 가지고 있다. 즉, meaning component를 가지고 있어 전 강의의 analogy처럼 다른 단어에 더하고 빼고 할 수 있다.
- 이 space는 word vectors analogy를 얻을 수 있다.
Towards GloVe: Count based vs. direct prediction
- LSA, COALS와 같은 linear algebra에 기반한 co-occurrence matrix 기법과 SG, CBOW 같은 iterative neural updating algorithm model을 연결하자는 것이 시작이었다.
- 그런 analogy를 얻기 위해 어떤 특성이 있어야 하는가?
➡️ meaning component의 property가 있어야한다. 이러한 meaning component는 co-occurrence probabilities의 ratio로 표현되어야 한다.
🔗 Encoding meaning components in vector differences
- ⭐️ Ratios of co-occurrence probabilties can encode meaning components
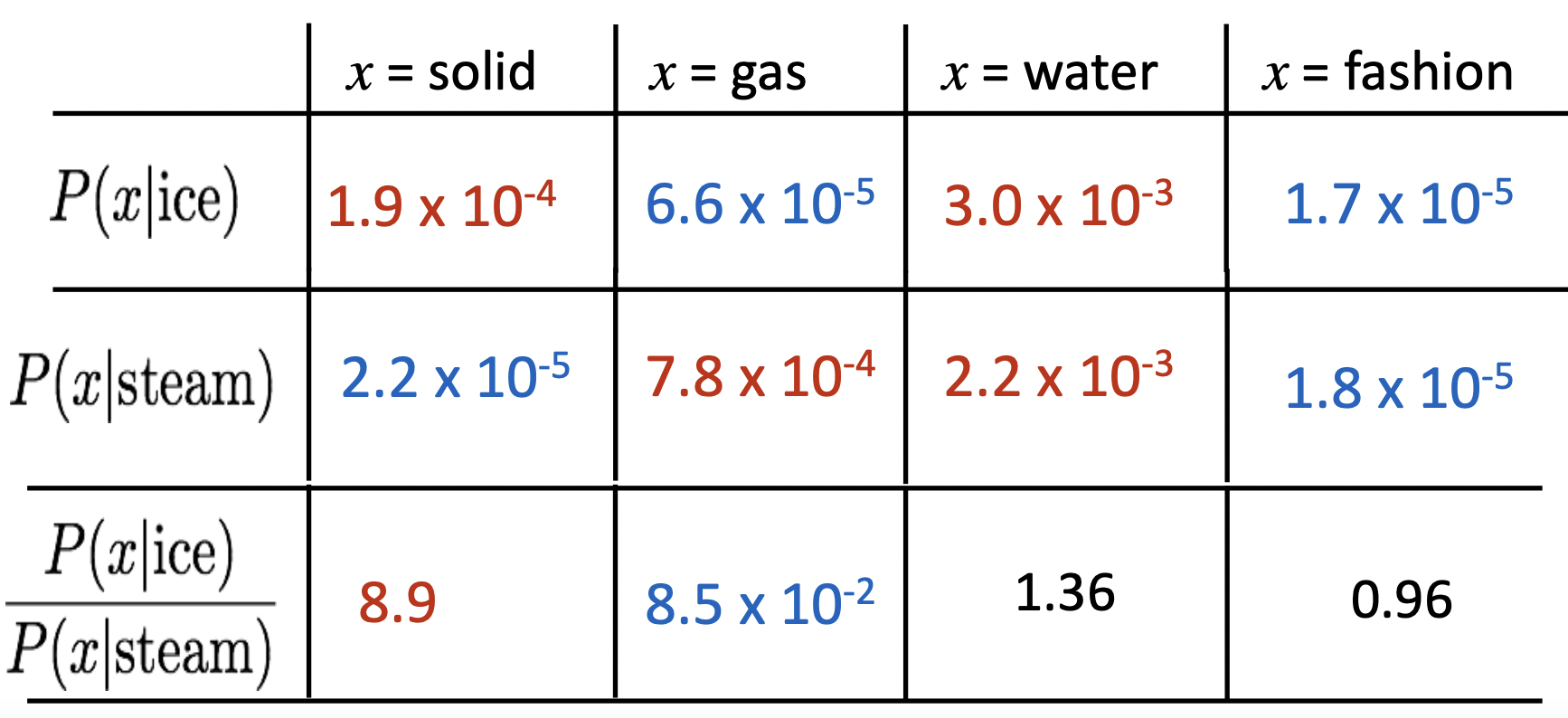
- 각 cell은 실제 co-occurrence probabilities
- Gas에서 solid로 가는 meaning component를 얻기 위해, 그들의 co-occurrence probabilities의 ratio를 보는 것이 useful하다.
- word vector space에서 어떻게 ratios of co-occurrence probabilities를 linear meaning component로 포착할까?
➡️ Build a Log-bilinear model!
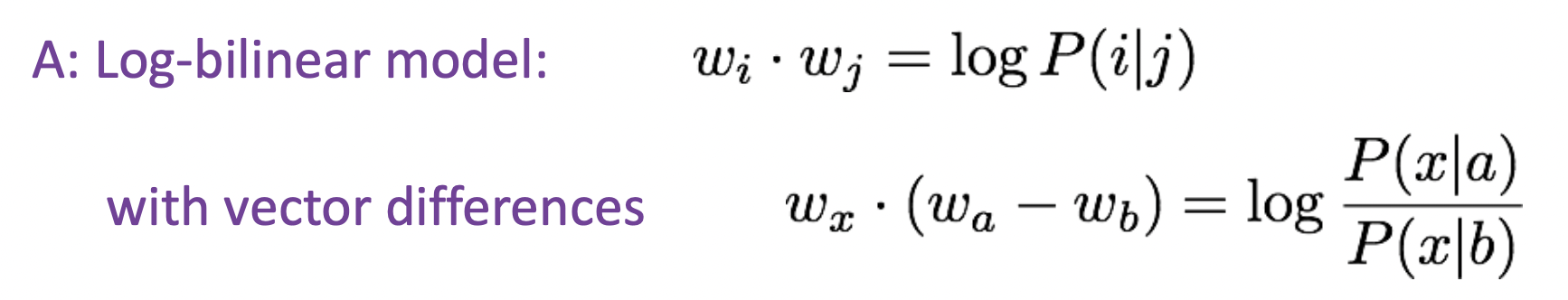
두 vector의 차이와 다른 word 간의 similarity는 log ratio of co-occurrence probabilities에 대응하게 된다.
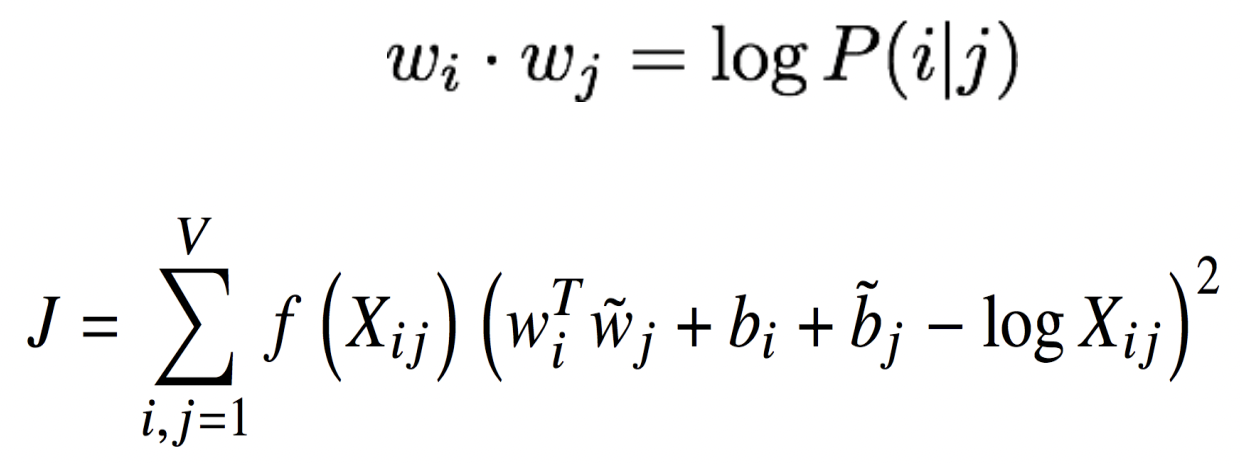
GloVe model은 co-occurrence model과 neural model이 통합되기를 바란다. 두 term이 같기를 바라기 때문에 두 차이를 최소화 하기 바란다.
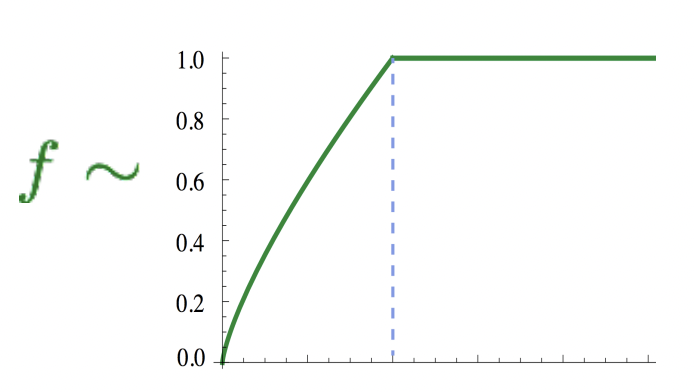
그리고 f function을 통해 scale을 하여 매우 흔히 등장하는 word 즉, 높은 word counts의 영향을 줄인다.
또한, co-occurence count matrix에서 직접 j loss function을 optimize할 수 있기 때문에 fast training과 scalable to huge corpora하다. 그리고 작은 corpus와 작은 vectors에 대해서도 성능도 좋다.
How to evaluate word vectors?
NLP evaluation에서 크게 두가지 evaluation 방법이 있다.
- Intrinsic evaluation
- 직접 너가 수행하고 있는 specific/intermediate subtask에서 evaluation
- Extrinsic evaluation
- 실제 task에서 evaluation
🔗 Intrinsic word vector evaluation
-
Word vector analogies

- word vector analogies에서 얼마나 model이 잘 맞추는지에 대한 accuracy score를 매긴다.
- GloVe word vectors evaluation
-
Another intrinsic word vector evaluation
- 얼마나 model이 word similarity에 대한 사람의 판단을 잘 modeling 하는가? 우리의 model이 같은 similarity judgement를 가지는지 본다.
- 특히, human과 same ordering of similarity judgement를 주었는지에 대한 correlation coefficient를 measure한다.
🔗 Extrinsic word vector evaluation
- 이 강의에서 모든 후속 NLP task이다.
- Named entity recognition : text에서 사람 이름 또는 회사 같은 단체 이름 또는 위치 언급을 식별하는 것
Word sense vectors
- 등장배경 : 대부분의 word들은 다양한 많은 다른 meaning을 가지고 있다. word vector는 space에서 one point, one vector이다. word당 one word vector만 가지고 있으면 어떻게 다양한 meaning을 capture할까?
- 해결 : 한 word의 다른 meaning들에 대해 다른 word vector들을 가진다.
- 어느정도 동작하지만, 실제로 주요하게 사용하지 않는다.
- 문제
- Simplicity : 먼저 word senses를 학습해야하고 그리고 word senses에 대해 word vector를 학습해야 한다. 복잡하다.
- k개의 다른 의미가 있어도 의미들끼리 연관되는 것들도 있어, word meaning을 어떻게 여러 다른 senses로 cut할것인가가 unclear하다. 실제로 여러 다른 dictionary를 보면 각자 다르게 한다.
➡️ 실제로는 한 word type당 하나의 word vector를 가지는 것이 꽤 잘된다.
Linear Algebraic Structure of Word Senses, with Applications to Polysemy
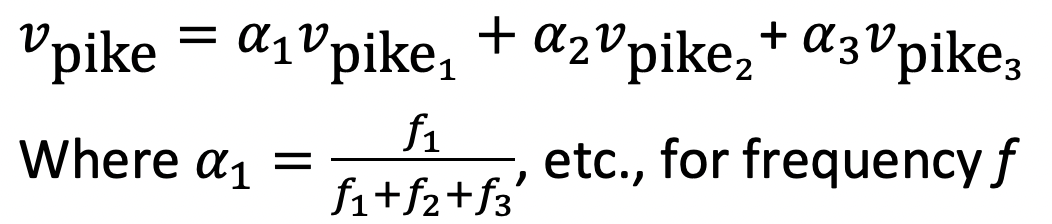
- 여러 다른 senses of a word에 대한 linear superposition (weighted sum)of the word vectors를 학습한다.
- weight는 단어마다 사용하는 빈도수에 따라 결정된다. 결국 v_pike는 average vector가 된다.
- 결과 : 실제로 이 average vector를 application에 사용하면 self-disambiguate하는 경향이 있다. 고차원 vector space 일때, vector가 매우 sparse하기 때문에 sparse coding 아이디어를 사용하여 서로 다른 sense를 실제로 분리할 수 있다(비교적 흔한 것이라면).
- 그리고 사실, 우리는 어떤 component가 같은 context에서 사용되는 다른 word들과 similar한지를 보는 것만으로도 어떤 "pike"의 sense가 의도된건지 알아낼 수 있다. 예를 들어 fish sense를 가진 v_pike의 part of vector가 component들 중에서 fish를 represent하므로 v_pike는 fish vector와 비슷할 것이다. 그래서 상당한 similarity가 있다고 할 수 있다.
Reference
- CS224n: Natural Language Processing with Deep Learning Lecture at Stanford University
