Word Meaning

word(signifier or symbol)과 이 word가 의미하는 것, 즉 signified thing(an idea or thing)의 쌍
- denotational semantics라고 한다.
- programming language의 의미론에 대해서도 이 개념이 유사하게 적용된다.
WordNet

- 컴퓨터에서 Word Meaning을 가지기 위한 NLP 초기의 해결책
- 동의어 집합과 상위어의 목록을 포함하는 유의어를 저장하고 사용하였다.
🔗 문제점
- Nuance가 부족하다. 동의어라고 분류한 두 단어가 어떤 경우에는 맞지만, 많은 다른 context에서는 동의어라고 보기 어렵다.
- 최신 정보를 유지하는 것이 어려워 새로운 meaning of words를 반영하지 못한다.
- 구축하려면 많은 사람들의 노력이 필요하다.
- 구축이 된다고 해도, word similarity를 정확히 계산하기 어렵다.
➡️ Word similarity에 대한 아이디어를 발전시키기에는 딥러닝 모델이 탁월할 것이다.
One-hot vector
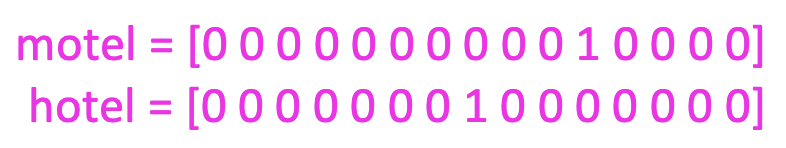
- 과거 statistical machine learning system에서는 symbol들을 별개의 것으로 표현하고 싶었기 때문에 단어들이 discrete symbol로 여겨졌다.
🔗 문제점
- 사전에 있는 단어의 개수만큼의 엄청나게 큰 차원의 vector가 필요했다.
- 더 큰 문제 : 단어들간의 관계나 similarity의 개념이 없다.
Distributional semantics

- 단어의 의미는 가까이에 자주 나타나는 단어들에 의해 주어진다. 어떤 context에서 이 단어가 나타나는가?
- statistical과 deep learning NLP에서 가장 성공적인 idea중 하나
- text에서 word w가 나타나면, 그것의 context는 근처에서 나타난(fixed-size window 내에 있는) 단어들의 집합이다.
- 이러한 context words들이 word banking의 meaning을 표현한다.
Two senses of word
- Types : banking이라는 단어가 쓰인 많은 예를 수집하고, banking이라는 단어와 그것의 많은 예들을 말할 때, 이 단어가 여러 사례에 걸쳐 가지고 있는 uses과 의미를 가리키는 type으로 취급한다.
- Tokens : 단어에 있는 banking은 tokenWord vectors

- context에서 발생하는 word들을 vector로 보는 것에 기반을 두어 각 word에 대해 dense real valued vector를 형성하고, 이 vector는 그 word의 meaning를 나타낸다. 그리고 그것이 그 단어의 의미를 나타내는 방법은 이 vector가 context에서 발생하는 다른 word들을 예측하는데 유용할 것이라는 것이다.
- 각각의 word는 word type이며, word vector를 가진다.
- 위 그림은 8차원이지만, 실제로는 더 큰 vector를 사용한다. 흔히 300 dimentional vector를 사용한다.
- word vectors는 word embeddings 또는 (neural) word representations라고 불린다.
- Distributed representation(not a localized representation)이다. 왜냐하면 banking word의 의미가 300차원 vector에 흩어져 있기 때문이다.

또한 word embedding으로 불리는 이유는, 단어들 묶음이 있을 때 이 표현들이 word들을 모두 고차원 벡터 공간에 배치한다. 그래서 word들은 그 공간에 embedding된다. 비슷한 의미를 가진 word들끼리 가깝게 위치한 것을 볼 수 있다.
Word2vec
🔗 Idea
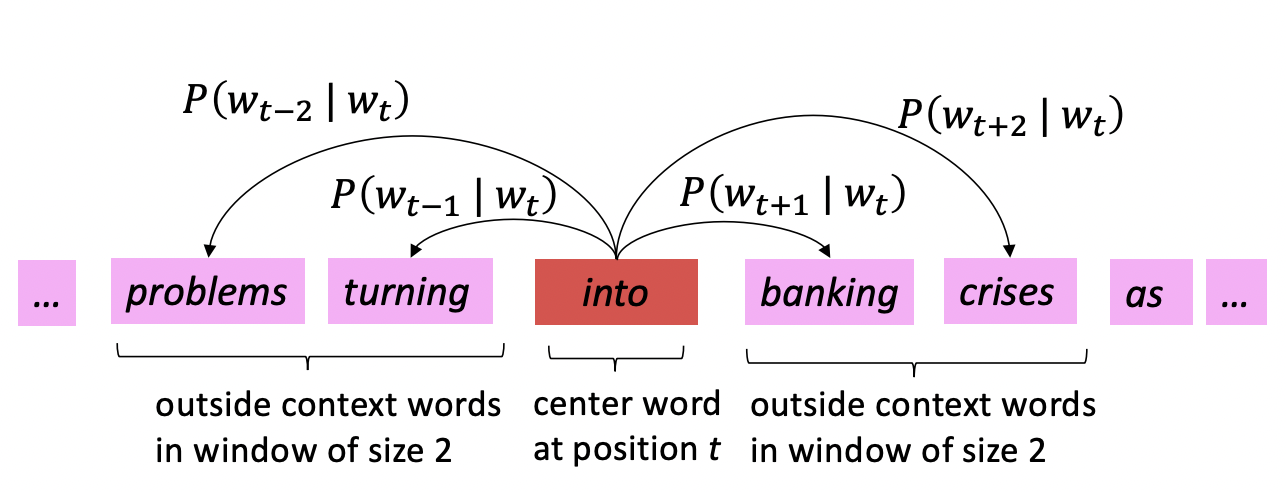
- 큰 text의 corpus("body")를 가지고 있다.
- fixed vocabulary를 선택하고, 각 word를 vector로 표현한다.
- text의 각 위치 t를 보면, center word c가 있고 context("outside") words o가 있다.
- 현재 word vector를 기반으로, center word가 주어지면 context word가 발생할 확률을 계산한다.
- Word vector를 계속 조정하여 실제 발생한 context word에 해당하는 확률을 최대화한다.
🔗 Objective function
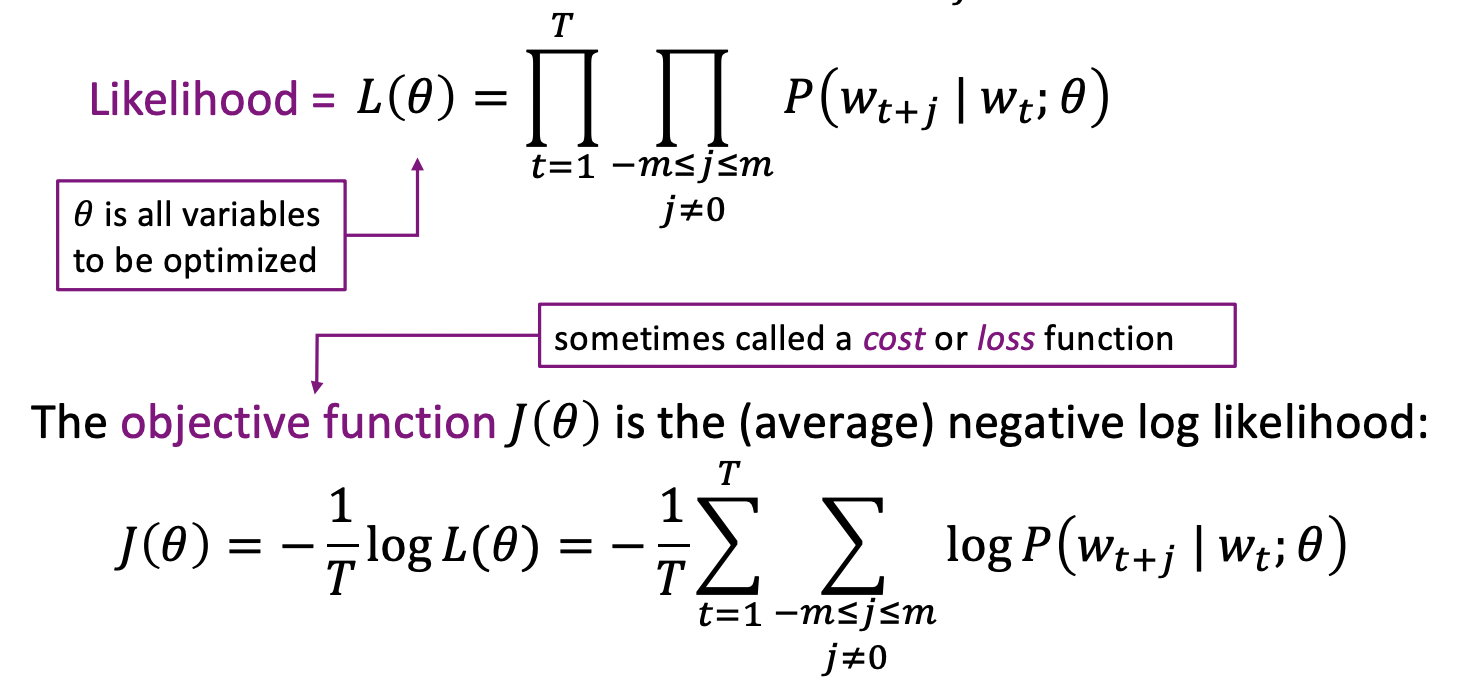
- position t = 1,...,T
- window of fixed size m
- center word
- word vectors, all parameters of model Θ
- center word 주변 context word의 likelihood를 maximize하고 싶다.
- Minimizing objective function <=> Maximizing predictive accuracy
- 각각의 word w 마다, 두 개의 word vector가 있다.
- when w is a center word
- when w is a context word
🔗 Prediction function
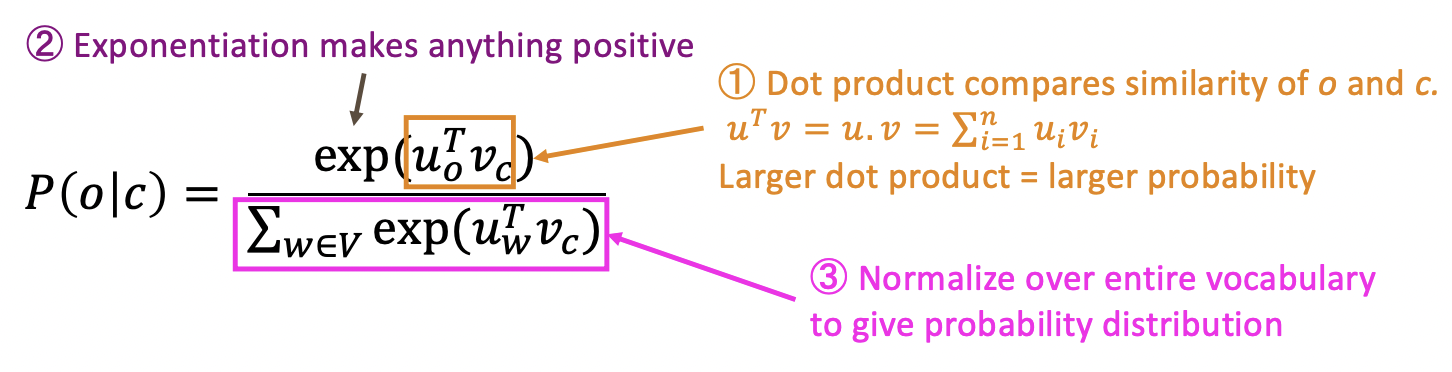
- 와 를 dot product한다.
- dot product는 단어들 사이 similarity에 대한 measure이다.
- 두 단어의 dot product가 크면 클수록, 두 단어는 서로 더 similar하다는 것이다.
- 음수를 피하기 위해 exponential을 취한다.
- probabiliy distribution을 얻기 위해 normalize한다.
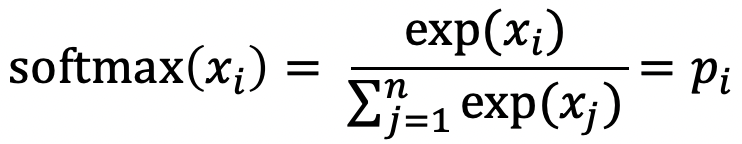
<softmax function>
- vector에서 임의의 실수 R을 0과 1 사이 value로 변환한다.
- 임의의 value를 probabiliy distribution으로 mapping한다.
- distribution을 리턴한다.
- max : exponentiate하기 때문에 큰 수를 강조하며, 대부분의 확률은 가장 비슷한 것들로 간다.
- soft : 여전히 비슷한 모든 것에 약간의 확률을 준다🔗 To train the model: Optimize value of parameters to minimize loss
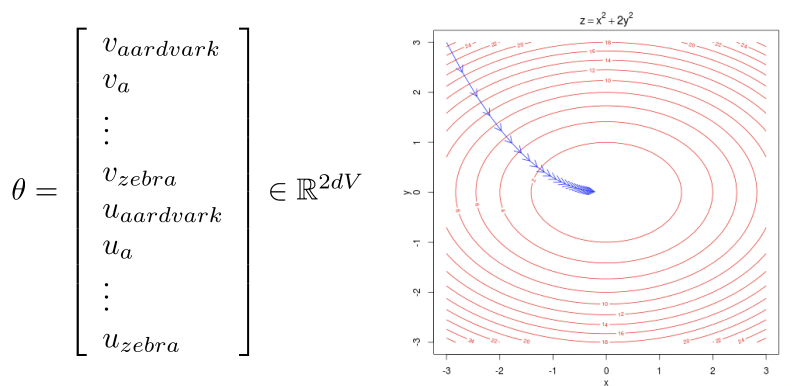
- d-dimensional vectors
- V-many words
- 각 단어마다 2개의 vector를 가진다.- context word의 prediction을 maximize하기 위해 parameter들을 모두 optimize 하고 싶다.
- 모든 vector gradients를 계산한다.
🔗 Word2vec derivations of gradient

내려가는 방향, gradient를 구하기 위해 objective function 수식을 model의 모든 parameter에 대해 편미분을 수행한다.
- center word vector(300차원 word vector)에 대해 편미분을 수행
- 결론 : 우리의 모델이 평균적으로 우리가 실제로 보는 word vector를 정확하게 예측한다면 모델의 성능은 좋다. 그래서 모델의 매개변수를 조정하려고 한다. 실제로 특정한 probability estimates는 약간 작을 것이지만, 그럼에도 불구하고 가능한 한 높은 estimates를 만들기 위해 word vector를 조작한다.
Gensim word vectors example
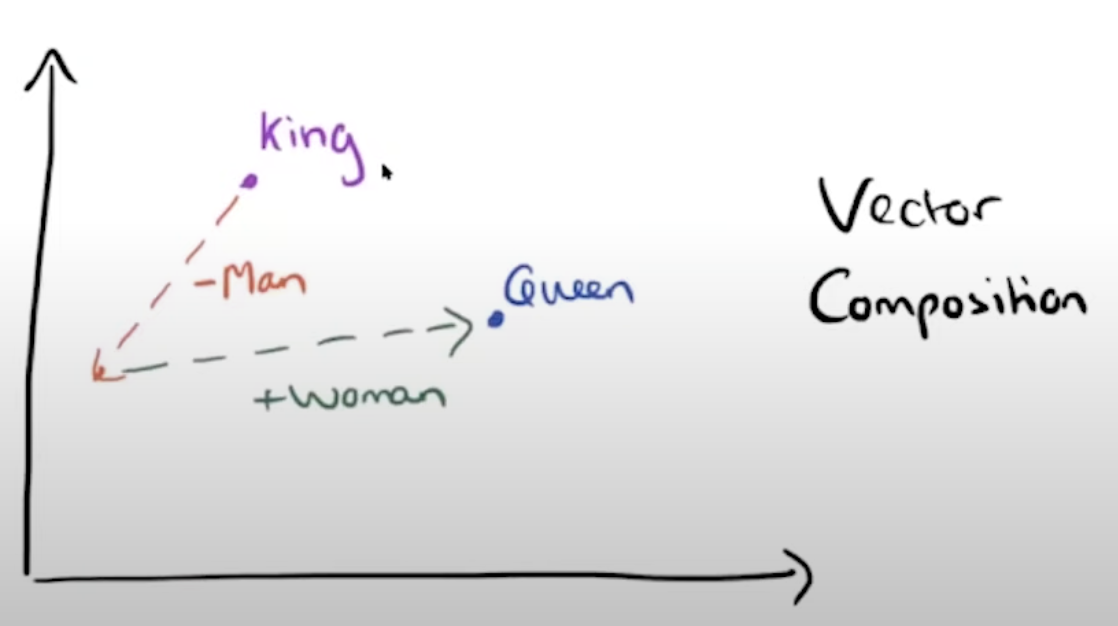
- 벡터 공간에서 산술을 할 수 있다.
- analogy task
- space에 있는 king word에서 시작하여 man component를 빼고 woman component를 더했을 때 나온 point와 가장 similar한 것으로 queen이 나온다.
Question
❓ Word마다 두 개의 vector를 사용하는 이유
계산이 복잡해지지 않게 하기 위해서이다. 그리고 optimize를 하면 할 수록 두 vector는 비슷해져 결국 word당 similar한 representation 2개를 얻게 된다. 마지막에는 이 둘을 average하여 하나의 word vector를 얻게 되어 각 word당 word vector 하나를 가지게 된다.
Reference
- CS224n: Natural Language Processing with Deep Learning Lecture at Stanford University

AI researcher