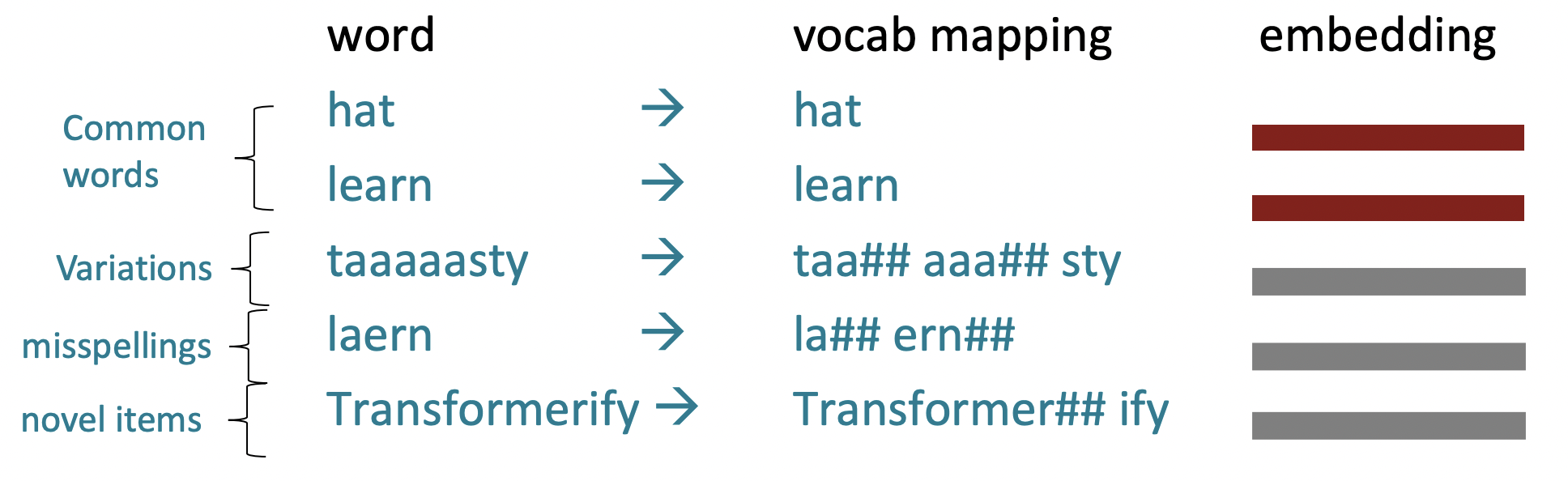
Subword modeling
🔗 배경
Fixed vocabulary를 가정하고 character의 개별 sequence가 그 word를 고유하게 식별하는 것처럼 word를 보게 되면, training set에서 보지 못한 새로운 word들은 UNK로 mapping되기 때문에 잘못된 것이다.
🔗 The byte-pair encoding algorithm
- character로만 되어있는 것과 "end-of-word" symbol로 시작한다.
- Corpus of text를 사용하여 가장 흔하게 발생하는 인접한 character들을 찾아 subword로 추가한다.
- 해당 character쌍의 instance들은 이 새로운 subword로 대체한다.
- 원하는 vocab size가 될 때까지 반복한다.
원래 machine translation에서 사용되었지만, 현재는 유사한 방법(WordPiece)이 사전 훈련된 모델에서 사용된다. 아이디어는 같다.
일반적인 단어는 subword vocabulary의 일부가 되는 반면, rare한 단어는 (때로는 직관적이고, 때로는 직관적이지 않은) 구성 요소로 나뉜다.
Transformer는 input이 word인지 subword인지 모른다.
Pretraining whole models
🔗 Motivation
- Word2vec으로 word에 embedding을 주면, 더이상 neighbor, 문맥은 보지 않는다.
- I record the record: 두 record는 다른 의미인데 같은 word2vec embedding을 준다.
🔗 Pretained word embeddings
-
그동안은 이미 pretrained된 word embedding으로 시작하고, task를 train함으로써 LSTM 또는 Transformer에서 context를 통합하는 방법에 대해 배웠다.
-
문제
- Downstream task에 대한 training data는 언어의 모든 contextual 측면을 가르치기에 충분해야 한다.
- 대부분의 parameter가 random하게 초기화되어야 한다.
- Downstream task를 위한 많은 양의 labeld data를 가지고 있지 않으면, 이 data에 너무 큰 역할을 주게 된다.
➡️ 전체를 다 공동으로 pretrain한다. 그럼으로써 full pretrained model에게 individual word만 주지 않고 해당 word의 embedding을 학습하도록 한다.
🔗 Pretraining whole models
현대 NLP에서 하는 방식이다.
- NLP network에 있는 모든 parameter들이 pretraining을 통해 초기화된다.
- 사전 훈련 방법은 input의 일부를 model에서 숨기고 해당 부분을 reconstruct하도록 모델을 훈련시킨다.
- 이것들을 강력하게 구축하는데 매우 효과적이다.
- representations of language
- parameter initializations for strong NLP models
- pretrain된 parameters로 시작하고, 갖고 있는 labeled data에 맞춰 finetune한다.
- probability distributions over language that we can sample from
- like in language modeling
- 실제로 특정 case에서 sample하는 데에 정말 유용하다.
🔗 The Pretrainig / Finetuning Paradigm
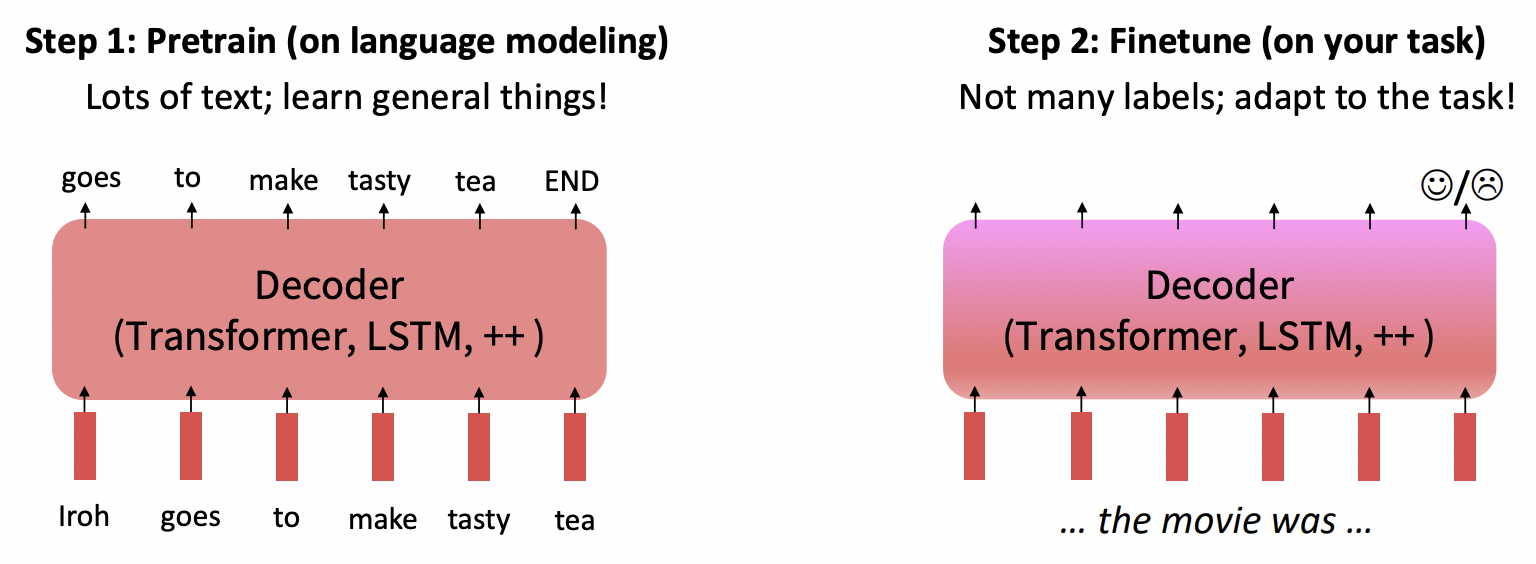
- Pretrain된 parameter값으로 시작하여 하고자 하는 task에 pretrained network를 적응시킨다.
🔗 Stochastic gradient descent and pretrain/finetune
- Θ hat과 가까운 local minima를 찾는 stochastic gradient descent의 locality가 language model의 general problem에 좋다.
- Θ hat 근처에서 finetuning loss gradient가 잘 propagate된다.
Model pretraining
Model을 pretraining하는 세 가지 방법이 있다.
- Decoders
- Language model
- Generate하기 좋다.
- Future word를 conditioning할 수 없다.
- Encoders
- Bidirectional context를 얻을 수 있어 future word를 conditioning할 수 있다.
- Representation of language를 구축하기 좋다.
- 어떻게 pretrain할지 생각해봐야 한다. Future access가 가능하기 때문에 langauge model pretrain하듯이 할 수가 없다.
- Encoder-Decoders
- Decoder의 좋은 점과 Encoder의 좋은 점을 둘 다 얻는다.
- 어떻게 pretrain할지 생각해봐야 한다.
Pretraining decoders
Pretrained decoder와 interacting하는 두 가지 방법이 있다.
1️⃣
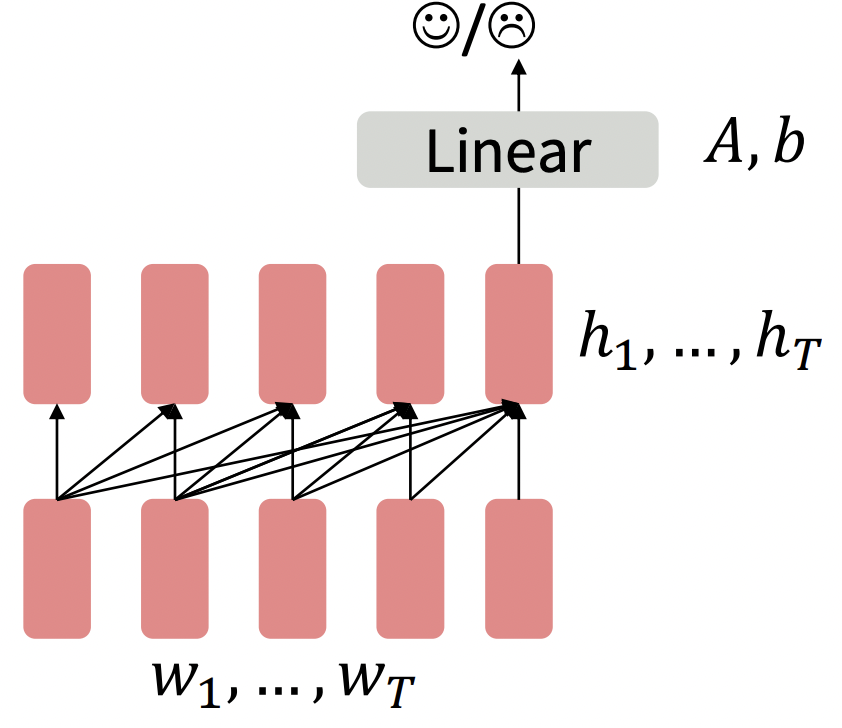
- Language model pretrained decoder를 사용하면 마지막 word's hidden state에 대한 classifier를 훈련함으로써 finetune할 수 있다.
- ,..., = Decoder(,...,)
y ~ A + b- A와 b는 randomly initialized되고 downstream task에 맞춰 optimize된다.
- Fine tuning loss function으로 전체 network를 통해 gradient가 backpropate된다.
2️⃣
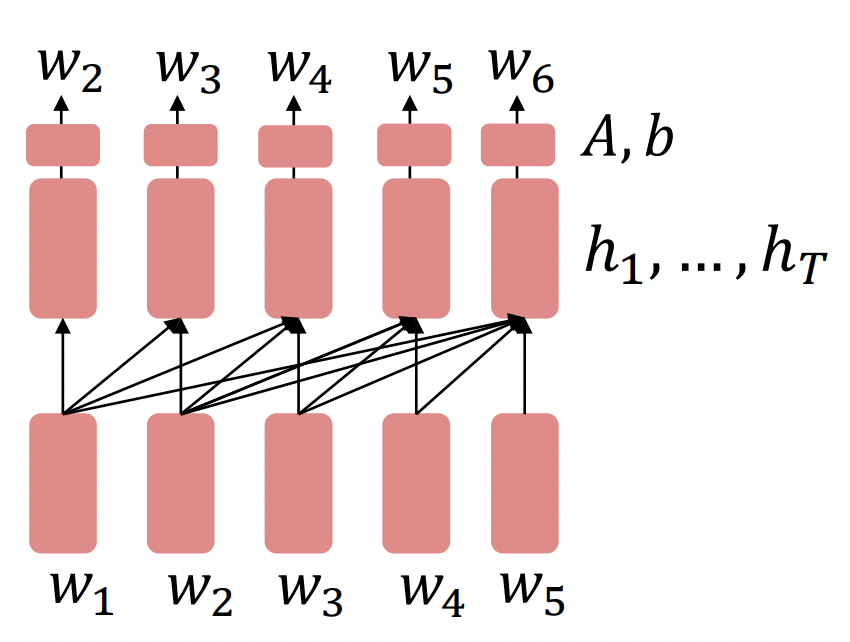
-
Language model로 decoder를 pretrain하고 (|w^(1:t-1))를 finetune하여 generator로 사용할 수 있다.
-
,..., = Decoder(,...,)
~ Ah^(T-1) + b -
output이 사전 훈련 시간에 해당하는 vocabulary를 가진 sequence인 task에서 유용하다.
- Dialogue(context=dialogue history)
- Summarization(context=document)
-
A와 b는 language model에서 pretrain된 것이다.
대표적인 pretrained decoder로 GPT가 있다.
Generative Pretrained Transformer(GPT)
- Transformer decoder 12 layers
- 768-dimensional hidden states, 3072-dimensional feed-forward hidden layers
- Byte-pair encoding with 40,000 merges
- Trained on BooksCorpus: over 7000 unique books.
- long-distance dependencies를 학습하기 위한 긴 범위의 연속 text를 포함한다.
✔️ Finetuning task
- Natural Language Inference: sentence쌍을 entailing/contradictory/neutral로 label한다.
Pretrained model을 사용하면, 들여야 하는 task-specific effort 양이 매우 작아진다.
Pretraining encoders
어떤 pretraining objective를 사용해야 할까?
🔗 Masked LM
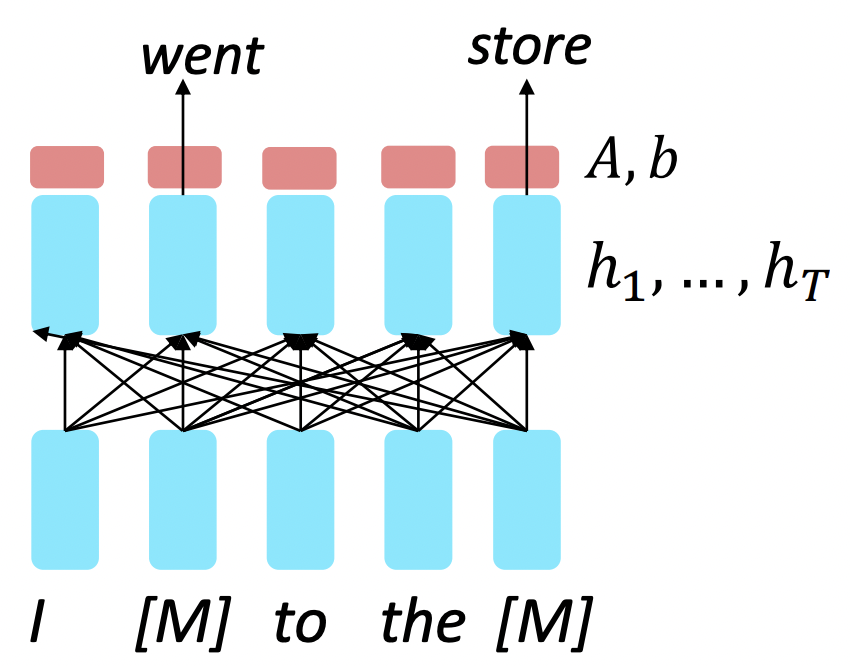
- Sentence의 일부 word들을 special [MASK] token하고 이 "masked out"된 word들로부터의 loss terms만 add한다.
- ,..., = Decoder(,...,)
~ A + b- A, b는 pretrained된 것이다.
BERT: Bidirectional Encoder Representations from Transformers
처음 "Masked LM"을 제안하였다.
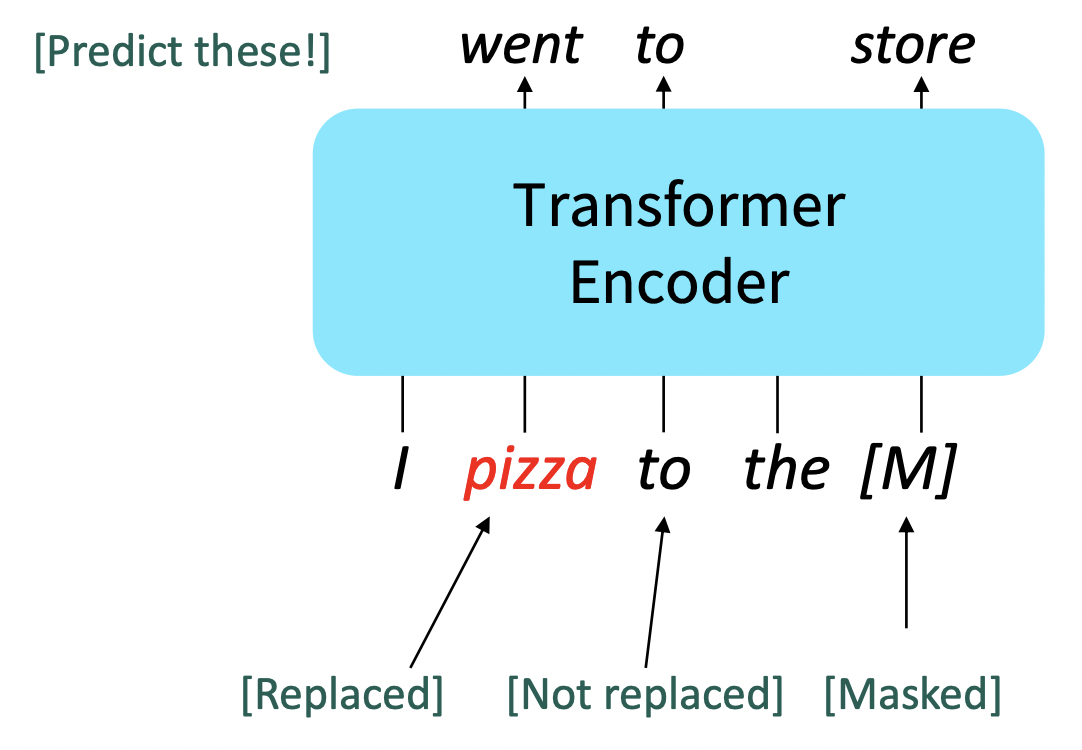
🔗 Some more details about Masked LM for BERT
- (sub)word tokens에서 랜덤하게 15%를 predict한다.
- 그 중 80%는 input word를 [MASK]로 대체한다.
- 그 중 10%는 input word를 random token(random vocabulary item)으로 대체한다.
- 그 중 10%는 input word를 안바꾸고 냅둔다.
➡️ 모델이 안주하고 non-masked word들에 대해 strong representation을 구축하지 않는 것을 막는다. 모델에 uncertainty를 추가한다.
- Fine-tuning time에는 mask가 없을 것이기 때문이다.)
✔️ Next sentence prediction objective
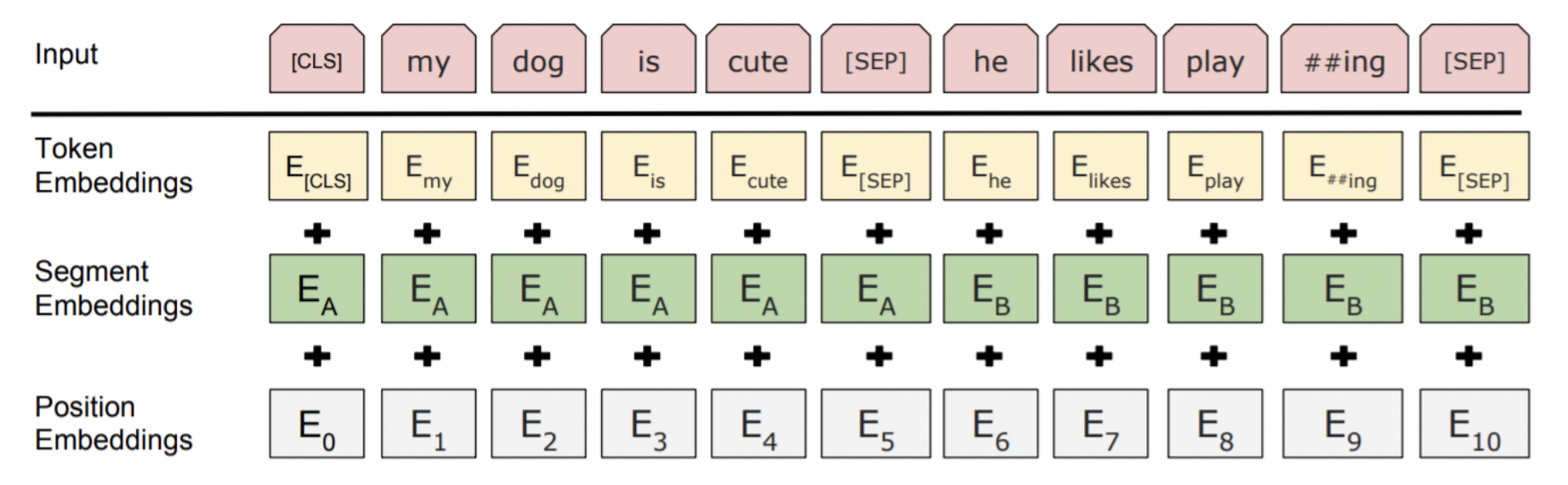
-
모델에 서로 다른 두 text간의 관계를 가르치고 싶다. 그래서 두번째 text 부분에 가끔은 dataset에서 실제로 뒤에 이어 나오는 text를 쓰기도 하고, 가끔은 randomly sample해서 unrelated인 것을 쓴다. 모델은 두 text간의 관계를 추론하여 둘 중 어느 case인지 예측해야 한다.
- 하지만 나중에 연구에서 next sentence prediction이 불필요하다는 주장이 나왔다. 왜냐면 2배 긴 single context를 input으로 넣어 longer distance dependencies를 학습하는 것이 더 좋다.
🔗 Details about BERT
-
Two models were released
- BERT-base: 12 layers, 768-dim hidden states, 12 attention heads, 110 million params
- BERT-large: 24 layers, 1024-dim hidden states, 16 attention heads, 340 million params
-
Trained on
- BooksCorpus (800 million words)
- English Wikipedia (2,500 million words)
-
Pretrain은 64 TPU chips를 사용하여 4일이 걸렸는데, finetuning은 single GPU로도 가능하며, 빠르고 실용적이다.
🔗 Limitations of pretrained encoders
Encoder가 strong representation을 구축하는 데에 좋긴 한데, pretrained decoder인 GPT model과 같은 방법으로 sequences를 generate할 수 없다. Autoregressive (1-word-at-a-time) generation method로는 적합하지 않다.
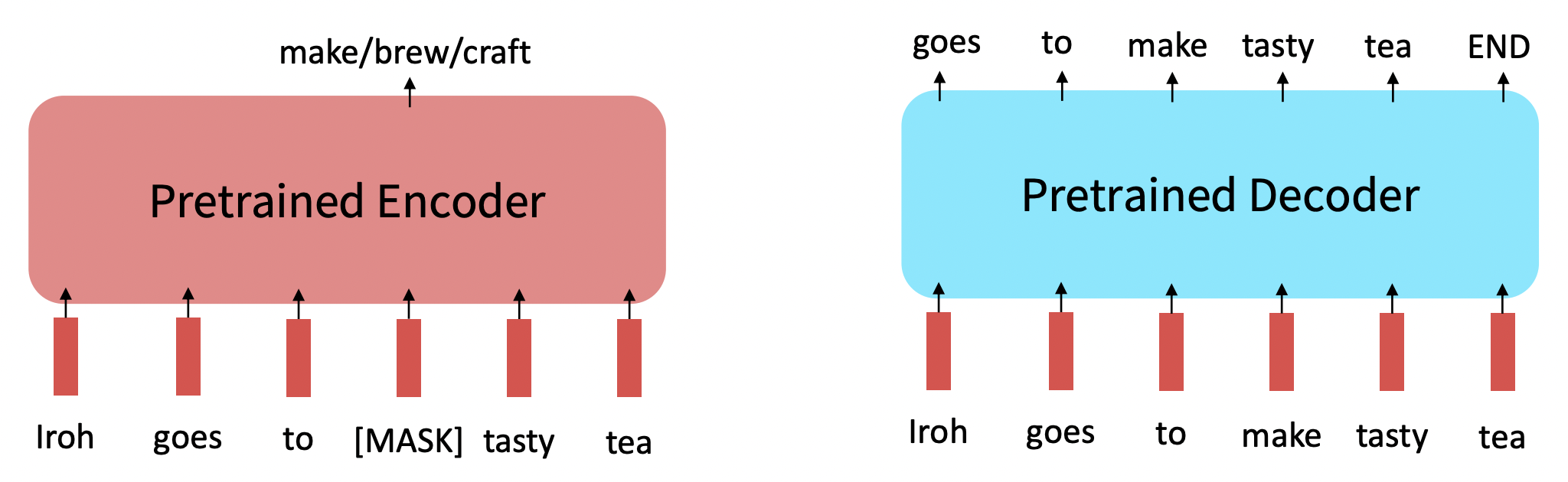
🔗 Extensions of BERT
-
RoBERTa
- BERT가 underfit되었다는 것을 보여주며, 같은 model을 더 많은 data에 대해 오래 training하고 batch size를 크게 하여 오래시간 training하여 더 좋은 성능을 얻어냈다.
- Next prediction prediction을 없앴다.
-
SpanBERT
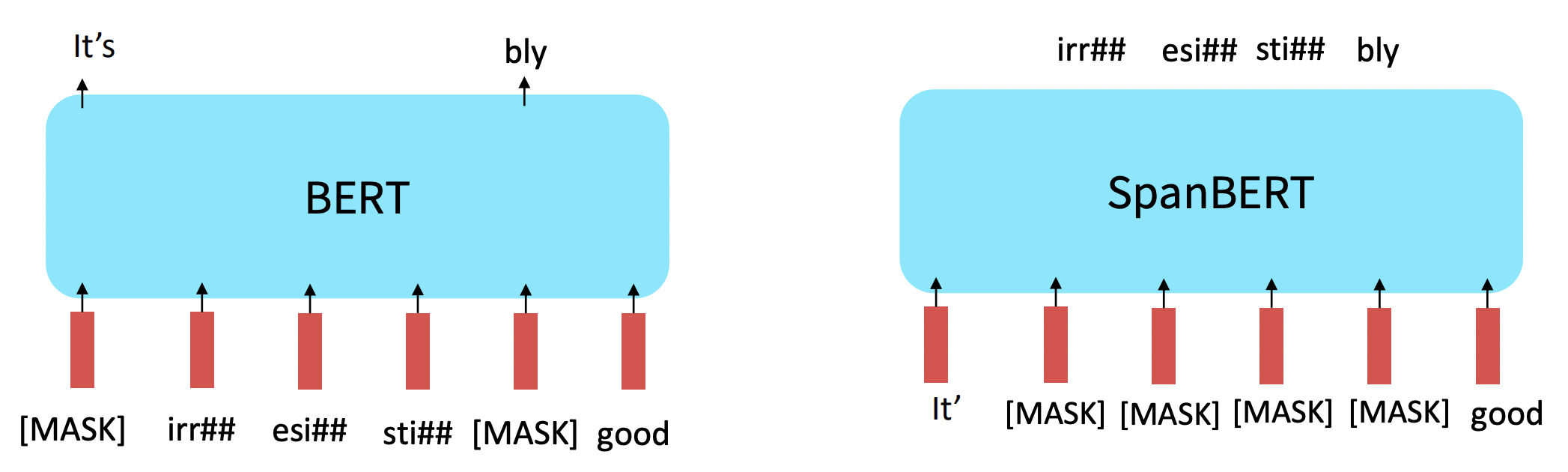
- Words의 연속적인 긴 범위를 masking하는 것은 더 어렵고 더 유용한 pretraining task을 만든다.
Pretraining encoder-decoders
어떤 pretraining objective를 사용해야 할까?
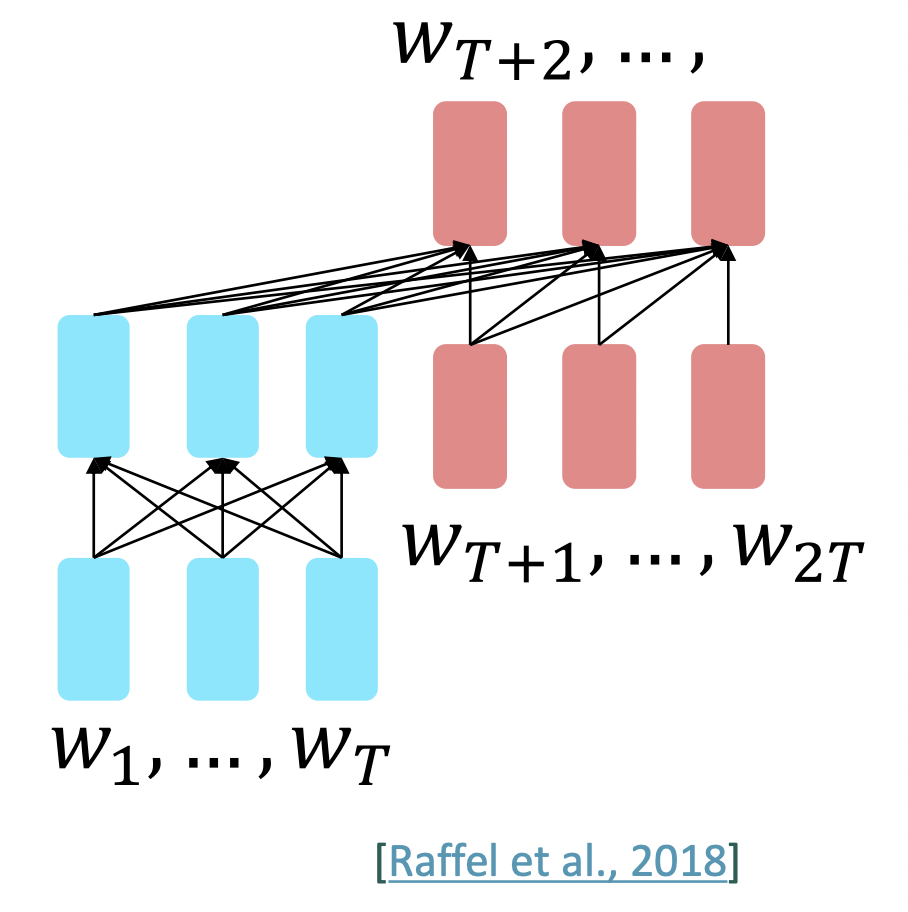
-
Encoder-decoders에서는, language modeling같은 것을 하는데, input의 prefix가 encoder에 들어가고 예측되지 않는다.
-
,..., = Encoder(,...,)
h_(T+1),...,h_2T = Encoder(,...,,,...,)
~ A + b, i>T -
Sequence의 절반은 encoder부분의 bidirectional context을 통해 strong representation을 구축할 수 있고 예측은 수행하지 않는다. 다른 절반은 language modeling을 통해 예측을 수행하여 전체 model을 train하는데에 사용된다. 하나의 language modeling loss로 전체 model을 훈련하여 두 부분이 모두 잘 pretrained되기를 바란다.
T5 : span corruption
Span corruption을 하면 매우 유용하다는 것을 알아내었다. 모델의 이름은 T5이다.
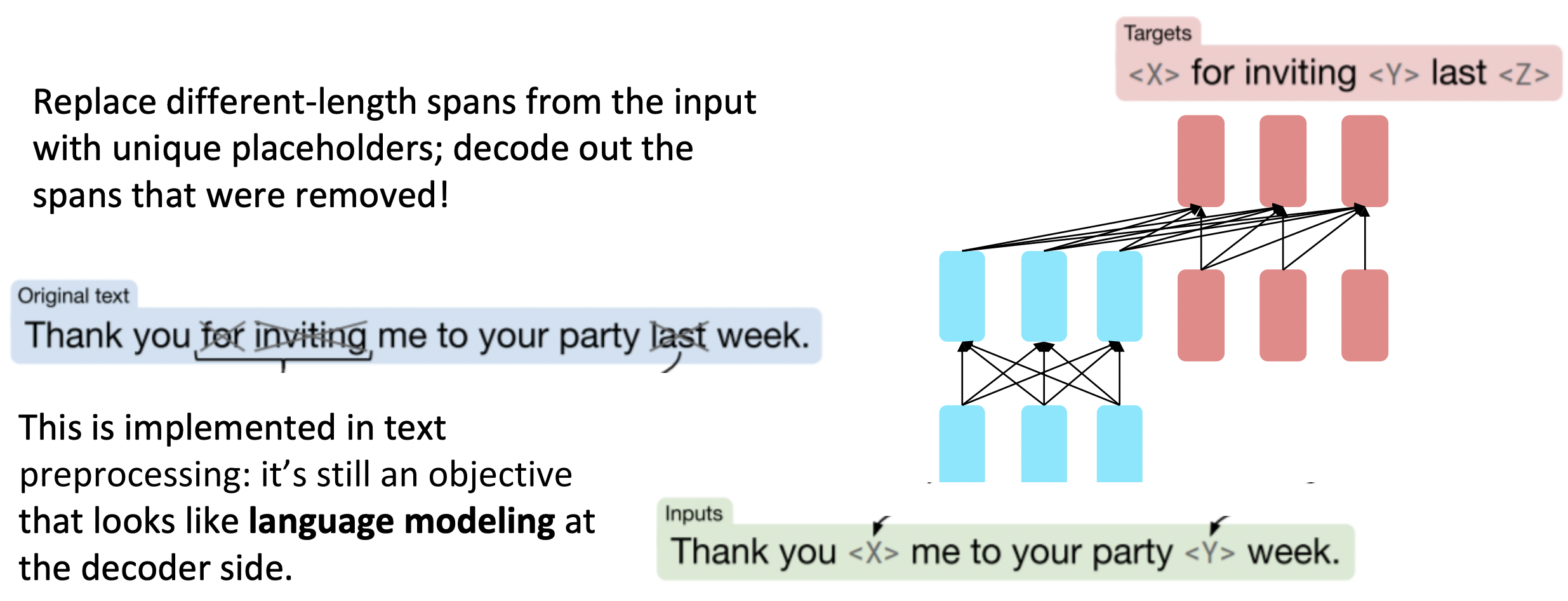
🔗 Span corruption
- Input에서 다른 길이의 간격을 unique placeholder로 바꾸고, 제거된 이 간격을 decode out한다.
- 이것은 text preprocessing 단계에서 implement된다. 그것은 여전히 decoder측면에서 language modeling처럼 보이는 objective이다.
- 숨겨논 것이 얼마나 긴지 모른다는 점에서 BERT와 차이가 있다.
🔗 Usage
- Pretrain된 T5는 넓은 범위의 question에 answer하도록 finetune될 수 있다.
- Parameters로부터 지식을 검색한다(retrieving knowledge).
- Test time에서 새로운 question에 대해 어느 정도 정확하게 parameters에서 answer을 회수할 것이다.
GPT-3, In-context learning, and very large models
지금까지 pretrained model과 두 가지 방식으로 interact하였다.
- Sample from the distributions they define
- 우리가 하고자 하는 task에 finetune하고, prediction을 얻어낸다.
모델을 language model로 취급하는 것과 연관된 세 번째 방식이 있다.
Very large language model은 단순히 decoder context 안에서 제공하는 example로부터, gradient step 없이, 어떤 종류의 학습을 수행하는 것처럼 보인다.
GPT-3가 그러한 예이다. GPT-3는 175 billion parameters를 가진다.
In-context examples는 수행할 task을 지정하는 것처럼 보이고, conditional distribution은 작업을 어느정도 수행하는 것을 흉내낸다.
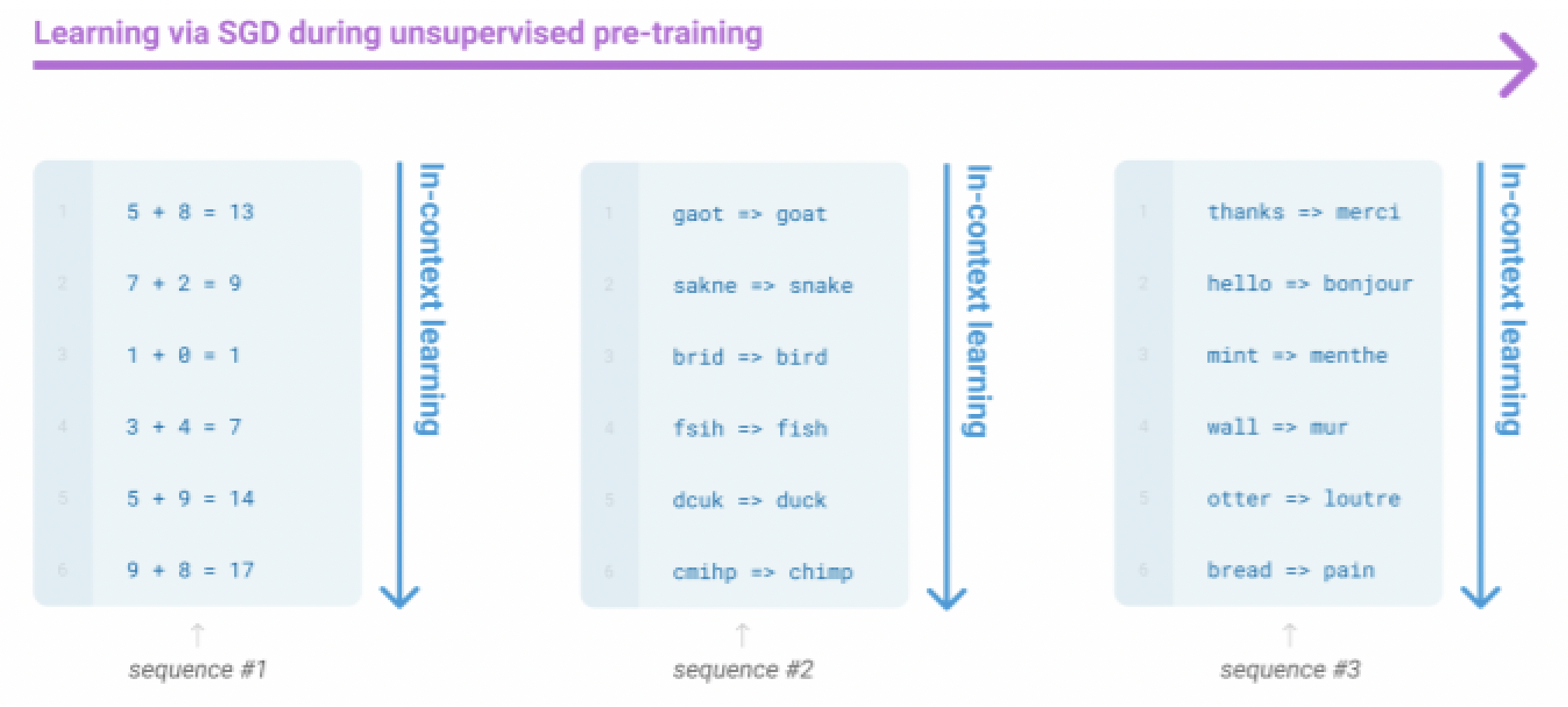
- 이러한
In-context learning은 아직 잘 이해되지 않고 있으며, 이것의 한계에 대한 많은 연구가 이루어지고 있다. - 단지 pretraining을 하는 것을 배우고, evaluating할 때는 모델을 finetune하지 않고 접두사만 제공한다.
Reference
- CS224n: Natural Language Processing with Deep Learning Lecture at Stanford University
