
Paper : Neural 3D Video Synthesis from Multi-view Video
Abstract
제안
- 고품질 뷰 합성과 모션 보간을 가능하게 하는 작지만 표현적인 표현으로 동적인 실제 장면의 멀티뷰 비디오 기록을 표현할 수 있는 3D 비디오 합성을 위한 새로운 접근법을 제안
- static neural radiance field의 고품질과 compactness를 모델이 없는 동적 설정으로 가져감
- compact latent code 세트를 사용하여 scene dynamic을 나타내는 time-conditioned neural radiance field
결과
- ray importance sampling과 결합하여 새로운 계층적 훈련 체계에 의해 생성된 이미지의 훈련 속도와 지각 품질을 크게 향상
- learned representation은 매우 compact하며, 모델 크기가 28MB에 불과한 18대의 카메라에 의한 10초 30 FPS 멀티뷰 비디오 녹화를 표현 가능
- 복잡하고 동적인 장면에서도 1K 이상의 해상도로 high-fidelity wide-angle novel view를 렌더링할 수 있음
1. Introduction
- 동적 실세계 장면의 현실적인 사진 표현과 렌더링은 매우 어려운 연구 주제이지만 영화 제작에서 가상 및 증강 현실에 이르는 많은 중요한 응용 분야이다.
- 동적 실세계 장면은 여러 물체와 사람의 복잡한 장면 움직임으로 인해 시간이 지남에 따라 지속적으로 진화하는 얇은 구조, 반투명한 물체, 거울 표면 및 토폴로지를 포함하기 때문에 고전적인 메시 기반 표현을 사용하여 모델링하기 어렵다.
- 이론적으로 6D plenoptic function 는 시각적 현실을 잘 설명하며 매 순간 모든 가능한 뷰를 렌더링할 수 있기 때문에 이 문제에 적합한 표현이다.
- 은 3D 공간의 카메라 위치, 는 보는 방향, 는 시간
- plenoptic function를 완전히 측정하려면 가능한 모든 시간에 공간의 모든 위치에 전방위 카메라를 배치해야 한다.
- Neural radiance fields(NeRF)는 이러한 문제를 피할 수 있는 방법을 제공한다.
- plenoptic function을 직접 인코딩하는 대신, 이를 근사화하기 위해 ray casting을 통해 샘플링할 수 있는 implicit, coordinate-based function로 장면의 radiance field를 인코딩한다.
- NeRF를 훈련하고 렌더링하는 데 필요한 ray casting에는 각 ray에 대한 수백 개의 MLP 평가가 포함된다. → 이는 정적 장면의 스냅샷에는 허용될 수 있지만, 동적 장면을 프레임당 NeRF의 시퀀스로 직접 재구성하는 것은 저장 및 훈련 시간이 시간에 따라 선형적으로 증가하기 때문에 한계가 있다.
예를 들어, 18대의 카메라에 의한 10초, 30 FPS 다중 뷰 비디오 녹화를 표현하기 위해 프레임당 NeRF는 훈련에 약 15,000 GPU 시간과 저장에 약 1GB가 필요하다.
- 더 중요한 것은 이렇게 얻은 표현은 이산 스냅샷 세트로만 세계를 재생할 수 있으며, 그 사이에 세계를 재생할 수 있는 수단이 없다는 것이다.
- 반면, Neural Volume은 동적 객체를 처리할 수 있고 심지어 상호작용 프레임 속도로 렌더링할 수 있다. → 그 한계는 내재된 메모리 복잡성으로 인해 재구성된 장면의 해상도/크기를 제한하는 조밀한 균일한 복셀 그리드다.
- 본 논문은 복잡하고 동적인 실제 장면의 3D 비디오 합성을 위한 새로운 접근법을 제안한다.
-
이는 compact하면서 고품질 view synthesis 및 motion interpolation을 가능하게 한다.
-
비디오는 일반적으로 안정적인 조명 하에서 시간 불변 성분과 지속적으로 변화하는 시간 불변 성분으로 구성된다.
-
비디오의 동적 성분은 프레임 간에 locally 상관된 기하학적 변형 및 외관 변화를 나타낸다.
→ 두 가지 새로운 기여에 기초하여 dynamic neural radiance field의 재구성 제안
-
- 첫째, neural radiance field를 시공간 영역으로 확장한다.
- 시간을 직접 입력으로 사용하는 대신, 콤팩트 잠재 코드 세트에 의해 장면 모션 및 외관 변화를 매개 변수화한다.
- 추가 'time coordinate'를 더 명확하게 선택하는 것에 비해 학습된 잠재 코드는 더 표현력이 뛰어나 이동 기하학과 질감의 생생한 세부 사항을 기록할 수 있다.
- 느린 모션이나 '총알 시간'과 같은 시각적 효과를 가능하게 하는 시간적으로 원활한 보간을 가능하게 한다.
- 둘째, dynamic radiance field에 대한 novel importance sampling 전략을 제안한다.
- 신경 장면 표현의 광선 기반 훈련은 각 픽셀을 독립적인 훈련 샘플로 취급하고 모든 뷰에서 관찰되는 모든 픽셀을 통과하려면 수천 번의 반복이 필요하다. 그러나 캡처된 동적 비디오는 종종 프레임 간에 작은 양의 픽셀 변화를 보여준다.
- 이는 훈련에 가장 중요한 픽셀을 선택함으로써 훈련 진행을 크게 향상시킬 수 있는 기회를 엽니다. 특히 시간 차원에서 우리는 프레임에서 거칠게 미세하게 계층적 샘플링으로 훈련을 예약한다. 광선/픽셀 차원에서 우리의 설계는 다른 것보다 더 시간 가변적인 픽셀을 샘플링하는 경향이 있다.
- 이러한 전략은 우리가 고품질 재구성 결과를 유지하면서 긴 시퀀스의 훈련 시간을 크게 단축할 수 있도록 합니다. 우리는 18개의 GoPro 카메라를 기반으로 하는 다중 뷰 리그를 사용하여 접근 방식을 시연한다. 우리는 매우 복잡한 뷰 의존적이고 시간 의존적인 효과를 가진 여러 도전적인 동적 환경에 대한 결과를 보여준다. 프레임당 NeRF 기준과 비교하여 우리는 시간적 및 공간적 중요성을 결합한 샘플링으로 30개의 FPS 3D 비디오의 10초 동안 크기가 40배 작은 모델로 훈련 속도에서 한 단계의 크기 가속을 달성한다는 것을 보여줍니다.
- 본 논문의 기여
- 복잡하고 역동적인 실제 장면의 고품질 3D 비디오 합성을 달성하는 시간 잠재 코드를 기반으로 한 새로운 동적 NeRF 제안
- 시공간 영역에서 계층적 훈련 및 중요도 샘플링을 기반으로 한 새로운 훈련 전략을 제시하여 훈련 속도를 크게 향상시키고 더 긴 시퀀스에 대해 더 높은 품질의 결과를 도출
- 연구 목적으로 어려운 4D 장면을 다루는 시간 동기화되고 보정된 멀티뷰 비디오 데이터 세트를 제공
2. Related Work
- 본 연구는 정적 장면에 대한 새로운 뷰 합성, 동적 장면에 대한 3D 비디오 합성, 이미지 기반 렌더링 및 신경 렌더링 접근법과 같은 여러 연구 영역과 관련이 있다.
Novel View Synthesis for Static Scenes
- 장면의 텍스처링된 3D 모델을 explicit하게 재구성하고 임의의 뷰 시점에서 렌더링함으로써 해결한다.
- Multi-view stereo
- visual hull reconstructions
- 복잡한 view-dependent 효과는 light transport acquisition 방법에 의해 캡처될 수 있다.
- 학습 기반 방법은 필요한 뷰의 수를 완화하고 추론 속도를 가속화하기 위해 제안되었다.
- geometry reconstruction
- appearance capture
- combined reconstruction technique
- 새로운 뷰 합성은 입력 영상 픽셀을 재사용함으로써 달성될 수도 있다. 이 접근법을 사용한 초기 작업은 뷰 시점을 보간한다.
- Light Field/Lumigraph 방법은 입력 영상 광선을 재샘플링하여 새로운 뷰를 생성한다. 한 가지 단점은 복잡한 장면의 고품질 렌더링을 위해 밀도 높은 샘플링이 필요하다는 것이다.
- 최근에는 신경망을 사용하여 참조 뷰에서 픽셀을 퓨즈 및 리샘플링하는 방법을 학습한다.
- Neural Radiance Fields (NeRFs)는 MLP 기반 radiance 및 opacity field를 학습하고 새로운 뷰 합성을 위한 최첨단 품질을 달성한다.
- hole filling을 위해 screen space neural network와 결합된 explicit point-based scene representation을 채용한다.
- differentiable sphere-based representation으로 장면 외관을 인코딩한다.
- 뷰 합성을 위해 screen space network와 결합하여 feature의 dense voxel grid를 채용한다.
→ 기존 방법은 정적 장면에 대한 뷰를 보간하는 데 탁월하지만 동적으로 확장하는 방법은 불분명
3D Video Synthesis for Dynamic Scenes
- 비디오 합성을 위해 기하학 및 텍스처를 명시적으로 캡처할 수 있는 가능성을 보인다.
- 상호작용 속도로 압축 및 재생할 수 있는 시간 계층 표현을 제안한다.
- 재구성 및 애니메이션은 특히 인간에 대해 잘 연구되지만 일반적으로 모델 기반으로 수행되거나 고급 캡처 설정에서만 작동한다.
- tracking 및 completion하여 시간적으로 일관된 표면을 캡처한다.
- 고급 하드웨어로 스트리밍 가능한 3D 비디오를 캡처하고 압축하기 위한 시스템을 제안한다.
- 최근의 학습 기반 방법은 sparse camera view에서 인간 성능을 위한 volumetric 비디오 캡처를 달성한다.
- 보다 일반적인 장면에 초점을 맞추어 이들을 정적이고 동적인 구성 요소로 분해하고, 추정된 대략적인 깊이를 기반으로 정보를 재투영하며, 화면 공간에 U-Net을 사용하여 중간 결과를 실제 이미지로 변환한다.
- 시공간 및 조명 보간을 위해 신경망을 사용한다.
- 추정된 깊이 맵을 새로운 뷰에서 렌더링할 수 있는 통합 표현에 병합하기 위해 모델 기반 단계를 사용한다.
- 신경 장면 흐름 필드는 정적 배경 모델을 통합한다.
- 공간 시간 신경 방사선 필드는 시공간 방사선 필드를 감독하기 위해 비디오 깊이 추정을 채택한니다.
- 최근 자체 예측된 흐름 벡터에 의해 감독되는 시간 조건부 방사선 필드를 제안합니다. 이러한 작업은 단일 뷰 설정으로 인해 뷰 각도가 제한되며 깊이 또는 흐름과 같은 추가적인 감독을 필요로 합니다.
- 표준 방사선 필드를 변형하기 위해 워프 필드 또는 속도 필드로 동적 장면을 명시적으로 모델링합니다.
- STaR은 엄격하게 변환되는 여러 표준 방사선 필드를 사용하여 경직적으로 움직이는 객체의 장면을 모델화할 수 없습니다. 이러한 방법은 토폴로지 변화와 같은 도전적인 동적 이벤트를 모델링할 수 없습니다. 디지털 인간을 모델링하기 위해 여러 래디언스 필드 접근법이 제안되었지만 일반적인 비강성 장면에는 직접 적용할 수 없습니다.
- 현장 장면에 대한 신경 래디언스 필드를 개선하고 장면 간에 일반화하는 노력이 있었다.
- HyperNeRF는 동적 새로운 뷰 합성에 대한 동시 작업이지만 짧은 시퀀스의 단안 비디오에 초점을 맞추고 있습니다.
- Neural volumes은 단일 객체의 동적 시퀀스를 매개 변수화하기 위해 뷰 조건 디코더 네트워크와 결합하여 볼륨 렌더링을 채택한다. 그 결과는 고유한 O(n 3) 메모리 복잡성으로 인해 해상도와 장면 복잡성에 제한이 있다.
- 수백 Mb/s의 속도로 스트리밍될 수 있는 독립적인 알파 텍스쳐 메시를 기반으로 VR 애플리케이션에 6DoF 비디오를 활성화한다. 이 접근법은 46대의 카메라로 캡처 설정을 채택하고 강력한 장면 사전 구성을 위해 대규모 훈련 데이터 세트를 필요로 합니다.
→ 본 연구는 10초의 전체 다중 뷰 비디오 시퀀스를 28MB로 표현할 수 있으면서 연속적인 시점과 시간 보간을 가능하게 하는 통합 시공간 표현을 추구한다.
3. DyNeRF: Dynamic Neural Radiance Fields
- known intrinsic 및 extrinsic parameter를 사용하여 시간 동기화된 다중 뷰 비디오에서 동적 3D 장면을 재구성하는 문제 해결
- 다중 카메라 녹화로부터 재구성하는 표현은 임의의 시점에서 광범위한 관점에서 사실적인 이미지를 렌더링할 수 있어야 함
- 여러 카메라로 캡처한 입력 비디오에서 최적화된 dynamic neural radiance fields(DyNeRF) 제안
- DyNeRF는 훈련 중에 공동으로 최적화된 일련의 temporal latent embedding에 의해 제어할 수 있는 novel continuous space-time neural radiance field representation
- 시공간 모두에서 연속적으로 쿼리할 수 있는 소형 6D representation으로 여러 카메라에서의 입력 비디오를 압축
- learned embedding은 explicit geometric tracking 없이 복잡한 광도 및 위상 변화와 같은 장면의 세부 시간적 변동을 충실히 캡처
3.1. Representation
- 3D 비디오를 표현하는 문제는 x,d,t를 c,에 매핑하는 6D plenoptic function를 학습하는 것
-
3D position , direction , time → RGB radiance , opacity 에 매핑
-
정적 장면의 5D plenoptic function를 근사화하는 NeRF에 기초하여, 잠재적인 해결책은 함수에 time dependency을 추가하는 것
- trainable weight $\Theta$을 MLP로 실현 - 1차원 시간 변수 $t$에 positional encoding 적용→ 이 설계가 화염과 같은 어려운 위상 변화와 시간에 의존하는 체적 효과로 복잡한 동적 3D 장면을 포착하기 어렵다는 것 발견
-
Dynamic Neural Radiance Fields
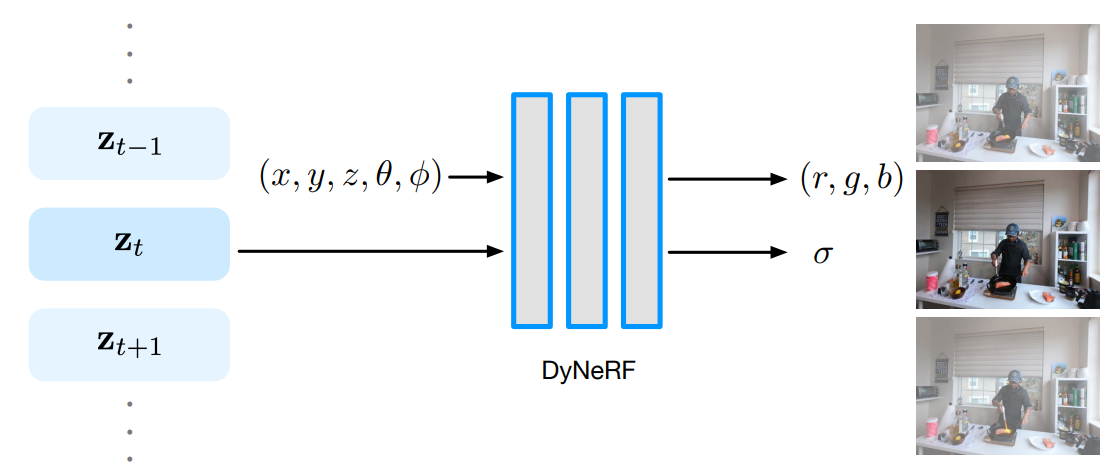
Figure 2. position, view direction 및 compact하지만 표현적인 time-variant latent code를 조건으로 하는 새로운 dynamic neural radiance field(DyNeRF)에 의해 6D 플렌옵틱 기능을 학습한다.
- 동적 장면을 time-variant latent code 로 모델링
- discrete time variable 에 의해 인덱싱된 discrete time variable 세트를 학습 :
- latent code는 변형, 위상 및 radiance 변화를 포함한 복잡한 장면을 처리할 수 있는 특정 시간의 동적 장면 상태를 압축적으로 표현
- time-dependent latent code에는 positional encoding이 적용되지 않음
- training 전, latent code 는 모든 프레임에 걸쳐 독립적으로 초기화
Rendering
- 시공간의 쿼리 뷰가 주어진 radiance field를 렌더링하기 위해 volume rendering 기술 사용
-
ray 가 주어질 때, 이 ray의 렌더링된 색상 은 누적된 불투명도에 의해 가중치가 부여된 radiance 위에 적분 :
-
& : bounds of the volume depth range
-
: accumulated opacity
-
Loss Function
- 렌더링된 색상 과 ground truth color 사이의 loss를 최소화하여 network parameters 와 latent code 를 동시에 학습하고, 모든 training camera view 및 all time frame 에서 이미지 픽셀에 해당하는 모든 ray 에 대해 합산 :
- NeRF와 유사하게 c와 로 표시된 coarse와 fine leve 모두에서 loss 평가
3.2. Efficient Training
-
비디오 데이터에 대한 ray casting–based neural rendering은 필요한 training 시간이 큼
- epoch 당 training 반복 횟수는 입력 멀티뷰 비디오의 전체 픽셀 수에 따라 선형으로 확산
18대의 카메라에서 10초, 30 FPS, 1MP 멀티뷰 비디오 시퀀스의 경우 한 epoch에 약 74억 개의 ray 샘플이 있으며, 이는 8개의 NVIDIA Volta class GPU를 사용하여 처리하는 데 약 반 주가 걸림
- 고품질 결과를 얻기 위해 각 광선을 여러 번 다시 방문해야 한다는 점을 감안할 때, 이 샘플링 프로세스는 대규모로 3D 비디오를 교육하는 ray-based neural reconstruction 방법의 가장 큰 병목 현상 중 하나
- epoch 당 training 반복 횟수는 입력 멀티뷰 비디오의 전체 픽셀 수에 따라 선형으로 확산
-
자연 영상은 대부분의 동적 장면이 1) time-invariant 하거나 2) 관찰된 비디오 전체에 걸쳐 특정 타임스탬프에서 작은 time-variant radiance 변화만 포함
→ 따라서 균일한 sampling ray은 time-invariant 관측과 time-variant 관측 사이의 불균형 초래
- 이는 매우 비효율적이며 재구성 품질에 영향을 미친다는 것을 의미
time-invariant 영역은 더 빨리 높은 재구성 품질에 도달하고 쓸데없이 오버샘플링되는 반면, time-variant은 추가 샘플링이 필요하여 훈련 시간이 늘어남
- 이는 매우 비효율적이며 재구성 품질에 영향을 미친다는 것을 의미
-
3D 비디오에서 시간적 중복을 탐구하기 위해 훈련 프로세스를 가속화하는 두 가지 전략 제안
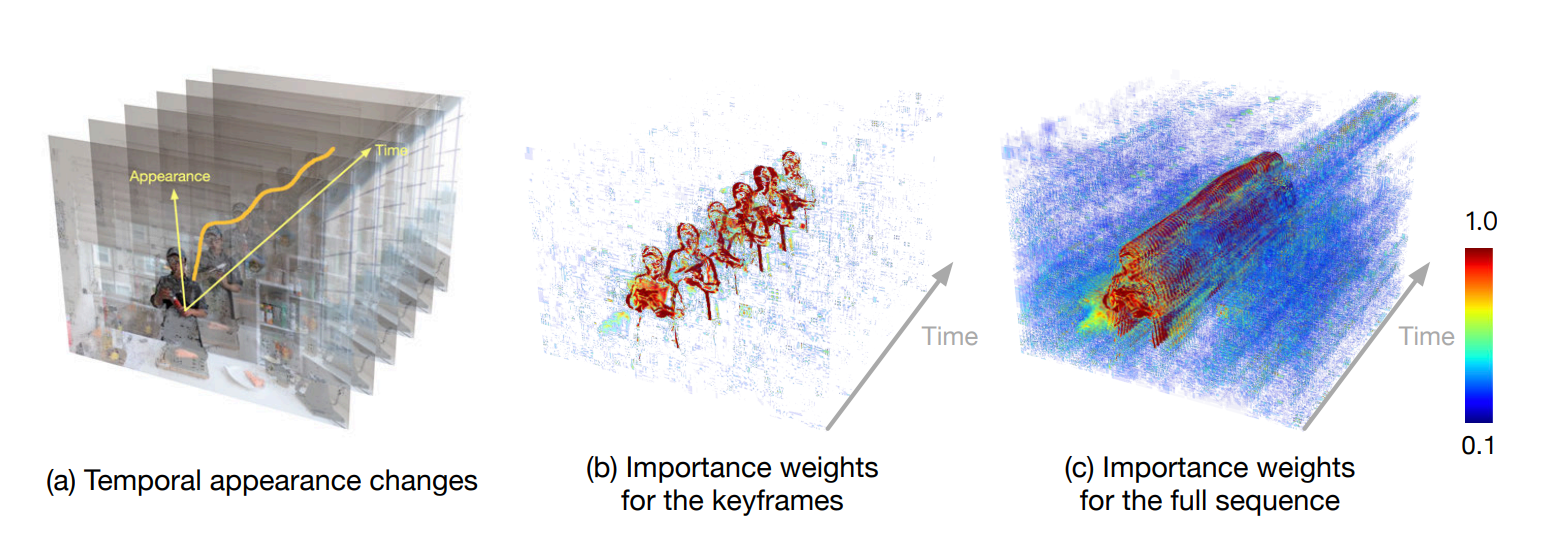
Figure 3. 효율적인 훈련 전략의 개요. 먼저 keyframe(b)을 사용하여 계층적 훈련을 수행한 다음, 전체 시퀀스(c)에 대해 수행한다. 두 단계 모두에서 ray importance sampling기술을 적용하여 시간적 외관 변화(a)를 측정하는 가중치 맵을 기반으로 시간 변동 정보가 높은 광선에 초점을 맞춘다. 히트맵(빨간색과 불투명은 높은 확률 의미)을 사용하여 전역 중앙값 맵을 기반으로 샘플링 확률의 시각화된 예를 보여준다.
- hierarchical training : coarse-to-fine frame 선택을 통해 데이터를 최적화
- importance sampling : 시간 변동이 큰 영역 주변의 ray를 선호
-
시간 프레임 세트 및 픽셀 세트 의 "중요한" ray에 더 많은 주의를 기울이기 위해 다른 loss function 형성 :
→ 이 두 전략의 결합은 adaptive sampling 접근 방식으로, 빠른 교육과 렌더링 품질 향상에 기여
Hierarchical Training
- 고정 시간 간격 , 즉 로 모든 이미지를 등간격으로 샘플링하는 keyframe에서 training
-
모델이 keyframe supervision에 수렴되면 이를 사용하여 전체 비디오와 동일한 시간 해상도를 갖는 최종 모델 초기화
-
각 segment(주변 keyframe으로 나눔) 내에서 장면의 프레임별 움직임이 매끄러우므로, coarse embedding 사이를 선형으로 보간하여 fine-level latent embedding을 초기화
-
모든 프레임의 데이터 를 사용하여 네트워크 가중치와 latent embedding을 더욱 최적화하도록 training
→ coarse keyframe 모델은 이미 비디오 전체에서 time-invariant 정보의 근사치를 캡처
→ 따라서 fine full-frame training은 프레임별 time-variant 정보만 학습하면 됨
-
Ray Importance Sampling
- 입력 비디오의 시간적 변화에 기초하여 서로 다른 중요도의 시간에 걸친 ray 의 샘플링 제안
- 시간 에서 관찰된 각 ray 에 대해 가중치 계산
- 각 training iteration에서 임의로 시간 프레임 선택
- 프레임 에 대한 모든 입력 뷰에 걸쳐 ray의 가중치를 정규화한 다음, inverse transform sampling을 적용하여 이러한 가중치를 기반으로 ray 선택
- 각 ray의 가중치를 계산하기 위해 서로 다른 통찰력을 기반으로 세 가지 구현을 제안
- Global-Median(DyNeRF-ISG) : 시간에 따른 전역 중앙값에 대한 색상의 잔차 차이를 기반으로 각 ray의 가중치를 계산
- Temporal-Difference(DyNeRF-IST) : 연속적인 두 프레임의 색상 차이를 기반으로 각 ray의 가중치를 계산
- Combined Method(DyNeRF-IS⋆) : 위의 두 전략을 모두 결합
- DyNeRF-IS*(후절에서는 DyNeRF라고 함)에서 두 방법의 이점을 결합 → 먼저 DyNeRF-ISG를 통해 선명한 세부 사항을 얻은 다음, DyNeRF-IST를 통해 시간적 움직임을 부드럽게 함
- 높은 learning rate로 DyNeRF-ISG를 훈련하면 동적 세부 사항을 매우 빠르게 복구할 수 있지만, 시간이 지남에 따라 약간의 jitter가 발생한다는 것을 관찰
- 낮은 learning rate로 DyNeRF-IST를 훈련하면 다소 흐릿한 시간 시퀀스가 생성
- 모든 importance sampling 방법은 정적 카메라 장치를 가정
4. Experiments
Implementation Details
- PyTorch에서 접근 방식을 구현
- 처음 8개의 MLP 레이어에 대해 256개 대신 512개의 activation를 사용한다는 점을 제외하면 NeRF에서와 동일한 MLP 아키텍처를 사용
- latent code : 1024차원
- 계층적 훈련에서 우리는 먼저 K = 30 프레임 떨어져 있는 키프레임에서만 훈련합니다.
- 매개변수 β1 = 0.9 및 β2 = 0.999로 Adam 최적화 프로그램[25]을 사용합니다.
- 키프레임 학습 단계에서 학습률을 5e-4로 설정하고 300K 반복 학습합니다. 중요한 샘플링 방식에 대한 세부 정보는 Supp에 포함되어 있습니다. 매트. 잠재 코드 학습률을 다른 네트워크 매개변수보다 10배 높게 설정했습니다. 프레임당 잠재 코드는 N(0, 0 √.01 D )에서 초기화됩니다. 여기서 D = 1024입니다. 총 훈련에는 8개의 NVIDIA V100 GPU와 총 배치 크기 24576개의 광선으로 약 일주일이 걸립니다.
Limitations
-
크고 빠른 모션이 있는 매우 역동적인 장면은 모델링하고 학습하기 어려우며, 이는 움직이는 영역에서 흐릿함을 초래할 수 있다.

그림과 같이, 숲 구조가 뒤에 있는 야외에서 빠른 모션을 다루는 것과 같은 복잡한 환경에서 특히 어렵다는 것을 관찰한다. 시퀀스의 어려운 부분 동안 더 많은 키프레임을 배치하는 계층적 훈련 동안의 적응적 샘플링 전략 또는 더 명확한 모션 모델링은 결과를 더욱 개선하는 데 도움이 될 수 있다.
-
기본 접근 방식에 비해 훈련 속도 측면에서 이미 상당한 개선을 달성했지만, 훈련은 여전히 많은 시간과 리소스를 계산한다. 훈련 시간을 더 줄이고 테스트 시간에 렌더링 속도를 높일 수 있는 방법을 찾는 것이 필요하다.
-
training view의 경계를 넘는 Viewpoint extrapolation은 도전적이며 렌더링된 이미지의 아티팩트로 이어질 수 있다.
