[Paper Review] Mobile, Egocentric Human Body Motion Reconstruction Using Only Eyeglasses-mounted Cameras and a Few Body-worn Inertial Sensors Paper Review
Human Pose Estimation

Abstract
- 사용자들이 시공간 구애 없이 이용할 수 있는 편리한 telepresence(원격 현장) 시스템을 구상
- 머리에 착용하는 장치에 내장된 카메라와 손목과 발목에 착용하는 IMU(관성 측정 장치)를 통해 사람의 동적 3D 캡처를 위한 독립형 실시간 시스템 제시
- 본 논문의 프로토타입 시스템은 학습 기반 포즈 추정을 통해 착용자의 동작을 자기 중심적으로 재구성
- 시각(visual) 및 관성(inertial) 센서의 입력을 융합 → 1) head-worn views의 일관성 없는 팔다리의 가시성 2) 희소 IMU의 모호성과 같은 문제를 극복
- 추정된 포즈는 prescanned surface model로 지속적으로 리타겟팅되어 high-fidelity(충실도)가 높은 3D reconstruction을 초래
- 다양한 인체 움직임을 재구성하여 시스템을 시연하고 실시간으로 실행되는 visual-inertial 학습 기반 방법이 시각 전용 및 관성 전용 접근 방식 능가
- https://sites.google.com/site/youngwooncha/egovip
Introduction
-
telepresence는 떨어져 있는 공간에서도 원격 사회적 상호 작용을 가능하게 함
-
지금까지의 문제
- eyeglass-frame form의 문제 : 팔다리의 가시성 떨어짐
- 프레임별 시각적 3D 포즈 추정 방법 : 가려진 관절에서는 신뢰할 수 없는 추정치
- 외부 카메라 캡처 방법 : 실시간으로 높은 정확도와 성능을 달성하지만, 모든 관절이 보여야 함
- Joint heatmap 추정 방법 : 2D heatmap 내에서 레이블을 지정할 수 없기 때문에 영상 외부에 있는 joint를 처리할 수 없음 → 경계를 패딩하여 히트맵 크기를 확장하면 와이드 FoV 또는 어안 렌즈의 왜곡이 크기 때문에 높은 3D 조인트 오류가 발생할 가능성
-
시각-관성 융합 접근법은 10개 이상의 신체 착용 센서가 필요
-
eyeglass-frame mounted 카메라 & 손목과 발목의 IMU에 의존하는 wearable 3D acquisition system 제안
- visibility-aware visual 3D pose network : 가려진 관절을 억제하면서 보이는 관절 추정
- online IMU offset calibration method : 부착된 IMU가 있는 팔뚝과 다리 아래에 대해 시간이 지남에 따라 시각적 및 관성 뼈 방향을 정렬하여 관성 측정을 향상
- visual-inertial 3D pose network : IMU가 없는 위쪽 팔과 허벅지의 포즈는 이전 프레임에서의 위쪽 뼈의 시각적 감지뿐만 아니라 상응하는 아래쪽 뼈의 관성 측정을 사용하여 추정
Contribution
- 희소 가시성과 희소 관성 센서를 모두 처리할 수 있는 최초의 자기 중심적 3D 인간 자세 추정 접근법
- 모바일 캡처 및 실시간 신체 움직임 추정을 위한 안경 폼 팩터의 작동 중인 독립적인 개념 증명 프로토타입
- 관성 측정뿐만 아니라 공동 가시성 정보가 있는 여러 뷰를 포함하는 최초의 자기 중심적 인간 모션 데이터 세트
RELATED WORK
Body Reconstruction
- Deformable body model-based surface 추정은 컴퓨터 비전에 초점 : SMPL: A Skinned Multi-Person Linear Model
- 모델 매개변수의 추정은 시각적 자세 추정과 함께 인간 표면을 근사화 : 2d human pose estimation: New benchmark and state of the art analysis
- 신체 모델과 이미지 사이의 밀도 높은 대응 추정(DensePose: Dense Human Pose Estimation In The Wild)
- 직접적인 volumetric 추론(Bodynet: Volumetric inference of 3d human body shapes)
- 최근 연구는 real-time 성능의 향상
- High-fidelity geometry의 추정
- fitting image silhouette(Livecap: Real-time human performance capture from monocular video)
- cloth simulation(Simulcap: Single-view human performance capture with cloth simulation)
- 해당 방식은 외부 카메라가 전신을 담을 수 있어야 하지만, egocentric view에서 신체 부위가 가려질 때가 있음
Visual Pose Estimation
- CNN을 사용하여 2D joint heatmap 기반 추정
- CNN 기반 3D joint 추정은 단일 외부 뷰에 대해 실시간으로 상당한 정확도 달성
- Human pose constraint와 occlusion information가 훈련 중에 통합
- 시간이 따른 연속적인 인간 움직임의 경우, RNN 기반 포즈 추정이 일련의 움직임 예측에 대해 유망한 결과
- 해당 방식은 관절 위치를 추정하지만, 전신 자세를 추정하기 위해 시각적 정보만 사용할 때 3D 뼈 방향 추정은 여전히 미해결 문제
Visual Egocentric Pose Estimation
- 몸에 착용한 카메라에 찍힌 자기 중심적 데이터로 고품질 재구성 미해결 → 계측되지 않은 임의의 환경에서 작동하는 재구성 방법 필요
- 외부 카메라 기반 인간 포즈 추정 방법은 신체의 자기 중심적 관점에 직접 적용할 수 없음
- 신체 움직임은 몸에 착용한 카메라에서 추론
- structure-from-motion(Motion Capture from Body-Mounted Cameras)
- learning-based approaches(Seeing invisible poses: Estimating 3d body pose from egocentric video, Cyclops: Wearable and Single-Piece Full-Body Gesture Input Devices)
- 신체를 직접 관찰하지 않으면 포즈 추정 정확도 제한 → 착용자의 신체 대부분을 볼 수 있는 머리 착용 하향 wide-FoV 카메라로 개선
- 최근 단일 머리 착용 카메라 뷰 기반 방법은 자세 추정 개선을 위해 less-obtrusively 장착된 카메라를 사용 → But, 광범위하게 수용하기에는 너무 눈에 띔
- 몸에 착용한 카메라로 아래쪽 몸에 가까운 시야를 사용하는 접근법은 self-occlusion 및 시야 밖 joint의 문제 미해결
Inertial Pose Estimation
- 인체 자세 추정은 신체 착용 관성 측정 장치(IMU)를 사용하여 수행
- IMU는 빠른 움직임을 포착 및 카메라 뷰에 가려지는 신체 부위를 추적 → But, 시간이 지남에 따라 측정 노이즈와 drift로 인해 어려움을 겪어 초기 자세에 대한 세심한 보정이 필요
- 센서 착용 수용성을 높이기 위해, 연속적인 방향과 가속을 사용하여 IMU의 수를 줄임
- IMU는 손목과 발목에만 착용하며, 사라진 위쪽 팔과 허벅지 방향은 아래쪽 뼈와 위쪽 뼈의 동작이 높은 상관 관계가 있다고 가정함으로써 추정
- 유사한 측정으로 여러 포즈가 가능할 수 있기 때문에 포즈 모호성 → 미래 프레임 또는 전체 시퀀스와 같은 더 많은 시간적 측정을 사용하여 부분적으로 해결
- 이 문제를 극복하기 위해 시각 및 관성 센서 융합은 IMU와 공동으로 외부 지향 카메라를 활용하여 3D 신체 자세를 계산
- 외부 지향 카메라의 시각적 자세 추정치는 관성 센서의 가능한 3D 포즈를 제한하고 IMU 측정 노이즈를 완화하는 데 도움 → 지금까지 완전한 신체 가시성을 요구, 이는 자기 중심적 관점에서는 거의 달성할 수 없음
WEARABLE CAPTURE AND EGOCENTRIC DATASET
Eyeglasses and IMUs Prototype
목표 : 안경, 손목 밴드 및 신발과 같이 일반적으로 착용하는 품목에 센서가 내장된 완전 모바일 텔레프레즌스 시스템을 개발하는 것
프로토타입 : 안경테 카메라 & 4개 IMU(손목과 발목의 Xsens MTw Awinda)과 밉 러닝 기반 기술
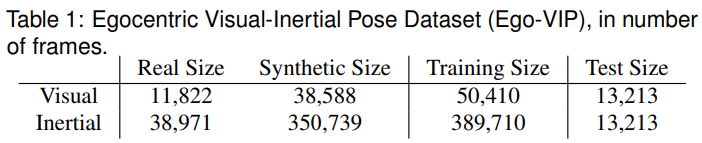
Egocentric Visual+Inertial Human Pose Dataset
-
프로토타입 헤드셋과 8개의 IMU를 착용한 사용자로 새로운 인간 포즈 데이터 세트를 수집
-
실제 전신 3D 관절은 캡처 스튜디오에서 여러 개의 벽 장착형 카메라를 사용하여 획득
-
training : 22 sequences, evaluation : 9 sequences
-
6 human subjects, for a total of 38k frames of visual+inertial data
- visual data
- real image : 11k개 실제 이미지를 균일하게 샘플링하고 전체 기록에서 수동으로 필터링
- synthetic image : 38k개의 합성 이미지는 의류 및 배경 질감, 헤드기어 변환 등 random augmentation을 통해 실제 데이터에서 신체 포즈를 사용하여 생성
- 각 joint visibility(label : visible, occluded, outside the FoV)는 자기 중심 이미지에 투영된 신체 모델의 z-buffer를 사용하여 추정
- 몸통 관절(목, 어깨, 엉덩이)은 뼈 자세 추정을 위한 뿌리 관절로서 필수적인 역할을 하기 때문에 occlusion에 관계없이 눈에 보이는 것으로 표시
- inertial data
- 8개 센서의 관성 데이터로 시각 데이터와 동기화 및 보정
- 38k 프레임의 실제 IMU 데이터를 정면에서 후면으로 포즈를 미러링, 측면에서 연속적으로 부드럽게 포즈 방향을 조정, 무작위 가속도 노이즈 도입을 통해 증강
- visual data
EGOCENTRIC RECONSTRUCTION METHOD
- 시각-관성 센서에서 사용할 수 있는 정보가 희소하여 전신 자세를 자체적으로 추정할 수 없음
- 팔다리 움직임은 신체에 의해 자주 가려지거나 카메라 시야밖에 있기 때문에 보이지 않음
- IMU는 팔뚝과 다리 아래쪽에만 착용하므로 팔 위쪽과 허벅지 방향이 없음
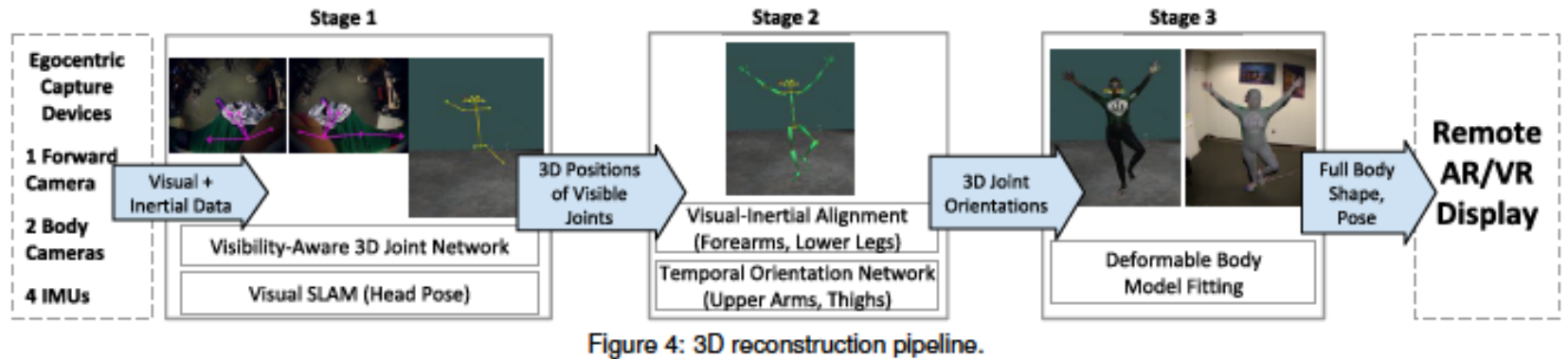
→ visibility-aware visual pose network and a temporally integrated visual and inertial pose network 제안
Stage1
visibility-aware 3D joint detector network는 두 개의 자기 중심적 하향 시야에서 관찰할 수 있는 joint의 3D 위치를 추정하며, 감지된 3D joint는 VSLAM을 통해 추정된 헤드셋 포즈를 사용하여 world space으로 변환
Stage2
하부 뼈(팔뚝, 아래쪽 다리)와 상부 뼈(위쪽 팔, 허벅지)의 3D 방향은 각각 visual-inertial IMU offset calibrator와 temporal visual-inertial orientation network를 사용하여 추정
Stage3
parametric body model의 모양과 포즈는 Stage2에서 추정된 전신 3D joint 위치와 방향을 사용하여 설정
VSLAM(Visual Simultaneous localization and mapping)
시각 기반의 동시적 위치추정 및 지도작성으로 주변 환경에 대하여 지도를 작성하면서 동시에 이 환경을 기준으로 카메라의 위치와 방향을 계산하는 과정
3D Body Representation
SMPL(skinned multi-person linear model) parametric body model
: 체형과 포즈를 나타내기 위한 모델
- 3D 개체는 vertex와 triangle로 표시되고 개체가 더 세부적일수록 더 많은 vertex 필요 → 인간의 3D 메시 표현은 축이 키, 뚱뚱함, 가슴 둘레, 배 크기, 포즈 등과 같은 저차원 공간으로 압축될 수 있음
- 두 가지 유형의 매개 변수로 인간 피험자를 인코딩
- Shape parameter : a shape vector of 10 scalar value, 더 크거나 더 작은 방향을 따라 인간 피험자가 팽창/축소되는 양으로 해석
- Pose parameters : a pose vector of 24x3 scalar value, 매개 변수에 대한 관절의 상대 회전을 유지하고 각 회전은 축-각 회전 표현에서 임의의 3D 벡터로 인코딩
- linear blend skinning을 통해 6480개의 vertice를 가진 triangular mesh 을 변형
linear blend skinning
어떤 3차원 물체를 컴퓨터 그래픽으로 형상화시킬 때에 사람의 뼈 구조(skeleton structure)로부터 Mesh를 만드는 작업
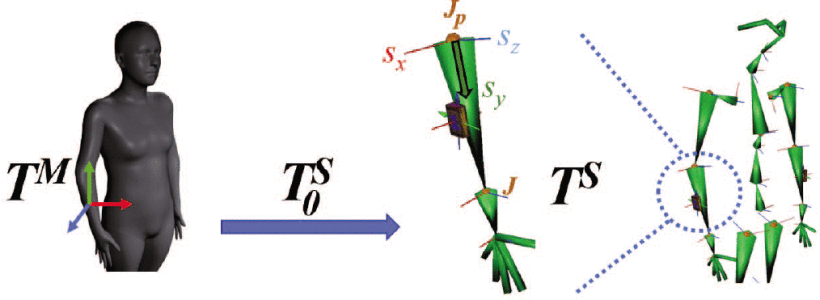
Bone representation
- 뼈 는 두 개의 연결된 joint와 transform에 의해 정의
- local bone rotation 집합 표현 대신, global transform 집합 으로 정의된 동등한 뼈 표현 사용
- Body Mesh space는 으로, Skeleton space는 로 표현
- global space의 skeletal bone transformation 을 pose in the skeleteon으로 표현
- : bone rotation
- : base joint position
- 의 열 벡터는 뼈의 3D 축을 형성
-
: base(parent)에서 tip(child) 까지 뼈 방향
-
회전으로부터 계산된 뼈의 방향
-
- pose parameter 는 으로 직접 계산
- 은 rest pose 시 identity matrix
- : bind pose matrix로 좌표 프레임 매핑
- 는 joint positions in the rest pose of the body model를 사용하여 계산되며, 가 변경될 때만 업데이트
- : rest pose의 joint 위치
- 는 shaped vertice에서 joint regressor 에 의해 설명
Estimate the body shape
- 을 최소화하여 unposed된 joint 를 사용하여 신체 형태 를 추정
- : weight for the regularization term
- : number of joint
- : mean shape → reshape vertices
- : linear blend shapes → reshape vertices
- : PCA 값을 최소화함으로써 각 주성분 간의 간극을 줄임
Visibility-Aware 3D Joint Detection Network
- 카메라로 얻은 joint visibility 정보를 통해 신뢰할 수 없는 joint를 거부하고 관찰 가능한 관절만 추정
- intput : egocentric images ()
- 머리에 착용하는 와이드 FoV 카메라 이미지에서 하체 관절은 상체 관절보다 상당히 작게 나타남
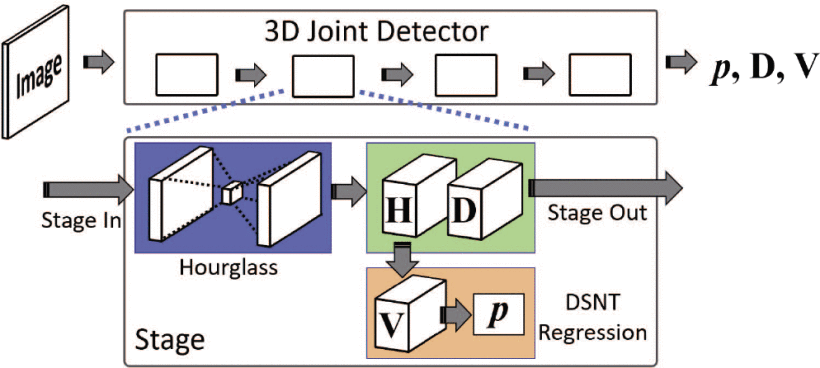
Network Structure for the 3D Joint Detector
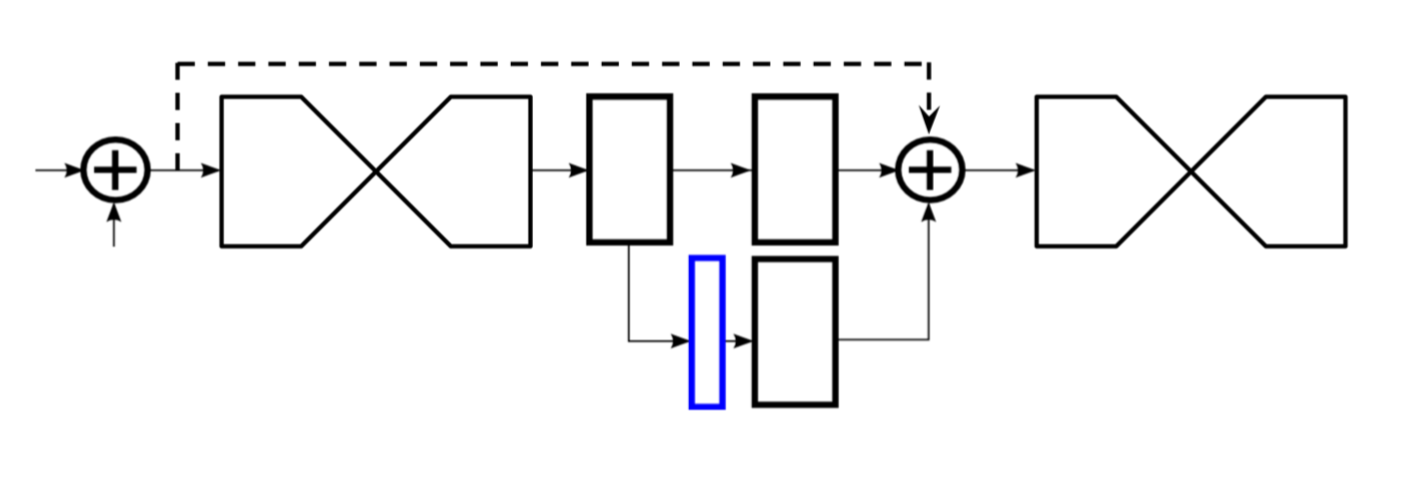
- 2D 인간 포즈 추정에 사용되는 Stacked Hourglass 아키텍처를 3D joint 추정 네트워크로 확장
stacked hourglass networks for human pose estimation
feature는 신체와 관련된 다양한 공간 관계를 가장 잘 포착하기 위해 모든 척도에 걸쳐 처리되고 통합된다. 해당 논문은 intermediate supervision과 함께 사용되는 반복적인 상향식 하향식 처리가 네트워크 성능 향상에 얼마나 중요한지 보여준다.
- DSNT 회귀 모듈을 사용하여 히트맵에서 2D 좌표를 추정 → 효율성 증가
DSNT : differentiable spatial to numerical transform
입력 이미지의 관심 지점에 대한 수치 좌표를 추론하는 딥 러닝 접근법 연구로, 기존 convolutional neural network-based 솔루션은 heatmap matching 접근 방식 or fully connected output layer 좌표 조정 회귀이다. DSNT 계층은 훈련 가능한 매개 변수를 추가하지 않고 완전히 미분할 수 있으며 좋은 공간 일반화를 나타낸다. 히트맵 매칭과 달리 DSNT는 낮은 히트맵 해상도에서 잘 작동하므로 기존의 광범위한 fully convolutional architecture의 출력 레이어로 사용할 수 있다. 결과적으로 DSNT는 기존 기술에 비해 추론 속도와 예측 정확도 사이의 더 나은 균형을 제공한다.
1. Hourglass 모듈은 첫 번째 채널의 heatmap 와 마지막 채널의 inverse depthmap 추론
- Heatmap
- Softmax 레이어에 의해 confidence map 로 정규화
- Inverse Depthmap
- joint에 대한 정규화된 inverse depth 값을 포함하는 heatmap
- 정규화된 inverse depth 값 :
- (meter)는 최대 깊이
- 카메라에 가까운 거리에는 더 높은 값, 더 먼 거리에는 near-zero 값 할당
2. 회귀 모듈은 에서 정규화된 confidence map 로부터 좌표 를 출력
- 는 X 및 Y 좌표 행렬의 내적에 의해 좌표 로 변환
- 신뢰 와 깊이 는 각각 와 로 추정된 좌표에서 읽힘
- 신뢰 가 충분히 클 때 좌표 가 유효하고 가시성 는 1로 설정, 그렇지 않으면 0으로 설정
3. 출력으로서 연결된 와 는 다음 스테이지의 입력으로 전파 = Intermediate Supervision
- raw inverse depth 판독치는 다시 깊이 (meter)로 변환
4. 단일 입력 이미지가 주어지면, 4단계 네트워크는 joint 좌표가 계산되는 ,를 출력
- joint 위치는 카메라 calibration matrix를 사용한 back-projecting으로 계산
Network Loss function
- ground truth binary visibility : visible joint는 1, invisible joint는 0
- : regression loss →
- : 2D Gaussian map drawn at μ with standard deviation σ(σ=1 for training)
- : 가 2D Gaussian map과 유사하게 하기 위한 Jensen-Shannon 발산
Jensen–Shannon divergence
두 확률 분포 사이의 유사성을 측정하는 방법
- : invisibility loss →
- 보이지 않는 joint에 대해 를 제로 히트맵으로 억제
- 에서 균일한 분포를 강화, 보이지 않는 관절에 대해 신뢰 값이 더 작아지도록 장려
- . : depth loss →
- : 2D binary maskmap drawn at μ with radius σ
- : 아다마르 곱 (Hadamard product)으로 같은 크기의 두 행렬의 각 성분을 곱하는 연산
- 깊이 맵은 관심 joint 영역만 훈련 → 마스크 맵을 사용하지 않을 때 깊이 맵 출력이 0이 되는 과적합을 방지하기 위해 외부 영역이 변경되지 않도록 함
The network is trained in multiple stages
- 레이어는 MPII Human Pose Dataset에서 low-level texture features를 학습하도록 훈련 → 회귀 손실 만 훈련에 사용되고 visibility는 무시
- 네트워크는 전체 손실 함수 로 intermediate supervision이 적용되어 훈련
- 오른쪽 카메라 이미지를 뒤집어 출력 joint 좌표를 뒤로 뒤집어, 왼쪽 카메라 이미지와 동일한 네트워크를 사용하기 위해 두 개의 하향 카메라 뷰 사이의 대칭 활용 → 두 뷰 모두에 대한 교육 및 런타임에서 단일 네트워크를 사용할 수 있게 함
Temporally, Multi-view Consistent Joint Estimation
- 3D joint는 좌우 하향 카메라 뷰에서 독립적으로 감지, camera clibration matrices를 사용하여 단일 3D 공간으로 재투영
- 잘못된 감지로 인해 상대 joint와 일치하지 않는 joint의 결과가 multi-view-consistent와 시간적으로 일관되도록 필터링됨
-
joint의 raw detection은 뼈 방향 가 시간적으로 일관성이 없는 경우 걸러지며, 이는 프레임 간에 30° 이상의 변화로 정의
-
필터링된 측정은 가중치 합계를 최소화하여 multi-view-consistent 및 시간적으로 일관된 joint 위치 를 추정하는데 사용
$$ E{proj}+w{d}E{dep}+w{l}E{len}+w{t}E_{temp} $$
- 가중치 설정
- : 목, 엉덩이 및 어깨를 포함한 몸통 joint
- : 팔 joint
- : 다리 joint
- Projection cost :
- : number of views
- : 2D location measurement in camera image c
- : camera c’s projection matrix
- Depth cost :
- : depth measurement in camera c
- : third row of the extrinsic matrix of camera c
- Bone length consistency :
- 골격 길이는 초기화부터 새로운 검출 측정을 통해 평균화까지 시간이 지남에 따라 유지
- 초기 골격 길이는 정지 자세 시 신체 모델에서 가져와 모델과 검출된 척추 길이 사이의 비율로 스케일링
- : parent joint’s position
- : bone length of joint
- Temporal smoothness cost :
- : joint position in the previous frame
-
- 헤드셋 공간 3D joint 위치 → VSLAM을 통해 획득한 현재 추정된 headset pose → 3D 세계 공간 joint 위치 로 변환
- 전체 프로세스는 직접적인 triangulation을 사용할 때보다 정확도 향상

Visual-Inertial Alignment
- 사람의 자세는 해당 뼈의 방향을 추적하는 신체 착용 관성 센서(IMU)로 추정
- IMU는 일반적으로 특정 초기 포즈를 사용하여 보정 → 약간 잘못 정렬된 신체 착용 IMU도 시각적 관성 일관된 포즈 추정을 방해하여 부정확한 결과를 초래
Coordinate frame transformations

(a) 사전 정의된 wear pose를 나타내는 스켈레톤 공간 에 대한 관성 센서 회전
(b) 잘못 정렬된 IMU를 보정하는 데 사용되는 IMU 회전 오프셋
- 시간에 따라 아래쪽 뼈 방향의 Visual-Inertial쌍을 사용하여 IMU 회전 오프셋 를 추정함으로써 부정확성 확인
Computing the lower bone
- 시간 단계 에 따른 뼈 회전 은 하부 뼈에 장착된 IMU를 통해 계산
- 가시성 관계 X
- : orientation read from the Inertial sensor at time
- : rotation from
- : 로 프레임 매핑
- Inertial lower bone direction
- : bone direction in the rest pose
Estimate IMU rotation offset
- IMU 회전 오프셋 은 동일한 뼈의 시각적 검출기에서 측정을 사용할 수 있을 때마다 업데이트
- prior bone direction = visual bone direction
- 센서가 정확히 지정된 위치와 방향으로 착용된 경우
- 은 최소 자승법를 해결하여 일련의 Visual 및 Inertial 방향으로부터 추정:
- 모든 쌍에 대해 위 식을 계산하는 것은 계산 집약적
- 온라인 k-d 트리 구조를 가진 Algorithm 1에 설명된 온라인 k-평균 알고리즘을 사용하여 visual-inertial 쌍을 그룹화하고 를 업데이트
- At runtime, k-d 트리에서 고정된 k=200개의 클러스터 쌍 유지
- 샘플링 전략은 군집 간 거리를 최대화 → 군집의 균일한 분포를 선호, 선형 표본의 수를 최소화
Temporal Visual-Inertial Orientation Network
- 상부 뼈 방향은 하부 뼈 움직임과 높은 상관 관계 → 상부 뼈 움직임은 여러 방향 가능 → 상부 뼈의 시각적 관찰을 사용
- 센서로 계측된 하부 뼈(i)와 계측되지 않은 상부 뼈(u) 구별
- 보정된 아래 뼈 방향 은 IMU offset matrix 으로 계산
Estimate upper bone
-
- : raw acceleration
- : 에서 계산된 위쪽 방향을 따라 회전하는 Heading reset을 나타내는 IMU acceleration offset matrix
-
이전 , 하부 뼈에 대한 , 시각적인 상부 뼈 방향 의 가용성 → 비계측 상부 뼈 를 추정
- 신체 방향에 불변하기 위해, , , 는 시간 에서 root joint(엉덩이 중심) 방향 에 대해 정규화:
- 과 비슷하게 정규화
- N : Normalized torso space
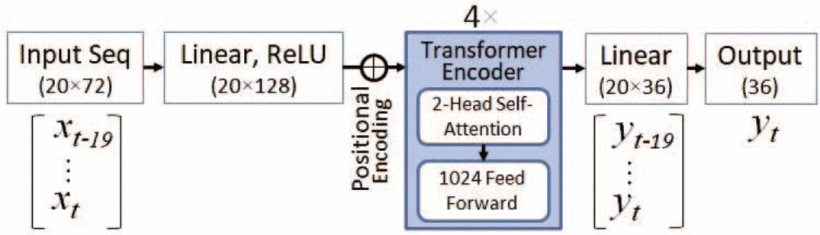
Temporal visual-inertial orientation network architecture
-
일련의 input features 에서 계측되지 않은 골격 방향을 예측하는 함수 을 학습하는 작업
- LSTM을 능가하는 Transformer network를 사용
- 입력 시퀀스는 마지막 프레임의 측정으로 구성
-
input feature vector
- input feature vector는 회전, 속도 및 가속도로 대표되는 하부 뼈 움직임을 통합
- : 벡터화된 으로, 4개의 입력 뼈에 대해 를 나타냄 → , 와 도 비슷하게 정의
- : 와 사이의 각속도
- 상부 뼈 의 joint가 시각적 검출기로 제공될 때, 방향이 추가되고 visibility 가 1로 설정
- 제공되지 않을 때, 과 을 사용하는 것이 모두 0으로 설정하는 것보다 성능이 더 우수
- 의 차원은 4개의 IMU 계측 뼈와 4개의 비 계측 뼈로
-
output vector
- 벡터화된 비계측 골격 방향 포함
- 가 출력 방향 로 reshape
- 의 차원은 4개의 위쪽 뼈에 대해 (9)
-
loss function
- orientation loss은 ground truth 를 사용하여 측정
- 는 계산된 출력 골격 방향을 나타냄
- ground truth 골격 방향에 의해 패널티가 발생하며, 이는 출력 골격 방향이 시각적 입력 골격 방향과 일치하도록 장려
- 이 항은 인 경우에만 계산
- At run-time, 정규화된 몸통 공간의 추정 는 식 (11)을 사용하여 세계 공간의 로 변환
Deformable Body Model Fitting
- 해당 연구의 파이프라인은 full body shape와 pose 추정 : joint positions J와 bone rotation
- 관찰되지 않은 관절 위치는 의 forward kinematics와 해당 뼈 길이를 사용하여 복구
- 전신 joint 위치 를 이용하여 식 를 풀어 체형 업데이트
- bone rotation 는 검출된 visual direction output 를 사용하여 추가로 보정(사용 가능 시)
- 추정된 는 시간적 일관성이 있지만 모션 또는 가시성에 갑작스러운 변화가 발생할 경우 모션이 over-smoothed → 뼈 방향 를 에 더 가깝게 맞춰 해결 → 변화에 대한 더 빠른 반응 촉진
- 를 사용할 수 있는 경우, 보정된 뼈 회전 를 추정:
- : 로부터 벡터로의 회전
- joint 위치 는 를 사용하는 forward kinematics에 의해 업데이트
- 추정된 joint 는 시간적으로 일관된 joint 추정을 위해 다음 프레임으로 전송
- 포즈 파라미터 은 식과 식의 와 를 이용하여 추정
Results and Evaluation
-
본 연구의 3D 포즈 추정 방법은 이전 방법과 직접 비교할 수 없음
- 외부 카메라 기반 방법은 모든 joint를 볼 수 있어야 함
- 이전의 visual+interial 융합 접근법은 10개 이상의 IMU를 필요로 함
- 본 연구는 몸 전체를 포착하지 못하는 입력 스테레오 헤드웨어 뷰 및 손목과 발목에 장착된 관성 센서 4개만 사용
-
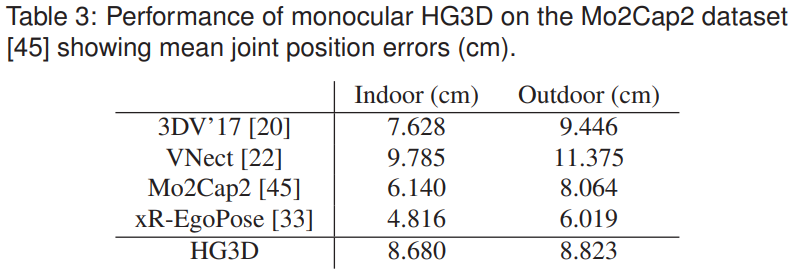
HG3D(stereo stacked hourglass 3D)는 식 의 visibility awareness term없이 절의 3D joint detector를 사용하는 시각적 전용 방법
- 눈에 보이는 관절과 보이지 않는 관절을 모두 감지하고, 4.3절에 표시된 것처럼 두 개의 아래쪽 카메라 뷰에서 관절을 병합하여 전신 3D 관절 위치를 생성
- 3D 골격 회전은 inverse kinematics 알고리즘을 사용하여 검출된 관절로부터 추정
- 본 연구는 공개적으로 사용 가능한 자기중심적 데이터 세트에 대해 monocular stacked hourglass 3D를 별도로 평가했으며 경쟁력 있는 결과

-
DIP는 손목, 발목, 몸통 및 머리에 배치된 6개의 센서를 사용하는 IMU 기반 방법인 Deep Inertial Poser[14]
- 본 연구는 머리 및 몸통의 방향과 가속도에 대한 실측값을 사용했고 비교에서는 사지 움직임만 포함
- 지상 실측 모양과 사전 보정된 관성 측정을 사용
- LSTM 아키텍처의 최상의 구성과 함께 20개의 과거 프레임과 5개의 미래 프레임을 포함
- 대조적으로, 본 연구의 자체적 방법은 런타임에 신체 형태와 센서 보정을 추정하며, 미래 프레임을 사용하지 않음
-
Ours8은 손목, 발목, 팔뚝, 허벅지에 착용하는 8개의 IMU를 사용한 버전
- 상부 뼈는 실제 측정이 가능하기에 절은 건너뜀
- 대신, 절의 visual-inertial alignment을 시간 경과에 따라 8개의 IMU 모두에 적용
Quantitative evaluation
-
재구성 결과의 정확성을 평가하기 위해 추정치와 실측치 사이의 3D joint 위치 및 방향 오류를 비교하여 시스템 평가
- Ego-VIP 데이터 세트에 대한 결과

- 모든 범주에서 본 연구의 방법이 HG3D 및 DIP를 능가 -
HG3D의 정확도는 보이는 joint에 대해서는 논문의 방법과 비슷하지만, 이외는 위치 오류가 상당히 높음
- IK를 사용하여 계산된 방향은 관성 센서에서 획득할 때보다 훨씬 덜 정확
- 소수의 관성 센서라도 joint 위치와 방향에서 자세 정확도를 크게 향상
-
DIP는 위치와 방향 모두에서 논문의 방법보다 훨씬 낮은 정확도와 높은 분산
- 희소한 시각 정보도 IMU 기반 방법에 통합하면 연속적 정확도가 크게 안정화된다는 것을 보여줌
- 보이지 않는 관절의 경우, 정확도는 여전히 DIP를 능가하면서 관성 센서에 전적으로 의존하기 때문에 크게 떨어짐
- 논문의 트랜스포머 네트워크 기반 방향 추정은 DIP의 LSTM 기반 네트워크보다 분산이 적음
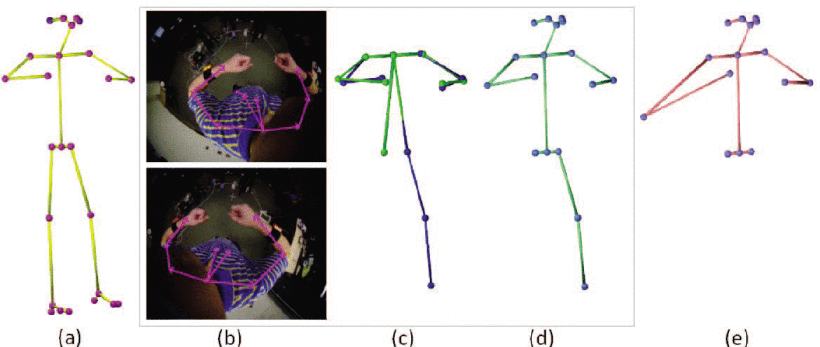
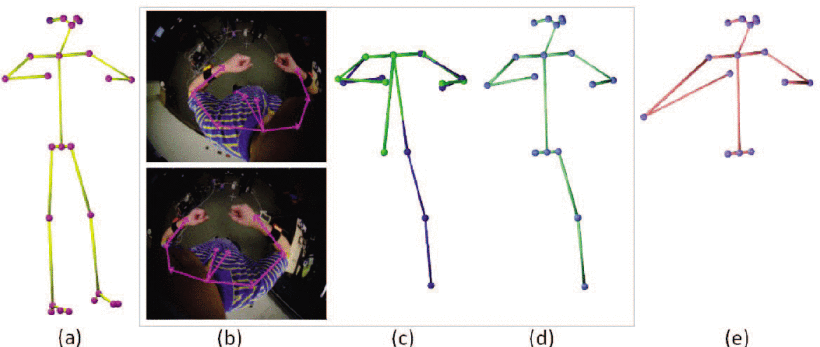
Qualitative evaluation
- HG3D는 (a)에서 가려진 오른쪽 무릎과 발목을, (b)에서 외부 관절을 감지하지 못함
- DIP는 (a)에서 왼쪽 무릎 올리기를, (b)에서 손 들기를 부족하게 감지하고, (c)에서 적은 IMU 입력의 포즈 모호성으로 인해 잘못된 하체 포즈를 출력
- Ours8(dense-IMUs) 변형은 모든 뼈가 IMU로 계측되기 때문에 세 가지 범주 모두에서 최고의 성능
- 그러나 IMU가 4개에 불과한 방법의 정확도는 Ours8과 비슷하며, HG3D 또는 DIP보다 훨씬 우수한 성능
FUTURE WORK
- 사용자의 사지만 추적하기 때문에 환경과의 상호 작용을 모델링하지 않으며, 신체 모델의 표면에서 토폴로지 또는 질감 변화를 감지할 수 없음
→ 의자 이동, 넥타이 착용 등 토폴로지 변화, 다른 셔츠 착용 등 질감 변화 등 객체와의 상호작용 지원을 추가할 계획
→ 3D 환경 접촉을 추정함으로써 물리적으로 타당한 접근 방식을 확장할 계획이며, 다른 신체 모델과 함께 보다 현실적인 모양을 만들 계획 - 관절 위치 정확도는 추정된 관절을 세계 공간으로 변환하는 데 사용되는 VSLAM 결과에 크게 좌우되며, VSLAM이 시간이 지남에 따라 불안정하거나 부정확한 경우 신체 자세 정확도 감소
→ 더 견고한 머리 포즈 추정을 위해 다중 전방 카메라를 사용하고 IMU를 헤드셋에 통합할 계획 - 현재 파이프라인에서 3D joint 감지 네트워크의 결과는 연속 방향 네트워크에 공급되며, 3D joint가 잘못 감지되면 오류가 전체에 전파
→ 잘못된 탐지에 대한 견고성을 개선하는 것뿐만 아니라 결합된 네트워크를 조사할 계획 - 현재 Physical Therapy (PT) 프로토타입과 달리, 미래의 애플리케이션 프로토타입은 양방향 텔레프레젠스를 보여줄 계획
