[Paper Review] Instant Neural Graphics Primitives with a Multiresolution Hash Encoding
0
NeRF
목록 보기
1/12

Abstract
- 품질을 유지하고 더 작은 네트워크의 사용을 위한 새로운 Input Encoding으로 성능 향상
- multiresolution hash table에 의해 feature 벡터 증강
- multiresolution 구조는 네트워크가 hash collision을 명확하게 할 수 있게 하여 현대 GPU에서 병렬화할 수 있는 단순한 아키텍처를 만듦
- 낭비되는 대역폭과 계산 작업을 최소화하는 데 중점을 두고, fully-fused CUDA 커널을 사용하여 전체 시스템을 구현함으로써 병렬성 활용
- 몇 초 만에 고품질 neural graphics primitive를 훈련하고 1920x1080의 해상도로 렌더링
MULTIRESOLUTION HASH ENCODING
- Instant-NGP 는 기존 voxel-based method 와 같이 voxel 의 vertices 에 parametric encoding 을 매핑하는 방법을 사용하며 독자적인 기능을 추가한다.
- Multi-level decomposition
: 전체 scene 을 multi-level 로 나누어 저장하여 각 level 별로 scene geometry 의 다른 부분에 집중할 수 있도록 함 - Spatial Hash Function
: 해상도가 높은 Voxel 일수록 저장해야 하는 point 의 수가 급격히 늘어나기 때문에, 모든 점에 대해 1:1 저장을 하지 않고 해당 함수를 통해 필요한 메모리를 줄임
- Multi-level decomposition
- Network 의 성능을 향상 시키기 위해 input 를 인코딩한다.
- : trainable weight parameter
- : trainable encoding parameter
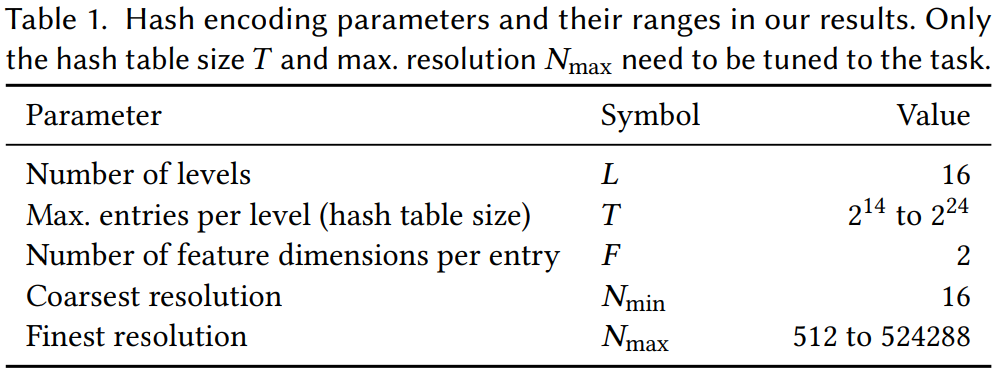
- 이들은 level에 배열되며, 각각은 차원 를 갖는 최대 개의 feature vector를 포함
PROCEDURE
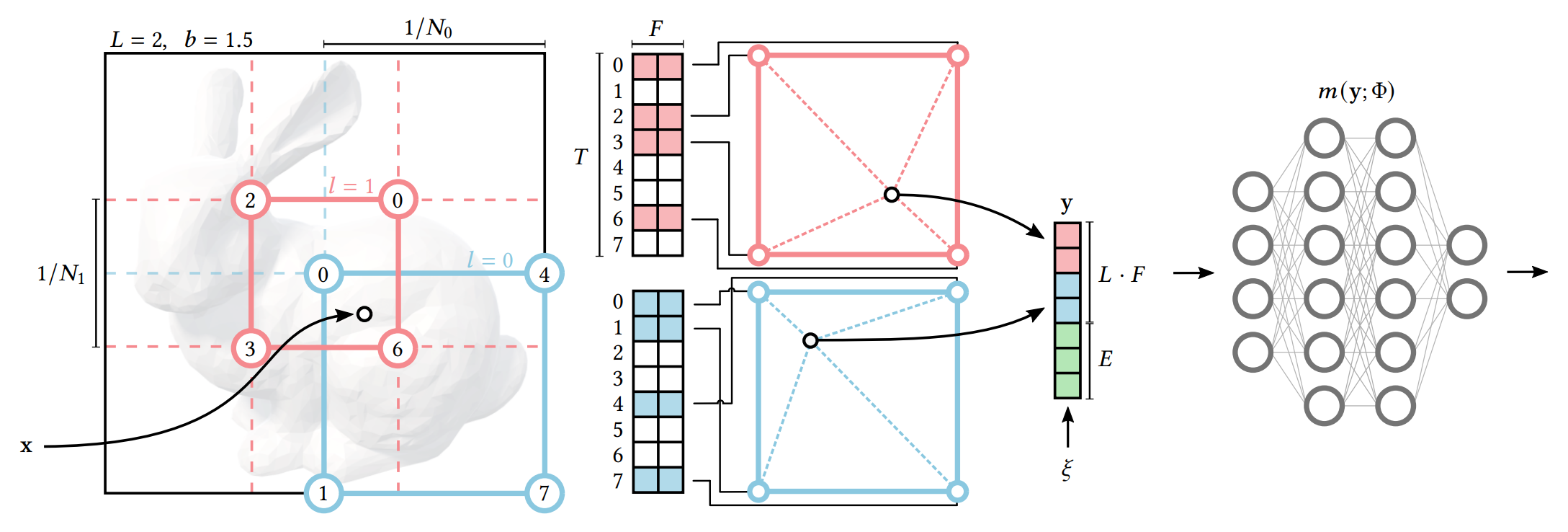
(1) Hashing of voxel vertices
- 각각의 level에 F차원 T개의 feature vector를 지정한다.
- 각 Level 마다 개의 resolution을 갖는 grid로 구성되며, F와 T는 Hyperparameter이고 performance와 quality의 tradeoff가 존재
Multi-Level Decomposition
- 총 level 에 대하여, level 에 대한 voxel 의 resolution 은 사이의 값으로 결정된다.
- : levels 의 수가 많기 때문에 growth factor는 작음
- 각 level의 해상도는 등비수열로 결정
- Input coordinates 가 가까운 Voxel로 매핑된다.
(2) Lookup
- Voxel의 Vertex에 정수 좌표를 hashing하여 인덱스를 할당한다.
- 입력 좌표 는 해당 level의 grid resolution에 따라 크기를 조정 (?이해안됨)
- grid size 가 보다 작으면(coarse level) voxel 과 feature table 1:1 매핑
- 그러나, grid size 가 보다 크면(fine level) Hash function을 이용해 indexing 후 매핑
- 입력 좌표 는 해당 level의 grid resolution에 따라 크기를 조정 (?이해안됨)
Spatial Hash Function
- Hash Function
- : bit-wise XOR operation
- 이 과정은 각 level에 대해 독립적으로 수행
- 매핑된 Voxel의 Vertex를 각 level의 feature vector array의 항목에 매핑한다.
- 연구의 기본 값 :
(3) Linear interpolation
- hypercube 내에서 의 상대적 위치에 따라 feature vector를 D차원 선형 보간한다.
- interpolation weight :
- discrete함을 방지하기 위해 interpolation을 통해 연속성을 보장
(4) Concatenation
- Interpolate된 각 level의 vector들을 auxiliary input과 함께 concatenate한다.
- e.g encoded view direction, textures etc
- interpolationed feature vector와 auxiliary input → MLP 에 대한 인코딩된 입력을 연결하여 인코딩된 MLP input 생성한다.
: NeRF에서의 viewing direction 정보
feature vector : input encoding parameter → hash table ?
(5) Neural network
- MLP에 input한다.

이세계 개발자입니다.