github : https://github.com/czczup/vit-adapter

Abstract
inductive biases를 도입한 최신의 vision specific model들과 달리,ViT는 사전 지식이 부족하기 때문에 dense prediction이 어려움ViT-Adapter제안- 다양한 데이터로 사전학습한 ViT Backbone을 가지고, downstream task에서,
pretraining-free adapter사용 - 이때,
adpater는 이미지 기반의inductive bias(위치 정보)를 모델에 넣어주는 역활
- 다양한 데이터로 사전학습한 ViT Backbone을 가지고, downstream task에서,
- 제안한
ViT-Adapter는 segmentation, detection 등 다양한 downstream task에서 좋은 성능을 보여줌ViT-Adapter가 vision-specific transformer들의 대체제가 되기를 바람
INTRODUCTION
- Vision Task model들은 크게 두분류로 나눌 수 있음
- plain ViT
- vision-specific transformers => inductive biases(ex. 공간 정보)를 구조에 도입하기 때문에 주로 사용되고 있음
- plain ViT는 이미지 기반의 사전 지식 X -> 느린 수렴 속도, 낮은 성능을 보여줌
=>Plain ViT에adapter도입
Vision Transformer Adapter (ViT-Adapter)
- pre-training free인 추가 네트워크
=> 기존 ViT에 효율적으로 다양한 down task를 붙일 수 있음 (flexible)

- vision-specific inductive biases를 ViT에 도입
- 이를 위한 모듈 구현 : (1)
spatial prior module, (2)spatial feature injector,multi-scale feature extractor
- 이를 위한 모듈 구현 : (1)
💥핵심💥
- plain ViT에 inductive biases를 도입한 새로운 파라다임 제안
- spatial prior module과, 2개의 feture interaction 모듈 설계 => ViT 구조 변경 없이 이미지 사전지식 넣어줌
METHOD
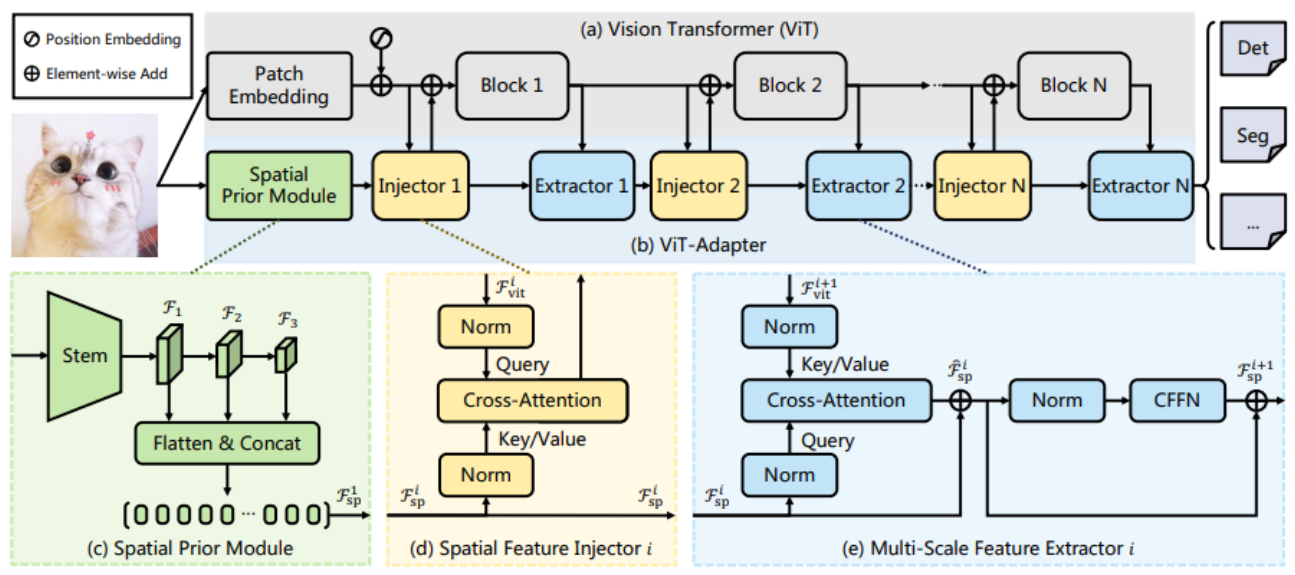
- 두 part로 구성
(a)ViT
(b)ViT-Adapter: spatial prior module, spatial feature injector, multi-scale feature extractor로 구성 - adapter의 multi-scale feature extracor에서 다양한 크기의 feature를 추출 => resnet과 같은 multi-scale feature 얻을 수 있음 => dense prediction에 사용 가능
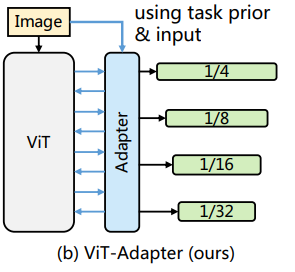
(1) Spatial Prior Module (SPM)
-
역할 : 입력 이미지에서 공간정보 추출
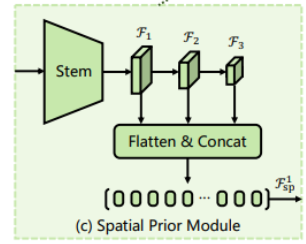
- transformer가 공간 정보를 포착하는데 convolution이 도움 -> ResNet의 convolution stem 사용 & 이후, 다른 모듈에서 attention을 수행하기 위해 flatten시켜줌
(2) Spatial Feature Injector (SPI)
-
역할 :
ViT에 추출한 공간정보 주입
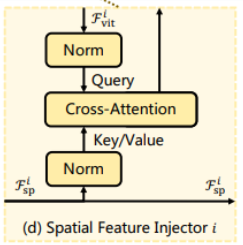
- ViT의 feature와 SPM의 공간 feature를
attention하여 ViT에 보내줌
- ViT의 feature와 SPM의 공간 feature를
(3) Multi-scale Feature Extractor (MFE)
-
역할 :
ViT의 feature를 multi-scale로 변환
(ViT의 각 block은 같은 크기의 feature 추출 -> 다양한 크기의 feature 학습 불가)

cross attention,FFN(-> down sampling 진행)구성
EXPERIMETNS
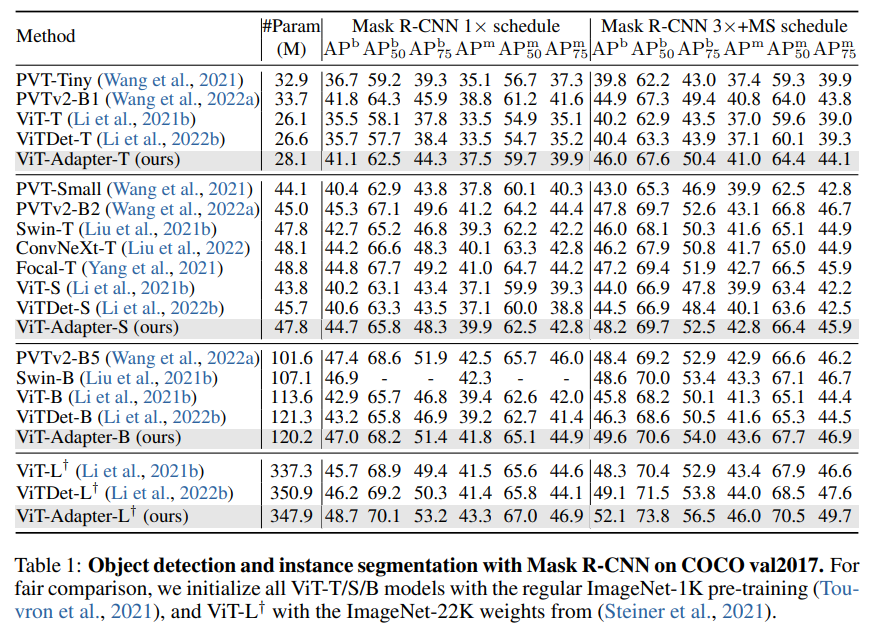
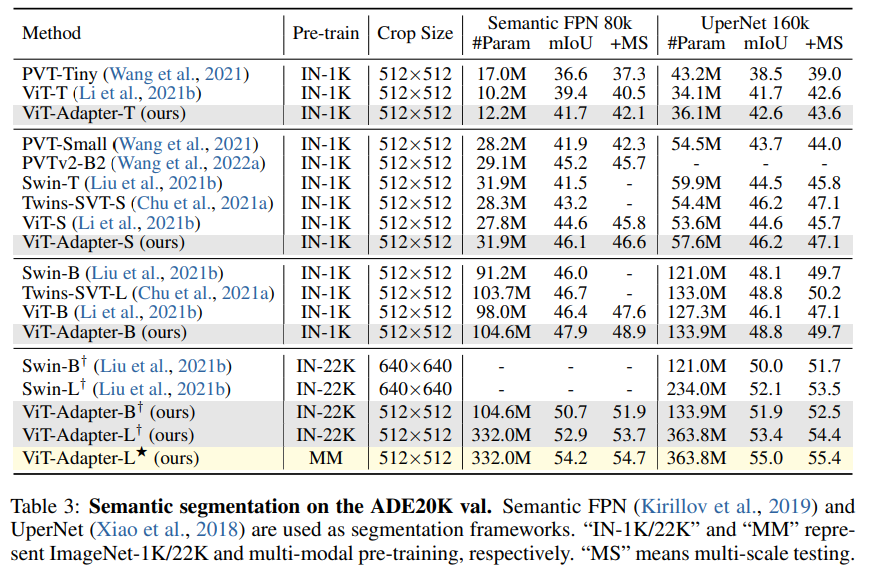

- Ablation Study
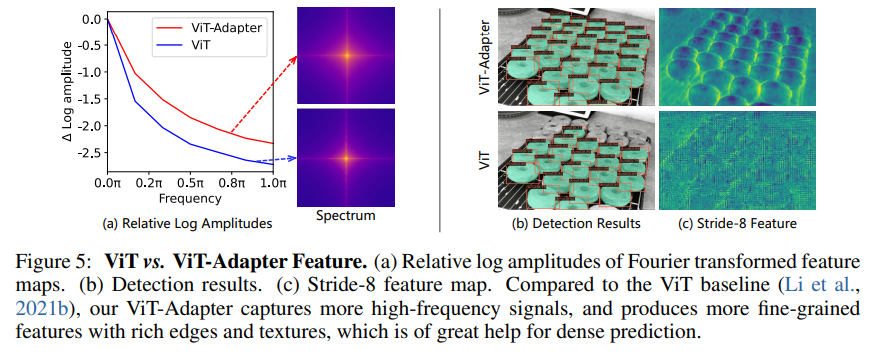
-> ViT-Adapter에서 나온 feature가 더 fine-grained(edge ..) 함



🦴피곤행🦴
저도 개발자인데 같이 교류 많이 해봐요 ㅎㅎ! 서로 화이팅합시다!