⚡ 분할정복
📌 분할정복
- 아우스터리츠 전투에서 나폴레옹이 사용한 전략에서 유래되었다.
💡 나폴레옹이 연합군의 중앙부로 쳐들어가 연합군을 둘로 나누고 둘로 나뉜 연합군을 한 부분씩 격파했다.
🔷 설계 전략
분할(Divide): 해결할 문제를 여러 개의 작은 부분으로 나눈다.정복(Conquer): 나눈 작은 문제를 각각 해결한다.통합(combine): 필요하다면 해결된 해답을 모은다.
🖥 거듭 제곱으로 알아보는 분할 정복
public class DailyClass {
public static void main(String[] args) {
int C = 3;
int N = 12;
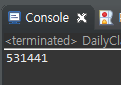
System.out.println(pow(C, N));
}
// 재귀로 거듭제곱
public static int pow(int C, int N) {
// 기저조건
if(N == 0 || N == 1) return C;
// 재귀조건
// 짝수
if(N%2 == 0) {
return pow(C, N/2) * pow(C, N/2);
}
else {
return pow(C, (N-1)/2) * pow(C,(N-1)/2) * C;
}
}
}
C^N는C^N/2 + C^N/2와 같음을 이용한다.- N이 홀수라면 C를 한번 분리해두다가 곱한다.
📌 이진 검색
🔷 자료의 가운데에 있는 항목의 키 값과 비교하여 다음 검색의 위치를 결정하고 검색을 계속 진행하는 방법
- 목적 키를 찾을 때까지 이진 검색을 순환적으로 반복 수행함으로써 검색 범위를 반으로 줄여가면서 보다 빠르게 검색을 수행함
❗ 이진 검색을 수행하기 위해서는 자료가 정렬된 상태여야 한다.
🔷 검색 과정
1. 자료의 중앙에 있는 원소를 고른다.
2. 중앙 원소의 값과 찾고자 하는 목표 값을 비교한다.
3. 중앙 원소의 값과 찾고자 하는 목표 값이 일치하면 탐색 종료
4. 목표 값이 중앙 원소의 값보다 작으면 자료의 왼쪽 반에 대해서 새로 검색을 수행하고, 크다면 자료의 오른쪽 반에 대해서 새로 검색을 수행한다.
5. 찾고자 하는 값을 찾을 때까지 1 ~ 4의 과정 반복
public class DailyClass {
public static int [] arr;
public static int key;
public static void main(String[] args) {
arr = new int [] {2, 4, 7, 9, 11, 19, 23};
key = 7;
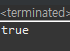
System.out.println(binarySearch(0, arr.length-1));
}
public static boolean binarySearch(int st, int ed) {
if(st > ed) return false;
int mid = (st + ed) / 2;
if(arr[mid] == key) return true;
else if(arr[mid] > key) return binarySearch(st, mid-1); // 키보다 크면 왼쪽으로
else return binarySearch(mid+1, ed); // 키보다 작으면 오른쪽으로
}
}
📌 병합 정렬
🔷 여러 개의 정렬된 자료의 집합을 병합하여 한 개의 정렬된 집합으로 만드는 방식
🔷 분할 정복 알고리즘 활용
- 자료를 최소 단위의 문제까지 나눈 후에 차례대로 정렬하여 최종 결과를 얻어냄
top-down방식안정 정렬
💡 시간복잡도:
O(nlogn)
병합 정렬 과정
1. 분할 단계: 전체 자료 집합에 대하여, 최소 크기의 부분집합이 될 때까지 분할 작업을 계속한다.
2. 병합 단계: 2개의 부분 집합을 정렬하면서 하나의 집합으로 병합
import java.io.BufferedReader;
import java.io.BufferedWriter;
import java.io.IOException;
import java.io.InputStreamReader;
import java.io.OutputStreamWriter;
import java.util.StringTokenizer;
// 100만개 입력받고 정렬한 뒤 50만번째 출력하기
public class Solution {
static int arr[];
static int sortedArr[];
public static void main(String[] args) throws IOException {
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
BufferedWriter bw = new BufferedWriter(new OutputStreamWriter(System.out));
StringTokenizer st = new StringTokenizer(br.readLine());
int N = 1000000;
arr = new int [N];
sortedArr = new int [N];
for(int i = 0; i < N; i++) {
arr[i] = Integer.parseInt(st.nextToken());
}
mergeSort(arr, 0, N-1);
bw.write(String.valueOf(sortedArr[500000]));
br.close();
bw.close();
}
// 분할 후 병합 과정
static void mergeSort(int [] arr, int left, int right) {
if(left < right) {
int mid = (left + right) / 2;
mergeSort(arr, left, mid);
mergeSort(arr, mid+1, right);
merge(arr, left, mid, right);
}
}
// 병합
static void merge(int [] arr, int left, int mid, int right) {
int L = left;
int R = mid+1;
int idx = left;
while(L <= mid && R <= right) {
if(arr[L] <= arr[R])
sortedArr[idx++] = arr[L++];
else
sortedArr[idx++] = arr[R++];
}
if(L <= mid) {
for(int i = L; i <= mid; i++) {
sortedArr[idx++] = arr[i];
}
} else {
for(int i = R; i <= right; i++) {
sortedArr[idx++] = arr[i];
}
}
for(int i = left; i <= right; i++) {
arr[i] = sortedArr[i];
}
}
}📌 퀵 정렬
🔷 주어진 배열을 두 개로 분할하고, 각각을 정렬한다.
- 병합 정렬은 그냥 두 부분으로 나누는 반면에, 퀵 정렬은 분할할 때, 기준 아이템(
pivot item) 중심으로, 이보다 작은 것은 왼편, 큰 것은 오른편에 위치시킨다. - 각 부분 정렬이 끝난 후, 병합 정렬은 "병합"이란 후처리 작업이 필요하지만 퀵 정렬은 필요로 하지 않는다.
불안정 정렬
💡 시간복잡도: O(nlogn), 최악의 경우(n^2)
🔷 동작 과정
1. 정렬한 배열 입력
2. 임의의 한점을 pivot으로 선정 (Partiton 방법)
pivot보다 작은 값들을 왼쪽으로, 큰 값들을 오른쪽으로 이동
- 정렬할 범위가 0이나 1이 될 때까지 분할 정복
🔷 Hoare-Partition 알고리즘
-
pivot: 왼쪽 끝, 오른쪽 끝, 임의의 세개 값 중 중간 값 중 선택1) 제일 왼쪽 값을
pivot으로 잡는다면
2) 그 다음 값을 L, 끝의 값을 R로 잡는다.
3) L과 R이 교차하지 않았으면서 L이pivot보다 작거나 같으면 L을 증가시킨다. 크면 멈춘다.
4)pivot보다 R이 크면 R을 감소시킨다. 작으면 멈춘다.
5) L보다 R이 아직 앞서지 않았으면 L과 R을 스왑한다.
6) R이 L을 앞섰으면(교차했으면) 중단하고 R과pivot의 위치를 스왑한다.
7) 스왑하여 자리잡은pivot의 위치는 정렬된 상태가 되었다.
8) 그 위치를 기준으로 좌측과 우측에 퀵 정렬을 반복한다.
🔷 Lomuto Partition 알고리즘
-
pivot은 제일 우측의 값
-
i = left - 1
1) j 반복문으로 left부터 right-1까지 순회 (right는 pivot이니 생략)
2) j가 가리키는 값과 pivot을 비교하며 pivot이 크거나 같으면 i를 증가시키고 arr[i]와 arr[j]를 스왑한다.
3) 반복이 종료되면 arr[i+1]과 pivot을 스왑한다.
4) 스왑하여 자리잡은pivot의 자리는 정렬된 상태가 되었다.
5) 그 위치를 기준으로 좌측과 우측에 퀵 정렬을 반복한다.
💡 직접 구현해보는 것은 중요하다. 하지만 java에는 이들을 그대로 가지고 온
Collections.sort()나Arrays.sort()가 있으니 원리를 깨우치고 나면 이를 활용하자. 나는 더 연습좀 해보련다...
