[AIB]Note113~4 Data Manipulation, Basic Derivative
AIBBasic DerivativeData ManipulationData PreprocessingEDAIntroduction to Data ScienceSection_1개념정리코드스테이츠
0
AIB 학습
목록 보기
2/15

1. Data Manipulation
1.1 Data Manipulation은 무엇인가?
- Data는 무슨 뜻인지 알고 있을거고, Manipulation은 조종하다는 뜻으로 이해하면 좋다. 데이터를 분석하기 좋도록 조종, 즉 조작, 수정 등으로 이해하면 좋을 듯하다.
1.2 왜 하는가?
- 내가 원하는 데이터들이 우리가 보는 엑셀 파일 등에 하나로 다 들어가 있을 수가 없다. 왜냐하면 다양한 곳에서 여러 주체들이 무수히 많은 데이터를 생산하고 정리하고 있기 때문이다. 그래서 여러 개로 나뉘어져 있는 파일 혹은 dataframe(이하 'df')을 하나로 합쳐줄 필요가 있다.
1.3 어떻게 하는가?
- pandas에서는 데이터를 concat, merge를 사용할 수 있다.
- 둘 다 df를 합쳐준다는 점에서 공통점이 있다.
1.3.1 concat
- concat은 concatenate의 줄임말이다.
- 쉽게 생각하면
무지성으로합쳐준다고 이해하면 좋을까? 나는 그렇게 이해했다. - 기계적으로, 물리적으로 그냥 합쳐준다. 아래 그림 참고!
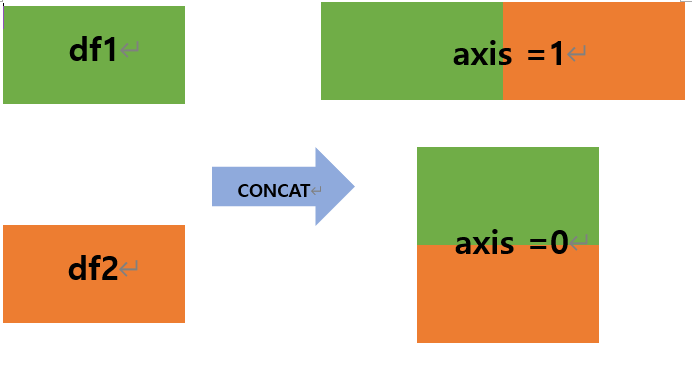
- 열(column, 세로, 좌우)은 axis=1 // 행(row, 가로, 위아래)로 합하려면 axis=0
+ https://pandas.pydata.org/docs/reference/api/pandas.concat.html
함수에 대해 궁금하면 pandas에서 보다 자세하게 확인할 수 있다!
1.3.2 merge
- merge 요게 좀 헷갈리고 어렵다...
- 기본 개념은 공통의 기반으로, 공통된 부분만 합쳐진다. 아래와 같은 느낌!
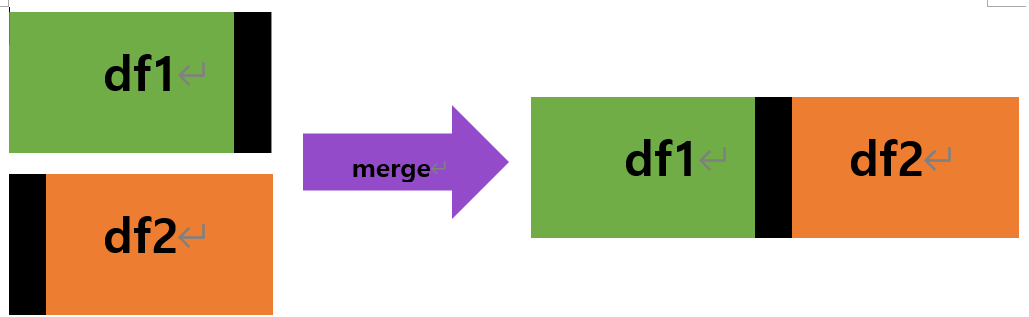
- 근데 이게 '공통'이 무엇인지에 따라 어떻게(함수에서는 how) 합쳐지는지가 달라진다. 위와 같은 것은 기본 값인 'inner'이다. 말고도 Outer, Left, Right가 있다!
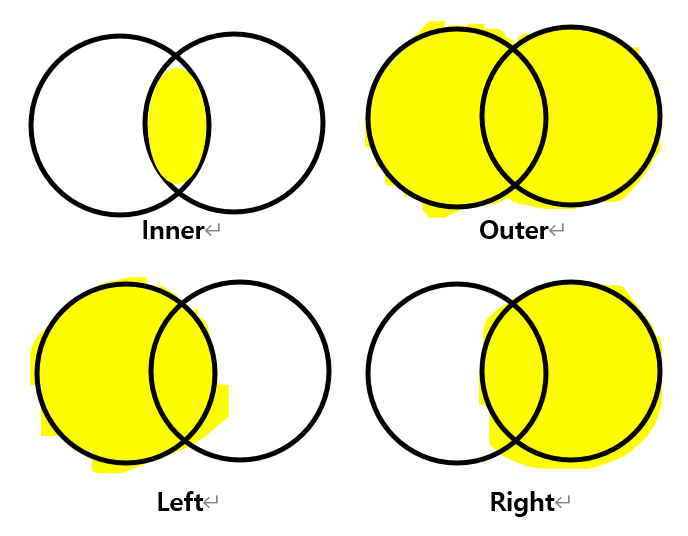
- Inner : 교집합, Outer: 합집합,
Left: 왼쪽(코드 상 먼저 오는 df)기준,
Right: 오른쪽(코드 상 뒤에 오는 df)기준
으로 생각하면 좋을 것 같다. 하지만 머릿속의 개념과 실제 코드는 정말.. 많이 다르게 나온다!! 직접 해보아야 알 수 있다
+https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.merge.html merge함수에 대해 더 알고 싶으면!
초저퀄 그림은 블로그에 올리려고 직접 한글로 그렸습니다 ㅜㅜ
1.4 그러면 어떻게 되는가?
- 앞서 언급한 것처럼 다양한 종류의 df를 하나로 합치기 때문에 df1, df2, df3 ... 등등의 df를 하나로 합치게 된다.
- 그러고 난 후에는 df가 하나가 되었기 때문에 다시 데이터 분석에 용이하도록 Feature 를 다시 수정하거나, 시각적으로 표현하거나 할 수 있다.
1.5 Tidy data
- 각 변수가 열이고, 각 관측치가 행이 되도록 배열된 데이터.
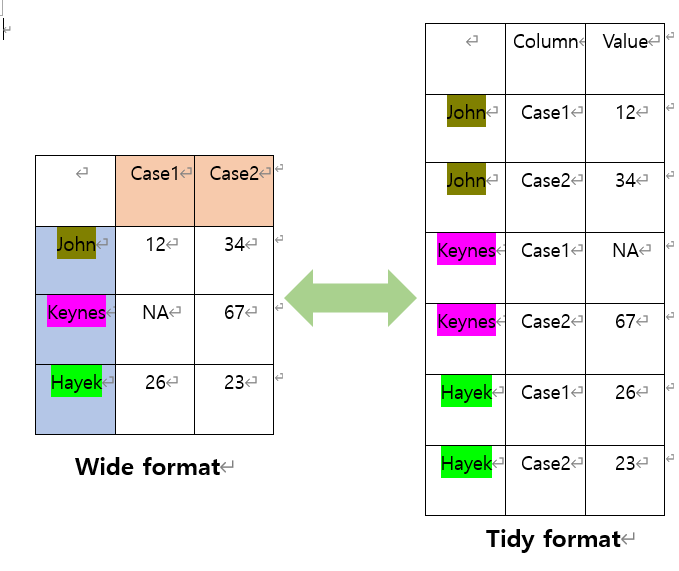
- Seaborn 등 시각화를 활용할 때 유용하게 쓰인다.
2. Basic Derivative
2.1 Basic Derivative가 뭔가?
- 단어의 뜻 자체는 '미분의 기초개념'으로 보면 될 듯 하다.
- 여기서 말하고자 하는 것은 도함수, 편미분, 미분
2.2 도함수
- 도함수는 그래프 접선에서의 기울기라고 생각하면 좋다.
2.3 편미분
- 여러 변수가 있는 다변수 함수에서 특정 변수에 주목하고, 나머지 변수를 상수로 간주한 미분. 경제에서 얘기하는 '다른 모든 조건은 일정할 때(=Cetris paribus)'
- 즉, 나 빼고 다 고정!! 나만 바뀔거야.
- 미분과 편미분의 차이: 미분은 모든 변수 x, y, z 등등 모든 것이 변화할 때의 변화량을 구한다면, 편미분은 x를 제외한 나머지 y, z 변수는 고정(=상수)되어 있다고 간주하고 미분하는 것!
- ∂ 기호를 사용한다.
2.4 Chain Rule
- 합성함수(함수의 함수)를 미분하기위해 사용하는 것.
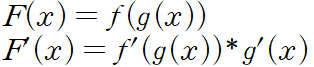
- 양파 껍질을 까듯이 바깥 함수 f(x)부터 미분 후에 안에 함수 g(x) 미분 후 곱
- 역전파(Backward propagation)에 많이 사용된다.
- 예)
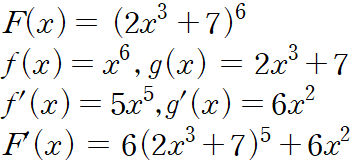
2.5 경사하강법(Gradient Descent)
- 최적화 알고리즘의 대표적인 예시
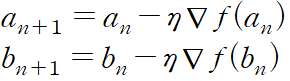
- 반복적으로 a, b를 update하면서 ∇f가 0이 될 때까지 이동한다.
- η(eta, 그리스어)는 학습률(Learning rate, lr)를 의미한다. 이 값이 낮으면 매우 조금씩 움직인다. 이는 시간이 오래 걸린다는 뜻. 반면 이 값이 높으면 극소 값을 못 찾게 된다. 즉 수렴을 못 하고 계속 반복할 수도 있다. 그러므로 학습률을 적절하게 잘 찾아주어야 한다.
- ∇(NABLA, 역삼각형)은 Gradient 즉, 기울기를 의미한다.
+ https://developers.google.com/machine-learning/crash-course/fitter/graph 여기를 들어가면 보다 자세하게 무슨 의미인지 알 수 있다! 그리고 직접 테스트를 해볼 수도 있다.

안녕하세요.