Porting Mellanox Connect X-6 100Gbe (feat. troubleshooting)
From the previous problem of not having enough rx performance, we decided to port both server's NIC to Mellanox Connect X-6 100Gbe!
1.Reset SR-IOV Settings
due to a new NIC, I had to reset SR-IOV Settings.
From the following command I was able to see the configurations of the NIC
sudo mlxconfig -d 0000:65:00.0 q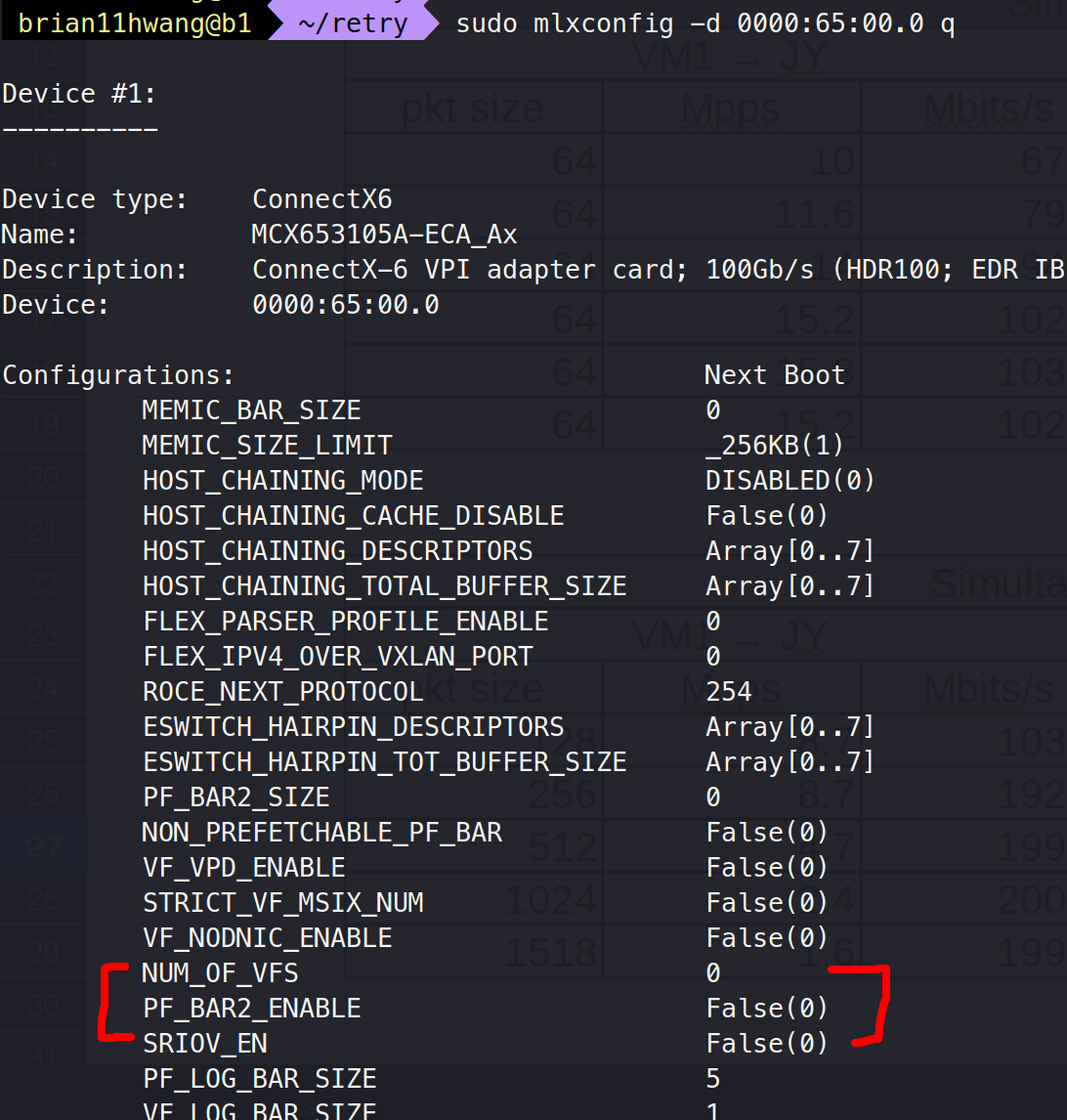
We can see that SR-IOV is not enabled and VFs are set as 0.
Change this with:
sudo mlxconfig -d 0000:65:00.0 set SRIOV_EN=1 NUM_OF_VFS=4Then, we can see:

Then, enable VFs using:
echo 4 > /sys/class/infiniband/mlx5_0/device/mlx5_num_vfsThen, we can see 4 VFs created.

2.Troubleshooting - IOMMU_Group
Then, after confiruing KVM on JY, and following the steps from KVM Installation on Connect X-3, I was unable to connect the SR-IOVed virtual NIC onto the VM as below:

Error starting domain: internal error: qemu unexpectedly closed the monitor: 2023-03-11T11:43:15.081326Z qemu-system-x86_64: -device vfio-pci,host=01:00.1,id=hostdev0,bus=pci.0,addr=0x9: vfio error: 0000:01:00.1: group 1 is not viable
Please ensure all devices within the iommu_group are bound to their vfio bus driver.
Traceback (most recent call last):
File "/usr/share/virt-manager/virtManager/asyncjob.py", line 89, in cb_wrapper
callback(asyncjob, args, **kwargs)
File "/usr/share/virt-manager/virtManager/asyncjob.py", line 125, in tmpcb
callback(args, kwargs)
File "/usr/share/virt-manager/virtManager/libvirtobject.py", line 82, in newfn
ret = fn(self, *args, kwargs)
File "/usr/share/virt-manager/virtManager/domain.py", line 1508, in startup
self._backend.create()
File "/usr/lib/python2.7/dist-packages/libvirt.py", line 1062, in create
if ret == -1: raise libvirtError ('virDomainCreate() failed', dom=self)
libvirtError: internal error: qemu unexpectedly closed the monitor: 2023-03-11T11:43:15.081326Z qemu-system-x86_64: -device vfio-pci,host=01:00.1,id=hostdev0,bus=pci.0,addr=0x9: vfio error: 0000:01:00.1: group 1 is not viable
Please ensure all devices within the iommu_group are bound to their vfio bus driver.
This was strange because b1 server was successfully binded.
2.1 What are b1 and JY different?
From throughly searching the difference, from the following shell script,
#!/bin/bash
shopt -s nullglob
for g in $(find /sys/kernel/iommu_groups/* -maxdepth 0 -type d | sort -V); do
echo "IOMMU Group ${g##*/}:"
for d in $g/devices/*; do
echo -e "\t$(lspci -nns ${d##*/})"
done;
done;The following outcome was:
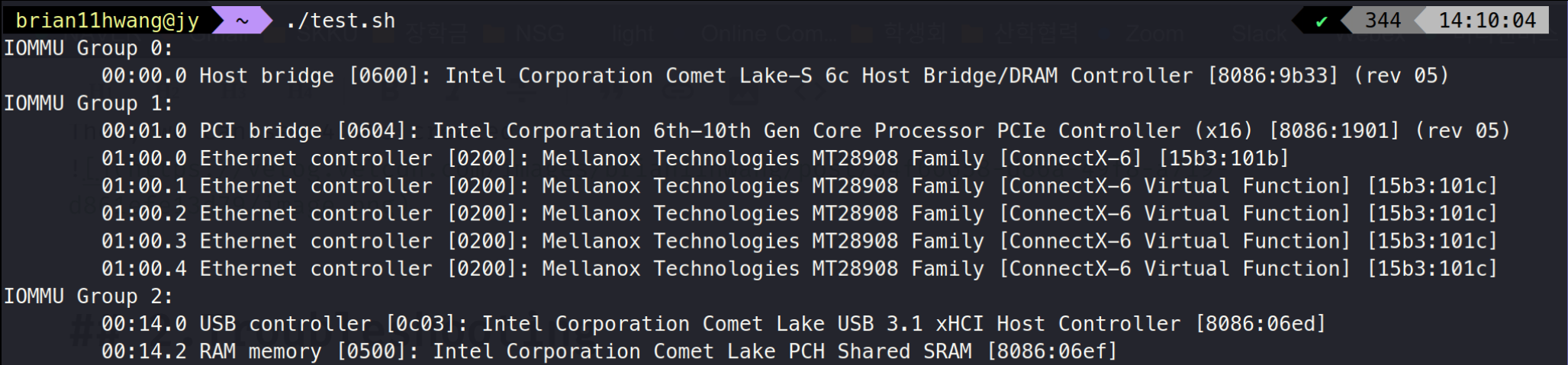
JY:
B1:
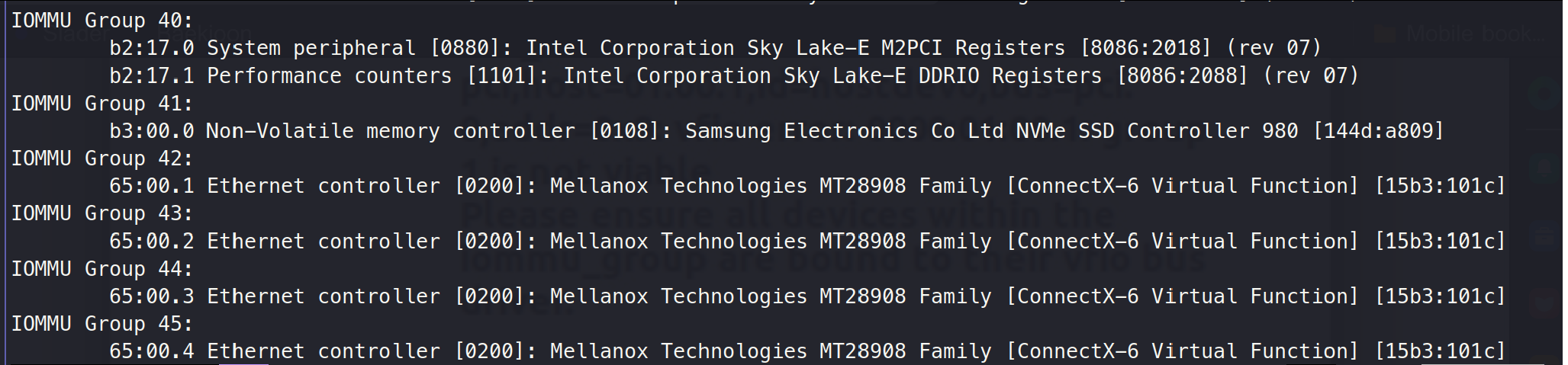
This showed that the virtual NICs was bound to a single group at JY, where as for b1, the groups were scattered.
In Hardware Considerations for Implementing SR-IOV it states:
Isolation of transactions between the virtual guest and the virtual functions of the PCIe device is fundamental to device assignment. Access Control Service (ACS) capabilities defined in the PCIe and server specifications are the hardware standard for maintaining isolation within IOMMU groups. Without native ACS, or confirmation otherwise from the hardware vendor, any multifunction device within the IOMMU group risks exposing peer-to-peer DMA between functions occurring outside of the protection of IOMMU, extending the IOMMU group to include functions lacking appropriate isolation.
Further, it states:
Intel devices do not typically include native ACS support on controller hub-based root ports, however the Red Hat Enterprise Linux 7.2 kernel includes some flexibility to enable ACS-equivalent isolation on those root ports for X99, X79, and 5-series through 9-series chipsets.
2.2 What are IOMMU , IOMMU group, vfio, and ACS?
To understand the problem straight, I had to first understand these keywords.
Thus, these concepts were studied here:
https://velog.io/@brian11hwang/What-are-IOMMU-IOMMU-group-vfio-and-AMC-support
2.3 How to solve?
--?
3.Troubleshooting2 - B1 Itself
Now that we've known that JY server will be unable to have SR-IOVed VFs on the VM, we've managed to rollback to B1.
The main reason we've intended to maximize JY's performance was due B1' lack of performance, so it was a pitty to come back to B1.
Anyways, B1 server had 2 main issues.
3.1 Low performance Issue at Host
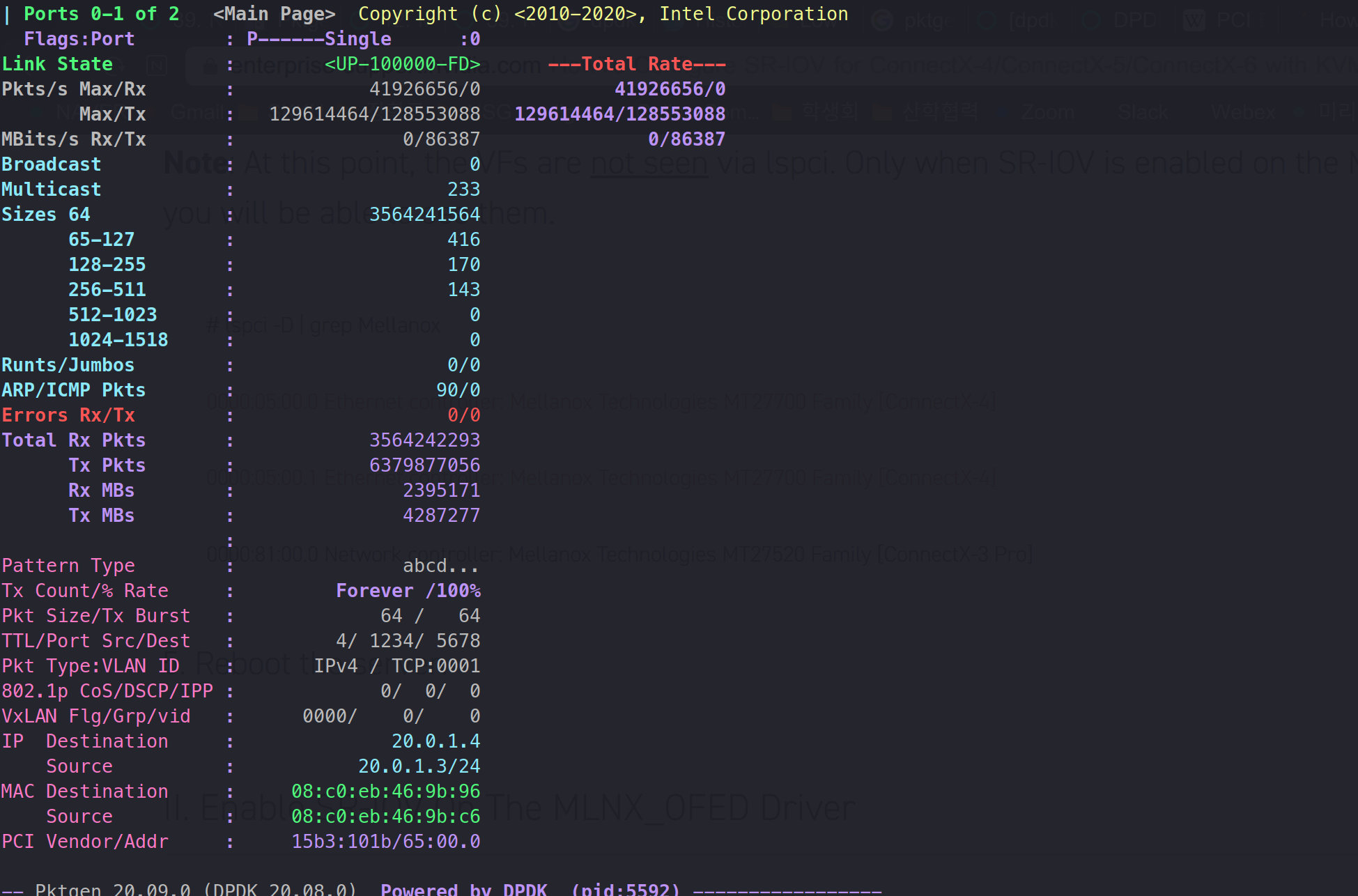
Unlike that of JY's performance, B1 has a performance degration of up to 86~88G. This is way lower to JY which showed up to 100G.
To solve this issue, I've tried a loads of methods.
3.1.1 DPDK Performance Report Optimization
--> Did not work..
3.1.2 Memory change
--> Did not work..
3.1.3 CPU Over/Under Clock
--> Did not work..
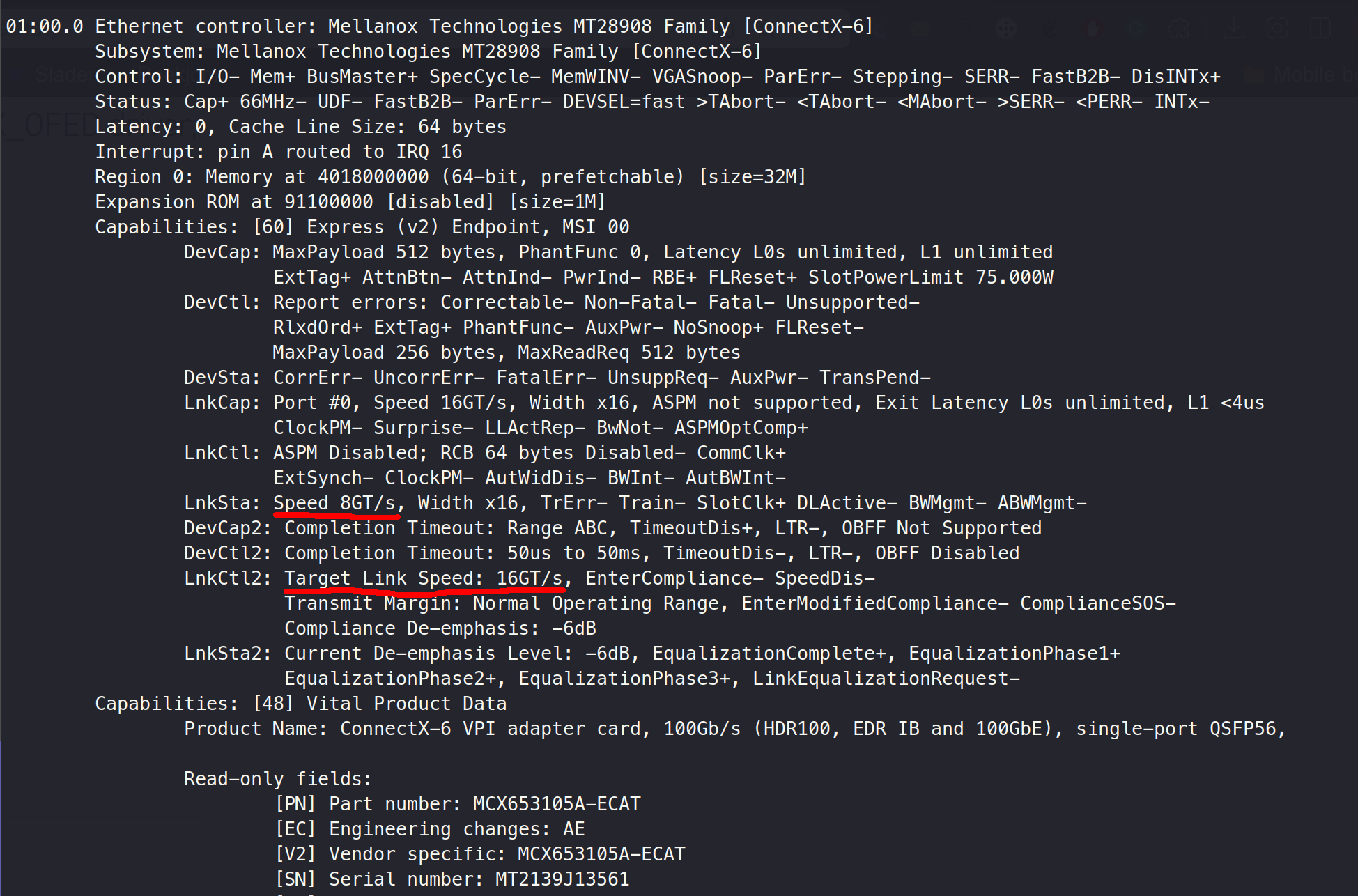
3.1.4 PCIe Bandwith
JY:
B1:
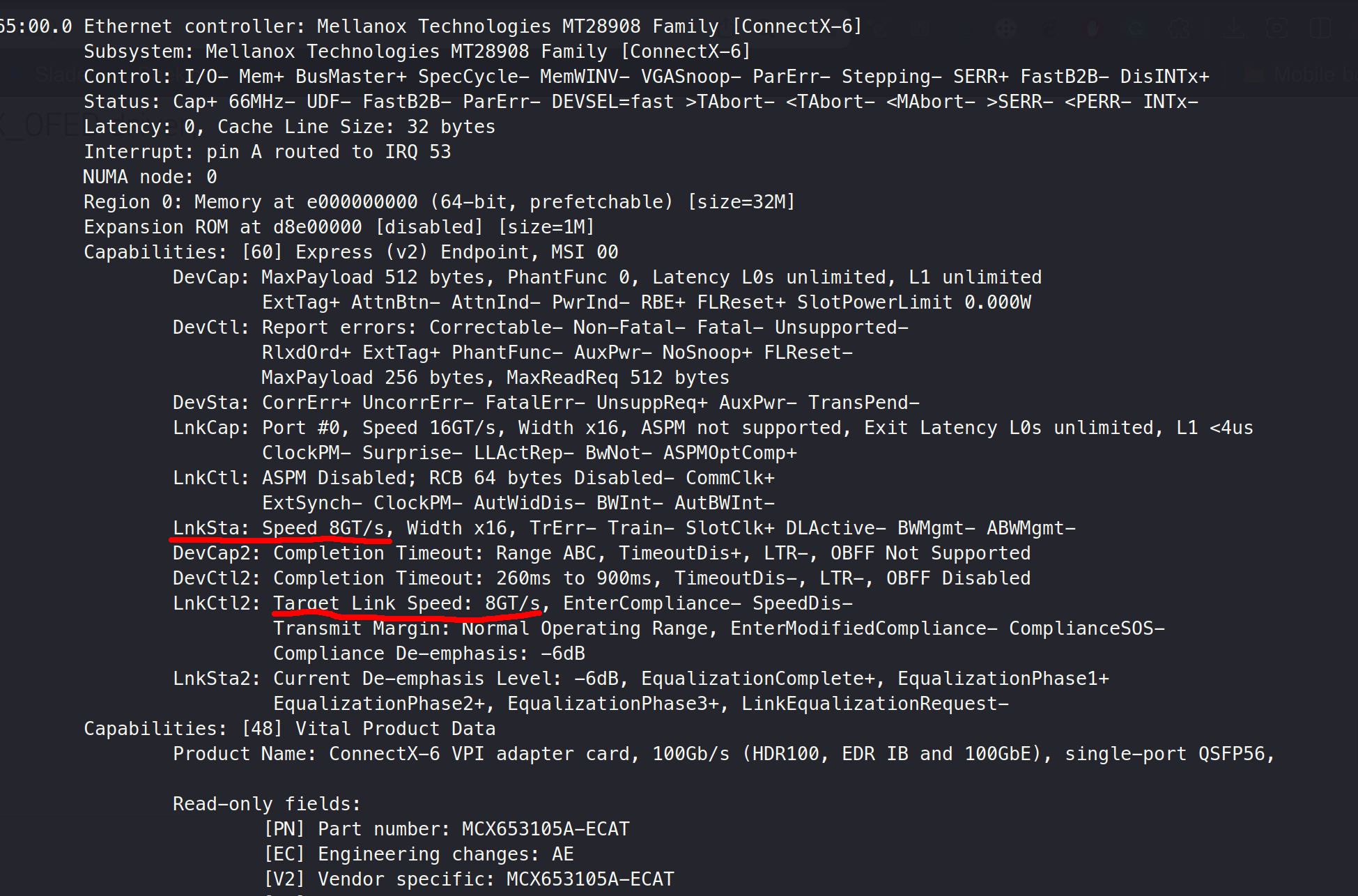
What is LnkCtl?


3.2 Low Performance Issue at VM
A far more worse problem is that the performance at VMs are way worse.
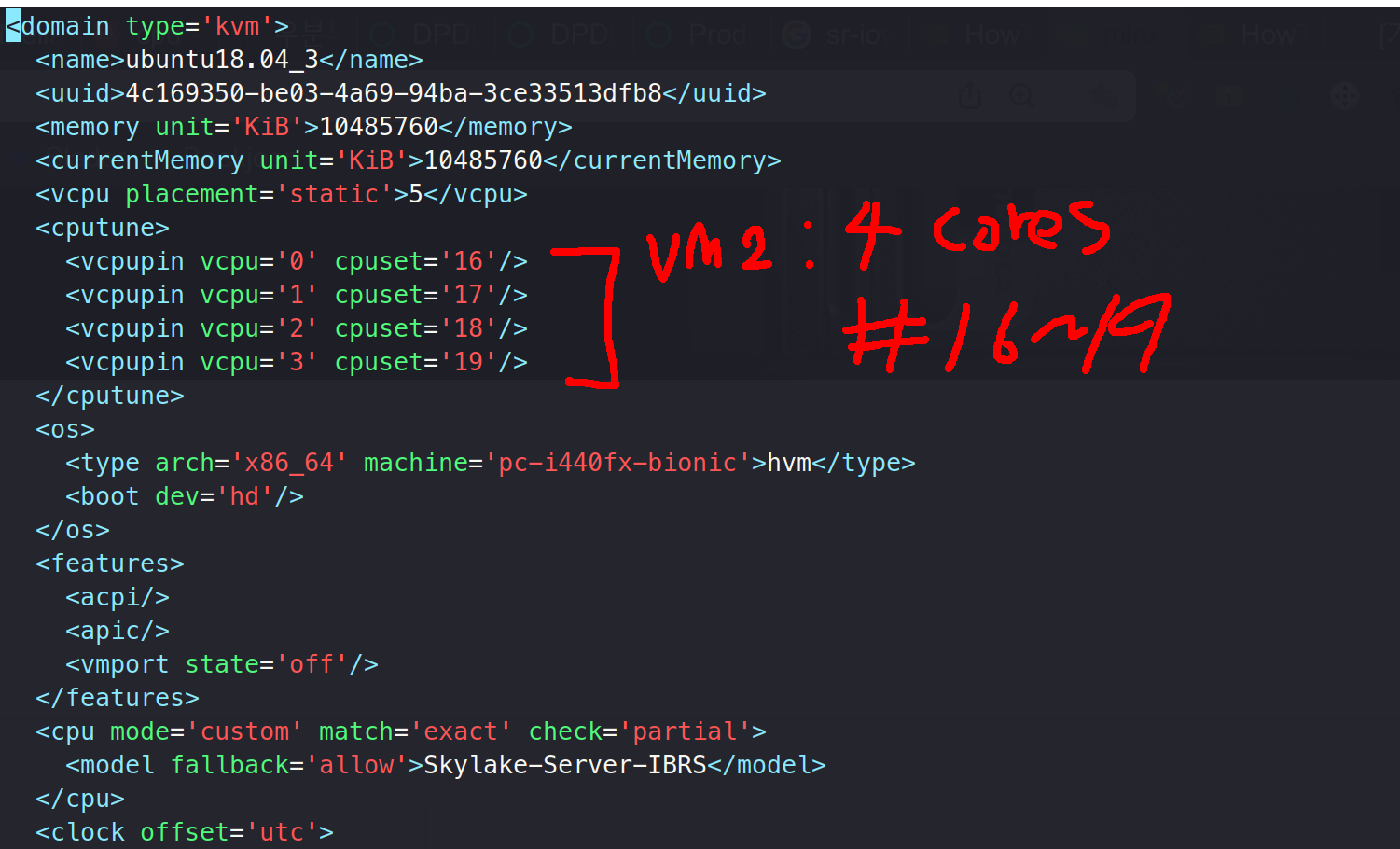
Then, I have found that even after turing off Hyper Threading, which makes the core # 10, VM1 and VM2 was able to run simultaneously, with 8 cores each.
This meant that cores were able to be shared between VMs, and also between the host and the VM
Then, I thought, then why not give all 10 cores to the VM and see what happens?
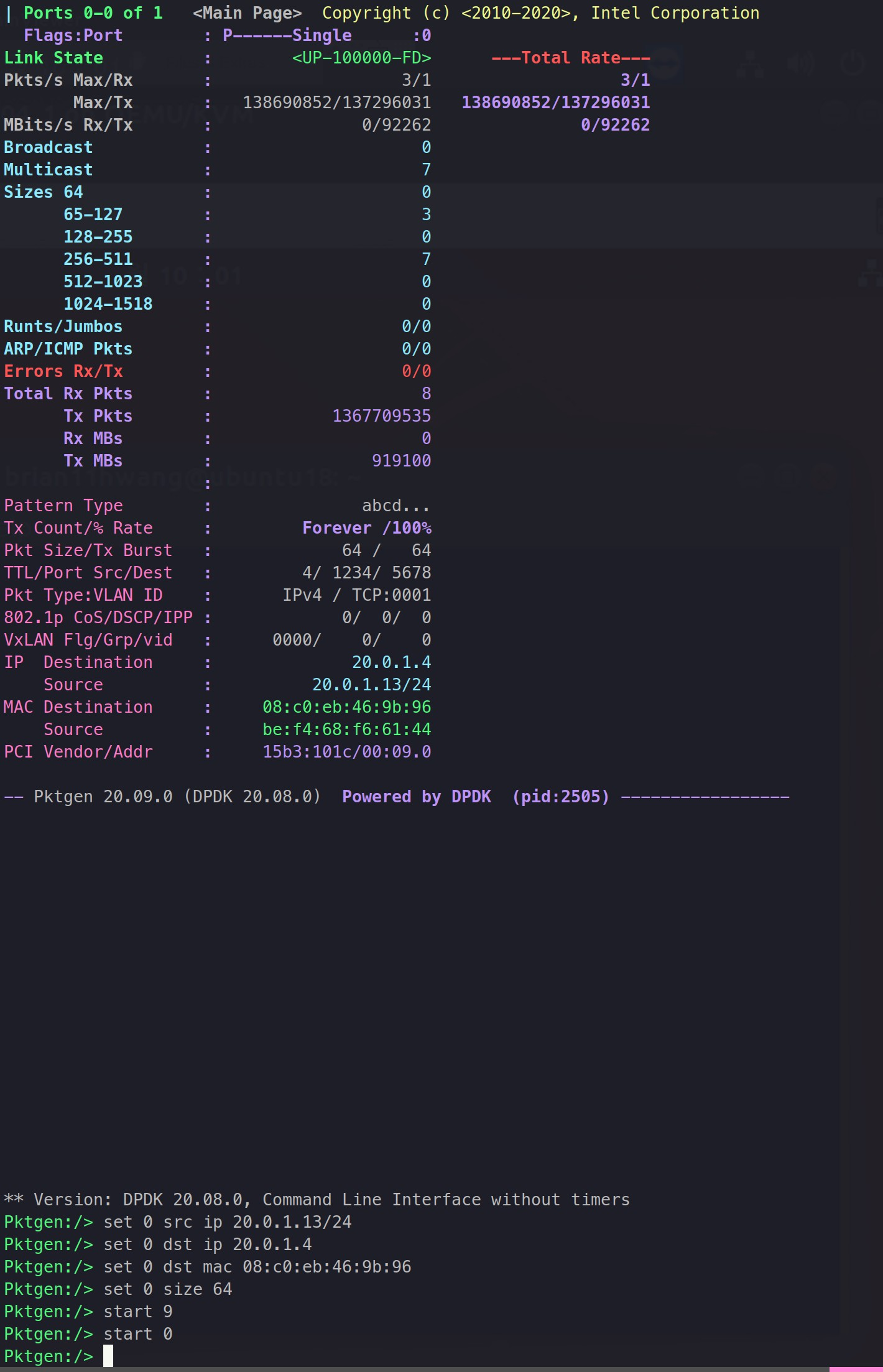
Wala! giving 10 cores hightened the performance up to 93G. This was higher than that of the host's.
So, I have thought Is this all suppose to be due lack of core numbers?
So, I have turned on the HyperThreading, made 20 cores, and gave 18 tx corse:
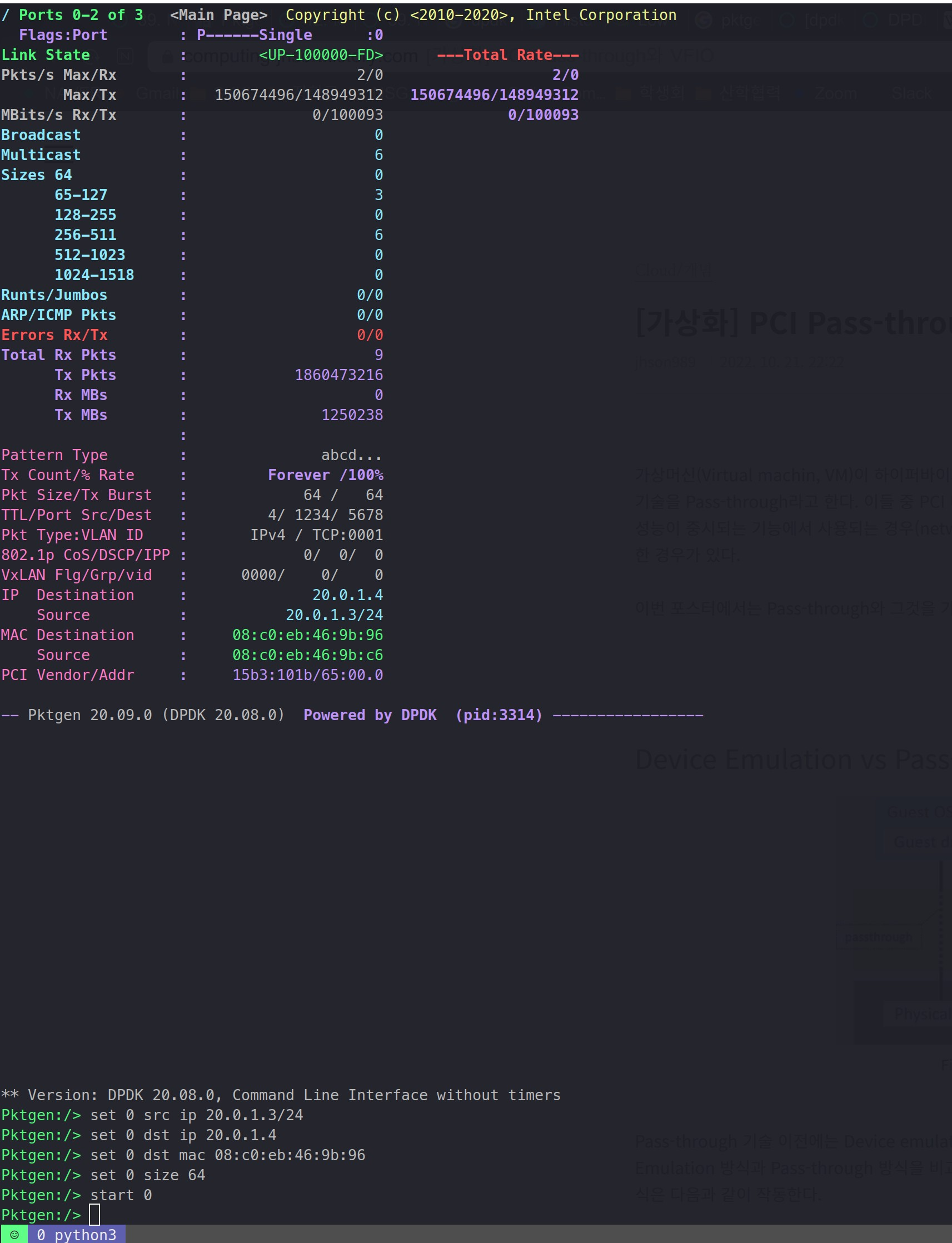
We can see that with 18 cores, 100G, the line rate was filled.
With that being said, I had to find out the minimum amount of cores needed for host and VM to fill the line rate.
< 64byte line rate >
HOST: 11 tx cores
VM : 14 tx cores
4. CPU Interference
From What I have found, VM shares CPU with the host, and when the number of cores per VM's sum exceed the host's number of cores, VMs will share cores.
Also, I have learned that:
- KVM: VMs try to spread the running CPUs, but when cores number exceed, they write in turns. Can be extremely slow depending on the scheduling technique.
- According to 1, if there are 10 physical cores, VM1-3 and VM2-5, each will spin on a different CPU. However, the CPU usage with the Host may overlap.
- Hyperthreading: Two threads share a physical core. In the case of vector operation, the performance of each thread is about 0.5 cores, but in the case of int and float operation, the performance can be 0.8 to 0.9 cores per thread. But the latency interference is big here too.
Thus, to lower CPU Interference, I had to link the VM's cores with physical cores. Before doing that, I had to first understand the performance per core:
<64byte Packet>
tx:11/rx:1 | 88G (VM 13 cores)
tx:12/rx:1 | 97G (VM 14 cores)
tx:13/rx:1 | 98G (VM 15 cores)
tx:14/rx:1 | 100G (VM 16 cores)
<512byte Packet>
tx:2/rx:1 | 100G (VM 4 cores)
tx:3/rx:1 | 98G (VM 5 cores)
tx:4/rx:1 | 100G (VM 6 cores)
Because we had 20 cores, we set to allocate 14 corse for VM1 (to do 64byte packet), 4 cores to VM2 (to do 512byte Packet) and have the host use 2 corse ( 14 + 4 + 2 = 20)
With that being said, corse were linked as below:
VM1:
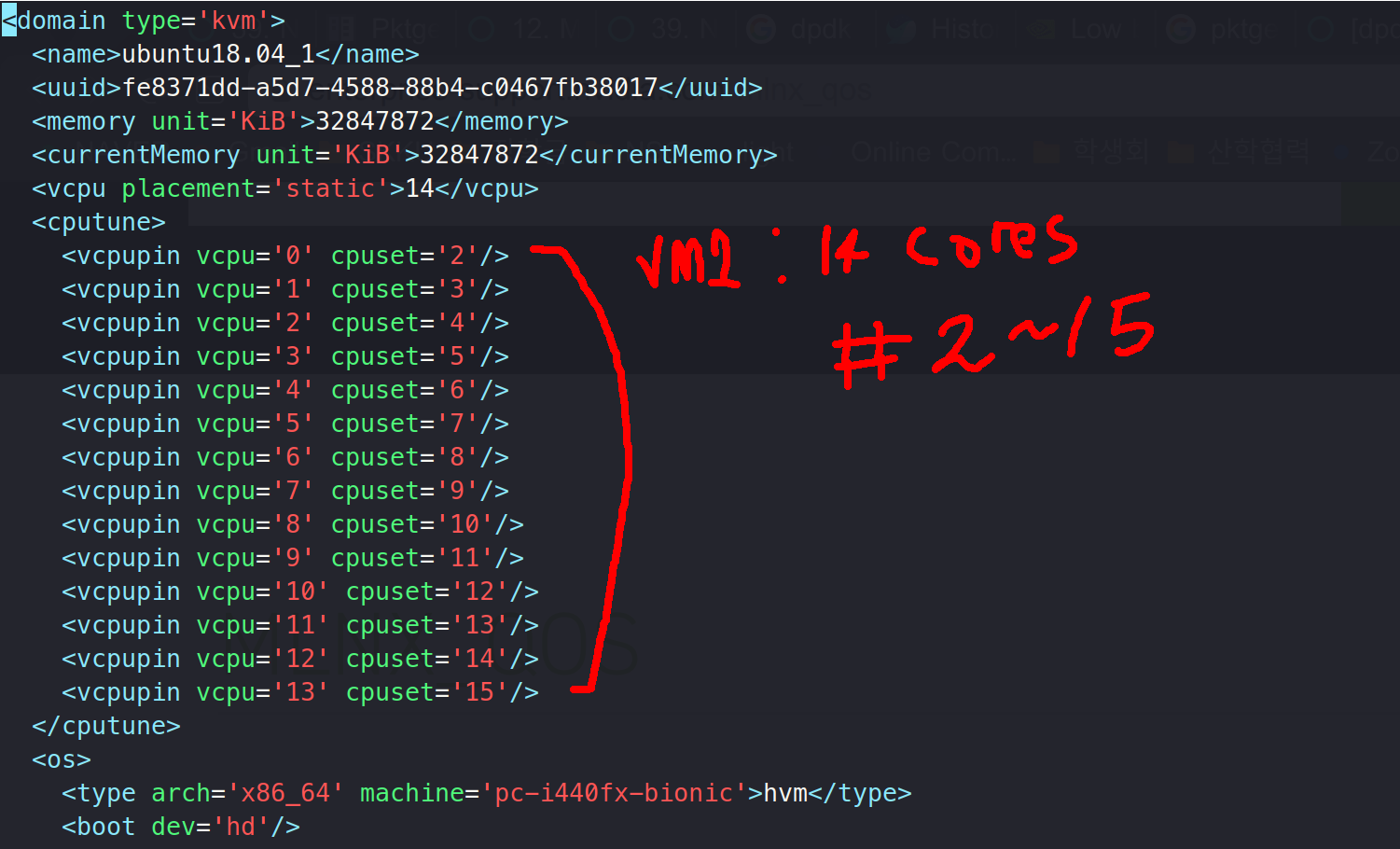
VM2: