ImageNet Classification with Deep Convolutional Neural Networks(Alexnet)
Classification(Paper)

논문 제목 : ImageNet Classification with Deep Convolutional Neural Networks
논문 링크 : https://proceedings.neurips.cc/paper/2012/file/c399862d3b9d6b76c8436e924a68c45b-Paper.pdf
첫 논문 리뷰이다. 이제 막 읽게 되어 시간이 조금 걸리긴 했으나 9페이지(끝에 주석 페이지를 빼면 실질적으로 8페이지)뿐이라 그래도 금방 읽은 것 같다. 기본 배경지식을 쌓고 보니 술술 읽힌 것 같다.
의의
CNN Architecture를 사용해 ILSVRC에서 정확도를 획기적으로 높이며 주목을 받은 중요한 논문이다. 이전까지는 SVM과 같은 비-딥러닝 방식이 우세했으나 본격적으로 컴퓨터 비전에 딥러닝이 유용함을 보여준 첫 시작이라 볼 수 있다.
Dataset
ImageNet은 22,000개의 카테고리가 넘는 1500만개의 이미지가 있는 방대한 자료이다. 여기서는 ImageNet의 subset인 1000개의 카테고리만 사용했다. 각 카테고리에는 대략 1000개의 이미지가 있어 총 이미 120만개만 사용했고, validation image는 5만개, testing image는 15만개 사용했다.
ImageNet은 해상도가 다른 이미지 이므로 256x256으로 down sample했다. 직사각형은 central 256x256 patch를 잘라 사용했다. Training set의 mean activity를 뺀 것 외에는 다른 전처리는 없다(centered raw RGB를 사용함).
Architecture
기본적 구조는 5개의 convolution layer와 3개의 fully-connected layer이다. 이 외에도 구별되는, 가장 중요한 architecture feature가 몇 가지 있다.
ReLU
기존에는 활성화 함수로 tanh나 sigmoid와 같은 saturating nonlinearities 사용했으나 이 대신 ReLU(Rectified Linear Units, non-saturating nonlinearity)를 사용했다.
여기서 saturating nonlinearity는 x가 무한대로 가면 어떤 범위내에서만 움직이는 비선형 함수를 의미한다.
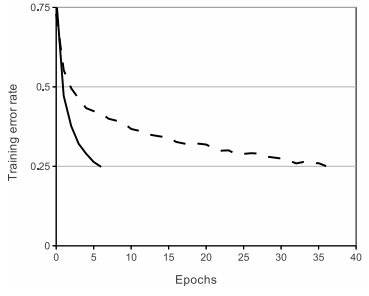
ReLU를 사용한 이유이다. 경사하강법 사용 시 수렴이 ReLU가 훨씬 빠르다. 위 그래프는 점선이 tanh, 실선이 ReLU이다. 각각 최대한 빠르게 수렴하는 learning rate를 사용했고, 그 결과 ReLU가 0.25 error에 훨씬 빨리 수렴하는 것을 볼 수 있다.
빠른 수렴이 큰 dataset에서 큰 model 학습을 가능케했다.
Training on Multiple GPUs
지금과 달리 그때는 GPU의 메모리가 한정적이어서 학습 가능한 크기가 제한적이었다. 따라서 cross-GPU parallelization을 통해 분산 학습을 진행했다. 예를 들어 layer 3의 kernel은 layer 2의 모든 kernel을 input으로 받지만, layer 4의 kernel은 오직 같은 GPU에 있는 layer 3 kernel만을 받아들인다.
Local Response Normalization
지금은 Batch Normalization에 밀려 거의 쓰이지 않는 기술이지만, 이 논문에는 해결책으로 소개되었다.
ReLU는 saturating(포화 상태)을 막기 위해 input normalization이 필요 없다. 그렇지만 local normalization이 generalization에 도움이 됨을 확인했다.
수식은 다음과 같다.
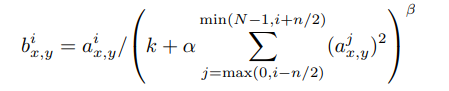
여기서 는 (x,y) position에서 kernel i를 적용했을때 neuron의 활성화 정도이다.
이 수식을 간략하게 해석해보자면 n의 범위만큼(min, max 범위는 넘지 않게) activation을 계산해서(몇 가지의 추가적 계산이 있지만) 나눠주는 것이다. 즉 직관적으로 높은 활성화도를 가진 픽셀이 있다면 그 값을 줄여준다.
이는 값이 매우 높은 한 픽셀이 Conv 또는 Pooling 계산에서 주변에 큰 영향주는 것을 방지하기 위해서이다. 이를 lateral inhibition(측면 억제)라 한다.
여기서 하이퍼파라미터 값은 를 사용했다. 이 normalization은 특정 레이어에서 ReLU 후에 적용되었다.
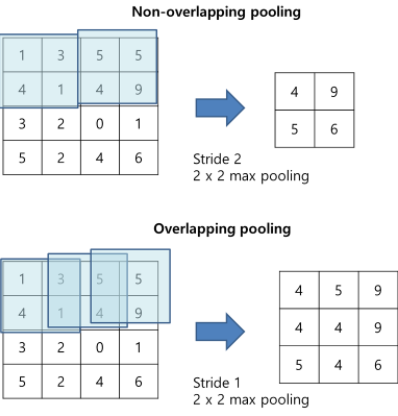
Overlapping Pooling
기존의 max-pooling은 overlapping 없이 했지만 여기서는 overlapping을 했다(s=2, z=3, s는 떨어진 젇오이고 z는 pooling unit 크기). Overfit 방지에 도움이 된다고 한다.
Overall Architecture
전반적 구조는 다음과 같다.
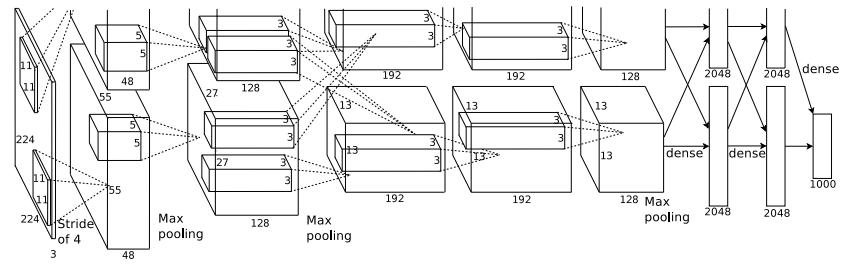
3번째 convolutional layer가 2번째 layer의 모든 input이 포함된걸 빼면 크게 어렵지 않다. 현대와는 달리 그때는 메모리 부족으로 어쩔 수 없었다. 5개의 convolutional layer, 3개의 fully connected layer, 그리고 1000개 class를 분류하는 softmax layer로 구성되어 있다.
여기서 눈여겨볼 이상한 숫자가 있다. Input image size가 227x227x3이다. 앞서 말한대로라면 256x256x3이어야 할텐데 왜 이럴까? 이는 바로 Data Augmentation 때문이다. 아래에 자세히 설명한다.
+) 아니 논문에는 224x224라는데 왜 227x227인가요? 왜냐하면 논문 저자들이 추후에 224가 오타라고 인정했기 때문이다.. 실제로 모델 그림을 보면 첫번째에서 224x224 라 가정할 시, 이고, 227x227로 하면 이다.
Reducing Overfitting
당시에는 이정도면 아주 깊은 model이기에 overfitting이 발생했다. Image에서 label로 mapping할 때 10bits의 제한을 두지만, 이 architecture가 6000만 parameter로 구성되어 있기에 overfitting 방지에는 역부족이었다. 따라서 아래의 방법들로 overfitting을 해결하고자 했다.
Data Augmentation
앞서 input image size가 이상한 이유는 바로 이것 때문이다. 이 방법은 CPU에서 python code로 했고, GPU에서 이전 batch 학습 시 사용되었기에 실질적 computation 비용이 free이다.
먼저 227x227 patch들로 잘라서 총 2048배 증강을 이뤄냈고, 거기에 좌우반전을 통해 최종적으로 4096배로 데이터를 키울 수 있다. 테스트에는 5개의 227x227 patch(상하좌우 모서리 + center)를 좌우반전해서 총 10개의 patch로 테스트한 뒤에 이를 평균냈다.
두번째는 PCA이다. 전체 ImageNet training set을 걸쳐 RGB 픽셀값에 PCA를 수행한다.

그리고 위의 공식을 통해 이미지에 위 값을 더해주어 데이터 증강을 이뤄냈다. 이 부분이 이해가 잘 안될 수 있다. 그때는 https://www.youtube.com/watch?v=27GFJ5Vs-r8 이 영상을 참고하자.
Dropout
Dropout은 overfitting 방지에 아주 유용하다. 여러 architecture를 앙상블하는 것과 동일한 효과를 내기 때문이다. 또 각 뉴런이 서로에게 의지하지 않아 robust한 model을 만들 수 있다.
여기서는 probability 0.5를 사용했고, 테스트에는 전체 출력값에 0.5를 곱해 사용했다.
Details of learning
Batch size는 128, momentum은 0.9를 사용했고 가중치 감소는 0.0005를 사용했다. 작게 감소하는게 model training error 감소에 도움이 되었다고 한다.
가중치 초깃값은 Gaussian Distribution(0, 0.01)을 사용했다(이때는 Xavier값이 없었다). Bias는 2, 4, 5번째 convolutional layer에서 1로, 나머지는 0으로 설정했다. 1로 설정하면 ReLU가 positive input을 갖도록 보장할 수 있어서 도움이 된다고 한다.
모든 layer에서 같은 learning rate를 사용했다고 한다. 초깃값은 0.01이고 Validation error가 안 나아진다면 10으로 나눴다고 한다. 3번 감소가 있었다고 한다.
총 90 cycle 학습했다.
구현
먼저 AlexNet 구현이다. 비교적 간단하다.
class AlexNet(nn.Module):
def __init__(self, num_classes = 1000):
super().__init__()
# CNN layers
self.layers = nn.Sequential(
# conv1
nn.Conv2d(in_channels=3, out_channels=96,kernel_size=11, stride=4),
nn.ReLU(inplace=True), # inplace True means change input value as ReLU value
nn.LocalResponseNorm(size=5, alpha=0.0001, beta=0.75, k=2), # used same parameter in paper
nn.MaxPool2d(kernel_size=3, stride=2),
# conv2
nn.Conv2d(in_channels=96, out_channels=256, kernel_size=5, stride=1, padding=2),
nn.ReLU(inplace=True),
nn.LocalResponseNorm(size=5, alpha=0.0001, beta=0.75, k=2),
nn.MaxPool2d(kernel_size=3, stride=2),
# conv3
nn.Conv2d(in_channels=256, out_channels=384, kernel_size=3, stride=1, padding=1),
nn.ReLU(inplace=True),
# conv4
nn.Conv2d(in_channels=384, out_channels=384, kernel_size=3, stride=1, padding=1),
nn.ReLU(inplace=True),
# conv5
nn.Conv2d(in_channels=384, out_channels=256, kernel_size=3, stride=1, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
)
# FC layers
self.classifier = nn.Sequential(
# fc1
nn.Dropout(p=0.5),
nn.Linear(in_features=(256*6*6), out_features=4096),
nn.ReLU(inplace=True),
# fc2
nn.Dropout(p=0.5),
nn.Linear(in_features=4096, out_features=4096),
nn.ReLU(inplace=True),
nn.Linear(in_features=4096, out_features=num_classes),
)
# initialize bias, weight
def init_bias_weights(self):
for layer in self.layers:
if isinstance(layer, nn.Conv2d): # if layer is Conv
nn.init.normal_(layer.weight, mean=0, std=0.01) # Gaussian Distribution with (0, 0.01)
nn.init.constant_(layer.bias, 0) # default=0, 1 for 2, 4, 5, FC
# conv2, 4, 5 bias for 1
nn.init.constant_(self.layers[4].bias, 1)
nn.init.constant_(self.layers[10].bias, 1)
nn.init.constant_(self.layers[12].bias, 1)
# FC bias for 1
nn.init.constant_(self.classifier[1].bias, 1)
nn.init.constant_(self.classifier[4].bias, 1)
nn.init.constant_(self.classifier[6].bias, 1)
def forward(self, x):
x = self.layers(x)
x = torch.flatten(x, 1)
return self.classifier(x)
"""
----------------------------------------------------------------
Layer (type) Output Shape Param #
================================================================
Conv2d-1 [-1, 96, 55, 55] 34,944
ReLU-2 [-1, 96, 55, 55] 0
LocalResponseNorm-3 [-1, 96, 55, 55] 0
MaxPool2d-4 [-1, 96, 27, 27] 0
Conv2d-5 [-1, 256, 27, 27] 614,656
ReLU-6 [-1, 256, 27, 27] 0
LocalResponseNorm-7 [-1, 256, 27, 27] 0
MaxPool2d-8 [-1, 256, 13, 13] 0
Conv2d-9 [-1, 384, 13, 13] 885,120
ReLU-10 [-1, 384, 13, 13] 0
Conv2d-11 [-1, 384, 13, 13] 1,327,488
ReLU-12 [-1, 384, 13, 13] 0
Conv2d-13 [-1, 256, 13, 13] 884,992
ReLU-14 [-1, 256, 13, 13] 0
MaxPool2d-15 [-1, 256, 6, 6] 0
Dropout-16 [-1, 9216] 0
Linear-17 [-1, 4096] 37,752,832
ReLU-18 [-1, 4096] 0
Dropout-19 [-1, 4096] 0
Linear-20 [-1, 4096] 16,781,312
ReLU-21 [-1, 4096] 0
Linear-22 [-1, 1000] 4,097,000
================================================================
Total params: 62,378,344
Trainable params: 62,378,344
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 0.59
Forward/backward pass size (MB): 14.73
Params size (MB): 237.95
Estimated Total Size (MB): 253.27
----------------------------------------------------------------
None
"""이제 직접 학습을 시켜볼 차례이다. 물론 ImageNet을 사용하면 정말 좋겠지만 학습 여건 상 돌려놓으면 아마 전역할 때 확인할 수 있을 것 같아 CIFAR-10을 사용했다. Image Augmentation(Patch, Flip, PCA)는 적용하지 않았다.
train = datasets.CIFAR10(root='data',
train=True,
download=True,
transform = transforms.ToTensor()
)
import numpy as np
def print_stats(dataset):
imgs = np.array([img.numpy() for img, _ in dataset])
mean_r = np.mean(imgs, axis=(2, 3))[:, 0].mean()
mean_g = np.mean(imgs, axis=(2, 3))[:, 1].mean()
mean_b = np.mean(imgs, axis=(2, 3))[:, 2].mean()
std_r = np.std(imgs, axis=(2, 3))[:, 0].std()
std_g = np.std(imgs, axis=(2, 3))[:, 1].std()
std_b = np.std(imgs, axis=(2, 3))[:, 2].std()
print(f'mean: {mean_r, mean_g, mean_b}')
print(f'std: {std_r, std_g, std_b}')
return mean_r, mean_g, mean_b, std_r, std_g, std_b
mean_r, mean_g, mean_b, std_r, std_g, std_b = print_stats(train)먼저 논문대로 mean, std값을 얻어낸다. 그 다음 이 값들로
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((mean_r, mean_g, mean_b),(std_r, std_g, std_b)),
transforms.Resize((227, 227))
])
trainset = datasets.CIFAR10(root='data',
train=True,
download=True,
transform=transform)
testset = datasets.CIFAR10(root='data',
train=False,
download=True,
transform=transform)
trainloader = data.DataLoader(trainset, batch_size=batch_size, shuffle=True)
testloader = data.DataLoader(testset, batch_size=batch_size, shuffle=True)데이터를 변환해준다. ToTensor, Normalize(얻어낸 값으로), 그리고 원하는 이미지 크기인 227x227로 resize.
이제 데이터가 잘 변환되었는지 살펴보자.
import matplotlib.pyplot as plt
def show_one_image(img):
img = img.numpy()
plt.imshow(np.transpose(img, (1, 2, 0)))
plt.show()
inputs, classes = next(iter(trainloader))
idx_to_name = {
0: 'airplane',
1: 'automobile',
2: 'bird',
3: 'cat',
4: 'deer',
5: 'dog',
6: 'frog',
7: 'horse',
8: 'ship',
9: 'truck'
}
titles = [idx_to_name[classes[i].numpy().item()] for i in range(10)]
plt.figure(figsize=(20,20))
for i in range(10):
img = inputs[i].numpy()
plt.subplot(5, 5, i+1)
plt.title(titles[i])
plt.imshow(np.transpose(img, (1, 2, 0)))
plt.axis('off')
plt.show()
와우! 잘된걸 확인할 수 있다. 여기서 이미지 normalize와 resize를 거치며 흐릿하고 알아보기 힘들지만 대략적으로 title과 이미지가 잘 맞다.
https://github.com/Parkyosep/Paper/tree/main/AlexNet
전체 코드는 Github에 있습니다~~.
