
📘 프로젝트 개요
프로젝트 기간 : 2021.11-2021.12
사용언어 및 프레임워크 : C, OpenCL
깃허브 : 2021_2_muticore
학습모델 : VGG16 (CNN)
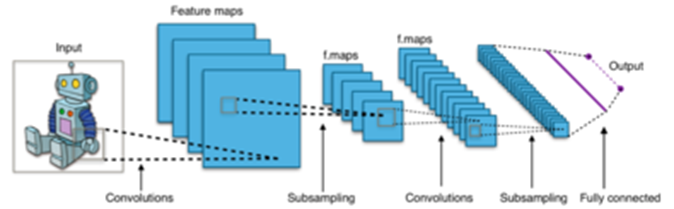 일반적인 CNN(Convolutional Neural Network)의 구조
일반적인 CNN(Convolutional Neural Network)의 구조
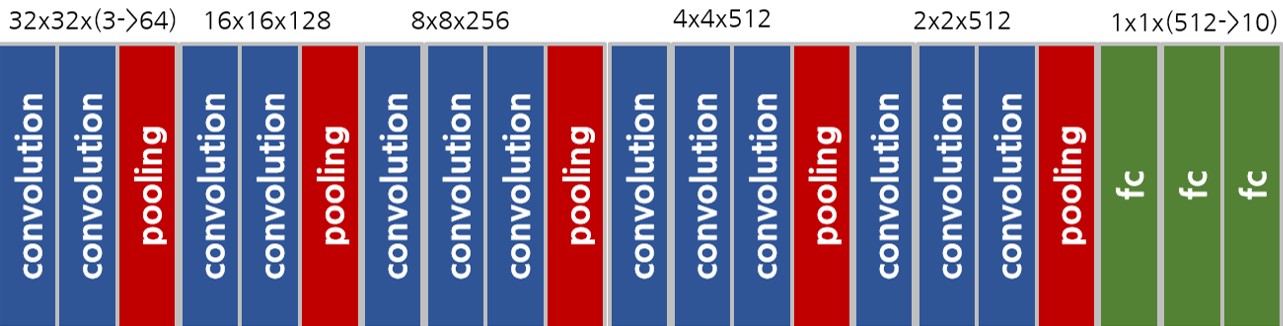
본 프로젝트에서 사용되는 VGG16 모델의 구조
⬛데이터셋 : CIFAR

📃 초기계획
⬜ CPU 실행 시간
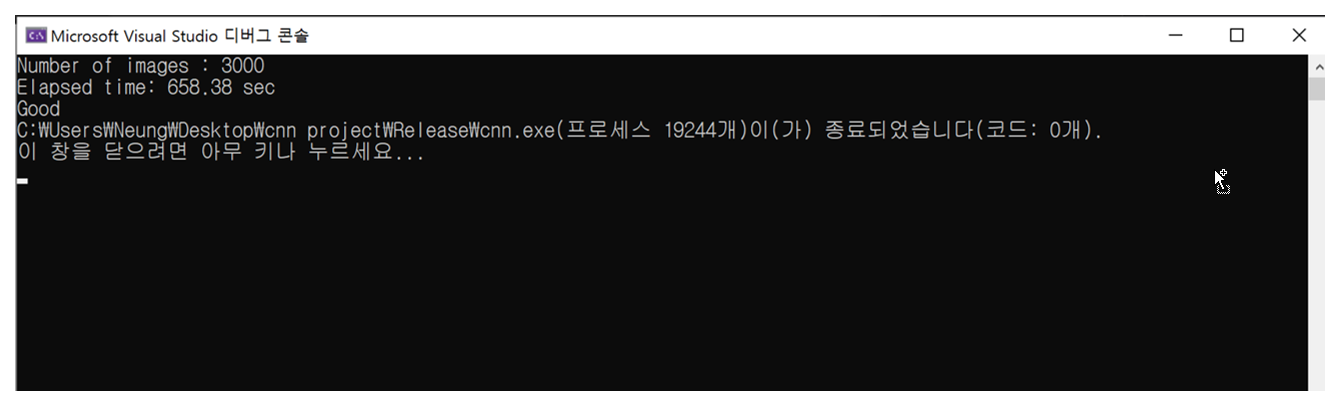
샘플로 주어진 seq코드를 활용해 3000개의 이미지에 대한 분류를 CPU에서 실행해 보았을 땐 대략 660초 정도의 시간이 소요되었다. 최종적으로 두 자릿수 내외의 실행시간을 목표로 설정했다.
CPU - AMD Ryzen 5 3600 6core 12thread, RAM - 16GB,
GPU - Nvidia GeForce GTX 1060 3GB
⬜ 병렬화 계획
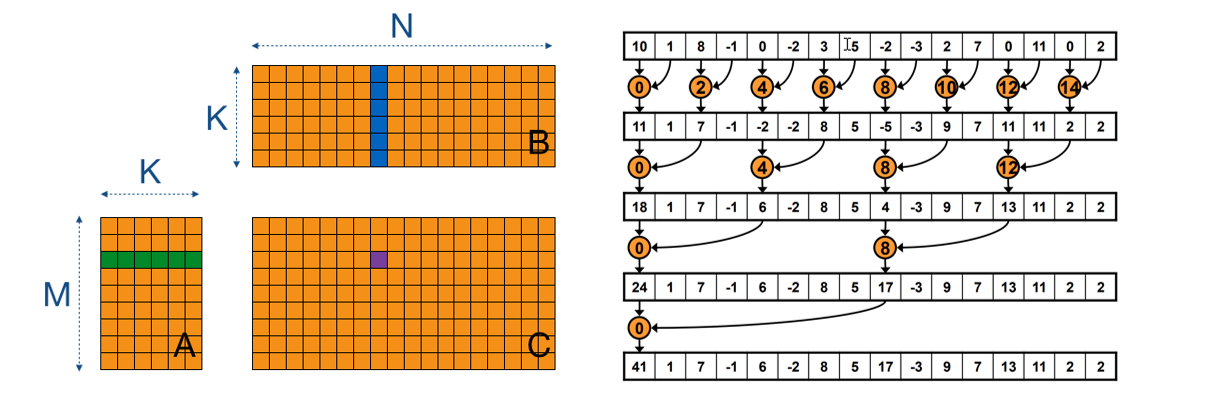
convolution layer 가 모델 연산 내에서 가장 많은 비중을 차지하기에 우선적으로 병렬화 할 계획이다. input 에 weigh를 곱해 output으로 만드는 과정을 위해 matrix multiplication을 활용하고 이 곱들을 합쳐주는 과정을 위해 local memory를 바탕으로 한 reduction을 활용할 계획이다.
🚀 프로젝트 수행
[1] 에러
한번 돌리고 끝나는 코드가 아니기 때문에 메모리 부분에서 에러가 발생했다. 에러 해결을 위해 cl 오브젝트를 전역변수로 선언해주고 clRelease 함수를 활용해 다 쓴 메모리를 해제하도록 하였다.
[2] convolution layer 병렬화
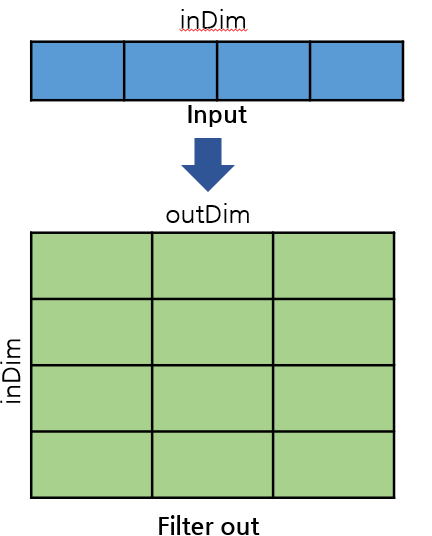
convolution layer에서 Input를 필터에 통과시키는 부분을 병렬화 하였다. 커널의 input는 inDimoffset이고 output은 inDimoutDim*offset이다. 이 병렬화를 모든 convolution layer에 적용했을 때 소요된 시간은 337초 정도로, 660초 였던 CPU의 절반이었다. 약 2배정도의 성능 향상을 이루어 냈다고 볼 수 있다.
[3] convolution sum 병렬화
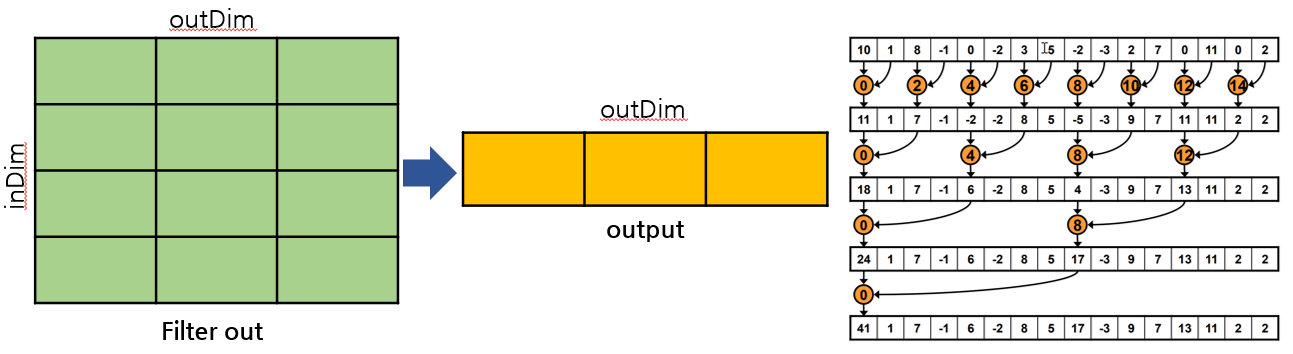
convolution layer에서 필터를 통과한 데이터들을 합쳐주는 부분을 병렬화 했다. inDimoutDimoffset 였던 filter out값에서 inDim을 local size로 설정하여 reduction sum을 진행하였다. 결과적으로 outDim*offse의 output값을 출력하게 된다. 이것을 모든 convolution layer에 적용하였을 때 실행 시간은 200초가 되었다. 660초에서 1/3인 200초가 되었으니 약 3배정도의 성능 향상을 이뤘다고 볼 수 있다.
[4] pooling, fc, ReLU 병렬화
ReLU는 간단한 함수이기에 기존의 convolution sum 커널 안에 구현하였다. Pooling은 4개의 인자 밖에 참조하지 않기 때문에 특별한 병렬 기법을 사용하지 않고 글로벌 메모리를 접근하도록 놔두었다.
fc layer는 convolution layer와 구조가 유사하기에 필터를 통과시키는 커널과 필터에서 나온 것들을 더해주는 커널을 합쳐서 구성했다.
이러한 부분들은 프로그램 에서 큰 비중을 차지하지 않고 특별한 병렬화 기법을 활용한 것이 아니기에 성능은 향상되지 않았다. 그럼에도 이렇게 모든 레이어들을 병렬화 한 이유는 뒤에 나올 batch화 때문이다.
[5] batch
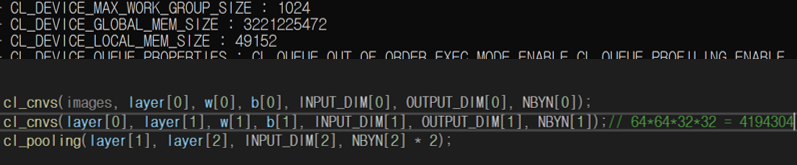
내 컴퓨터에서 사용 가능한 global memory size는 3221225472였지만 이미지 1개를 convolution할 때 최대로 사용하는 메모리의 크기는 646432*32=4194304였다. 사용되지 않는 메모리가 훨씬 많았기에 한 번에 여러 이미지를 처리하면 더욱 향상된 성능을 기대할 수 있을 것 같아 cnn의 개념 중 하나인 batch를 도입하였다.
이를 위해 앞선 부분에서 모든 레이어를 병렬화(성능은 향상되지 않는) 하였다.각 레이어와 커널의 global, local memory에 batch 차원을 추가해주었다. cnn() 의 for문을 한 번 돌 때 마다 이용자가 설정하는 만큼의 이미지를 처리할 수 있도록 하였다. BATCH 값을 5에서 150까지 적용해 보았을 때 나의 데스크탑 컴퓨터 에서는 30일 때 가장 좋은 성능을 보였다. BATCH가 30일 때 71~72초의 실행시간이 나오며 660초에서 약 1/9의 시간만이 소요되었다. 결과적으로 9배의 성능 향상을 이뤄냈다.
📊 결과
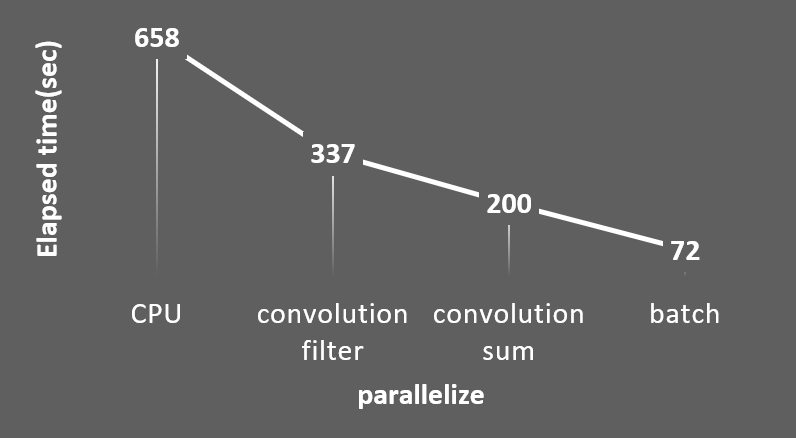
Convolution에서 input데이터를 가중치 필터를 통과 시킬 때 matrix multiplication개념을 활용해 병렬화를 하였다. 그 이후 filter out데이터를 output로 합치기 위해 local memor접근을 통한 reduction sum을 활용해 병렬화 하였다. 이를 통해 1, 2차적인 성능 향상을 이루어 냈다. ReLU, pooling, fc도 병렬화 하였다. 이부분은 병렬화를 해도 성능 향상이 일어나지 않았지만 batch를 활용하기 위해 모든 레이어를 병렬화 하였다. 마지막으로 딥러닝의 batch를 활용해 데이터 흐름을 개선하여 최종적인 성능 향상을 이루어 냈다. 이 과정에서 타일링은 활용하지 못했다.
CPU로 sequential하게 실행한 658초에서 최종적으로 병렬화를 통해 72초가 되어 약 9배의 성능 향상을 이끌어 냈다.
💾 References
cnn 이미지 : https://en.Wikipedia.org/wiki/Convolutional_neural_network
CIFAR-10 이미지 : https://paperswithcode.com/dataset/cifar-10
matrix multiplication 이미지 : https://cnugteren.github.io/tutorial/pages/page2.html
reduction 이미지 : https://developer.download.nvidia.com/assets/cuda/files/reduction.pdf
