1. 셀프 주유소가 정말 저렴할까?
-
가져와야 할 데이터(14개)
주유소 이름, 주소, 브랜드(상호명), 휘발유 가격, 경유 가격, 셀프 여부, 세차장 여부, 충전소 여부, 경정비 여부, 편의점 여부, 24시간 운영 여부, 구, 위도,경도
2. selenium 을 활용한 크롤링
- 과제에서는 엑셀 파일이 아닌, 크롤링 코드로 데이터 수집
- 페이지 접근 'https://www.opinet.co.kr/searRgSelect.do'
- 서울 선택 (고정)
- 구별 선택
- 서울시 구별 주유소 데이터 수집
- 전체 데이터 수집
- 데이터 프레임 저장
2-1 페이지 접근
from selenium.webdriver import ActionChains
from selenium.webdriver.common.by import By
from selenium import webdriver
url = 'https://www.opinet.co.kr/searRgSelect.do'
driver = webdriver.Chrome('./driver/chromedriver.exe')
driver.get(url)2-2 서울 선택(고정)
# 시/도 선택
sido_select = driver.find_element(By.CSS_SELECTOR, value="#SIDO_NM0")
#or(By.ID, 'SIDO_NM0')
# '서울' 입력
sido_select.send_keys('서울')2-3 구별 선택
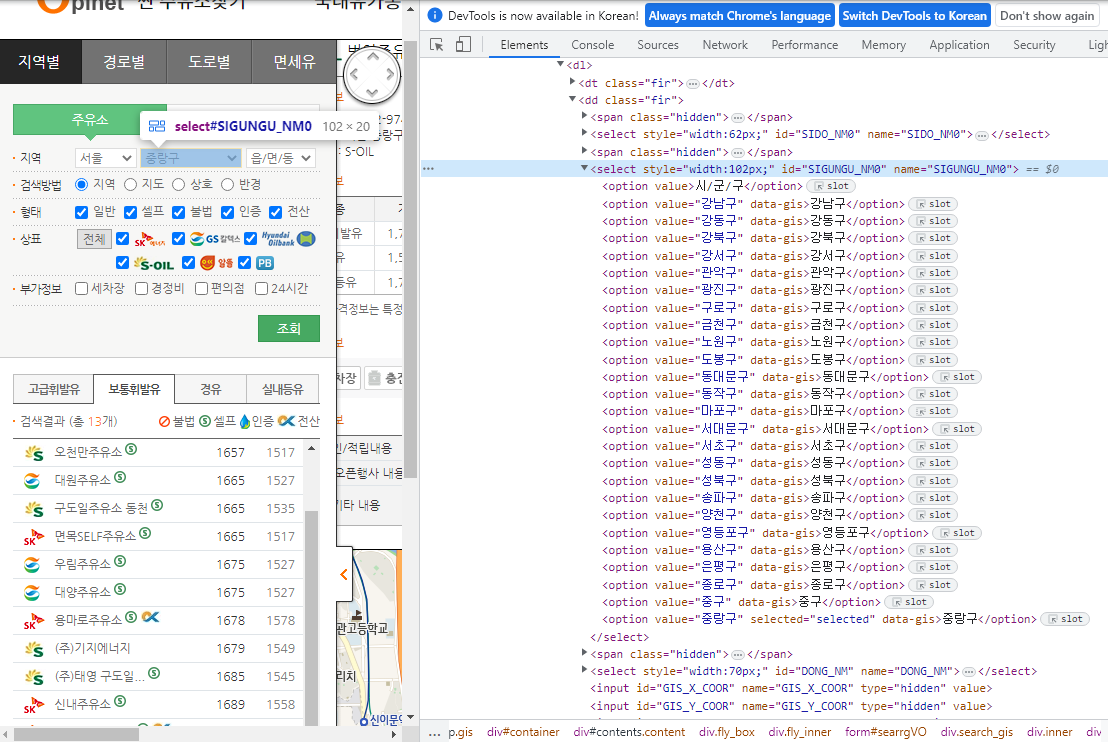
# 기존 유가 분석 강의에서 가져옴
# 서울의 구 목록 가져오기
# 지역: 구
# 지역관련 html 에 id 가 모두 있다 id = 'SIGUNGU_NM0'
# 우리나라 시/도 목록을 가져오려면,
# 목록을 포함하고 있는 부모 태그를 가져와서 해당 목록을 가져온다
# id 로 해당 목록을 가져온다
gu_list_raw = driver.find_element(By.ID, value="SIGUNGU_NM0") # 부모태그
# html 에서 option 태그를 기준으로 가져온다
# 여러개 가져오므로 find_elements 이다.
gu_list = gu_list_raw.find_elements(By.TAG_NAME, value="option") # 자식태그
# gu_names = []
# for option in gu_list:
# gu_names.append(option.get_attribute("value"))
# 한줄로 작성
# gu_names = [option.get_attribute("value") for option in gu_list]
# gu_names = gu_names[1:] # 첫번째가 빈값이어서 두번째 값부터 넣음
# 공백 제거까지 한번에
gu_names = [option.get_attribute("value") for option in gu_list if option.get_attribute('value')]
gu_names[:5], len(gu_names)
>>
(['강남구', '강동구', '강북구', '강서구', '관악구'], 25)# 원하는 구로 바뀜
# 아래를 두번 실행하면 두번째에서는 에러남
# 근데 위 코드를 실행 후 다시 이 코드를 실행하면 실행됨
gu_list_raw.send_keys(gu_names[0])해결방법
# 개발자도구에서 강남구 부분 copy selector
driver.find_element(By.CSS_SELECTOR, value="#SIGUNGU_NM0 > option:nth-child(2)").text
>> '강남구'
# 0이 없고 1부터 시작한다
# 2부터 강남구 시작(필요한 데이터는 2부터 시작)
driver.find_element(By.CSS_SELECTOR, value="#SIGUNGU_NM0 > option:nth-child(1)").text
>> '시/군/구'
driver.find_element(By.CSS_SELECTOR, value="#SIGUNGU_NM0 > option:nth-child(26)").text
>> '중랑구'구별선택 방법
# 구별 선택 방법 1
# 구별 클릭
# 중랑구 선택
driver.find_element(By.CSS_SELECTOR, value="#SIGUNGU_NM0 > option:nth-child(26)").click()
# 구별 선택 방법 2
# 강남구 선택
driver.find_element(By.CSS_SELECTOR, value='#SIGUNGU_NM0').send_keys('강남구')반복문 테스트
# 서울 고정
# 구별 순환
import time
for i, v in enumerate(gu_names):
# {i+2} : i 가 0부터 시작인데 위에서 강남구는 2부터 시작이므로 +2 를 해줌
# 중괄호:'#SIGUNGU_NM0 > option:nth-child(i+2)'를 i+2 에 포맷팅
gu_selector = f'#SIGUNGU_NM0 > option:nth-child({i+2})'
#태그를 변수로 담음으로써 디버깅까지 생각, 태그 바뀔수도 있으니
driver.find_element(By.CSS_SELECTOR, value=gu_selector).click() 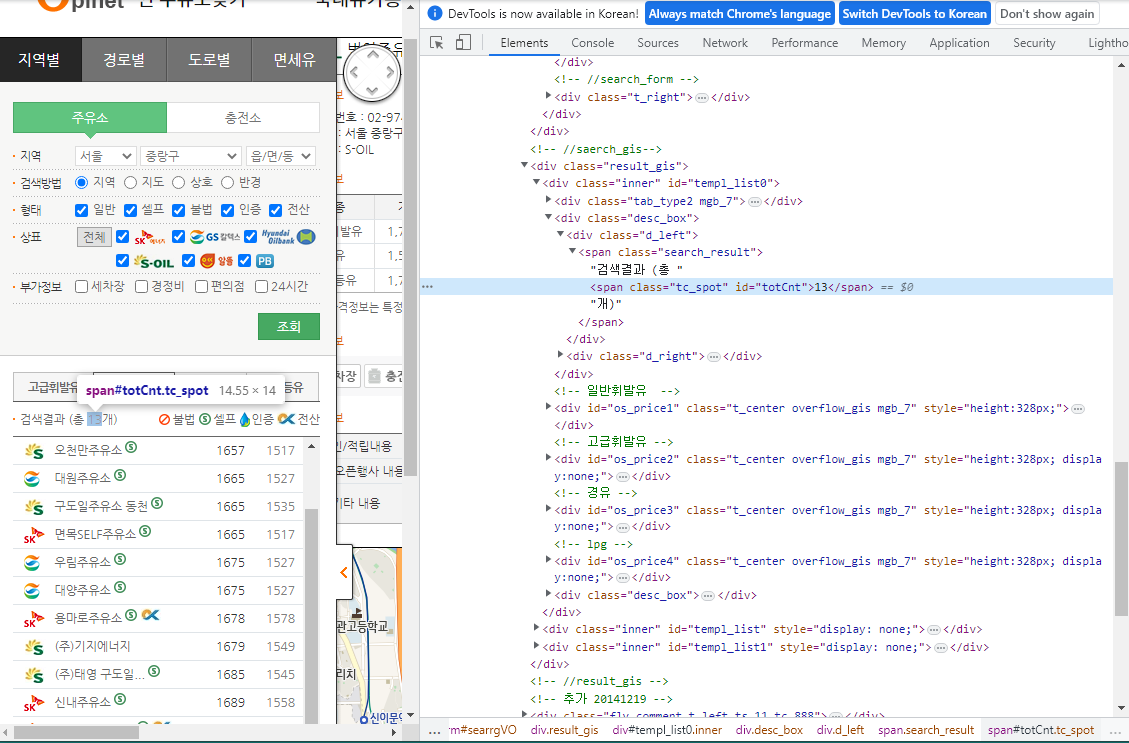
목적에 맞는 데이터를 가져오는지 확인
#중랑구에는 주유소가 13개
#id="totCnt"
#특정구가 선택된 상태에서 아래를 실행하면 해당구에 있는 주유소의 갯수를 가져옴
driver.find_element(By.CSS_SELECTOR, value="#totCnt").text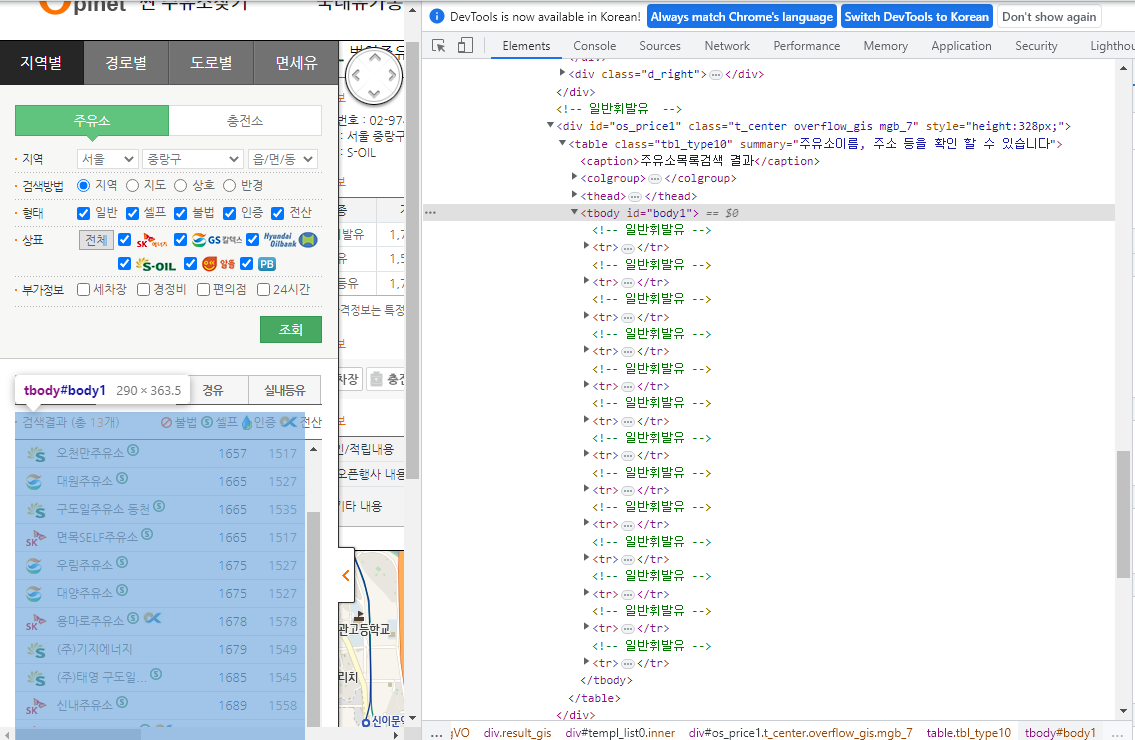
#구별로 주유소의 갯수가 다름, 주유소별 정보는 tbody 태그(id=body1) 밑에 tr 태그임
# 현재 중랑구, 중랑구는 주유소 13개
driver.find_elements(By.CSS_SELECTOR, value='#body1 > tr')
len(.find_elements(By.CSS_SELECTOR, value='#body1 > tr'))
>> 13#홈페이지에 나오는 주유소 갯수와 주유소 정보를 가져와서 확인한 갯수가 같은지 확인
totCnt = driver.find_element(By.CSS_SELECTOR, value="#totCnt").text
totCnt, len(driver.find_elements(By.CSS_SELECTOR, value='#body1 > tr'))
>> ('13', 13)import time
for i, v in enumerate(gu_names):
gu_selector = f'#SIGUNGU_NM0 > option:nth-child({i+2})'
driver.find_element(By.CSS_SELECTOR, value=gu_selector).click()
totCnt = driver.find_element(By.CSS_SELECTOR, value="#totCnt").text
gu_totalCnt = driver.find_elements(By.CSS_SELECTOR, value='#body1 > tr')
print(i, v, totCnt, len(gu_totalCnt))
time.sleep(0.5)
>>
0 강남구 34 34
1 강동구 13 13
2 강북구 12 12
3 강서구 33 33
4 관악구 14 14
5 광진구 13 13
6 구로구 20 20
7 금천구 11 11
8 노원구 14 14
9 도봉구 16 16
10 동대문구 18 18
11 동작구 9 9
12 마포구 11 11
13 서대문구 14 14
14 서초구 30 30
15 성동구 16 16
16 성북구 23 23
17 송파구 29 29
18 양천구 24 24
19 영등포구 27 27
20 용산구 12 12
21 은평구 16 16
22 종로구 9 9
23 중구 10 10
24 중랑구 13 132-4 서울 구별 주유소 데이터 수집
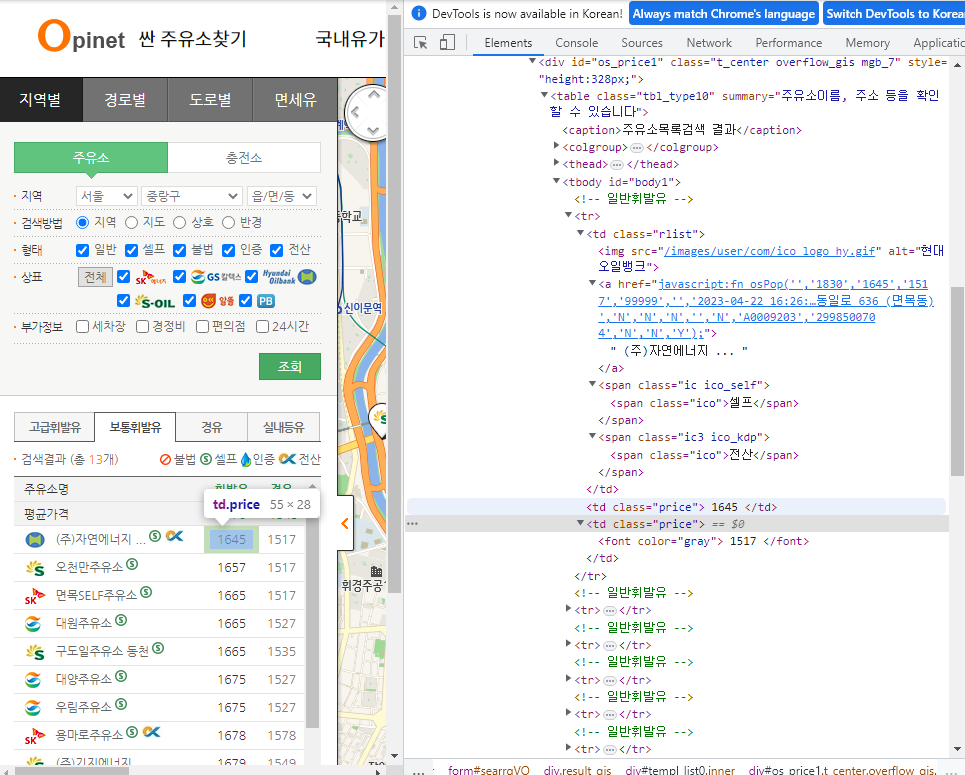
# 데이터 수집 1번째 시도
# 하나의 구에서 데이터 수집 테스트
from selenium.webdriver import ActionChains
from selenium.webdriver.common.by import By
body1 = driver.find_element(By.CSS_SELECTOR, value='#body1')
# 휘발유 가격 가져오기
gas = body1.find_elements(By.CSS_SELECTOR, value= 'td:nth-child(2)')
# copy selector 가 #body1 > tr:nth-child(1) > td:nth-child(2) 인데, 마지막만 넣어줌
# #body1 은 위 body1 에서 지정을 해줬으므로 뺌
# 경유 가격 가져오기
disel = body1.find_elements(By.CSS_SELECTOR, value= 'td:nth-child(3)')
# copy selector 가#body1 > tr:nth-child(1) > td:nth-child(3) 인데, 마지막만 넣어줌
# #body1 은 위 body1 에서 지정을 해줬으므로 뺌
# 브랜드명 가져오기
# rlist 클래스 밑에 img 로 들어감
brand = body1.find_elements(By.CSS_SELECTOR, value= '.rlist img')
# 부가정보(세차장, 경정비, 편의점, 24시간) 가져오기
# copy selector : #body1 > tr:nth-child(1) > td.rlist > span.ic.ico_self > span
is_self = body1.find_elements(By.CSS_SELECTOR, value= 'td.rlist span.ic.ico_self')
# 주유소명 가져오기
# copy selector : #body1 > tr:nth-child(1) > td.rlist > a
name = body1.find_elements(By.CSS_SELECTOR, value= '.rlist a')
# brand[0].get_attribute('alt') # rlist 클래스 밑에 img 로 들어가서 alt 값을 가져옴
# 주유소명이 잘려서 나옴
gas[0].text, disel[0].text, brand[0].get_attribute('alt'), is_self[0].text, name[0].text
>>
('1645', '1517', '현대오일뱅크', '셀프', '(주)자연에너지 ...')
# 숫자를 바꾸면 주유소마다의 정보를 가져온다
gas[3].text, disel[3].text, brand[3].get_attribute('alt'), is_self[3].text, name[3].text
>>
('1665', '1517', 'SK에너지', '셀프', '면목SELF주유소')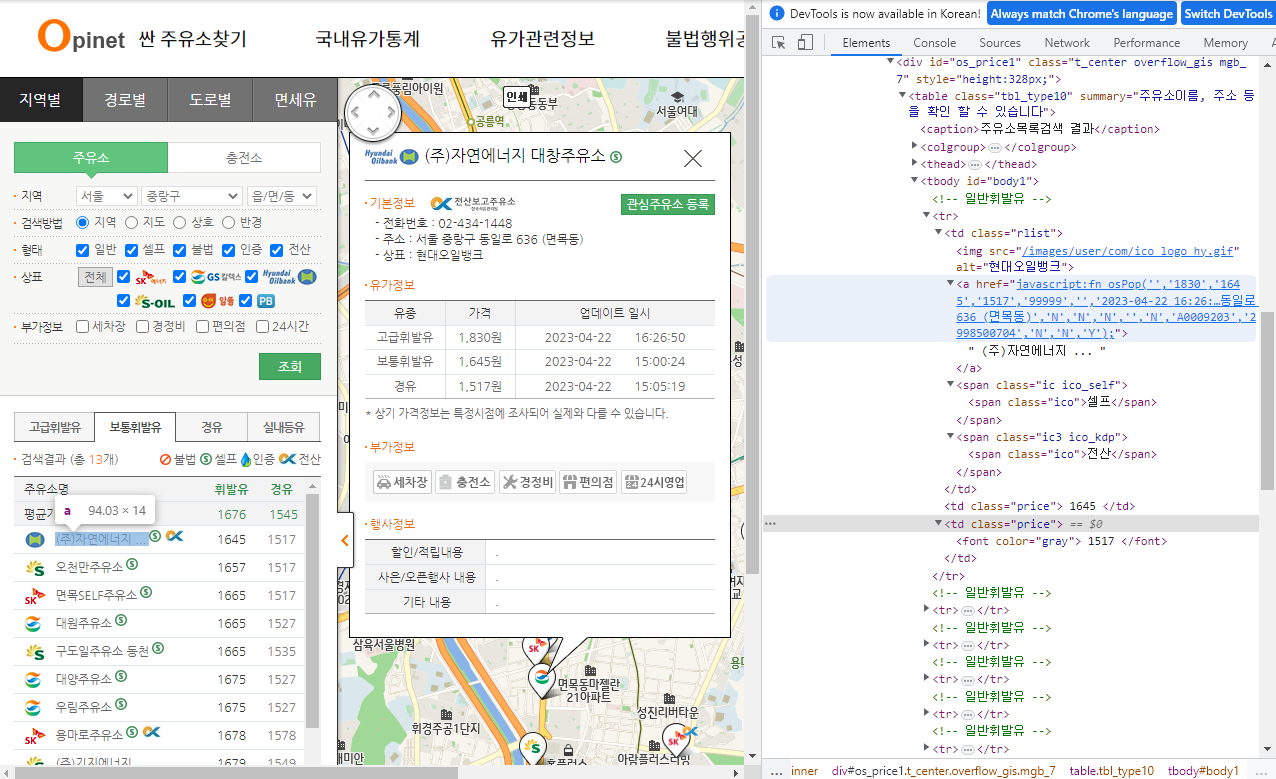
# 데이터 수집 2번째 시도
driver.find_element(By.CSS_SELECTOR, value='#body1 > tr:nth-child(1) > td.rlist > a').click()driver.find_element(By.CSS_SELECTOR, value='.header #os_nm').text
>>
'(주)자연에너지 대창주유소'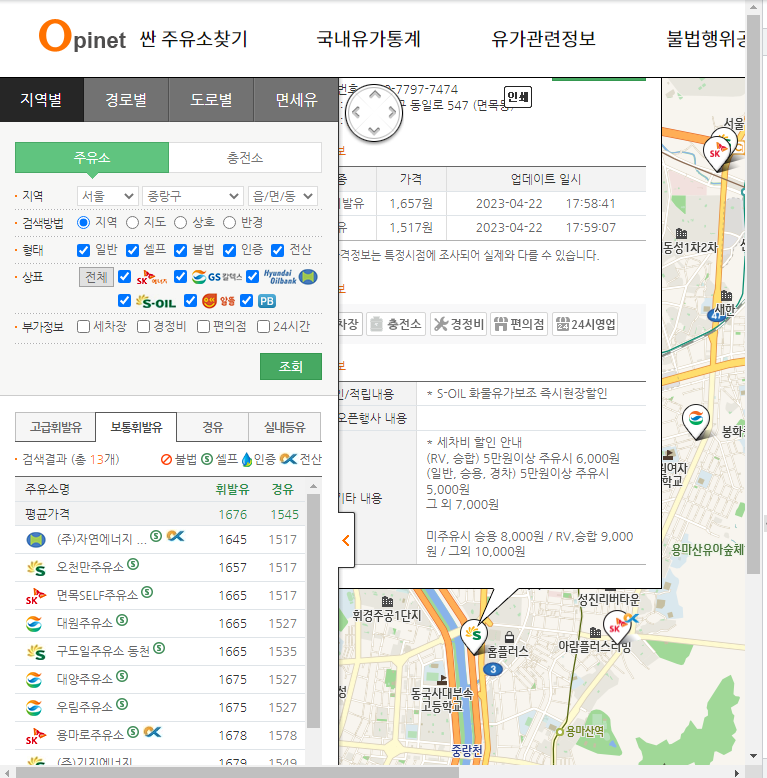

#주유소명 가져오기
#방법 1
driver.find_element(By.CSS_SELECTOR, value='.header #os_nm').text
#방법 2
driver.find_element(By.CSS_SELECTOR, value='.header #os_nm').get_attribute('innerText')
#방법 3
driver.find_element(By.CSS_SELECTOR, value='.header #os_nm').get_attribute('innerHTML')
>>
'오천만주유소'2-4 반복문 테스트
- 3개구에서 3개씩만 가져와보자
#세부페이지(팝업창)에서 주유소명 가져오기
import time
for i in range(0, 3):
gu_selector = f'#SIGUNGU_NM0 > option:nth-child({i+2})'
driver.find_element(By.CSS_SELECTOR, value=gu_selector).click()
for idx in range(0, 3): # 주유소 선택
detail_selector = f'#body1 > tr:nth-child({idx+1}) > td.rlist > a'
driver.find_element(By.CSS_SELECTOR, value=detail_selector).click()
title = driver.find_element(By.CSS_SELECTOR, value='.header #os_nm').get_attribute('innerText')
print(title)
>>
(주)보성 세곡주유소
삼성동주유소
현대오일뱅크 도곡셀프주유소
재건에너지 재정제2주유소 고속셀프지점
구천면주유소
대성석유(주)길동주유소
씨앤에스유통㈜ 미아셀프주유소
덕릉로주유소
북서울고속주유소
#구별로 순회하면서, 세부페이지 주유소 이름 수집
for i, v in enumerate(gu_names[:3]): # 구 선택
gu_selector = f'#SIGUNGU_NM0 > option:nth-child({i+2})'
driver.find_element(By.CSS_SELECTOR, value=gu_selector).click()
station_items = driver.find_elements(By.CSS_SELECTOR, value='#body1 > tr')
print()
print(f'========={v}에는 {len(station_items)}개 주유소가 있습니다==========')
for idx in range(len(station_items))[:3]: # 주유소 선택
detail_selector = f'#body1 > tr:nth-child({idx+1}) > td.rlist > a'
driver.find_element(By.CSS_SELECTOR, value=detail_selector).click()
title = driver.find_element(By.CSS_SELECTOR, value='.header #os_nm').get_attribute('innerText')
print(f'{v} 주유소 이름:', title)
time.sleep(0.5)
>>
=========강남구에는 34개 주유소가 있습니다==========
강남구 주유소 이름: (주)보성 세곡주유소
강남구 주유소 이름: 삼성동주유소
강남구 주유소 이름: 현대오일뱅크 도곡셀프주유소
=========강동구에는 13개 주유소가 있습니다==========
강동구 주유소 이름: 재건에너지 재정제2주유소 고속셀프지점
강동구 주유소 이름: 구천면주유소
강동구 주유소 이름: 대성석유(주)길동주유소
=========강북구에는 12개 주유소가 있습니다==========
강북구 주유소 이름: 씨앤에스유통㈜ 미아셀프주유소
강북구 주유소 이름: 덕릉로주유소
강북구 주유소 이름: (주)석산에너지
2-5 메인데이터 수집
# 메인 데이터 수집
name = title = driver.find_element(By.CSS_SELECTOR, value='.header #os_nm').get_attribute('innerText')
gasoline = driver.find_element(By.CSS_SELECTOR, value='#b027_p').get_attribute('innerText')
disel = driver.find_element(By.CSS_SELECTOR, value='#d047_p').get_attribute('innerText')
address = driver.find_element(By.CSS_SELECTOR, value='#rd_addr').get_attribute('innerText')
brand = driver.find_element(By.CSS_SELECTOR, value='#poll_div_nm').get_attribute('innerText')
name, gasoline, disel, address, brand
>>
('씨앤에스유통㈜ 미아셀프주유소', '1,623', '1,513', '서울 강북구 도봉로 200 (미아동)', 'S-OIL')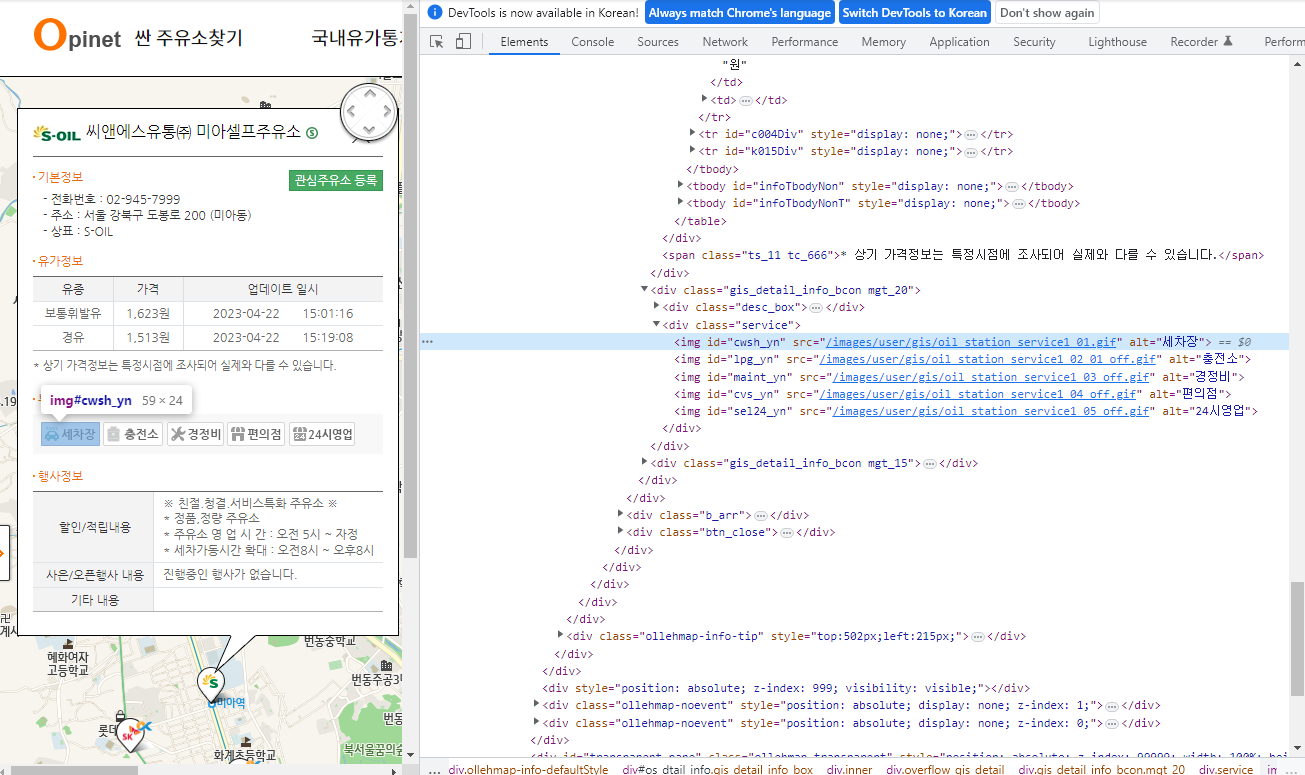
# 부가정보 데이터 수집
# 세차장은 나오는데, 세차장을 하는건지 안하는건지는 알 수 없음
cwsh_yn = driver.find_element(By.CSS_SELECTOR, value='.service #cwsh_yn').get_attribute('alt')
cwsh_yn# 없으면 off 가 들어가있고, 있으면 off 가 없음
# src 를 가져온다
# / 를 기준으로 되어있다
cwsh_yn = driver.find_element(By.CSS_SELECTOR, value='.service #cwsh_yn').get_attribute('src')
lpg_yn = driver.find_element(By.CSS_SELECTOR, value='.service #lpg_yn').get_attribute('src')
cwsh_yn, lpg_yn
>>
('https://www.opinet.co.kr/images/user/gis/oil_station_service1_01.gif',
'https://www.opinet.co.kr/images/user/gis/oil_station_service1_02_01_off.gif')# / 를 기준으로 나눈다.
# 마지막 것만 필요하므로 마지막 것만 가져온다
lpg_yn.split('/')[-1]
>>
'oil_station_service1_02_01_off.gif'
#off 가 있는걸 가져와보자
# lpg_yn.split('/')[-1] 에 '_off'가 있으면 'N' 없으면 'Y'
'N' if '_off' in lpg_yn.split('/')[-1] else 'Y'
>> 'N'
'N' if '_off' in cwsh_yn.split('/')[-1] else 'Y'
>> 'Y'2-6 셀프여부(try ~ except~ )
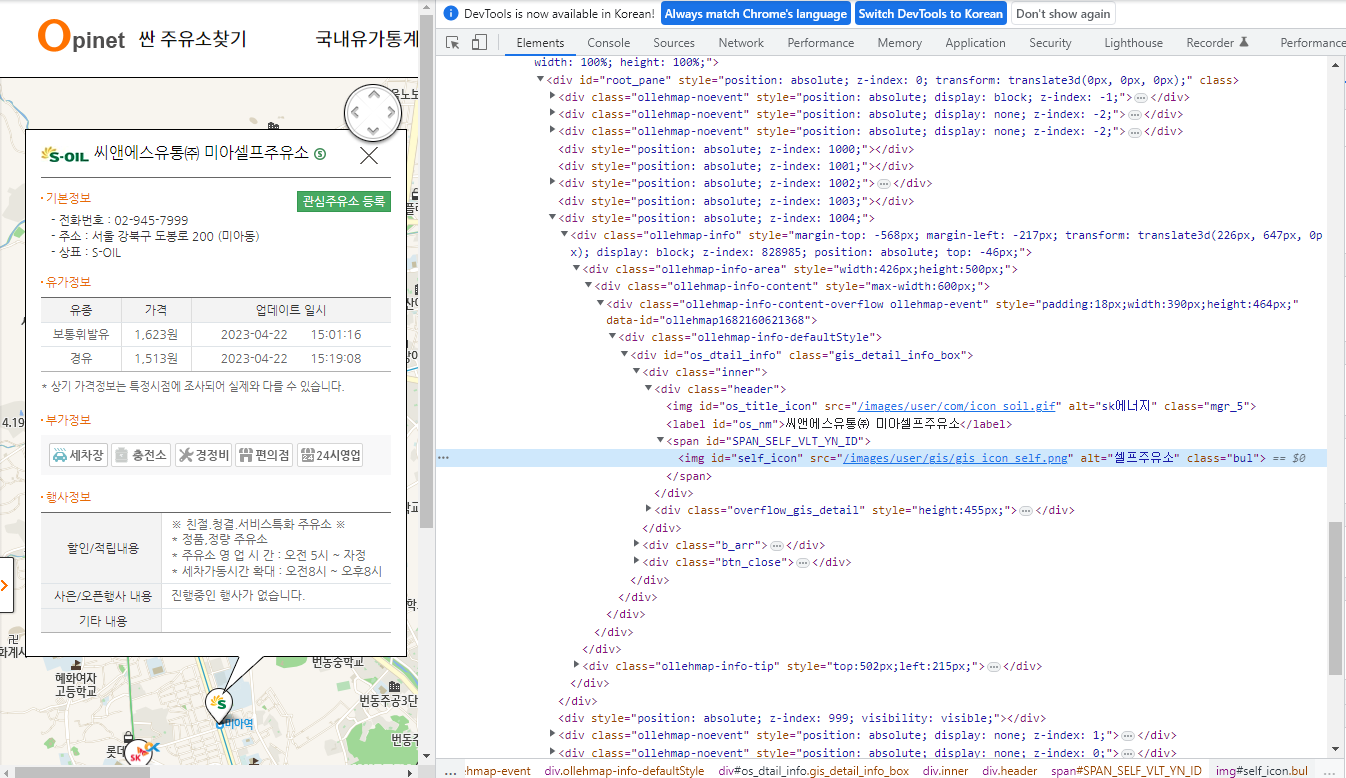
# 셀프주유소인 곳은 셀프 아이콘 html 의 alt 에 셀스주유소라고 되어있고,
driver.find_element(By.CSS_SELECTOR, value='#self_icon').get_attribute('alt')
>> '셀프주유소'# 셀프주유소가 아닌 곳은 오류가 난다.
driver.find_element(By.CSS_SELECTOR, value='#self_icon').get_attribute('alt')
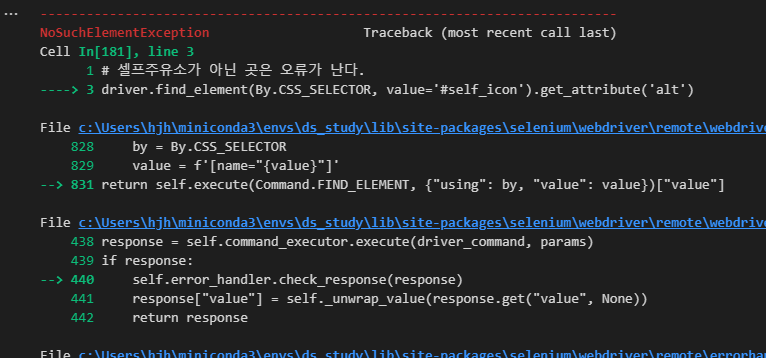
try: # 아래가 실행이 되면 Y
driver.find_element(By.CSS_SELECTOR, value='#self_icon').get_attribute('alt')
is_self = 'Y'
except: # 실행 안되면 N
is_self = 'N'
is_self
>> 'N'2-7 전체 데이터 수집
# 페이지 접근
from selenium.webdriver import ActionChains
from selenium.webdriver.common.by import By
from selenium import webdriver
url = 'https://www.opinet.co.kr/searRgSelect.do'
driver = webdriver.Chrome('./driver/chromedriver.exe')
driver.get(url)
driver.get(url)# 서울시 고정
# 시/도 선택
sido_select = driver.find_element(By.CSS_SELECTOR, value="#SIDO_NM0")
# '서울' 입력
sido_select.send_keys('서울')# 구별 선택
gu_list_raw = driver.find_element(By.ID, value="SIGUNGU_NM0")
gu_list = gu_list_raw.find_elements(By.TAG_NAME, value="option")
gu_names = [option.get_attribute("value") for option in gu_list if option.get_attribute('value')]import pandas as pd
import time
import googlemaps
gmaps_key = '본인키입력'
gmaps = googlemaps.Client(key=gmaps_key)
datas = []
for i in range(len(gu_names)): # 구 선택
gu_selector = f'#SIGUNGU_NM0 > option:nth-child({i+2})'
driver.find_element(By.CSS_SELECTOR, value=gu_selector).click()
station_items = driver.find_elements(By.CSS_SELECTOR, value='#body1 > tr')
for idx in range(len(station_items)): # 주유소 선택
detail_selector = f'#body1 > tr:nth-child({idx+1}) > td.rlist > a'
driver.find_element(By.CSS_SELECTOR, value=detail_selector).click()
title = driver.find_element(By.CSS_SELECTOR, value='.header #os_nm').get_attribute('innerText')
name = title = driver.find_element(By.CSS_SELECTOR, value='.header #os_nm').get_attribute('innerText')
gasoline = driver.find_element(By.CSS_SELECTOR, value='#b027_p').get_attribute('innerText')
disel = driver.find_element(By.CSS_SELECTOR, value='#d047_p').get_attribute('innerText')
address = driver.find_element(By.CSS_SELECTOR, value='#rd_addr').get_attribute('innerText')
brand = driver.find_element(By.CSS_SELECTOR, value='#poll_div_nm').get_attribute('innerText')
cwsh_yn = 'N' if '_off' in driver.find_element(By.CSS_SELECTOR, value='.service #cwsh_yn').get_attribute('src').split('/')[-1] else 'Y'
lpg_yn = 'N' if '_off' in driver.find_element(By.CSS_SELECTOR, value='.service #lpg_yn').get_attribute('src').split('/')[-1] else 'Y'
maint_yn = 'N' if '_off' in driver.find_element(By.CSS_SELECTOR, value='.service #maint_yn').get_attribute('src').split('/')[-1] else 'Y'
cvs_yn = 'N' if '_off' in driver.find_element(By.CSS_SELECTOR, value='.service #cvs_yn').get_attribute('src').split('/')[-1] else 'Y'
sel24_yn = 'N' if '_off' in driver.find_element(By.CSS_SELECTOR, value='.service #sel24_yn').get_attribute('src').split('/')[-1] else 'Y'
try: # 아래가 실행이 되면 Y
driver.find_element(By.CSS_SELECTOR, value='#self_icon').get_attribute('alt')
is_self = 'Y'
except: # 실행 안되면 N
is_self = 'N'
# gu
gu = address.split()[1]
# lat, lng
tmp = gmaps.geocode(address, language='ko')
lat = tmp[0].get('geometry')['location']['lat']
lng = tmp[0].get('geometry')['location']['lng']
datas.append({
'name' : name,
'address' : address,
'brand' : brand,
'is_self' : is_self,
'gasoline' : gasoline,
'disel' : disel,
'car_wash' : cwsh_yn,
'charging_station' : lpg_yn,
'car_maintenance' : maint_yn,
'convenience_store' : cvs_yn,
'24_hour' : sel24_yn,
'gu' : gu,
'lat' : lat,
'lng' : lng
})
time.sleep(0.2)
time.sleep(0.5)
driver.quit
df = pd.DataFrame(datas)
df.tail()
df.info()
>>
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 441 entries, 0 to 440
Data columns (total 14 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 name 441 non-null object
1 address 441 non-null object
2 brand 441 non-null object
3 is_self 441 non-null object
4 gasoline 441 non-null object
5 disel 441 non-null object
6 car_wash 441 non-null object
7 charging_station 441 non-null object
8 car_maintenance 441 non-null object
9 convenience_store 441 non-null object
10 24_hour 441 non-null object
11 gu 441 non-null object
12 lat 441 non-null float64
13 lng 441 non-null float64
dtypes: float64(2), object(12)
memory usage: 48.4+ KB
import datetime
now = datetime.datetime.now()
now
>> datetime.datetime(2023, 4, 22, 16, 25, 52, 771547)
nowDate = now.strftime('%Y%m%d')
nowDate
>> '20230422'# csv 파일 저장
df.to_csv(f'./oilstaion_oneday_{nowDate}.csv', encoding='utf-8')
# csv 파일 읽기
# thousands=',' : 휘발유, 경유 가격에 천단위 콤마 없애기 > 그래야 휘발유, 경유 자료형이 int 로 나옴
station = pd.read_csv('./oilstaion_oneday_20230422.csv', encoding='utf-8', thousands=',', index_col=0)
station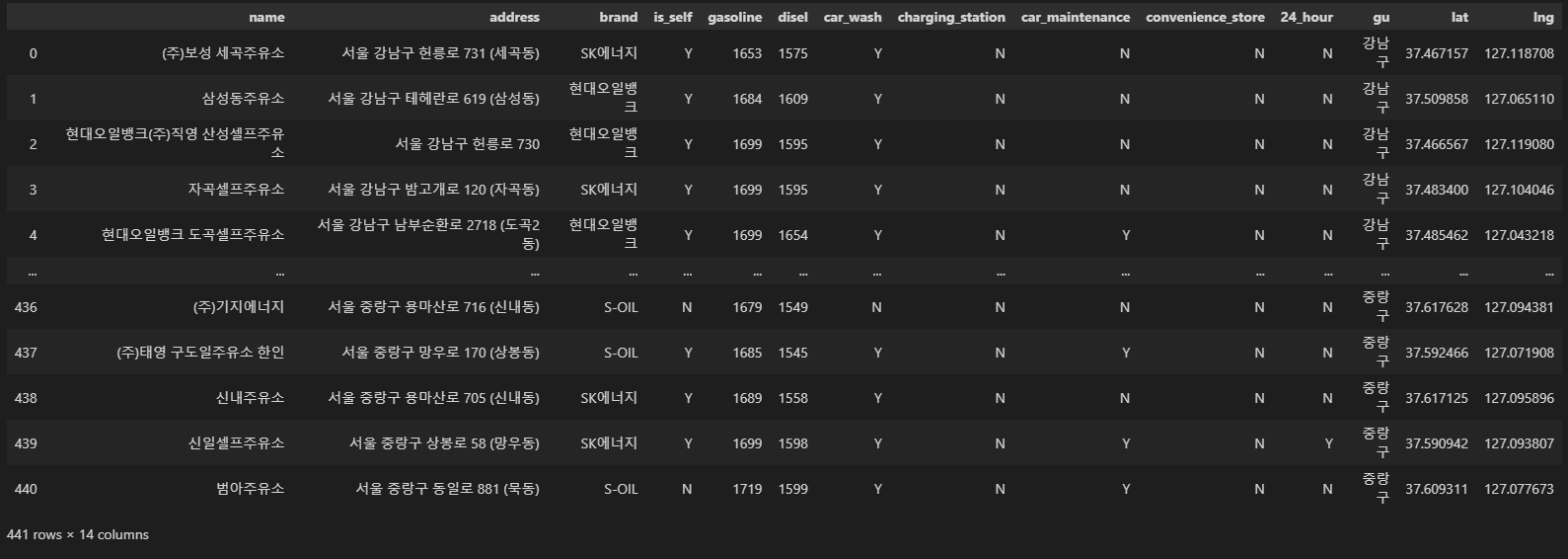
station.info()
>>
<class 'pandas.core.frame.DataFrame'>
Int64Index: 441 entries, 0 to 440
Data columns (total 14 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 name 441 non-null object
1 address 441 non-null object
2 brand 441 non-null object
3 is_self 441 non-null object
4 gasoline 441 non-null int64
5 disel 441 non-null int64
6 car_wash 441 non-null object
7 charging_station 441 non-null object
8 car_maintenance 441 non-null object
9 convenience_store 441 non-null object
10 24_hour 441 non-null object
11 gu 441 non-null object
12 lat 441 non-null float64
13 lng 441 non-null float64
dtypes: float64(2), int64(2), object(10)
memory usage: 51.7+ KB3. 데이터 시각화
# 한글대응
import matplotlib.pyplot as plt
import seaborn as sns
import platform
from matplotlib import font_manager, rc
%matplotlib inline
path = 'C:/Windows/Fonts/malgun.ttf'
if platform.system() == 'Darwin':
rc('font', family = 'Arial Unicode MS')
elif platform.system() == 'Windows':
font_name = font_manager.FontProperties(fname = path).get_name()
rc('font', family = font_name)
else:
print('Unknown system. sorry.')boxplot(feat. seaborn)
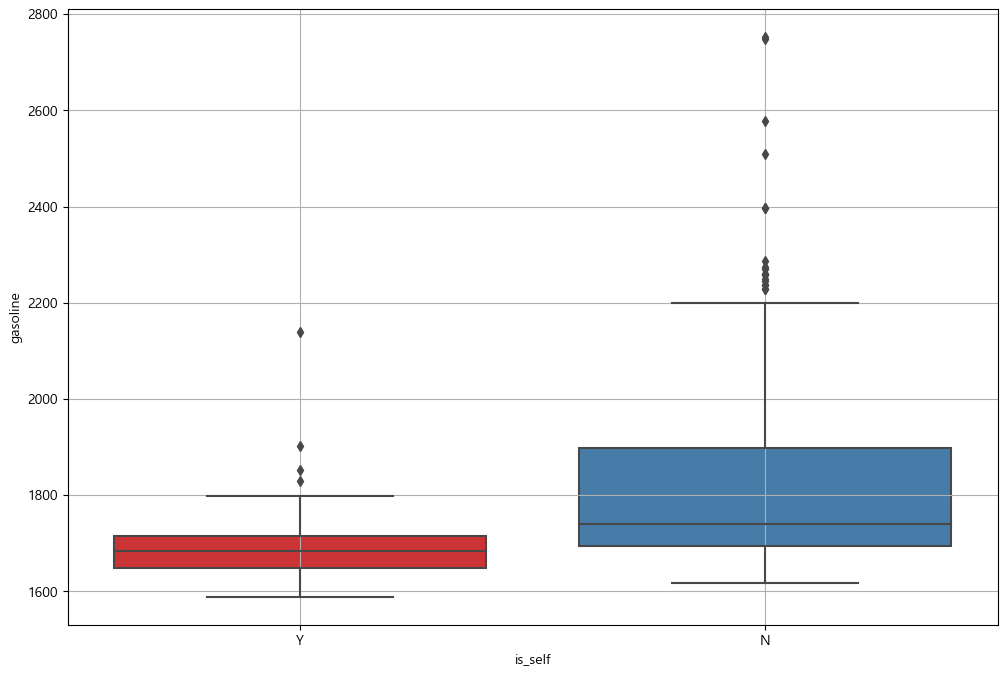
# 휘발유 boxplot(feat. seaborn)
plt.figure(figsize=(12, 8))
sns.boxplot(x='is_self', y='gasoline', data=station, palette='Set1')
plt.grid(True)
plt.show()
# 휘발유 브랜드별 비교
# boxplot(feat. seaborn)
plt.figure(figsize=(12, 8))
sns.boxplot(x='brand', y='gasoline', hue='is_self', data=station, palette='Set1')
plt.grid(True)
plt.show()
# 휘발유 구별 비교
# boxplot(feat. seaborn)
plt.figure(figsize=(18, 8))
sns.boxplot(x='gu', y='gasoline', data=station, palette='Set1')
plt.grid(True)
plt.show()
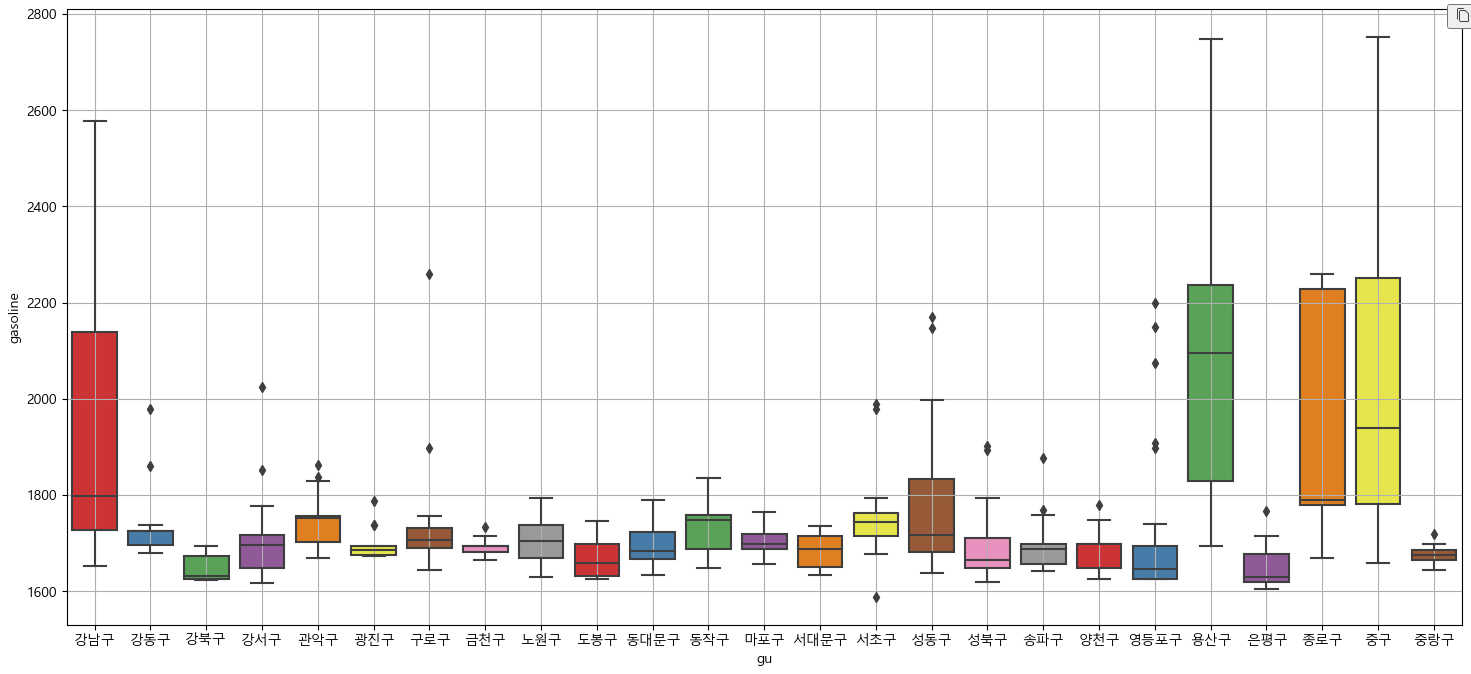
4. 지도 시각화
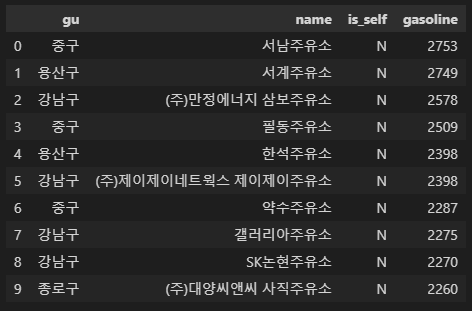
가장 비싼 주유소 10개
# 가장 비싼 주유소 10개
station[['gu', 'name', 'is_self', 'gasoline']].sort_values(by='gasoline', ascending=False).head(10)
station[['gu', 'name', 'is_self', 'gasoline']].sort_values(by='gasoline', ascending=False).head(10).reset_index(drop=True)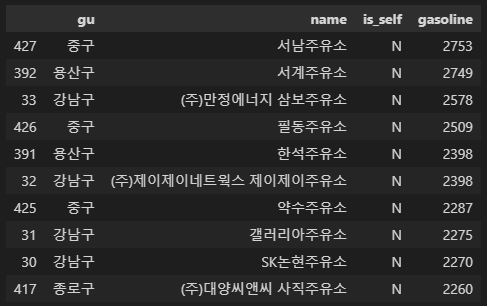
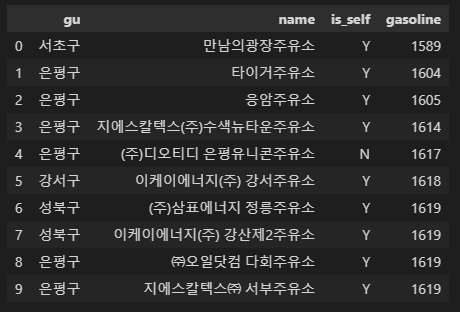
가장 저렴한 주유소 10개
# 가장 저렴한 주유소 10개
station[['gu', 'name', 'is_self', 'gasoline']].sort_values(by='gasoline', ascending=True).head(10).reset_index(drop=True)
지도 시각화용 데이터프레임 만들기
# 지도 시각화용 데이터프레임 만들기
import numpy as np
gu_data = pd.pivot_table(data=station, index='gu', values='gasoline', aggfunc=np.sum)
gu_data.head()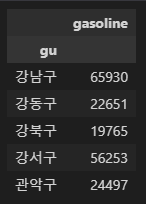
서울 지도 가져오기
# 서울 지도 가져오기
geo_path = './data/02. skorea_municipalities_geo_simple.json'
geo_str = json.load(open(geo_path, encoding='utf-8'))
m = folium.Map(location=[37.5502, 126.982], zoom_start=12)
# 지도에 서울시 구별로 경계선 넣기
m.choropleth(
geo_data = geo_str,
data = gu_data,
columns = [gu_data.index, 'gasoline'],
key_on = 'feature.id',
fiil_color = 'PuRd'
)
m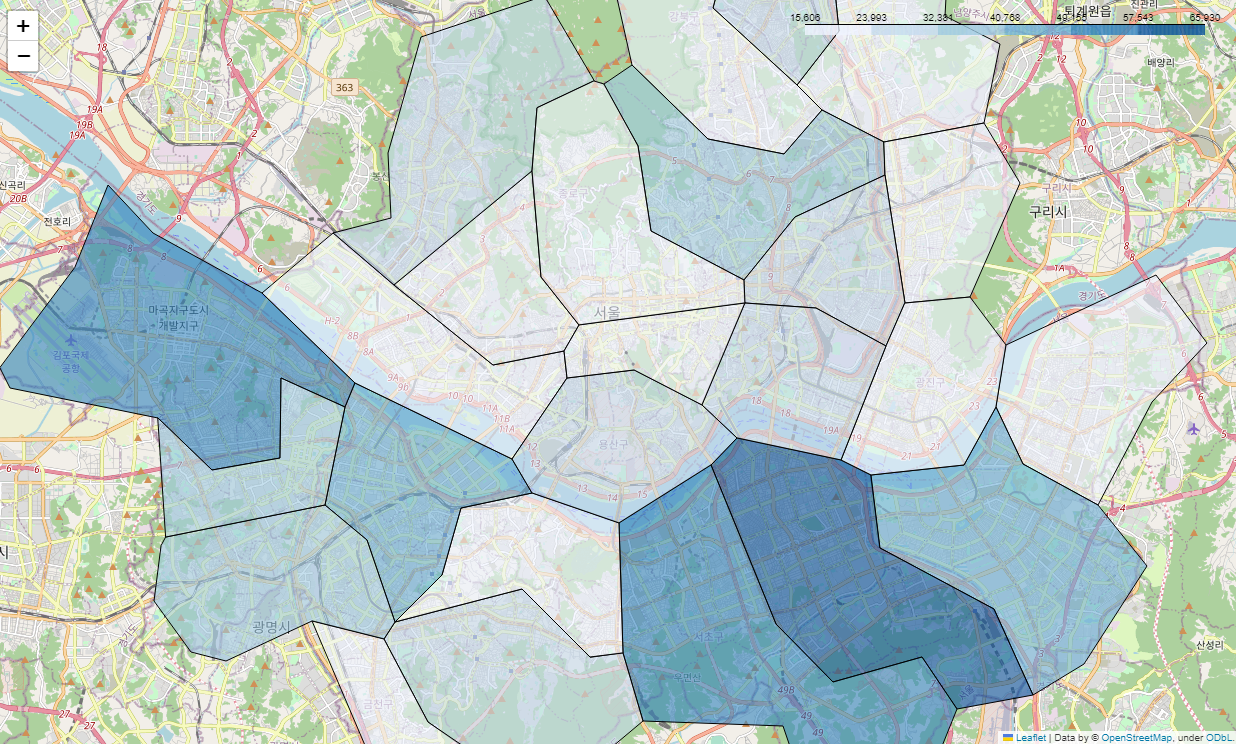

+database