이디야가 스타벅스 옆에 전력적으로 위치 한다는 소문이 있다. 사실인지 분석해보자
스타벅스 데이터 수집
0. 사용할 모듈 import
import pandas as pd
import time
import pandas as pd
from tqdm import tqdm_notebook
from selenium import webdriver
from bs4 import BeautifulSoup
from selenium.webdriver.common.by import By
from selenium.webdriver.common.action_chains import ActionChains1. 페이지 접근
from selenium import webdriver
# 1. 스타벅스 페이지 접근
url = 'https://www.starbucks.co.kr/store/store_map.do'
driver = webdriver.Chrome("../driver/chromedriver.exe")
driver.get(url)2. 지역 선택
# '지역검색' 선택
from selenium.webdriver import ActionChains
from selenium.webdriver.common.by import By
search_tag = driver.find_element(By.CSS_SELECTOR, value='#container > div > form > fieldset > div > section > article.find_store_cont > article > header.loca_search')
action = ActionChains(driver)
action.click(search_tag)
action.perform()- 경고 문구 무시
import warnings
warnings.simplefilter(action = 'ignore')3. 서울 선택
# '서울' 선택
driver.find_element(By.CSS_SELECTOR,
'#container > div > form > fieldset > div > section > article.find_store_cont > article > article:nth-child(4) > div.loca_step1 > div.loca_step1_cont > ul > li:nth-child(1) > a').click()
ActionChains(driver).move_to_element(element).click().perform() #위에 쓴 것과 편한거 쓰길
4. 전체 선택
# 전체 선택
all_select = driver.find_element(By.CSS_SELECTOR, value='#mCSB_2_container > ul > li:nth-child(1) > a').click()
len(all_select) # (606) 데이터 확인용으로 한번씩 꼭 하자
5. 검색 결과 리스트 가져오기(beautifulsoup)
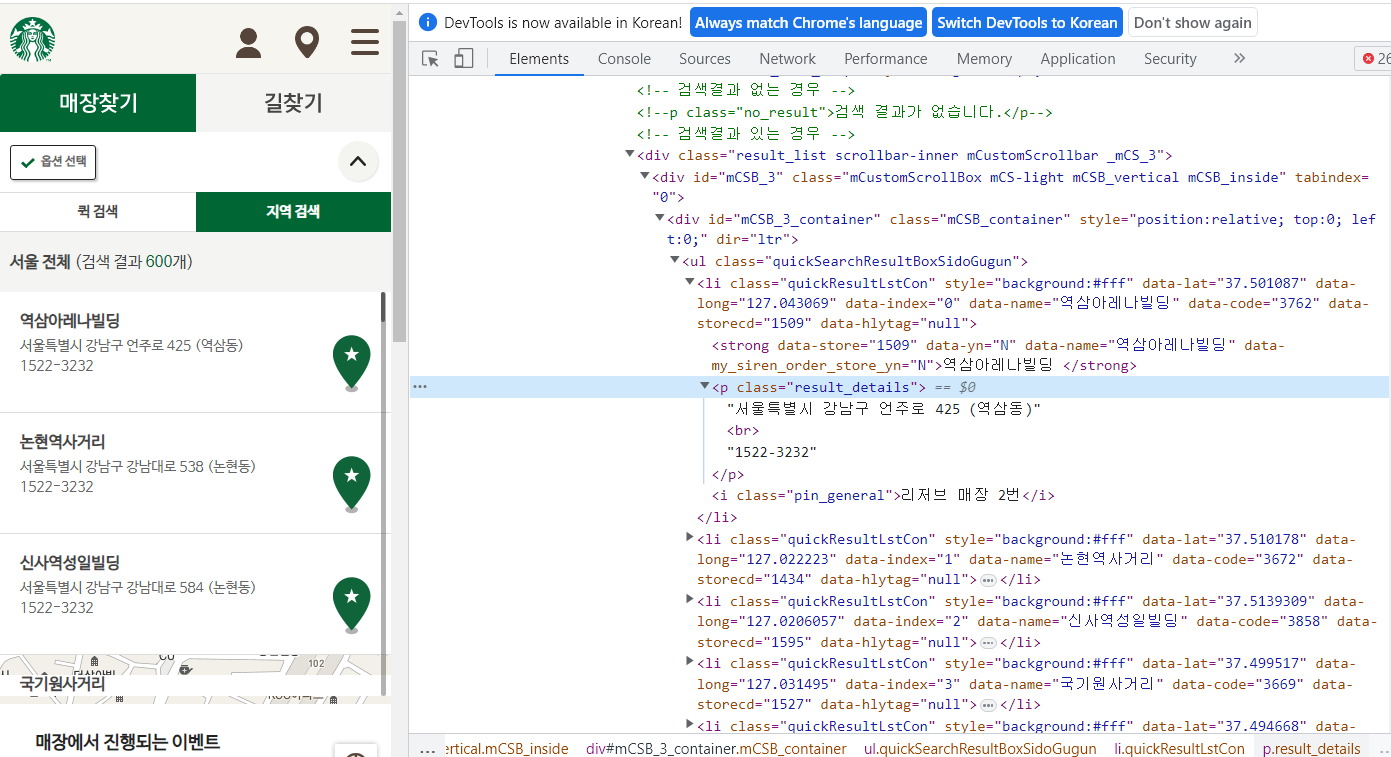
# 검색 결과 리스트 가져오기(beautifulsoup)
# #mCSB_3_container : id 가 mCSB_3_container
# #mCSB_3_container ul li: id가 mCSB_3_container 이고 밑에 ul, 그 밑에 li를 모두 가져와야함
driver.find_elements(By.CSS_SELECTOR, "#mCSB_3_container ul li")# 길이 확인
# 매장에 대한 정보를 모두 가져왔다
tmp_list = driver.find_elements(By.CSS_SELECTOR, "#mCSB_3_container ul li")
len(tmp_list)
6. 데이터 수집(매장 이름, 주소, 위도, 경도)
from bs4 import BeautifulSoup
# html로 읽어오기
req = driver.page_source
dom = BeautifulSoup(req, "html.parser")
dom
sbuck_list = dom.select("#mCSB_3_container ul li")
len(sbuck_list)
sbuck_list[0]
#위 결과값을 보기 편하게 정리해놓음
<li class="quickResultLstCon"
data-code="3762" data-hlytag="null" data-index="0"
data-lat="37.501087"
data-long="127.043069"
data-name="역삼아레나빌딩"
data-storecd="1509" style="background:#fff">
<strong data-my_siren_order_store_yn="N"
data-name="역삼아레나빌딩" data-store="1509" data-yn="N">역삼아레나빌딩
</strong>
<p class="result_details">서울특별시 강남구 언주로 425 (역삼동)<br/>1522-3232</p>
<i class="pin_general">리저브 매장 2번</i></li>-> 위 정보를 참고해 데이터를 뽑아오자
sbuck_list = dom.select("#mCSB_3_container ul li")
title = sbuck_list[0]['data-name']
lat = sbuck_list[0]['data-lat']
lng = sbuck_list[0]['data-long']
# p태그 안의 값을 가져온다
address = sbuck_list[0]('p')
address
>>
[<p class="result_details">서울특별시 강남구 언주로 425 (역삼동)<br/>1522-3232</p>]
# 아래처럼 해도 값은 같다
address = sbuck_list[0].select_one('p')
address
>>
<p class="result_details">서울특별시 강남구 언주로 425 (역삼동)<br/>1522-3232</p>
address = sbuck_list[0].select_one('p').text
address
>>
'서울특별시 강남구 언주로 425 (역삼동)1522-3232'
# 전화번호 부분을 제외시킨다
address = sbuck_list[0].select_one('p').text[:-9]
address
>>
'서울특별시 강남구 언주로 425 (역삼동)'7. 전체 데이터 수집
import pandas as pd
from tqdm import tqdm_notebook
datas = []
for content in tqdm_notebook(sbuck_list):
title = content['data-name']
address = content.select_one('p').text[:-9]
lat = content['data-lat']
lng = content['data-long']
datas.append({
'title': title,
'address': address,
'lat': lat,
'lng': lng
})
df = pd.DataFrame(datas)
df.tail()
8. 구 컬럼 추가
df['address'][0]
>> '서울특별시 강남구 언주로 425 (역삼동)'
df['address'][0].split()
>> ['서울특별시', '강남구', '언주로', '425', '(역삼동)']
df['address'][0].split()[1]
>> '강남구'#일단 강남구루만 다 채워봄
df['구'] = df['address'][0].split()[1]
df
for idx, rows in df.iterrows():
print(rows['구']) # 현재 모든 구가 강남구임
>>
강남구
강남구
...
강남구
강남구
강남구
강남구-> 다 강남구니까 반목문을 이용해 다른 구들을 맞게 채워보자
for idx, rows in df.iterrows():
rows['구'] = df['address'][idx].split()[1]
# idx 마다 해당 구를 구해서 rows['구'] 에 넣음
df.tail() # 해당구에 맞는 구가 잘 들어감
9. 데이터 저장
# 데이터 저장
df.to_csv('../data/starbucks.csv', encoding='utf-8')
# 데이터 읽어와보기
starbucks_df = pd.read_csv('../data/starbucks.csv', index_col=0)
#index_col=0 필요없는 index 컬럼 지움
starbucks_df
이디야 데이터 수집
1. 페이지 접근
# 1. 이디야 페이지 접근
driver = webdriver.Chrome("../driver/chromedriver.exe")
driver.get("https://ediya.com/contents/find_store.html#c")2. 주소 검색 탭 선택
driver.find_element(By.CSS_SELECTOR, value='#contentWrap > div.contents > div > div.store_search_pop > ul > li:nth-child(2) > a').click()3. 검색어(구) 만들기
스타벅스 구 컬럼 가져오기
# 스타벅스 매장 구 컬럼 가져오기
df["구"].unique()
>>
array(['강남구', '강북구', '강서구', '관악구', '광진구', '금천구', '노원구', '도봉구', '동작구',
'마포구', '서대문구', '서초구', '성북구', '송파구', '양천구', '영등포구', '은평구', '종로구',
'중구', '강동구', '구로구', '동대문구', '성동구', '용산구', '중랑구'], dtype=object)리스트형으로 변환
# gu_list 에 넣어주고 list 자료형으로 형변환
gu_list = list(df["구"].unique())
gu_list
>>
['강남구',
'강북구',
'강서구',
'관악구',
'광진구',
'금천구',
'노원구',
'도봉구',
'동작구',
'마포구',
'서대문구',
'서초구',
'성북구',
'송파구',
'양천구',
'영등포구',
'은평구',
'종로구',
'중구',
'강동구',
'구로구',
'동대문구',
'성동구',
'용산구',
'중랑구']'서울' 붙이기
- 앞에 서울 붙이는 이유는 '검색량이 너무 많다'고 오류 뜸...
이거때매 과제 몇시간 날린듯 하..
# '서울' 붙이기
gu_list = [str('서울 ') + gu for gu in gu_list]
gu_list
>>
['서울 강남구',
'서울 강북구',
'서울 강서구',
'서울 관악구',
'서울 광진구',
'서울 금천구',
'서울 노원구',
'서울 도봉구',
'서울 동작구',
'서울 마포구',
'서울 서대문구',
'서울 서초구',
'서울 성북구',
'서울 송파구',
'서울 양천구',
'서울 영등포구',
'서울 은평구',
'서울 종로구',
'서울 중구',
'서울 강동구',
'서울 구로구',
'서울 동대문구',
'서울 성동구',
'서울 용산구',
'서울 중랑구']구 확인
len(gu_list), gu_list[:3]
>>
(25, ['서울 강남구', '서울 강북구', '서울 강서구'])4. 데이터 수집
준비
# 데이터 수집 준비
keyword = driver.find_element(By.CSS_SELECTOR, value="#keyword")
keyword.clear() # 기존에 입력한 검색어 지우기
keyword.send_keys(gu_list[0]) # 일단 강남구 넣어봄구별 검색어 입력
import time
# 1. 이디야 페이지 접근
url = "https://ediya.com/contents/find_store.html#c"
driver = webdriver.Chrome("../driver/chromedriver.exe")
driver.get(url)
# 2. 주소 검색 탭 선택
driver.find_element(By.CSS_SELECTOR, value='#contentWrap > div.contents > div > div.store_search_pop > ul > li:nth-child(2) > a').click()
# 3. 검색어를 입력할 공간 찾기
search_keyword = driver.find_element(By.CSS_SELECTOR, value="#keyword")
# 4. 검색 버튼 클릭
search_btn = driver.find_element(By.CSS_SELECTOR, value="#keyword_div > form > button")
time.sleep(2)
# 5. 검색 결과 리스트 가져오기(BeautifulSoup)
html = driver.page_source
dom = BeautifulSoup(html, "html.parser")
contents = dom.select('#placesList li')
# 6. 매장이름, 주소 데이터 수집
title = content.select_one('dt').text
address = content.select_one('dd').text
# 7. 구별 반복문
ediya = []
for gu in gu_list:
search_keyword.clear()
search_keyword.send_keys(gu)
search_btn.click()
time.sleep(1)
html = driver.page_source
dom = BeautifulSoup(html, "html.parser")
contents = dom.select('#placesList li')
for content in contents:
title = content.select_one('dt').text
address = content.select_one('dd').text
ediya.append({
'title' : title,
'address' : address
})
df_ediya = pd.DataFrame(ediya)
df_ediya.tail()5. 구 컬럼 추가
# 구 컬럼 추가
df_ediya['gu'] = df_ediya['address'][0].split()[1]
for idx, rows in df_ediya.iterrows():
rows['gu'] = df_ediya['address'][idx].split()[1]
# idx 마다 해당 구를 구해서 rows['구'] 에 넣음
df_ediya['gu'].unique()
>>
array(['강남구', '강북구', '강서구', '관악구', '광진구', '금천구', '노원구', '도봉구', '동작구',
'마포구', '서대문구', '서초구', '성북구', '송파구', '양천구', '영등포구', '은평구', '종로구',
'중구', '강동구', '구로구', '동대문구', '성동구', '용산구', '중랑구'], dtype=object)
df_ediya.tail()
6. 위도, 경도 (googlemaps)
준비
# googlemaps 이용한 매장 위치 좌표
# 위도, 경도 컬럼 추가
import googlemaps
gmaps_key = '_____________' # 본인 키 입력
gmaps = googlemaps.Client(key=gmaps_key)위도, 경도 컬럼 만들도 nan 값으로 채우기
import numpy as np
df_ediya['lat'] = np.nan
df_ediya['lng'] = np.nan
df_ediya.head(2)
위도, 경도 넣기
for idx, rows in tqdm_notebook(df_ediya.iterrows()):
address = rows['address']
tmp = gmaps.geocode(address, language='ko')
tmp[0].get('formatted_address')
lat = tmp[0].get('geometry')['location']['lat']
lng = tmp[0].get('geometry')['location']['lng']
df_ediya.loc[idx, 'lat'] = lat
df_ediya.loc[idx, 'lng'] = lng7. 데이터 저장
# 데이터 저장
df_ediya.to_csv('../data/ediya.csv', encoding='utf-8')
# 파일 읽어와 보기
ediya_df = pd.read_csv('../data/ediya.csv', index_col=0)
ediya_df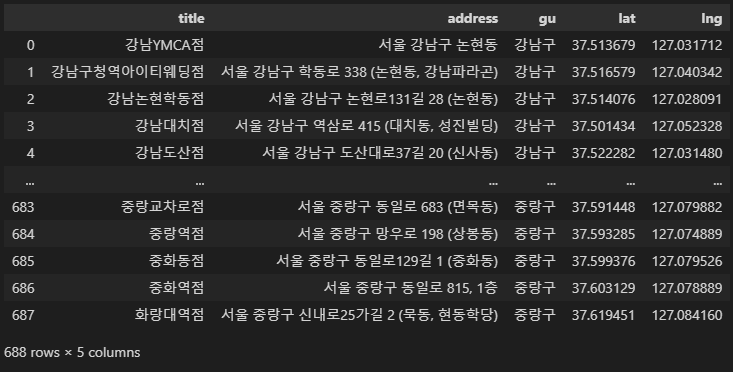
데이터 분석 및 시각화
데이터 정리
#데이터 불러오기
starbucks_df = pd.read_csv('../data/starbucks.csv', index_col=0)
ediya_df = pd.read_csv('../data/ediya.csv', index_col=0)
# 이름 붙이기
starbucks_df['brand'] = '스타벅스'
ediya_df['brand'] = '이디야'
#데이터 합치기 및 정리
cafe_df = pd.concat([starbucks_df, ediya_df], axis=0)
cafe_df.reset_index(inplace=True)
del cafe_df['index']시각화 전에 기본적으로 해줄 것
->
# 한글대응
import matplotlib.pyplot as plt
import seaborn as sns
import platform
from matplotlib import font_manager, rc
%matplotlib inline
path = 'C:/Windows/Fonts/malgun.ttf'
if platform.system() == 'Darwin':
rc('font', family = 'Arial Unicode MS')
elif platform.system() == 'Windows':
font_name = font_manager.FontProperties(fname = path).get_name()
rc('font', family = font_name)
else:
print('Unknown system. sorry.')스타벅스 매장 주요 분포 지역
# 스타벅스 매장 주요 분포 지역
cafe_df['gu']
>>
0 강남구
1 강남구
2 강남구
3 강남구
4 강남구
...
1284 중랑구
1285 중랑구
1286 중랑구
1287 중랑구
1288 중랑구
Name: gu, Length: 1289, dtype: object스타벅스 상위 5개 구 확인
# 스타벅스 상위 5개 구 확인하기
# 구별 스타벅스 갯수 파악하기
# 구별 스타벅스 갯수를 내림차순 정렬하고, 상위 5개만 보자
cafe_df['gu'][cafe_df['brand']=='스타벅스'].value_counts(ascending=False)[:5]
>>
강남구 88
중구 53
서초구 48
영등포구 41
종로구 40
Name: gu, dtype: int64이디야 상위 5개 구 확인하기
# 이디야 상위 5개 구 확인하기
cafe_df['gu'][cafe_df['brand']=='이디야'].value_counts(ascending=False)[:5]
>>
강남구 44
영등포구 41
송파구 38
강서구 35
마포구 34
Name: gu, dtype: int64구별 매장 수
# 구별 매장 수
# 강남구 스타벅스는 88개
# 강남구 이디야는 44개
# ...
df1 = cafe_df.groupby(['gu', 'brand'])['title'].count().reset_index(name='shop_count')
df1.head()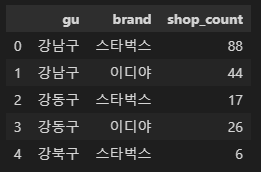
구별 매장 수 더 보기 좋게
# 위 구별 매장 수를 더 보기좋게 : 피봇테이블
# 구별 각 브랜드 매장 수 (피봇테이블)
# shop_count 왜 있지? 위에서 이미 만들어서 있는건가?
import numpy as np
df1.pivot_table(index='gu', columns='brand', aggfunc=np.sum)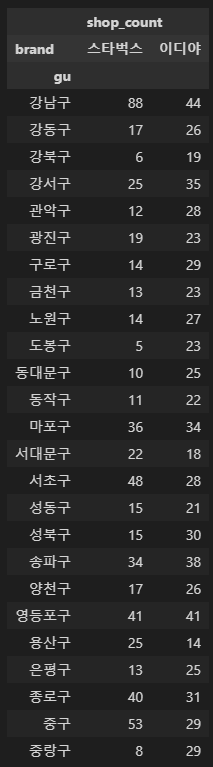
barplot
# 시각화
# 구별 매장 수 차이 1 (피봇테이블 사용x)
plt.figure(figsize=(24, 6))
sns.barplot(data=df1, x=df1['gu'], y=df1['shop_count'], hue='brand', palette='Set1')
plt.show()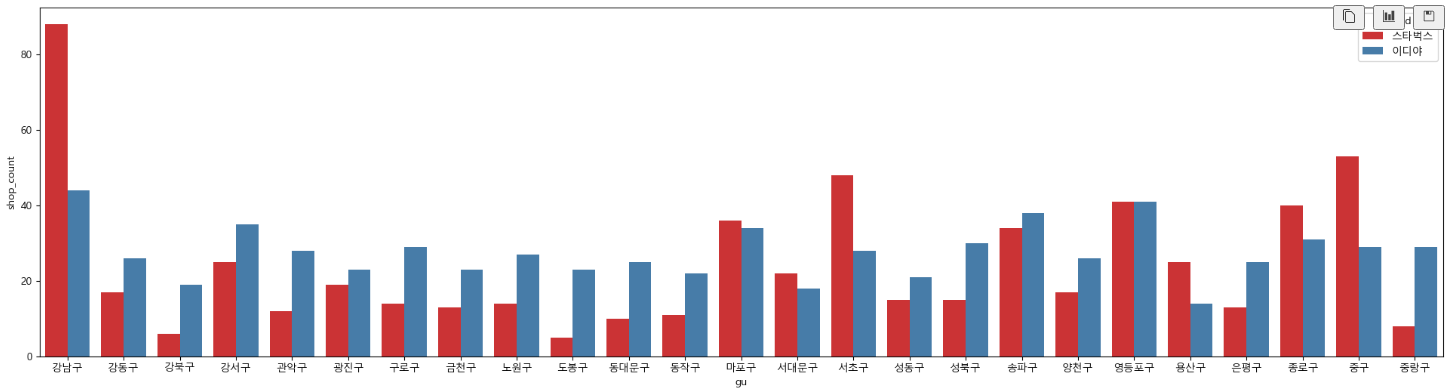
barplot - dodge(겹치기)
# 구별 매장 수 차이 2
# dodge=True : 그래프 안겹치게
# dodge=False : 그래프 겹치게
plt.figure(figsize=(24, 6))
sns.barplot(data=df1, x=df1['gu'], y=df1['shop_count'], hue='brand', dodge=True, alpha=0.8, palette='Set1')
plt.show()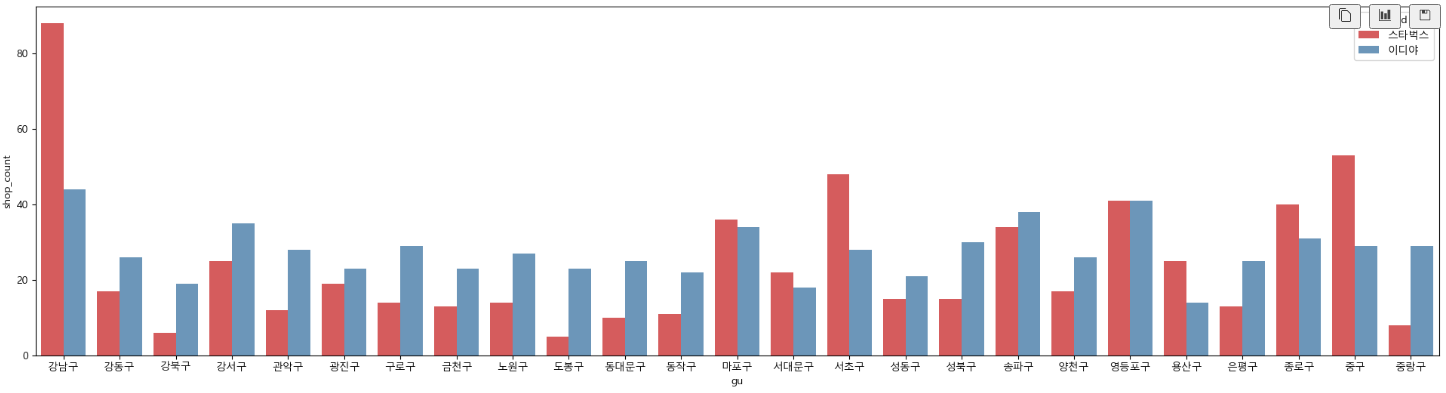
# 구별 매장 수 차이 2
# dodge=True : 그래프 안겹치게
# dodge=False : 그래프 겹치게
# 강남구, 마포구, 서대문구, 서초구, 용산구, 종로구, 중구에서는 스타벅스 매장이 더 많다
# 마포구, 송파구, 영등포구는 매장의 비율이 비슷한 지역인 것을 확인할 수 있다.
# 이디야 매장이 고르게 분포되어 있다.
plt.figure(figsize=(24, 6))
sns.barplot(data=df1, x=df1['gu'], y=df1['shop_count'], hue='brand', dodge=False, alpha=0.8, palette='Set1')
plt.show()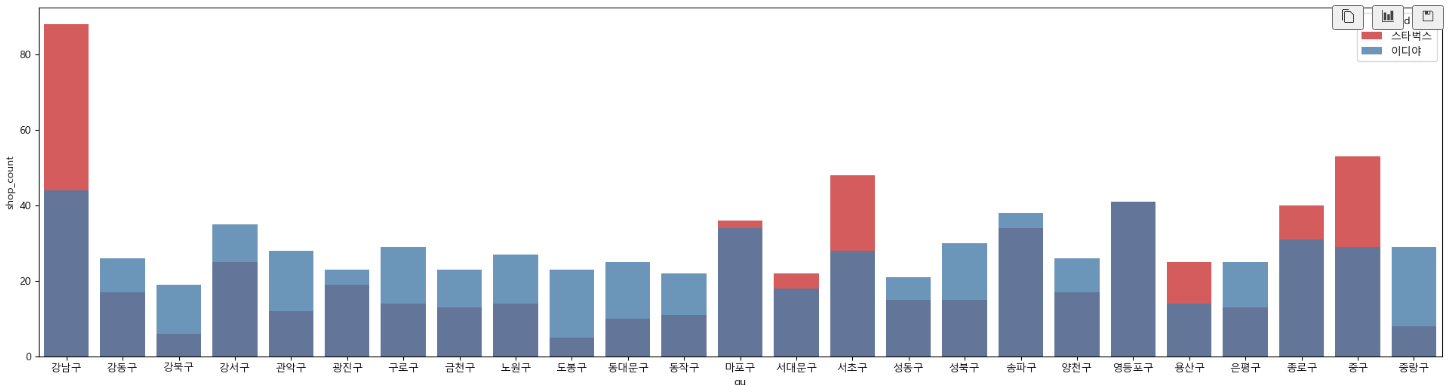
지도 시각화
지도 시각화 데이터프레임(스타벅스)
# 지도 시각화 데이터프레임(스타벅스)
stb_df_m = stb_df.groupby(['gu', 'brand'])['title'].count().reset_index(name='shop_count')
stb_df_m = stb_df_m.pivot_table(index='gu')
stb_df_m.head()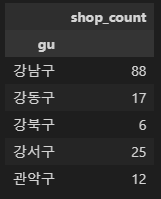
# 지도 시각화 데이터프레임(이디야)
edi_df_m = ediya_df.groupby(['gu', 'brand'])['title'].count().reset_index(name='shop_count')
edi_df_m = edi_df_m.pivot_table(index='gu')
edi_df_m.head()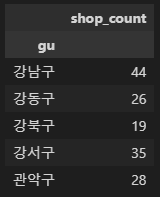
folium
import folium
import json
geo_path = '../data/02. skorea_municipalities_geo_simple.json'
geo_str = json.load(open(geo_path, encoding='utf-8'))
서울시 지도 나타내기
# 서울시 지도 나타내기
sta_m = folium.Map(location=[37.5502, 126.982], zoom_start=12)
sta_m
지도에 구별 경계선 넣기
# 지도에 서울시 구별로 경계선 넣기
sta_m = folium.Map(location=[37.5502, 126.982], zoom_start=12)
sta_m.choropleth(
geo_data = geo_str,
data = stb_df_m['shop_count'],
columns = [stb_df_m.index, stb_df_m['shop_count']],
fiil_color = 'PuRd',
key_on = 'feature.id'
)
sta_m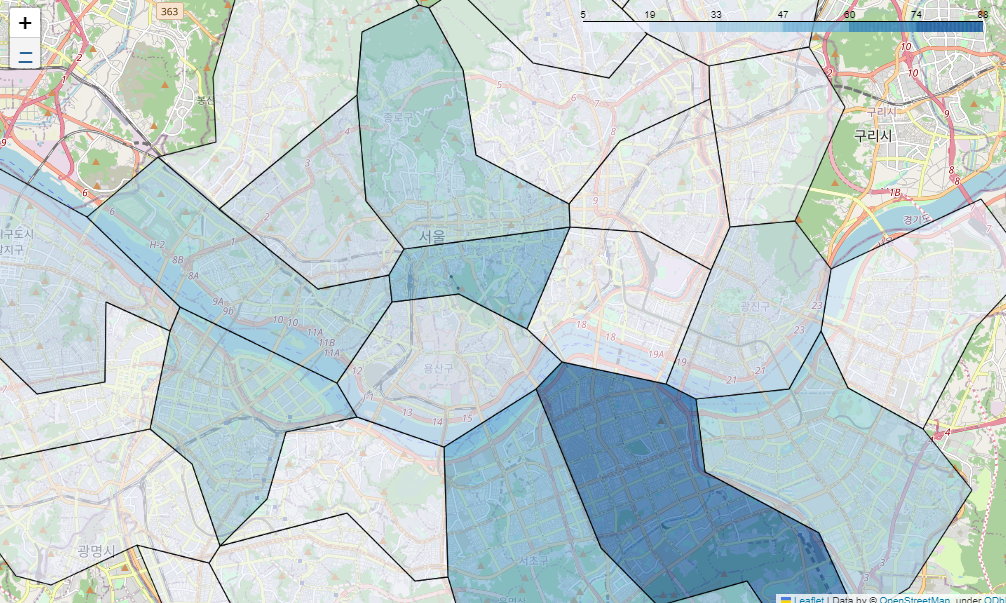
스타벅스 매장 시각화
# 스타벅스 매장 시각화
# 위 경계선 지도 데이터에 folium 만 더함
sta_m = folium.Map(location=[37.5502, 126.982], zoom_start=12)
sta_m.choropleth(
geo_data = geo_str,
data = stb_df_m['shop_count'],
columns = [stb_df_m.index, stb_df_m['shop_count']],
fiil_color = 'PuRd',
key_on = 'feature.id'
)
for idx, rows in stb_df.iterrows():
folium.Circle(
location=[rows['lat'], rows['lng']],
radius=100,
popup=rows['title'] + '점',
color='#2c9147',
fill_color='#2c9147'
).add_to(sta_m)
sta_m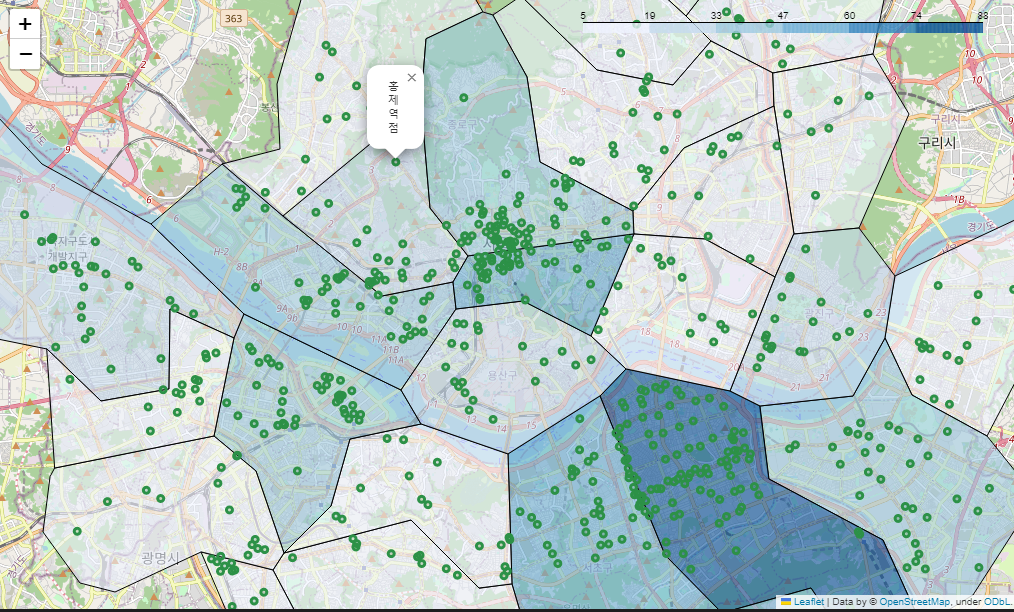
이디야 매장 시각화
# 이디야 매장 시각화
edi_m = folium.Map(location=[37.5502, 126.982], zoom_start=12)
edi_m.choropleth(
geo_data = geo_str,
data = edi_df_m['shop_count'],
columns = [edi_df_m.index, edi_df_m['shop_count']],
fiil_color = 'PuRd',
key_on = 'feature.id'
)
for idx, rows in ediya_df.iterrows():
folium.Circle(
location=[rows['lat'], rows['lng']],
radius=100,
popup=rows['title'] + '점',
color='#5882FA',
fill_color='#5882FA'
).add_to(edi_m)
edi_m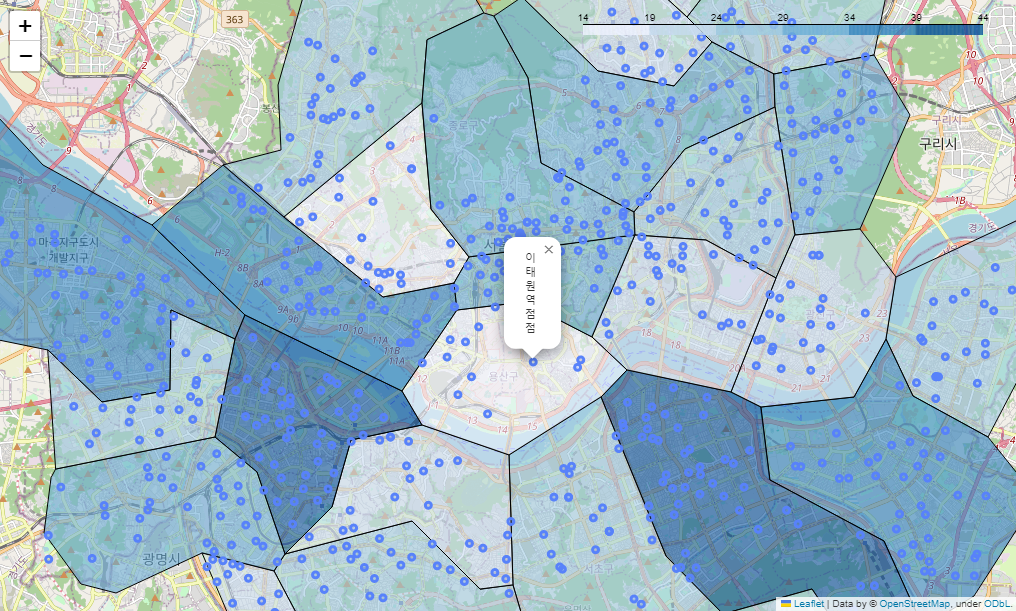
스타벅스+이디야 시각화
# 스타벅스 + 이디야 매장 지도 시각화(스타벅스 기준)
sta_edi_m = folium.Map(location=[37.5502, 126.982], zoom_start=12)
# 스타벅스 매장 기준 경계선
sta_edi_m.choropleth(
geo_data = geo_str,
data = stb_df_m['shop_count'],
columns = [stb_df_m.index, stb_df_m['shop_count']],
fiil_color = 'PuRd',
key_on = 'feature.id'
)
# 스타벅스 folium
for idx, rows in stb_df.iterrows():
folium.Circle(
location=[rows['lat'], rows['lng']],
radius=100,
popup=rows['title'] + '점',
color='#2c9147',
fill_color='#2c9147'
).add_to(sta_edi_m)
# 이디야 folium
for idx, rows in ediya_df.iterrows():
folium.Circle(
location=[rows['lat'], rows['lng']],
radius=100,
popup=rows['title'] + '점',
color='#5882FA',
fill_color='#5882FA'
).add_to(sta_edi_m)
sta_edi_m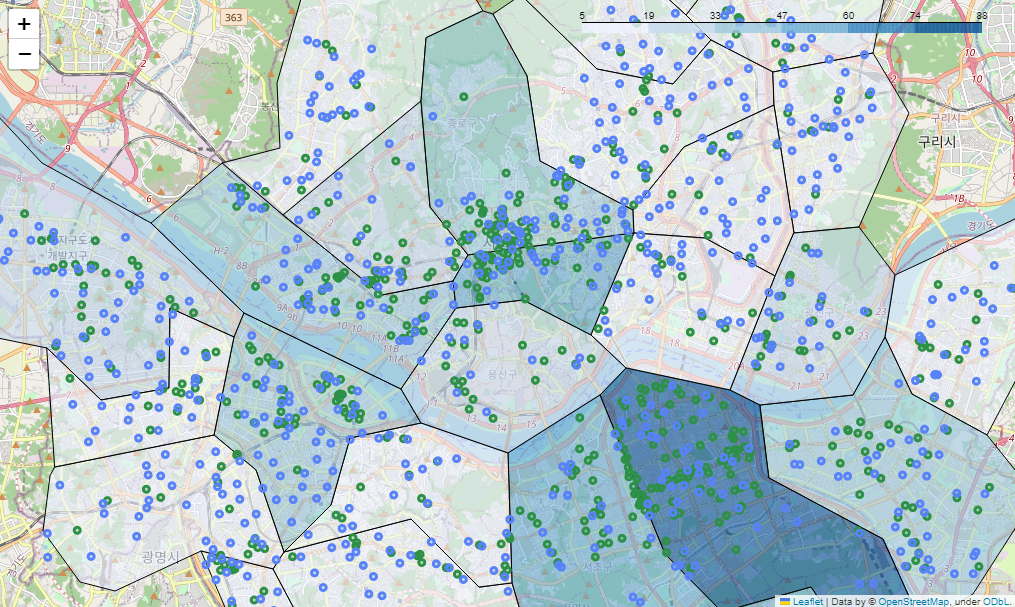
folium.Circle
데이터 준비
# 데이터 준비
df2 = cafe_df.groupby(['gu', 'brand'])['title'].count().reset_index(name='shop_count')
df2.head()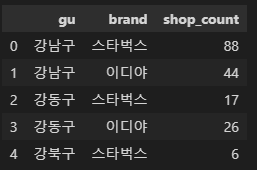
피봇테이블로 만들기
# 위 데이터에서는 shop_count 가 컬럼값이었는데,
# 여기에서는 values 값으로 넣어서 컬럼으로 안나오게 함
totalCnt = df2.pivot_table(index='gu', columns='brand', values='shop_count', aggfunc=np.sum)
totalCnt.head()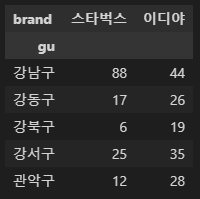
구글맵스로 위도, 경도 넣기
# 위도, 경도 nan 값으로 컬럼 만들고
# 구글맵스 임포트해서 위도, 경도 넣기
import googlemaps
gmaps_key = '키값넣기'
gmaps = googlemaps.Client(key=gmaps_key)
totalCnt["위도"] = np.nan
totalCnt["경도"] = np.nan
# 무슨 위도, 경도를 불러온거지?
# 구의 위도, 경도를 가져올 수 있나보네?
for idx, rows in totalCnt.iterrows():
tmp = gmaps.geocode(idx, language='ko')
if tmp:
lat= tmp[0].get("geometry")["location"]["lat"]
lng= tmp[0].get("geometry")["location"]["lng"]
totalCnt.loc[idx,"위도"]=lat
totalCnt.loc[idx,"경도"]=lng
else:
print(idx)
totalCnt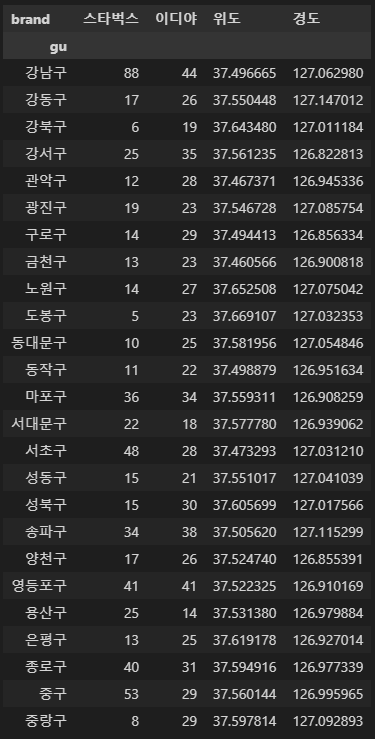
folium.Circle
seoul = [37.517692, 126.989912]
resultMap = folium.Map(
location=seoul,
zoom_start=11,
tiles="OpenStreetMap"
)
for idx, rows in totalCnt.iterrows():
#스타벅스 --> 파란 원
folium.Circle(
location=[rows["위도"], rows["경도"]],
radius = rows["스타벅스"]* 50,
fill = True,
color = 'blue',
popup = idx,
tooltip = idx
).add_to(resultMap)
#이디야--> 붉은 원
folium.Circle(
location=[rows["위도"], rows["경도"]],
radius = rows["이디야"]* 50,
fill = True,
color = 'red',
popup = idx,
tooltip = idx
).add_to(resultMap)
resultMap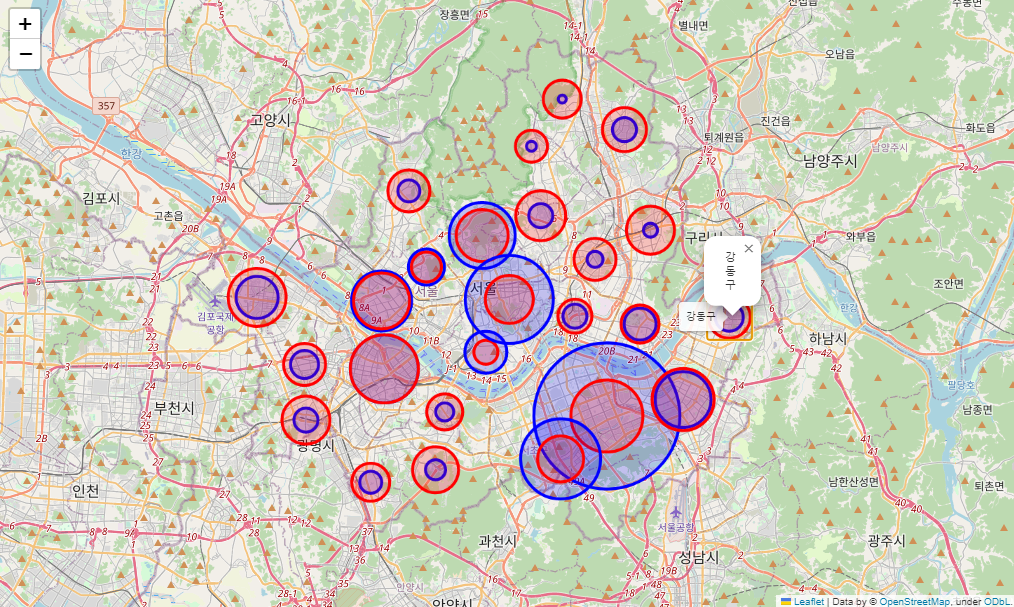
분석 결과
- 강남구, 중구, 서초구, 종로구, 용산구에서 스타벅스 매장이 더 많음
- 서대문구, 영등포구, 마포구는 스타벅스와 이디야 비율이 비슷함
- 8개 지역 제외하고는 스타벅스보다 이디야가 더 고르게 분포
- 주요 상권, 회사 밀집 지역에는 스타벅스가 집중
- 이디야는 주요 상권에서는 스타벅스와 인접 하지만 이것만으로 이디야가 스타벅스 옆에 전력적으로 위치 한것으로 판단하기엔 부족
- 이디야는 스타벅스와 비교해 서울시 기준으로 더 고르게 분포
결론적으로, 이디야는 스타벅스 매장 옆에 위치한 전략을 고수했다고 불 수 없다.

+database