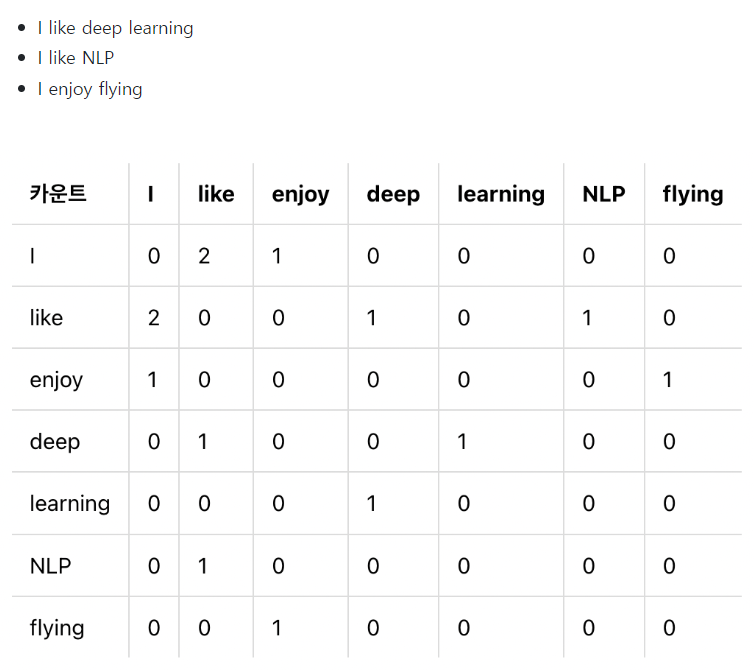
NLP
1.통계적 언어모델의 흐름
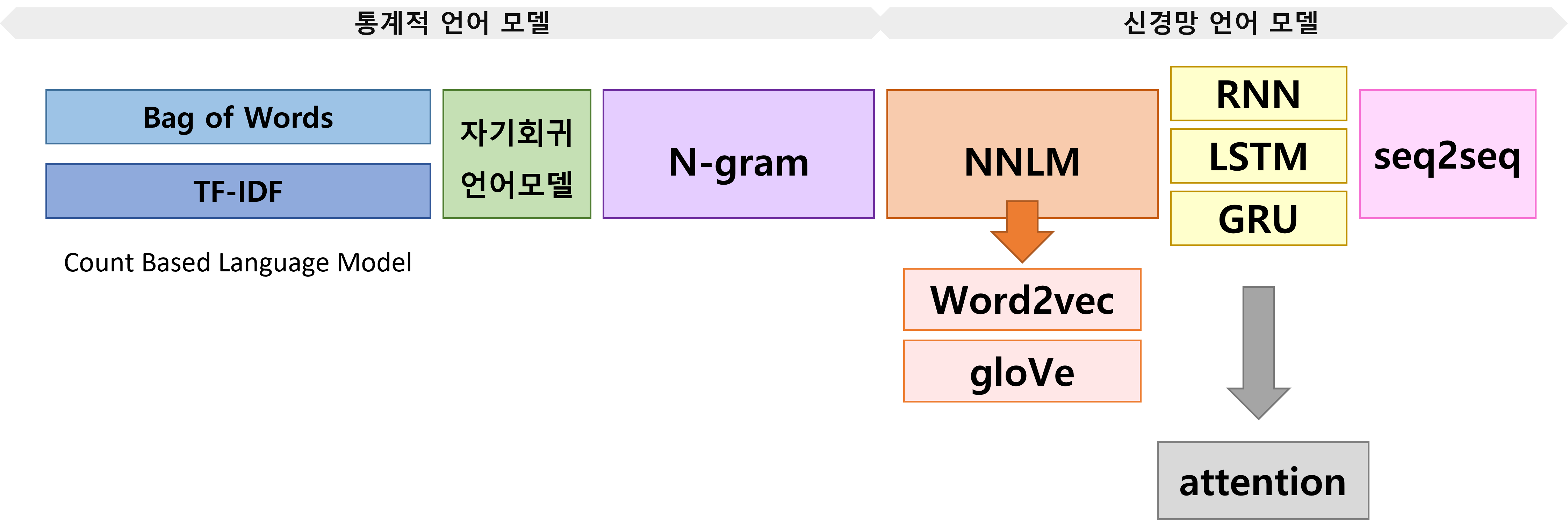
세미나를 준비하며.. 전반적인 흐름을 공부해보자
2.N-gram 언어모델

1)
3.NNLM(피드 포워드 신경망 언어 모델)
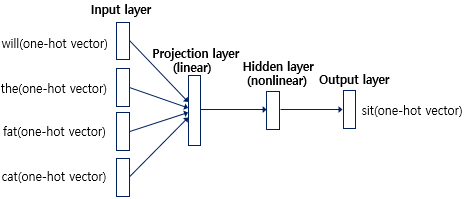
과거에는 기게가 자연어를 학습하게 하는 방법으로 통계적인 접근(통계적 언어모델, SLM)을 사용하였으나 최근에는 인공 신경망을 사용하는 방법이 더 좋은 성능을 얻고 있다. 1) N-gram 언어 모델의 한계 : 바로 앞 n-1개의 단어를 참고하여 다음 단어 예측(
4.Word2Vec
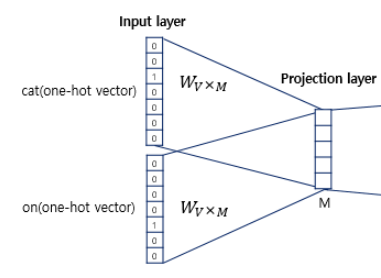
Skip-gram이 CBOW에 비해 더 높은 성능을 보인다.CBOW : 중심단어(벡터)는 단 1번의 업데이트 기회를 가진다.Skip-gram : 중심단어의 업데이트 기회를 여러번 확보할 수 있다.즉, Skip-gram이 훨씬 더 많은 학습량을 가진다.CBOW Skip-
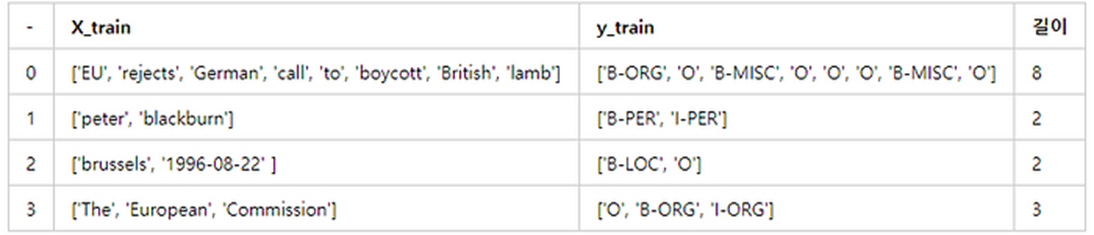
5.Word2Vec 실습

<영어/한국어 Word2Vec 실습>실습 코드https://colab.research.google.com/drive/1gHSsgfaIJb_D65Tydk869kx9Lhu75VWrkonlpy 이용결측값 존재 유무data에 NULL값 존재 유무
6.SGNS(Skip-Gram with Negative Sampling)
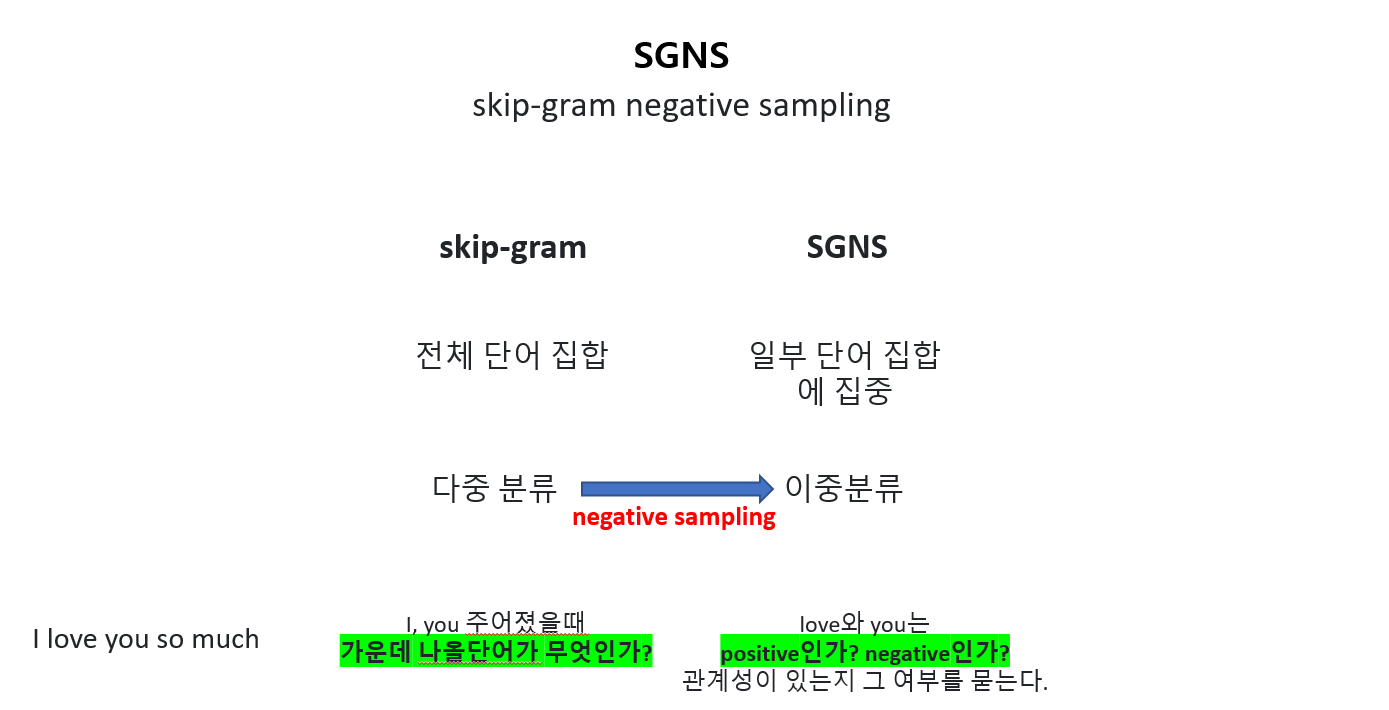
🗻 네거티브 샘플링(Negative Sampling)
7.GloVe(보류)
GloVe는 Word2Vec과 함께 가장 많이 사용되는 워드 임베딩 기법이다.말뭉치 전체의 통계적인 정보를 입력받아 차원을 축소하여 잠재된 의미를 끌어내는 방법론 🚩 문서 전체에 단어가 등장하는 빈도로 워드 임베딩 BUT 단어간 유사도(관계성) 측정 어려움저차원 벡
8.순환 신경망(RNN)
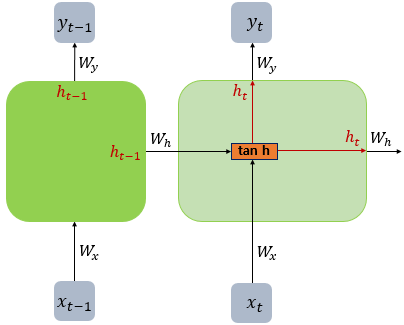
: 입력과 출력을 시퀀스 단위로 처리하는 시퀀스 모델x : 입력층의 입력벡터y : 출력층의 출력벡터cell(셀) : 은닉층에서 활성화 함수를 통해 결과를 내보내는 역할(= 메모리 셀, RNN 셀)t : 현시점은닉층 : 결과값 출력층으로 보내기 or 다시 은닉층 노드의
9.장단기 메모리(LSTM)
바닐라 RNN : 가장 단순한 형태의 RNN비교적 짧은 시퀀스에 대해서만 효과를 보임장기 의존성 문제 : 바닐라 RNN의 시점이 길어질수록 앞의 정보가 뒤로 충분히 전달되지 못함
10.게이트의 순환 유닛(GRU)
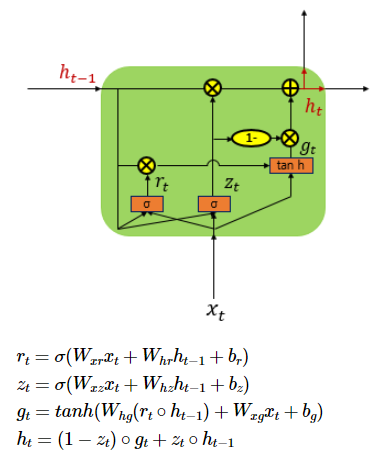
GRU(Gated Recurrent Unit)LSTM의 장기 의존성 문제에 대한 해결 + 은닉 상태 업데이트 연산 줄임즉, LSTM 보다 단순화된 구조 + 성능 우수
11.RNN / LSTM / GRU
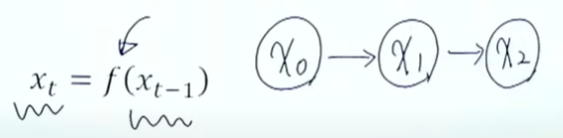
: 시계열 데이터(시간에 따라 변하는 데이터)를 처리하기에 좋은 뉴럴 네트워크 구조EX) 음성인식, 번역기, 감정 분석, 음악 생성기CNN은 이미지 구역별로 같은 weigth를 공유한다면, RNN은 시간별로+과거와 현재가 같은 weight를 공유한다기본가정First O
12.(미완) 태깅 작업(Tagging Task)
RNN의 Mnay-to-many 구조 이용(RNN-스스로 반복하면서 이전 단계에서 얻은 정보가 지속되도록 하는 것)양방향 LSTM 사용(앞,뒤 시점의 입력을 모두 참고)양방향 LSTM (Bi-LSTM)정방향으로 학습하되 -> 마지막 노드에서 역방향으로 실행되는 다른 L
13.서브워드 토크나이저(Subword Tokenizer) -- 5, 6번 추후 추가예정
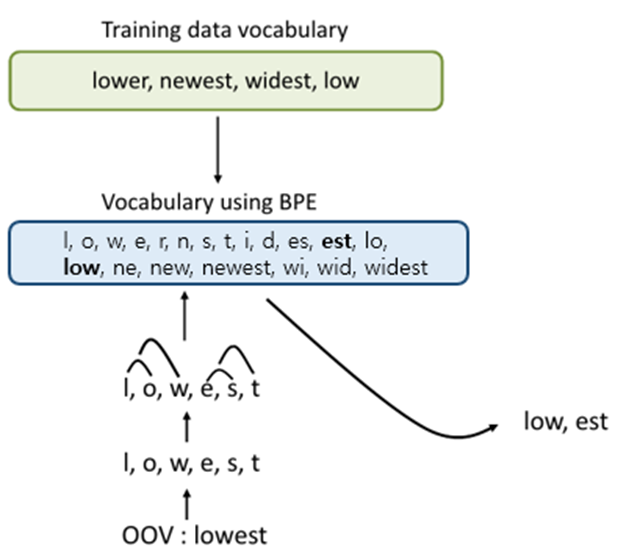
Tokenizing을 할 때어떤 문장이 주어졌을 때, 공백기준으로 + 구두점 제거 등등에 대해서 여러가지 전처리를 해줘야 명확하게 토큰간의 분리를 수행할 수 있다.하지만 예외적으로 Don't는 Do + ' + not으로 분리를 해줘야한다.이러한 예외적인 부분에서 어려
14.seq2seq (sequence-to-sequence)
2개의 RNN을 연결해서 사용하는 인코더-디코더 구조\-> 입력문장과 출력문장의 길이가 다를 경우 사용한다. 예 1) 영어문장을 한국어문장으로 번역한다고 했을 때, 입력문장인 영어문장과 번역된 결과인 한국어 문장의 길이가 똑같을 필요는 없다.예 2) 텍스트 요약의 경우
15.Attention Mechanism
1) 하나의 고정된 크기의 벡터(컨텍스트 벡터)에 모든 정보를 압축하려니 정보 손실 발생2) RNN의 고질적인 문제 Vanishing gradient(기울기 소실) 문제 발생입력 시퀀스가 길어지면 번역 품질이 떨어지는 것을 보정해주기 위한 기법⭐Attention 등장⭐
16.Transformer
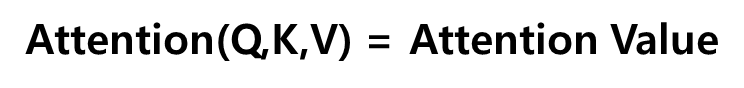
Attention(Q,K,V) = Attention ValueAttention Score 계산: Query (디코더의 특정 시점 t의 은닉 상태)와 각 Key (인코더의 모든 시점의 은닉 상태) 사이의 유사도를 계산합니다. 이 유사도는 내적(dot product)을 통
17.BLEU score (생성형LM 평가방법)

정성적 평가: 사람이 직접 번역된 문장을 채점하는 주관적 평가정량적 평가: 수치를 이용한 객관적인 평가 \- BLEU score \- ROUGE \- PPL(Perplexity)(bilingual evaluation understudy)참고자료https://d