과거에는 기게가 자연어를 학습하게 하는 방법으로 통계적인 접근(통계적 언어모델, SLM)을 사용하였으나
최근에는 인공 신경망을 사용하는 방법이 더 좋은 성능을 얻고 있다.
1) N-gram 언어 모델의 한계
: 바로 앞 n-1개의 단어를 참고하여 다음 단어 예측(가장 전통적인 통계적 자연어 처리방식)
(4-gram -> 바로 전 3개의 단어만 참고)
BUT n-gram 언어 모델은 충분한 데이터를 관측하지 못하면 언어를 정확히 모델링하지 못하는 희소 문제(sparsity problem)가 있다.
2) 희소문제 해결 -> 단어의 '의미적 유사성'
: 단어의 의미적 유사성을 학습할 수 있도록 설계하면,
훈련 코퍼스에 없는 단어라도 유사한 단어가 사용된 단어 시퀀스를 참고해 예측이 가능하다.
3) NNLM
: 단어의 의미적 유사성을 학습할 수 있도록 설계한 신경망 언어 모델
(워드 임베딩의 아이디어)
- 원-핫 벡터를 이용해서 만들었다는 점
> 과정
훈련 코퍼스(예문) 준비
💨 모든 단어 수치화(원-핫 벡터)
💨 정해진 개수(n개)의 단어만 참고(윈도우)
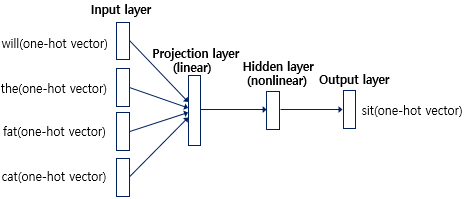
💨 입력층 - n개의 layer로 이루어진 인공 신경망 / 출력층 - 정답 단어가 레이블로 사용됨(오차구하기 위해)
💨 투사층(projection layer) : 활성화 함수 존재 X
각 입력단어들은 룩업 테이블이 만들어진다.
(input의 원-핫벡터 X projection의 가중치)
(W의 특정 행을 그대로 읽어온 룩업 테이블)

(N:입력받은 input의 수, M:투사층 크기, V:단어 집합의 크기)
- input이 projection layer를 거치면서 차원 수가 줄어든다.
- e_fat은 학습을 하는 동안 계속 바뀌는 embedding vector이다.
- 활성화 함수가 없어서 projection layer에서 나온값이 hidden layer 그대로 들어감
💨 룩업테이블 후 V차원의 원-핫벡터는 M차원의 벡터로 맵핑된다.
이 값들은 초기에는 랜덤한 값을 가지지만
학습과정에서 값이 계속 변경된다
= 임베딩 벡터
💨 투사층에서 모든 임베딩 벡터들의 값이 연결됨(합성곱)(concatenate)
ex) 5차원 벡터 4개를 연결한다 = 20차원의 벡터를 얻는다

💨 결과적으로 단어들은 유사한 임베딩 벡터값을 얻게된다.
따라서, 훈련 코퍼스에서 없던 단어 시퀀스라 하더라도 다음 단어를 선택할 수 있다.
임베딩 벡터 아이디어는 Word2Vec등으로 발전해서 딥러닝 자연어 처리 모델에서는 필수가 됨..
모델링 학습 과정
1) "what will the fat cat sit on" 문장 -> "what will the fat cat ____ on" 의 빈칸을 예측하는 문제
2) "will", "the", "fat", "cat"의 네가지 단어로 다음 단어를 예측하고자 함.
3) window: 특정 단어를 예측하기 위해 앞(또는 뒤)의 단어 몇 개를 참고할 것인지의 지표(window size = 4)
선형 함수란 출력이 입력의 상수배만큼 변하는 함수(은닉층으로 쌓는게 의미가 없음)
비선형 함수는 직선 1개로는 그릴 수 없는 함수(은닉층)
투사층과 은닉층
투사층-선형층/활성화함수X
은닉층-비선형층/활성화함수o
둘의 공통점 : 가중치 행렬과의 연산이 이루어짐
테이블 룩업 -> 원-핫 벡터를 더 차원이 적은 임베딩 벡터로 맵핑
투사층 은닉층 둘다 사용하는 이유가 무엇인가???????
https://warm-uk.tistory.com/9
첫째, 투사층은 입력된 단어들을 고정 길이의 벡터로 표현하기 위한 작업을 수행합니다. 이를 위해 입력 단어들의 원핫 인코딩 벡터를 저차원의 밀집 벡터(dense vector)로 변환합니다. 이 과정을 통해 단어 간의 유사성을 측정할 수 있으며, 입력 단어의 문맥 정보를 보존하는 데 도움이 됩니다.
둘째, 은닉층은 투사층의 출력을 입력으로 받아, 다음 단어를 예측하기 위한 작업을 수행합니다. 은닉층은 입력 단어들의 문맥 정보를 학습하고, 이를 기반으로 다음 단어를 예측합니다. 이러한 과정에서 은닉층은 단어 간의 추상적인 관계를 학습할 수 있으며, 이를 통해 더 정확한 예측이 가능해집니다.
투사층에 활성화 함수를 적용하지 않은 이유는 주로 계산 효율성과 훈련 안정성을 개선하기 위함입니다.
투사층의 목적은 입력 단어를 저차원의 밀집 벡터로 변환하는 것입니다. 이때 활성화 함수를 사용하면 변환된 벡터의 각 원소가 비선형적으로 변환되므로 표현 능력은 높아지지만, 계산량이 증가하게 됩니다. 또한, 활성화 함수를 사용하면 그래디언트가 잘 전파되지 않는 문제가 발생할 수 있으며, 이는 모델의 훈련 안정성을 저해할 수 있습니다.
따라서, NNLM에서는 활성화 함수를 사용하지 않고 선형 변환(linear transformation)만을 사용하여 입력 단어를 변환합니다.
RNN와 차이
은닉층의 출력값을 출력층으로도 내보내지만, 동시에 은닉층의 출력값이 다시 은닉층의 입력으로 사용됨
4) NNLM의 한계
이점
- 임베딩 벡터를 사용해 단어를 표현하므로 단어의 유사도를 계산할 수 있다.
-> 희소문제 해결 - n-gram 언어모델보다 저차원이므로 저장 공간을 적게 사용
한계
- 고정된 길이의 입력
모든 이전 단어를 참고하는 게 아니라 정해진 n개의 단어만을 참고할 수 있다.
==> RNN 언어 모델이 한계 극복
참고하기
https://hul980.tistory.com/m/34
활성화 함수-비선형(직선 1개로 그릴수없는 함수)
인공신경망은 성능 향상을 위해 은닉층을 계속해서 추가해야하는데
선형함수를 사용하면 은닉층을 계속 쌓을 수가 없음
(선형함수로는 은닉층을 추가해도 여러번 추가한 것과 1회 추가한 것의 차이가 없음)
손실함수
실제값과 예측값의 차이를 수치화 해주는 함수
오차가 클수록 손실함수 크다
오차가 작을수록 손실함수 작다
매개변수는 가중치와 편향
-> 이 손실함수의 값을 최소화 하는 과정이 가중치와 편향값을 찾아가는 과정이고 학습 과정이다.
