pandas
: 데이터 분석과 관련된 다양한 기능을 제공하는 python 패키지
(python을 exel처럼 사용 할 수 있는 libray)
→ 데이터 셋을 이요한 다양한 통계 기능을 다루는데 특화되어있는 pytohb모듈
→ Series, DataFrame 제공 - 표 형태 데이터 다루기 위하여
- Series : 1차원 자료구조를 표현 - 데이터가 나열된 방향이 한 방향
- DataFrame : 2차원 행렬구조의 표(table)을 표현 - 데이터가 나열된 방향이 두 방향
설치:
pip install pandas
conda install pandas
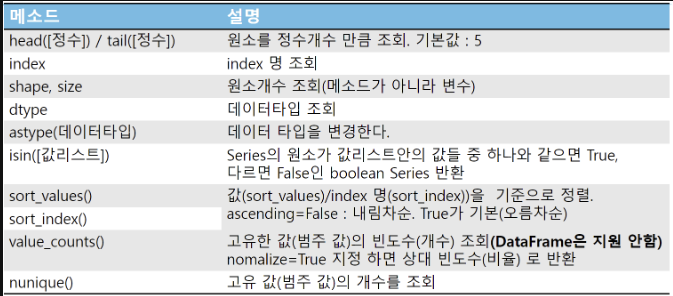
series
- 1차원 자료구조
- DataFrame(표)의 한 행(row)이나 한 열(column)을 표현
- 각 원소는 index와 index 이름을 가지며 그것들을 이용해 사용할 수 있음
- 벡터화 연산(element-wise 연산)을 지원
- Series 객체에 연산을 하면 각각의 Series 원소들에 연산이 됨
- Series를 구성하는 원소들을 다루는 다양한 메소드 제공
dictionary + list 의 형태라 생각 가능
구문
: Series(1차원 배열형태 자료구조)
→ 배열형태(array-like) 자료구조
- 리스트
- 튜플
- 넘파이 배열(ndarray)
Series안의 원소(element) 접근 - Indexing & Slicing
- Index는 Series에 저장된 각 원소를 구분하는 식별자로 각 원소를 사용할때 사용. Series의 원소들은 두 종류의 index를 가짐
- index(순번)
- 자동으로 배정되는 순번
- 리스트나 튜플의 index와 동일.
- 0 부터 1씩 증가하는 양수 index와 -1 부터 1씩 감소하는 음수 index 두가지가 붙는다. 양수 index는 앞에서 부터, 음수 index는 뒤에서 부터 붙음
- index name(index이름)
- 명시적으로 각 index에 지정하는 이름
- 딕셔너리의 key의 역할을 함
- Series의 index name은 중복될 수 있음
- 생략하면 양수 index가 index name이 됨
- Index와 index name 두가지의 식별자가 붙는 것은 Series, DataFrame 동일
- Series나 DataFrame을 출력하면 나오는 index는 index name. 자동으로 붙는 index는 판다스 내부에서 관리됨
- index(순번)
Indexing
- index 순번으로 조회
:Series[순번]Series[순번]: spprecated
Series[순번]Series.iloc[순번]- iloc indexerSeries[순번]: spprecated
→ series는 웬만하면 이것으로 해결 가능→ 그러나 그러지 못할 경우에는 loc index나 iloc index중에 무었을 사용해야 할지 결정 필요
:Series.iloc[순번]-> iloc indexer
index는 내부적으로 관리되는 값
- index 이름으로 조회
:Series[index 이름]
:Series.loc[index 이름]-> loc indexer- index 이름이 문자열이면 문자열(" ") 로, 정수이면 정수로 호출
s['name'], s[2], s.loc['name'], s.loc[2]
- Series.index 이름
- index의 이름이 파이썬 식별자 규칙에 맞을 경우
. 표기법사용 할 수 있음
- index의 이름이 파이썬 식별자 규칙에 맞을 경우
- index 이름이 문자열이면 문자열(" ") 로, 정수이면 정수로 호출
- Series[index]는 기본적으로 Index명으로 조회.
- index 이름과 index의 타입이 다르면 알아서 처리함
- index 이름의 type이 int일 때 index(순번)으로 조회하고 싶은 경우 (index이름과 index 의 타입이 int로 같은 경우)
- iloc indexer를 사용
Series객체.iloc[순번]
- 팬시(fancy) 인덱싱
-Series[index리스트]- 한번에 여러개의 원소를 조회할 때 그 index들을 list로 묶어서 전달
series[[1,2,3]]
- 한번에 여러개의 원소를 조회할 때 그 index들을 list로 묶어서 전달
Slicing
: 범위로 원소들을 조회할 때 사용
- Series[start index : stop index : step]
- start index 생략 : 0번 부터
- stop index
→ index 순번일 경우는 포함 하지는 않음.
→ index 명의 경우는 포함 - stop index 생략 : 마지막 index까지
- step 생략 : 1씩 증가
- Slicing의 결과는 원본의 참조(View)를 반환
- Slicing은 shallow copy함. 그래서 slicing한 결과를 원소를 변경하면 slicing 했던 원본도 같이 바뀜
- 원본은 변경되지 않게 하려면
slicing결과.copy()를 이용해 deep copy를 해야 함
- shallow copy와 deep copy
- deep copy(깊은 복사)
- 원본과 동일한 값을 가진 새로운 객체를 만들어 반환 -> 그래서 복사본의 값을 변경해도 원본이 변경되지 않음
- 파이썬 리스트는 slicing시 deep copy를 함
- shallow copy(얕은 복사)
- 원본을 반환하여 값 변경시 원본에 영향을 줌
- Series, DataFrame, 넘파이 배열(ndarray)은 slicing 조회 시 shallow copy
- copy() 메소드
- Series, DataFrame, ndarray를 deep copy
백터화
- Pandas의 Series나 DataFrame은 연산을 하면 원소 단위로 연산
- element-wise 연산 이라고도 함
- Series/DataFrame과 값(scalar값)을 연산하면 각 원소들과 값을 연산
- Series끼리 또는 DataFrame끼리 연산을 하면 같은 위치의 원소끼리 연산
- Index 이름이 (index가 아닌) 같은 원소끼리 연산
boolean 인덱싱
- Series의 indexing 연산자에 boolean 리스트를 넣으면 True인 index의 값들만 조회
- 원하는 조건의 값들을 조회할 때 사용논리연산자 설명 & and연산 | or연산 ~ not 연산
- 논리연산자의 피연산자들은 반드시 ( )로 묶어줌
- 파이썬과는 다르게
and,or,not은 예약어는 사용할 수 없음
- Series에서
특정 조건이 True인 원소들을 조회
: boolean indexing특정 조건이 True인 원소들의 index를 조회
: numpy.where(boolean 연산)특정 조건이 True인 원소와 False인 원소를 각각 다른 값으로 변경
: numpy.where(boolean 연산, True변환값, False변환값)
주요 method
정렬
- sort_values()
- 값으로 정렬
- sort_index()
- index명으로 정렬
- 공통 매개변수
- ascending=False (내림차순, 기본-True:오름차순)
- inplace=True
- 원본 자체를 정렬
- False(기본값): 정렬결과를 새로운 Series로 반환.
- 결측치(NaN)는 정렬 방식과 상관없이 마지막에 나온다.
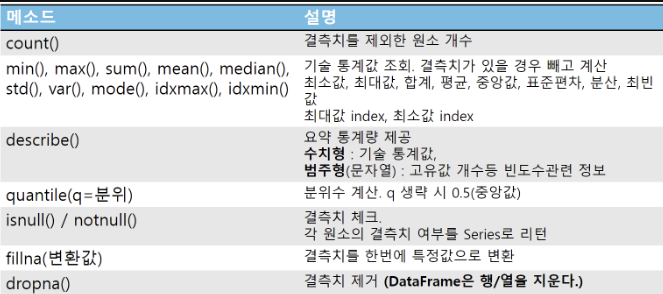
기술 통계량
: 데이터셋들의 제이터들의 특징을 하나의 숫자로 요약산 것
- 평균
-> 전체 데이터들의 합계를 총 개수로 나눈 통계량
-> 전체 데이터셋의 데이터들은 평균값 근처에 분포되어 데이터셋의 대표값으로 사용
-> 이상치(너무 크거나 작은 값) 의 경향을 많이 받음
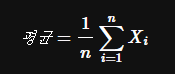
중앙값
: 분포된 값들을 작은 값부터 순서대로 나열한 두 구 중앙에 위치한 값
-> 이상치에 영향을 받지 않아 평균 대신 집단의 대표값으로 사용
표준편차 / 분산
- 값들이 흩어져있는 상태(분포)를 추정하는 통계량으로 분포된 값들이 평균에서 부터 얼마나 떨어져 있는지를 나타내는 통계량.
- 각 데이터가 평균으로 부터 얼마나 차이가 있는지를 편차(Deviation)라고 한다. ()
분산
: 편차 제곱의 합을 총 개수로 나눈 값
표준편차
: 분산의 제곱근
: 분산은 원래 값에 제곱을 했으므로 다시 원래 단위로 계산한 값.
최빈값 mode
: 데이터 셋에서 가장 많이 있는 값
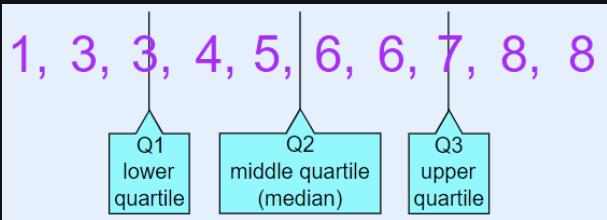
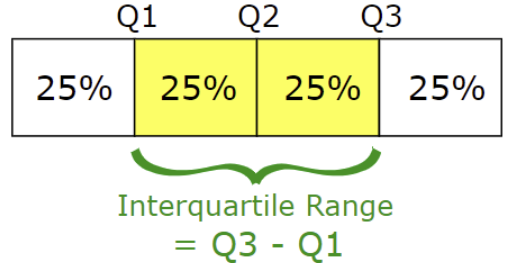
분위수 Quantile
: 데이터의 크기에 따른 위피 값
-> 데이터셋을 크기순으로 정렬한뒤 N등분했을 때 특정 위치에서의 값 (단면)
-> N등분한 특정위치의 값들 통해 전체 데이터셋을 분포를 파악한다.
- 대표적인 분위수 : 4분위, 10분위, 100분위
-> 데이터의 분포를 파악할 때 사용
-> 이상치 중 극단값들을 찾을 때 사용 (4분위수)
결측치 (Missing Value, Not Available)
- 결측치
: 모르는 값, 수집이 안된값, 현재 가지고 있지 않은 값. - 판다스에서 결측치
- None, numpy.nan, numpy.NAN
- 결측치는 float 타입으로 처리됨
결측치 확인
- 각 함수/메소드는 각 원소별로 결측치인지 확인해서 결과를 반환
- Numpy
- np.isnan(배열)
import numpy as np
a = np.array([1,np.nan])
np.isnan(a)- Series/DataFrame
- Series/DataFrame객체.isnull() 또는 isna()
- Series/DataFrame객체.notnull() 또는 notna()
결측치 처리
- 제거
- dropna()
- 다른값으로 대체
- fillna()
- 평균, 중앙값, 최빈값을 주로 사용
