DataFrame
: 표(table - 행렬)을 다루는 Pandas의 타입
(Database 의 Table이나 Exvel의 표와 동일한 역할)
→ 분석할 데이터를 가지는 판다스의 가장 핵심적인 class
→ 행(row), 열(column)로 구성
→ 하나의 해과 하나의 열은 Series로 구성됨
→ DataFrame 객체는 직접 데이터를 넣어 생성하거나 데이터 셋을 파일(csv, 엑셀, DB 등)로 부터 읽어와 생성
- 각 행과 열은 식별자를 가지며 Series와 같이 2종류가 있음
- 순번
→ 양수, 음수 index 두가지
→ 컬럼도 내부적으로는 순번으로 관리되지만 우리가 조회할 때 사용 불가 - 이름
→ 명시적으로 지정한 행과 열의 이름
→ 행 이름: index name, 열 이름: column name (중복 가능)
→ 명시적으로 지정하지 않을 시 양수 순번이 index, column이 이름으로 설정됨
- 순번
DataFrame 생성
직접 생성
pd.DataFrame(data [, index=None, columns=None])- data
- DataFrame을 구성할 값을 설정
- Series, List, ndarray를 담은 2차원 배열
- 열이름을 key로 컬럼의 값 value로 하는 딕션어리(사전)
- DataFrame을 구성할 값을 설정
- index
- index명으로 사용할 값 배열로 설정
- columns
- 컬럼명으로 사용할 값 배열로 설정
- data
ex)
import pandas as pd
#dictionary 이용
data = {
"id": ['id-1', 'id-2', 'id-3', 'id-4', 'id-5'],
"국어" : [100, 80, 90, 70, 80],
"영어": [80, 90, 75, 80, 60]
}
grade = pd.DataFrame(data)
grade - key(컬럼명): values(1차원자료구조 - 컬럼의 값들) - 각 value의 원소 개수는 동일해야 함
- index 일믜: 따로 지정하지 암으면()index=[index 이름들] 양수index 가 이름이 된다
- print를 사용하지 않고 그냥 뽑을것만 작성하면 표 형태로 제공하기 때문에 좋음
- 만약 ggrade.T라고 하면은 column과row 가 서로 뒤집힘
→ 하지만 이런 방식은 사용 안함
DataFrame 저장
DataFrame의 객체를 파일에 저장
- DataFrame객체는 다양한 형식의 파일로 저장할 수 있음
- 기본구문
DataFrame객체.to_파일타입()
CSV 파일로 저장
DataFrame객체.to_csv(파일경로,sep=',', index=True, header=True)- 텍스트 파일로 저장
- 파일경로: 저장할 파일경로(경로/파일명)
- sep : 데이터 구분자
- index, header: 인덱스/헤더 저장 여부
- encoding방식: UTF-8 로 저장됨
엑셀로 저장
-
DataFrame객체.to_excel(파일경로, index=True, header=True) -
index명은 굳이 저장 할 필요 없이 불러올 때 자동으로 인출할 수 있음 ( index 명이 자동 증가인 경우가 해당)
기타 저장
- pickle
grade.to_pickle('saved_data/grade.pkl')- html
grade.to_html('saved_data/grade.html', index=False)파일로 부터 데이터셋을 읽어와 생성하기
csv 파일 등 텍스트 파일로 부터 읽어와 생성
구문
: pd.read_csv(파일경로, sep=',', header, index_col, na_values)
-
파일경로
→ 읽어올 파일의 경로- sep=","
- 데이터 구분자.
- 기본값: 쉼표
- header=정수
- 열이름(컬럼이름)으로 사용할 행 지정
- 기본값: 첫번째 행
- None을 설정하면 Header는 없다는 것으로 파일의 첫번째 행부터 값으로 사용하고 컬럼명은 0부터 자동증가하는 값을 붙임
- index_col=정수,컬럼명
- index 명으로 사용할 열이름(문자열)이나 열의 순번(정수)을 지정
- 생략시 0부터 자동증가하는 값을 붙임
- na_values
- 읽어올 데이터셋의 값 중 결측치로 처리할 문자열 지정
- sep=","
주요 method, 속성
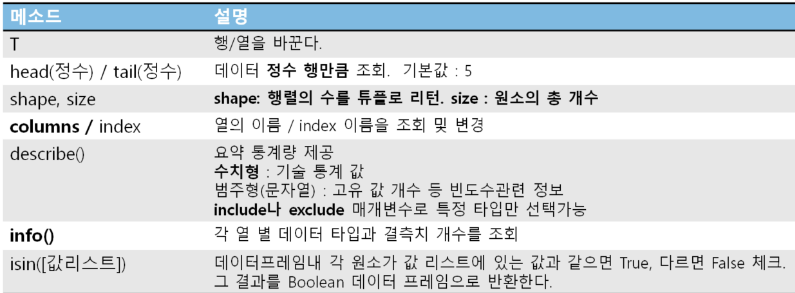
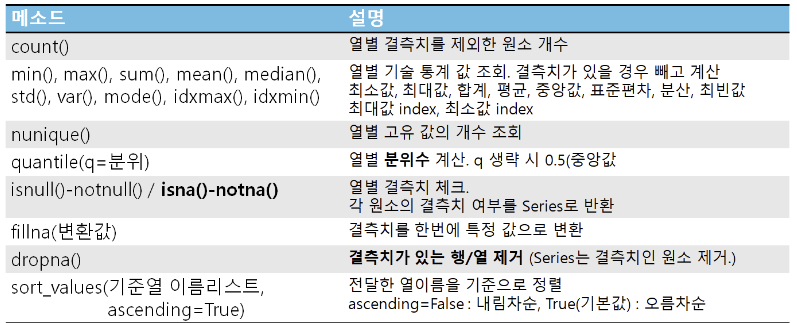
데이터 프레임의 기본 정보 조회
- csv 파일 읽기
- shape
- info()
- head()
- tail()
- isnull().sum()
- 컬럼별 null 체크 (sum() 한번 더 하면 총개수)
- describe() : 숫자형-기술통계값, 범주형-총개수, 고유값들, 최빈값
컬럼이름/행이름 조회 및 변경
컬럼이름/행이름 조회
- DataFrame객체.columns
- 컬럼명 조회
- 컬럼명은 차후 조회를 위해 따로 변수에 저장하는 것이 좋음
- DataFrame객체.index
- 행명 조회
컬럼이름/행이름 변경
- columns와 index 속성으로는 통째로 바꾸는 것은 가능하나 일부만 선택해서 변경하는 것은 안된다.
df.columns = ['새이름','새이름', ... , '새이름']df.columns[1] = '새이름'- 이런식으로 개별적으로 변경은 안됨
구문:
DataFrame객체.rename(index=행이름변경설정, columns=열이름변경설정, inplace=False)
특정 컬럼을 행의 index 명으로 사용
열이 index명이 되면서 그 컬럼은 Data Set 에서 제거됨
DataFrame객체.reset_index(inplace=False)
- index를 첫번째 컬럼으로 복원
행과 열의 값 변경
특정 행 또는 열 삭제
-
DataFrame객체.drop(columns, index, inplace=False)- columns : 삭제할 열이름 또는 열이름 리스트
- index : 삭제할 index명 또는 index 리스트
- inplace: 원본을 변경할지 여부(boolean)
행, 열의 값 조회
-
indexer 연산자를 이용한다.
- 행은 loc indexer, iloc indexer를 사용한다.
-
열은 indexing만 되고 slicing은 안된다.
-
행은 indexing, slicing 모두 지원한다.
열의 값 조회
-
df['열이름']
- 열이름의 열 조회
-
df.열이름
- 열이름이 Python 식별자 규칙에 맞으면 . 표기법을 사용할 수 있다.
-
Fancy indexing
- 여러개의 열들을 한번에 조회할 경우 열이름들을 리스트로 묶어서 전달한다.
-
주의
-
열은 순번으로는 조회할 수 없다.
-
열 조회 indexer에서 슬라이싱을 하면 행 조회 Slicing이다.
- 만약 indexing이나 slicing을 이용해 열들을 조회하려면 columns 속성을 이용한다.
-df[df.columns[:3]]
행 조회
-
-
loc : index 이름으로 조회
-
iloc : 행 순번으로 조회
loc indexer
- index name으로 조회
DF.loc[ index이름 ]- 한 행 조회.
- 조회할 행 index 이름(레이블) 전달
- 이름이 문자열이면 " " 문자열표기법으로 전달. 정수이며 정수표기법으로 전달한다.
DF.loc[ index이름 리스트 ]- 여러 행 조회.
- 팬시 인덱스
- 조회할 행 index 이름(레이블) 리스트 전달
DF.loc[start index이름 : end index이름: step]- 슬라이싱 지원
- end index 이름의 행까지 포함한다.
DF.loc[index이름 , 컬럼이름]- 행과 열 조회
- 둘다 이름으로 지정해야 함.
iloc indexer
-
index(행 순번)으로 조회
-
DF.iloc[행번호]- 한 행 조회.
- 조회할 행 번호 전달
-
DF.iloc[ 행번호 리스트 ]- 여러 행 조회.
- 조회할 행 번호 리스트 전달
-
DF.iloc[start 행번호: stop 행번호: step]- 슬라이싱 지원
- stop 행번호 포함 안함.
-
DF.iloc[행번호 , 열번호]-
행과 열 조회
-
행열 모두 순번으로 지정
loc은 이름(column name), iloc은 번호(index)
-
Boolean indexing을 이용한 조회
-
원하는 조건을 만족하는 행, 열을 조회한다.
-
DataFrame객체[조건], DataFrame객체.loc[조건]- 조건이 True인 행만 조회
- 열까지 선택시
DataFrame객체[조건][열]DataFrame객체.loc[조건, 열]
-
iloc indexer는 boolean indexing을 지원하지 않는다.
-
논리연산자
| 논리연산자 | 설명 |
|---|---|
| & | and 연산 |
| \ | or 연산 |
| ~ | not 연산 |
- 논리연산자의 피연산자들은 반드시 ( )로 묶어준다.
- 파이썬과는 다르게
and,or,not예약어는 사용할 수 없다.
query() 를 이용한 boolean indexing
- query(조회조건)
- sql의 where 절의 조건 처럼 문자열의 query statement를 이용해 조건으로 조회
- boolean index에 비해
- 장점: 편의성(문자열로 query statement를 만들므로 동적 구문 생성등 다양한 처리가 가능)과 가독성이 좋음
- 단점: 속도가 느림
- 조회조건 구문
"컬럼명 연산자 비교값"
- 외부변수를 이용해 query문의 비교값을 지정할 수 있음
- query 문자열 안에서 @변수명 사용
- f string이나 format() 함수를 이용해 query를 만들 수도 있음
query 함수 연산자
-
비교 연산자
- ==, >, >=, \<, \<=, !=
-
결측치 비교
- 컬럼.isna(), isnull()
- 컬럼.notna(), notnull()
-
논리 연산자
- and, or, not
-
in 연산자
- in, ==
- not in, !=
- 비교 대상값은 리스트에 넣기
-
Index name으로 검색
- 행의 index 이름으로 검색
- 문자열 부분검색(sql의 like)
컬럼명.str.contains(문자열): 문자열을 포함하고 있는컬럼명.str.startswith(문자열): 문자열로 시작하는컬럼명.str.endswith(문자열): 문자열로 끝나는- 문자열 부분검색을 할 컬럼에 결측치(NaN)이 있으면 안됨
