동물원 - 구역을 나누고 각 구역에 의미를 부여해서 구분. (육식동물, 초식동물, 식물원 등) 내가 원하는 구역에서, 내가 찾고 싶은 동물을 찾으면 된다. => 해싱과 유사!
1. 정적 해싱
해시의 구조
해싱의 개념
-
해시(hash)
- 탐색키에 산술적인 연산을 통해 버킷의 주소를 계산하는 해시 함수를 사용하여 데이터 배분 및 접근하는 방법.
탐색키에 산술적 연산을 해 나온 숫자에 맞춰 레코더의 포인터를 배치
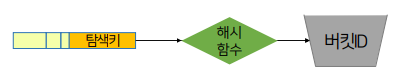
- 탐색키에 산술적인 연산을 통해 버킷의 주소를 계산하는 해시 함수를 사용하여 데이터 배분 및 접근하는 방법.
-
버킷(bucket)
- 한개 이상의 레코드를 저장할 수 있는 저장공간의 단위
- 크기는 일반적으로 디스크 블록의 크기와 일치
해시의 구조
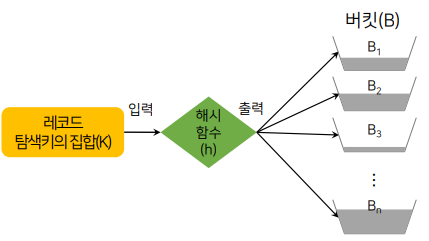
일반적으로 해시는 여러개의 버킷을 통해 자료를 저장. 해시함수는 탐색키를 입력받고 저장될 버킷의 ID를 출력해주는 역할을 함.
해시의 사용
해시에 있는 데이터는 어떻게 알 수 있을까?
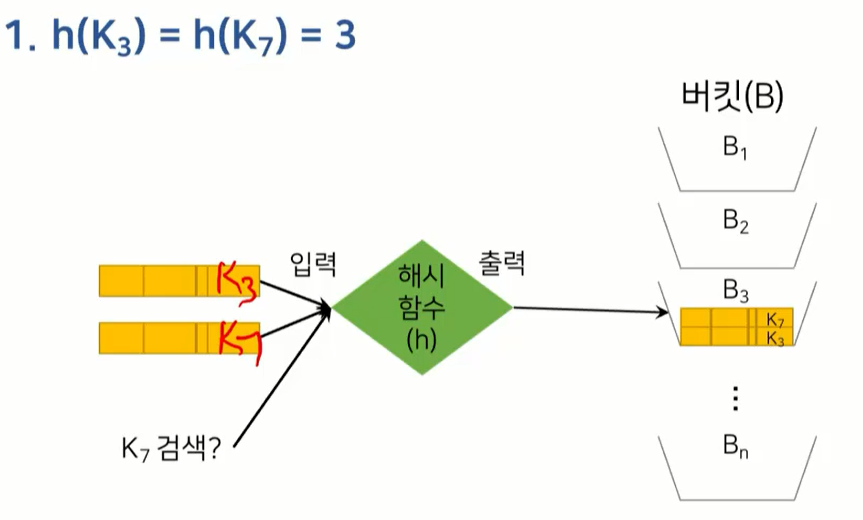
해시함수에다가 탐색키(K3, K7)를 넣으면 그 데이터가 있는 버킷(B3)의 위치를 알려줌.
해시 함수의 역할
| 최선 | 최악 | 일반 |
|---|---|---|
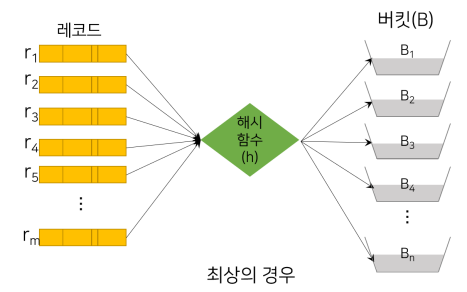 | 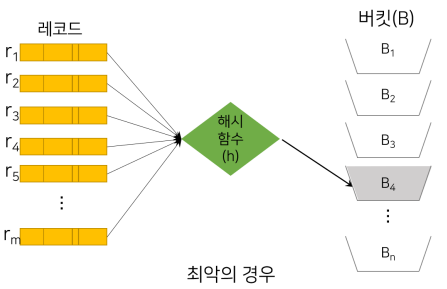 | 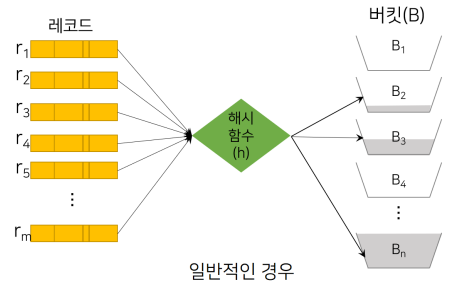 |
| 여러개의 레코드가 모든 버킷에 균등하게 배분하는것. | 모든 레코드를 하나의 버킷에 배분하는 것. | 균등분배는 거의 이론상으로만 가능하고 좀 몰리는 경향이 있음. |
왜 최악일까?
모든 데이터가 버킷 B4에 들어있음. 그럼 다시 B4에가서 다시 원하는 데이터를 찾아야 함. 이렇게 배분되면 자료를 찾는데 엄청 오래걸리게 됨.
해시 파일 구조
파일구조란 한테이블의 여러 레코드가 디스트의 어느 블럭에 들어갈지 결정하는 것. 이걸 해시함수가 결정하도록 한 것이 "해시파일구조"
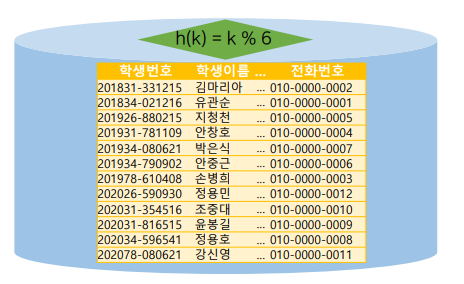
K(학번의 끝자리)
인덱스와는 관련없고 자료를 저장하는 방법론에 관한 이야기.
정적 해싱의 특징
- 버킷의 개수가 고정된 해싱 기법
- 키값이 Ki인 레코드 삽입
- h(Ki)를 통하여 Ki에 대응하는 버킷 주소를 생성하고 레코드를 해당 버킷에 저장
- 키 값이 Ki인 레코드 검색
- h(Ki)를 통하여 버킷 주소를 생성하고 버킷에 저장된 레코드 접근
- h(Ki) = h(Kj) = m인 경우가 발생하기 때문에 버킷 m에 저장된 모든 레코드를 탐색하여 선택하는 과정이 필요.
충돌과 동거자
- 충돌: 서로 다른 두 레코드(탐색키가 다른)가 동일한 버킷에 대응
- 동거자: 충돌에 의해 같은 버킷 주소를 갖는 레코드
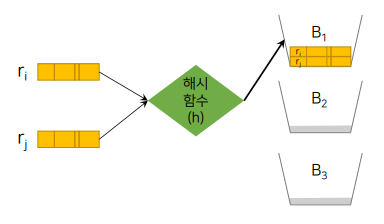
오버플로(overflow)
동거자가 너무 많으면 오버플로가 발생 가능
- 버킷에 레코드를 저장할 수 있는 여유 공간이 없는 상황에 발생
- 추가적인 버킷을 할당 또는 다음 버킷에 할당하여 처리
- 오버플로우가 발생할수록 접근시간이 길어지고 해시 성능이 저하
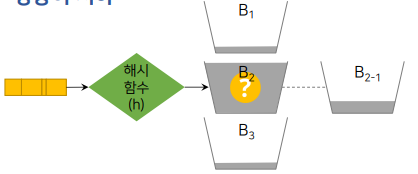
버킷 B2에 들어갈 수 있는 레코드를 초과해서 추가 레코드가 들어오는 경우, B2-1에 넣거나, 그 다음 버킷인 B3에 넣을 수 있음.
만약 탐색키 K5인 레코드를 요구할 때, 해시함수는 B2라고 알려줌. 그 안에 다 뒤졌는데 없으면 연결된 버킷을 메모리에 올려 K5가 나올때까지 더 뒤져봐야 함. 만약 연결된 버킷이 5개이면, 5번의 I/O를 거쳐야 해서 성능 감소가 있게 됨.
오버플로우의 처리 뿐 아니라, 오버플로우의 발생률을 따져보고 이가 발생하지 않는 해시함수를 선택해야 한다.
해시 인덱스
1. 해시 파일 구조와 동작 방식을 레코드가 아닌 인덱스 엔트리에 적용한 인덱스
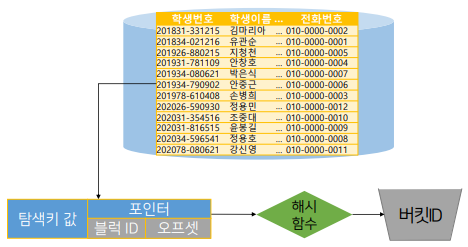
이미 디스크 안에 테이블이 저장되어 있고, (각각의 레코드를 버킷 ID에 저장하는 것이 아니라) 레코드에 접근할 수 있는 인덱스 엔트리를 저장할 버킷ID를 구하는데 해시 함수를 사용한다.
각각의 레코드에 대한 인덱스 엔트리를 만들고, 인덱스 엔트리의 탐색기를 해시함수에 적용하고, 그 값을 버킷 0~5사이에 넣는다.
-
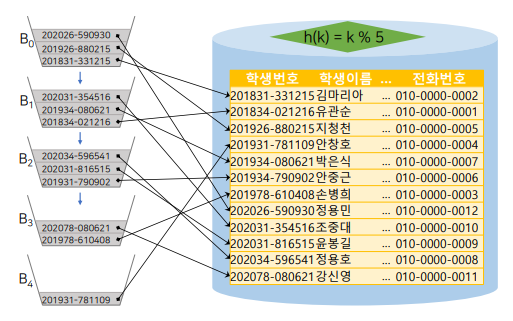
유관순을 찾고 싶어 하는 경우.
끝번호 K=(6 % 5)해시함수 = B1. B1에서 레코드를 찾는다. -
윤봉길 학생은 끝번호가 5인데 왜 B2에 있을까?
오버플로우가 발생하여 그 다음 버킷에 넣어둔 것. B0에 빈공간이 없어서 B1에, 거기에도 없어서 B2까지 밀려나서 레코드를 넣어 둠. 이런 경우, 윤봉길의 레코드를 찾으려면 3번의 I/O를 거쳐야만 데이터를 찾을 수 있음.
정적 해싱의 문제
- 데이터베이스의 크기가 커짐에 따른 성능 감소.
- 테이블 안 레코드의 양이 많아지면 성능은 무조건 떨어짐. 버킷안에서 검색할 데이터가 늘어나므로 재검색 횟수가 더 많이 요구되게 됨.
- 미리 큰 공간을 잡을 경우 초기에 상당한 양의 공간이 낭비
- 재구성 시 새롭게 선택된 해시 함수를 사용하여 모든 레코드에 대하여 다시 계산하고 버킷에 할당하는 대량의 비용이 발생
=> 해시 구조의 크기가 동적으로 결정되는 동적 해싱 기법제안
2. 동적 해싱
동적 해싱의 개념
- 동적 해싱의 정의
- 버킷의 개수를 가변적으로 조절할 수 있는 해싱 기법
- 데이터베이스의 크기에 따라 버킷의 크기가 비례
- 데이터베이스의 증대 혹은 축소에 따른 인덱스의 구조를 조절하기 위해 해시 함수를 동적 변경하는 기술
- 확장성 해싱
(동적 해싱은 여러개 있는데, 주로 확장성 해싱을 사용함)- 동적 해싱의 일종으로 디렉토리와 버킷의 2단계 구조
- 디렉터리는 디스크에 저장되는 버킷 주소 테이블
- 디렉터리 깊이를 의미하는 정수값 d를 포함하는 헤더와 데이터가 저장된 버킷에 대한 2^d개의 포인터로 구성
해시함수가 아니라 디렉터리를 거쳐야지만 버킷에 접근 가능
확장성 해싱
- 모조키(pseudo key)
- 레코드의 탐색키 값이 해시 함수에 의해 일정 길이의 비트스트링으로 변환된 키
- 모조키의 첫 d(몇개의)비트를 사용하여 디렉터리에 접근
- 버킷 헤더
- 정수값 i(<=d)가 저장되어 있음을 표시
- i는 버킷에 저장되어 있는 레코드의 모조키들이 처음부터 i비트까지 일치함을 표시
확장성 해싱의 구조
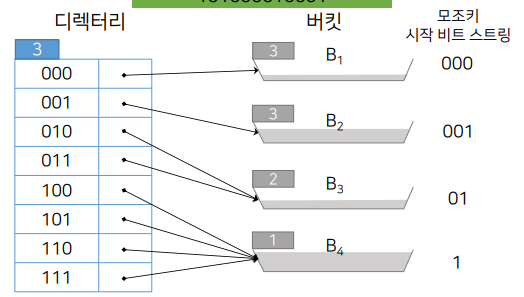
디렉터리 헤더 3: "모조키의 앞 3비트를 보겠다."
B1
버킷의 헤더 3: (=디렉터리 헤더3) "모조키의 앞 3비트를 보겠다."
앞 3비트가 000인 데이터는 다 저에게 주세요
B3
버킷의 헤더 2: "모조키의 앞 2비트를 보겠다."
앞 3비트가 01인 데이터는 모두 저에게 주세요
B4
버킷의 헤더 1: "모조키의 앞 1비트를 보겠다."
앞의 1비트가 1인 데이터는 모두 저에게 주세요

h(k3) (= 탐색기 k3에 해시함수 적용한 값) 으로 위의 모조키를 만들었다. 이 모조키는 어디로 가야할까? => 3비트가 101 => B4로 가야한다!
💬근데 만약에, 이 모조키를 추가하는 상황이라면 어떨까? 디렉터리 구조에 맞춰 해당 모조키가 B4에 입력되야 할 것이다. 그런데 만약, 여기에 더해, B4가 가득 차 오버플로우가 일어나고 있는 상황이라면?
🔍 정적 해싱에서는 연쇄 버킷을 추가해 넣어주거나, 그 뒤의 버킷에 넣었다.
✔️ 그러나 확장성 해싱(동적 해싱)에서는 그 위의 구조인 디렉터리를 이용해 버킷의 갯수를 추가할 수 있다!
확장성 해싱의 분할
1. 레코드 삽입에 의해 분할된 확장성 해싱 파일
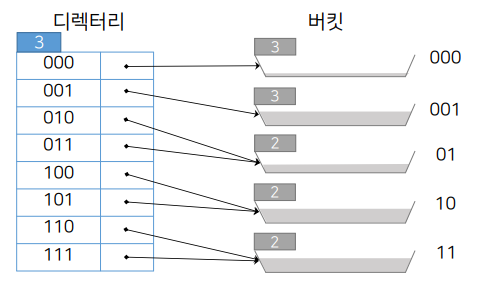
문제가 되는 부분은 B4(시작비트가 1인 모조키를 가진 버킷)이 었다. 이 부분에서 디렉토리를 조정해서, 버킷을 추가했다. 모조키가 1로 시작하는 인덱스 엔트리를 저장하는 버킷을 하나더 추가해 10은 B4에, 11은 B5에 저장되도록 조정했다.
버킷 B1~B3는 어떤 영향도 받지 않았다. 조정되는 것은 B4, B5가 분할된 것 뿐이다. 정적 해싱에 비해 새로운 단계가 추가되어 굉장히 느려질 것 같으나 심각하게 느려지지는 않는다. 디렉토리는 항상 메모리에 적재되어 있어 별도의 디스크 I/O를 발생시키지도 않고, 버킷에 대한 재조정 부분도 향후 오버플로우를 발생시키지 않음을 감안하면 성능저하에 영향이 적은 편이다. 이런 장점으로 확장성 해싱은 자주 사용되는 해싱 기법 중 하나이다.
어떤 해싱을 사용하는게 좋을까?
데이터가 급속도로 증가 & 데이터가 수천배, 수만배 만들어질 수 있는 경우 = 동적해싱 권장
레코드가 항상 유지되는 테이블 = 정적 해싱 권장
3. 비트맵 인덱스
탐색키가 너무 많이 중복되면 순차 인덱스, 해싱 인덱스도 효율서이 많이 떨어짐. 이런 경우 비트맵 인덱스를 이용한다.
비트맵 인덱스의 개념
만약 성별을 인덱스로 사용한다면? 10만명이 있는 데이터에 5만이 여자고 5만이 남자라면 순차 인덱스, 정적 해싱, 동적 해싱 다 효과적이지 못함. 이런 경우 비트맵 인덱스를 사용한다.
- 탐색키의 중복 비율이 높은 컬럼을 대상으로 하는 질의를 효율적으로 처리하기 위해 고안된 특수한 형태의 인덱스
- 비트맵
- 간단한 비트의배열
- 릴레이션r의 속서 A에 대한 비트맵 인덱스는 A가 가질 수 있는 값에 대해 비트맵을 구성
- 각 비트맵은 릴레이션에 있는 레코드의 수 n개만큼 n개의 비트로 표현
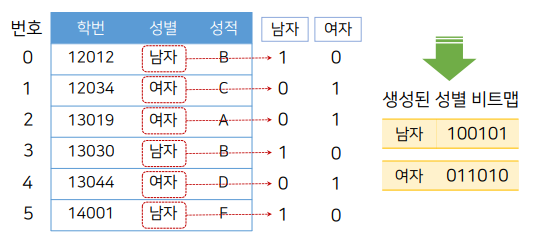
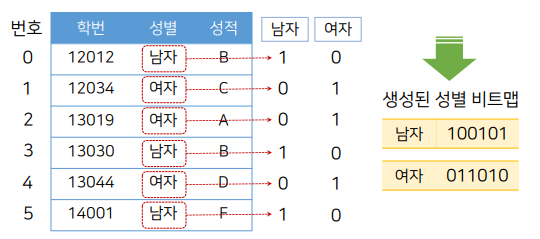
비트맵 인덱스의 구성
1. i번째 레코드가 컬럼 A에 해당 값을 가지면 비트맵의 i번째 비트를 1로, 그렇지 않으면 0으로 설정
비트열: 특정 컬럼이 가질 수 있는 값들의 갯수만큼 만들어짐.
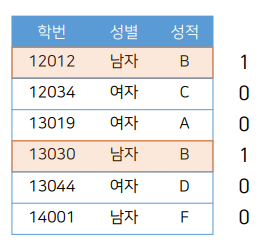
< 성별에 대한 비트맵 >
< 성적에 대한 비트맵 >
비트맵 인덱스의 사용
-
성별이 남자이고 성적이 B인 학생의 정보를 출력
SELECT * FROM 학생 WHERE 성별 ='남자' AND 성적 ='B'
-
성별의 '남자'와 성적의 'B'의 비트열에 대한 비트 논리곱 연산을 수행
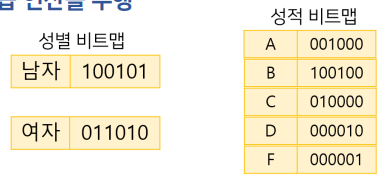
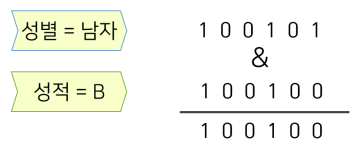
최종적으로 and연산(조건이 or이면 or연산을 해준다)을 수행한 비트열을 가지고, 값이 1인 레코드들이 조건을 만족하는 레코드임을 알 수 있다. 해당 블럭들을 메모리에 적재시켜 결과를 줌으로써 인덱스 역할을 수행할 수 있는 것이 비트맵 인덱스다.
비트맵 인덱스의 특징
- 비트맵의 활용
- 컬럼에 대한 값의 범위가 유한(10개 이내)하고 비교적 적은 규모일 때 용이
- 적용: 직책, 학과, 혈액형 등
(종류가 많은 기본키등에 비트맵 인덱스를 적용하면 급격한 성능저하 유발 가능)
- 비트맵 인덱스의 크기
- 레코드의 크기가 수백 바이트 이상이 되어도 비트맵 인덱스에서는 하나의 비트로 표시
- 실제 릴레이션 크기에 비해 매우 작은 것이 장점
(데이터가 아무리 많아져봐야 1010하는게 그리 큰 용량을 차지 안함)
