오늘은 데이터의 관리가 아닌, 사용성에 대해 논의해보자! 사용자가 데이터를 요구할 때, 사용자의 편리성을 위해 어떻게 하면 빠르게 정보를 제공할 수 있을까? 이 문제에 답변하기 위해 인덱스에 관해 논해봅시다!
1. 인덱스의 이해
인덱스의 개념
인덱스의 필요
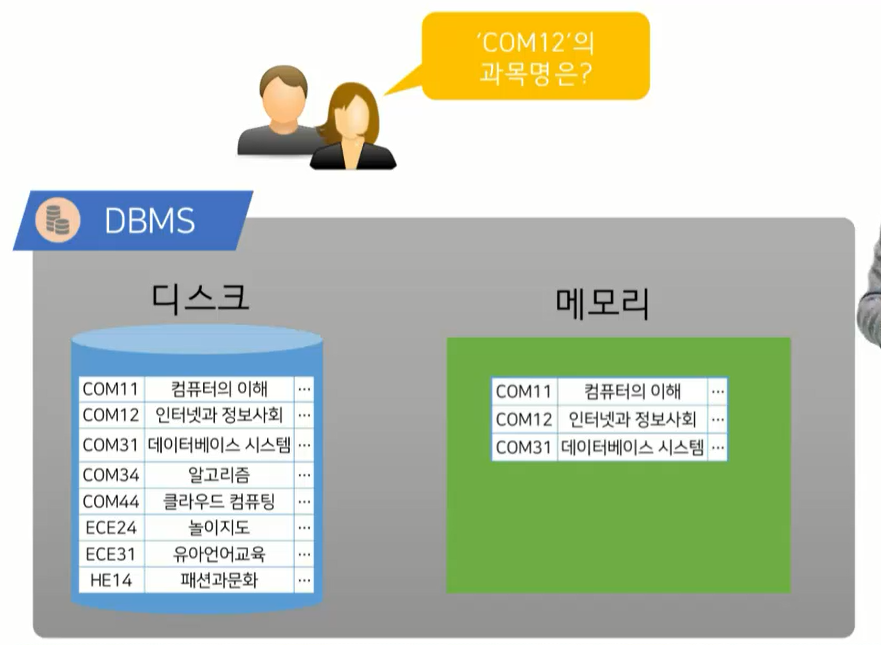
데이터가 디스크에 저장되어있고, 사용자가 특정 자료(COM12)를 요구하면, 메모리에 해당 데이터를 불러와서 대답하는 처리과정을 겪는다. (이전시간에 이걸 배웠다!) 이 지시사항은 간단하나, 만약 사용자가 수천, 수만개의 자료를 요구한다면 디스크와 메모리사이에 수없이 많은 데이터 I/O가 발생하게 되는데, 이는 오랜 시간을 요구하고 DBMS의 성능을 악화시킬 수 있다.
그렇다면, I/O를 줄일 수 있는 방법은 뭘까? 이걸 논의하기 위해 인덱스가 개발되었다!
인덱스의 개념
- 데이터 검색에서 발생하는 비효율적인 데이터 입출력 문제를 해결하기 위한 목적으로 시작
- 인덱스: DBMS에서 요청된 레코드에 빠르게 접근할 수 있도록 지원하는 데이터와 관련된 부가적인 구조
- 인덱싱: 인덱스를 구성하고 생성하는 작업
- 인덱스의 탐색키를 이용하여 해당 레코드가 저장된 블럭을 디스크 저장장치 또는 메모리에서 파악하여 해당 블럭을 빠르게 적재
탐색키: 파일에서 레코드를 찾는데 사용되는 컬럼이나 컬럼의 집합
기본키 외래키와 같은 키값이 아니라, 레코드를 검색할 때 사용할 수 있는 키를 "탐색키"라고 한다!
인덱스가 컬럼이구나.. list의 자료들을 확인할 때 for문의 i를 인덱스로 접근한다고 배웠는데, 그 인덱스가 이 인덱스일까? 그러고보니 정확한 작동 원리를 궁금해하지 않았던것 같다. 넘모재밋다.
인덱스 기반의 검색 과정
인덱스 사용 검색과정은, 사용하지 않는 검색과정과 어떤 차이점이 있을까?

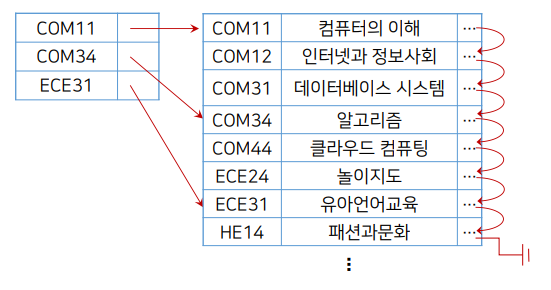
탐색키가 과목 코드로 되어있고, 과목코드와 관련된 데이터가 화살표로 지칭되어 있음. 만약 사용자가 "COM12"를 물어보면, DBMS는 요구 자료와 관련된 레코드 블럭을 올리는것 아니라, 먼제 메모리에 인덱스 블럭을 올린다. 이를 통해 COM12의 위치가 파악하고, 그 위치가 있는 블럭을 불러와서 제공한다.
언뜻 보기에는 한 단계가(인덱스를 메모리에 올리는) 증가하여 더 복잡해 보일 수 있으나, 실제로는 속도면에서 매우 빠르다. 인덱스는 실제 레코드 블럭보다 훨씬 사이즈가 작기 때문에 굉장히 많은 인덱스의 양을 올릴 수 있고, 그래서 그 위치를 빠르게 알 수 있다. 그에 반해 바로 레코드 블럭을 메모리에 올려 레코드를 찾는 것은, 레코드의 양이 많아지는 경우 한번에 많은 양의 레코드를 메모리에 적재할 수 없기 때문에 해당 레코드 위치를 찾는데 오랜 시간이 걸리게 된다.
인덱스의 종류
-
인덱스의 종류
- 순서 인덱스: 특정 값에 대해 정렬된 순서 구조
- 해시 인덱스: 버킷의 범위 안에서 값의 균일한 분포에 기초한 구조로 해시 함수가 어떤 값이 어느 버킷에 할당되는지 결정
-
인덱스의 평가 기준
- 접근 시간: 데이터를 찾는 데 걸리는 시간
- 유지 비용: 새로운 데이터 삽입 및 기존 데이터 삭제 연산으로 인한 인덱스 구조 갱신 비용
실제 레코드가 삽입, 수정, 삭제될때마다 인덱스도 보조적인 구조이기에 같이 탐색키를 삽입 삭제하는 관리가 필요함. 이 관리에 많은 비용이 들어가면 DBMS에게 부담이 되어 성능저하가 발생할 수 있음 - 공간 비용: 인덱스 구조에 의해 사용되는 부가적인 공간 비용.
2.순서 인덱스
순서 인덱스의 특징
순서 인덱스: 모든 인덱스의 탐색키들이 순차적으로 정렬되어 있다! = 빠른 접근
예시: 사전 (day라는 단어를 찾고 싶으면 D부터 찾으면 됨. 아주 빠르게 검색가능)

- 탐색키로 정렬된 순차 파일에 대하여 레코드에 대한 빠른 접근이 가능하도록 구성한 인덱스
- 탐색키를 정렬하여 해당 탐색키와 탐색키에 대한 레코드와의 연계를 통하여 인덱스 생성
- 순서 인덱스의 종류
- 밀집 인덱스
- 희소 인덱스
- 다단계 인덱스
순차 파일
파일 구조화 3가지: (힙, 순차, 해쉬) 파일 구조. 각각의 레코드를 실제 디스크에 어느 레코드블럭에 저장해야할지 고민하는 개념.
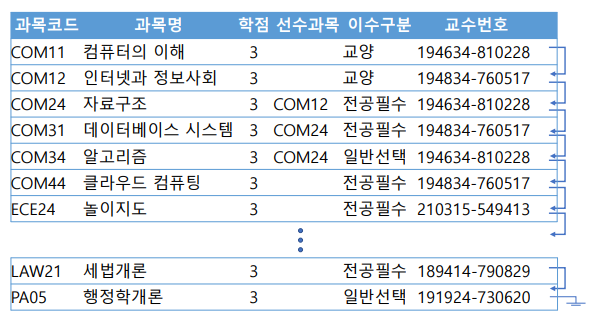
각각의 레코드가 과목코드 순으로 정렬되어 있음. 순차파일들은 연속된 레코드를 정렬하기 위해 다음 레코드를 지목하는 포인트를 가져 다음 레코드에 빠르게 접근하도록 도움. 순서 인덱스는 이 순차 파일처럼 저장된 레코드를 대상으로 만든 인덱스!
인덱스의 구성
인덱스 엔트리의 구조
인덱스는 어떤 구조를 가지고 있을까?

인덱스 엔트리: 각각 레코드에 대한 빠른 접근을 할 수 있는 작은 형태의 테그(레이블).
- 탐색키값: 어떤 레코드를 대상으로 만들어졌는지 알려주는 부분
- 블럭ID: 해당 레코드가 어느 블럭에 저장되어있는지 가르키는 부분
- 오프셋: 해당 레코드가 블럭의 어느정도 부분에 위치해있는지 알려주는 부분
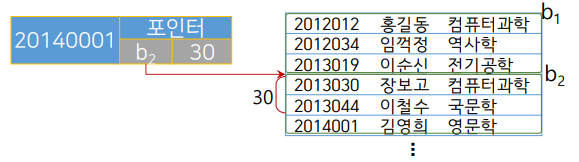
김영희를 가르키는 인덱스 엔트리. b2 블럭의 30byte뒤에 있음을 의미함.
밀집, 희소, 다단계 인덱스
밀집 인덱스
빡빡하게 모여있다!
- 모든 레코드에 대해 "인덱스 엔터리"{탐색키값 | 포인터}쌍을 유지
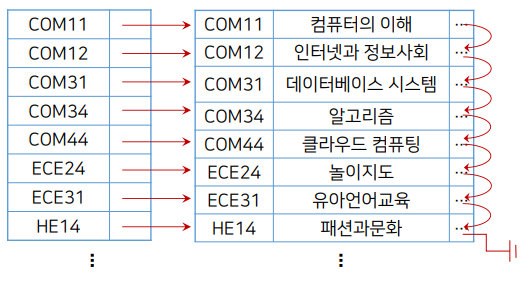
데이터베이스시스템의 인덱스(COM31)를 찾기 위해 I/O의 기본 단위만큼 차근차근 메모리에 적재되어 COM31을 찾을때까지 넣었다뺐다 반복. 만약 COM31 인덱스를 찾으면 해당 블럭을 메모리에 올려서 데이터 찾아옴.
희소 인덱스
- 인덱스의 엔트리가 일부의 탐색키 값만을 유지
(모든 인덱스가 아닌, 일부만 듬성듬성 유지!)
만약 COM31을 메모리에 적재하기 위해서는 어떻게 해야할까?
곧바로 찾아갈 수 있는 인덱스 엔트리가 없으므로, COM31보다 작은 엔트리 중 가장 큰 것(COM11)을 따라가서, COM31이 나올때까지 순차 레코드를 따라간다.
밀집 인덱스
- 장점: 해당 레코드로 곧바로 이동가능(경로를 제공받음)
- 단점: 인덱스의 크기가 매우 커짐.
희소 인덱스
- 장점: 인덱스의 크기가 작아 인덱스를 찾는 비용 작음.
- 단점: 특정 인덱스를 찾기 위해 순차파일 내부에서 일부 검색을 다시
뭐가 더 좋고 나쁜가는 상황에 따라 달라진다. 차이점에 초점!
다단계 인덱스의 필요
- 4KB크기의 한 블럭에 100개의 엔트리가 삽입될 때, 100,000,000개의 레코드에 대한 순서 인덱스
- 1,000,000개의 블럭 = 4GB 공간 필요
밀집 인덱스의 한 예시. 위같은 예시에서 인덱스 자체만으로 4GB의 공간을 사용해야만 한다. 레코드를 찾기 위해서는 먼저 메모리에 4GB(인덱스의 양)를 적재해야 함. 메모리에 공간이 없이면 특정 레코드를 찾기 위해 수백, 수천번의 I/O를 거듭해야 한다.
아.. 인덱스 쓰는거만해도 넘 힘든데, 인덱스 잘 쓰기 위한 방법이 없을까?를 논의하기 위해 다단계 인덱스가 나옴!
- 인덱스 크기에 따른 검색 성능
- 인덱스 크기 < 메모리 크기
이럼 괜찮음. 한번의 적재로 빠르게 찾을 수 있음- 디스크 I/O이 줄어 탐색 시간이 축소
- 인덱스 크기 > 메모리 크기
이러면 곤란함. 레코드 찾자고 인덱스만 여러번 I/O해야함- 저장된 블럭을 여러번 나누어 읽어야 하기 때문에 디스크 I/O 비용이 증가하여 탐색 시간이 증가
=> 다단계 인덱스를 구성
- 저장된 블럭을 여러번 나누어 읽어야 하기 때문에 디스크 I/O 비용이 증가하여 탐색 시간이 증가
그러면, 지금 인덱스도 너무 크잖아? 인덱스를 찾기 위한 인덱스를 또 만드는건 어떨까? = 다단계 인덱스
다단계 인덱스
밀집+희소
내부 인덱스는 밀집 인덱스로 만들고, 밀집 인덱스의 각 블럭에 대한 인덱스를 만들면, 이건 희소 인덱스와 유사해짐.
- 내부 인덱스와 외부 인덱스로 구성
- 외부 인덱스를 내부 인덱스보다 희소한 인덱스로 구성하여 엔트리 포인터가 내부 인덱스 블럭을 지칭
- 포인터가 가리키는 블럭을 스캔하여 원하는 레코드보다 작거나 같은 탐색키 값 중에 가장 큰 값을 가지는 레코드를 탐색
- 내부 인덱스는 1,000,000개의 블럭을 갖는 반면, 외부 인덱스는 100개의 블럭만 사용하여 작은 크기의 외부 인덱스로 메모리에 적재 가능
다단계 인덱스의 구조
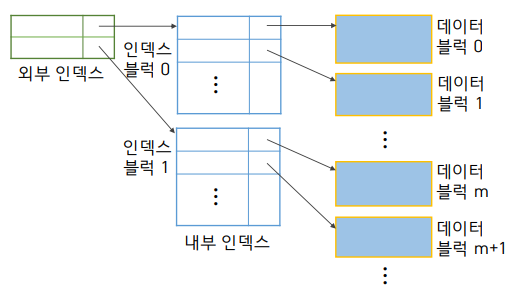
내부 인덱스(=밀집 인덱스)에 대한 또 다른 인덱스 외부 인덱스(=희소 인덱스)를 만든다! 외부 인덱스는 범위정도를 알려줄 수 있다.
3. B+ - 트리 인덱스
특정 다단계 인덱스
카드 찾기

이 카드들을 모두 뒤집어놓고 7을 찾으라고 하면 어떻게 할까요?
1. 첫번째부터 뒤집어본다.
2. 뒤에서부터 뒤집어본다.
3. 무작위로 잡히는걸 뒤집어본다.
=> 평균적으로 카드를 절반개정도 뒤집으면 알수 있다. 만약 카드가 1억개면, 5천만번 정도 뒤집어봐야 알 수 있다. 이 카드를 정렬해놓으면 훨씬 빠르게 원하는 카드를 찾을 수 있다!

Q. 7을 찾고 싶으면 어디를 뒤집으면 될까?
A. 중간쯤을 뒤집어보면 된다.
Q. 13을 찾으려는데, 뒤집은 카드가 10이다. 어디를 뒤집어보면 될까?
A. 오른쪽을 뒤집어 보면 된다.
이같은 방식을 이진 검색 트리라 한다.
이진 탐색 트리(binary search tree)
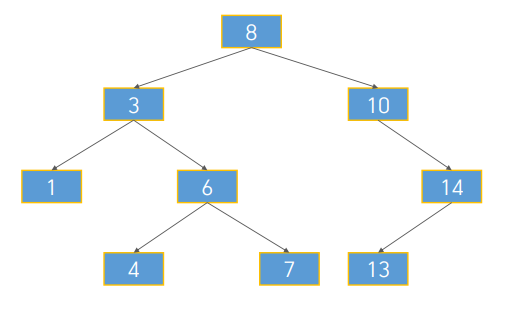
다단계 인덱스도 이런 방식으로 구성되어 있다. 다단계와 이진탐색트리를 절묘하게 결합시켜 하나의 노드가 하나의 블럭사이즈가 되도록 담고, 두 갈래가 아닌 수십개, 사백개로 나뉘도록 하여 짧은 계층의 인덱스 구조를 제공하는 것이, B+ 트리이다!!
- 근원은 이진 탐색 트리이다.
- 이진탐색 트리와 다단계 를 합쳐 B+트리가 개발되었다.
B+ 트리의 구조
하나의 노드에 하나의 값이 아니라, 하나의 노드는 4KB정도가 되고 여러개의 탐색키와 그 하위노드를 가르키는 포인터를 담을 수 있도록 크기를 확장 해놓은 구조. (=B+트리) 실제 DB에는 이 탐색키가 100개정도 들어간다.
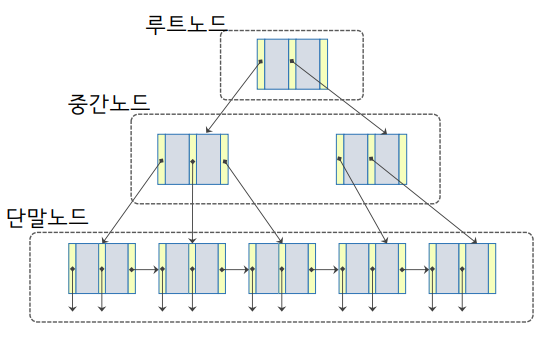
제일 밑의 노드가 서로 가리키고 있는 일종의 연결 리스트 형식으로 되어있다.
-
루트 노드로부터 모든 단말 노드에 이르는 경로의 길이가 같은 높이 균형 트리
- 순서 인덱스는 파일이 커질수록 데이터 탐색에 있어서 접근 비용이 커지는 문제점을 해결하기 위해 제안
- 상용 DBMS에서도 널리 사용되는 대표적인 순서 인덱스
-
B+ 트리의 노드 구조

각각의 노드는, 탐색키를 위한 칸이 존재하고, 탐색키보다 작은 값이 왼쪽에, 큰 값이 오른쪽에 위치하도록 한다. n-1개의 탐색키, 탐색키에 맞춰 하위노드를 가르키는 포인터가 총 n개 들어간다.
- n개: 차수 = 팬아웃(fanout)
팬아웃이 몇개야? = 어떤 노드의 하위 노드가 몇개야?
B+ 트리의 구성 요소
실제 레코드의 위치에 대해 알려주는 것이 아니라, 그 데이터가 위치하는 범위를 알려준다. 경로 제공이 목적!
- 인덱스 세트: 루트노드와 중간노드로 구성
- 단말 노드에 있는 탐색키 값을 신속하게 찾아갈 수 있도록 경로를 제공하는 목적으로 사용
- [n/2]~n 사이의 개수를 자식으로 소유
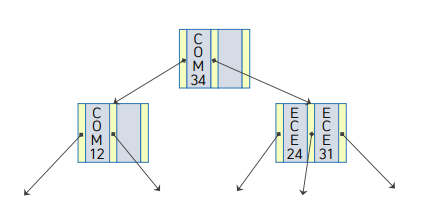
루트노드 + 중간노드 인덱스 세트.
포인터는 레코드를 가르키는게 아니라, 그 하위의 토드를 가르키기 위함. COM34는 레코드의 위치 방향성 제시를 위함.
-
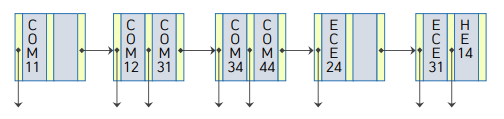
순차세트: 단말노드로 구성
모든 단말노드들은 형제노드가 무엇인지 포인터로 가르키고 있기 때문에 순차세트라고 부름- 모든 노드가 순차적으로 서로 연결
- 단말 노드는 적어도 (n-1)/2개의 탐색키를 포함
- 탐색키에 대한 실제 레코드를 지칭하는 포인터를 제공
이 키값들은 그포인터(화살표)가 실제 디스크 내의 레코드 위치를 가리키고 있음.
단말 노드의 구성
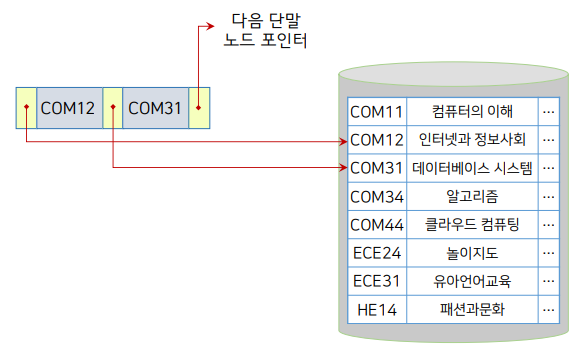
과목테이블이 디스크에 저장되어 있으면, 이렇게 인덱스를 만들어 볼 수 있다. COM12, COM31은 실제 포인터에 대한 태그. 포인터는 디스크의 실제 데이터를 지목하고 있다.
B+ 트리 기반 검색
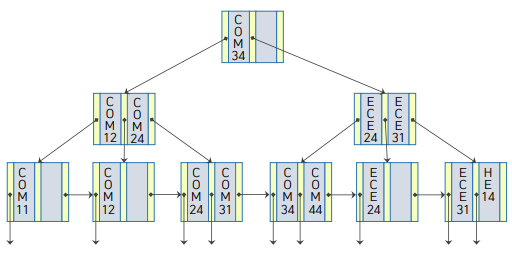
B+ 트리의 예
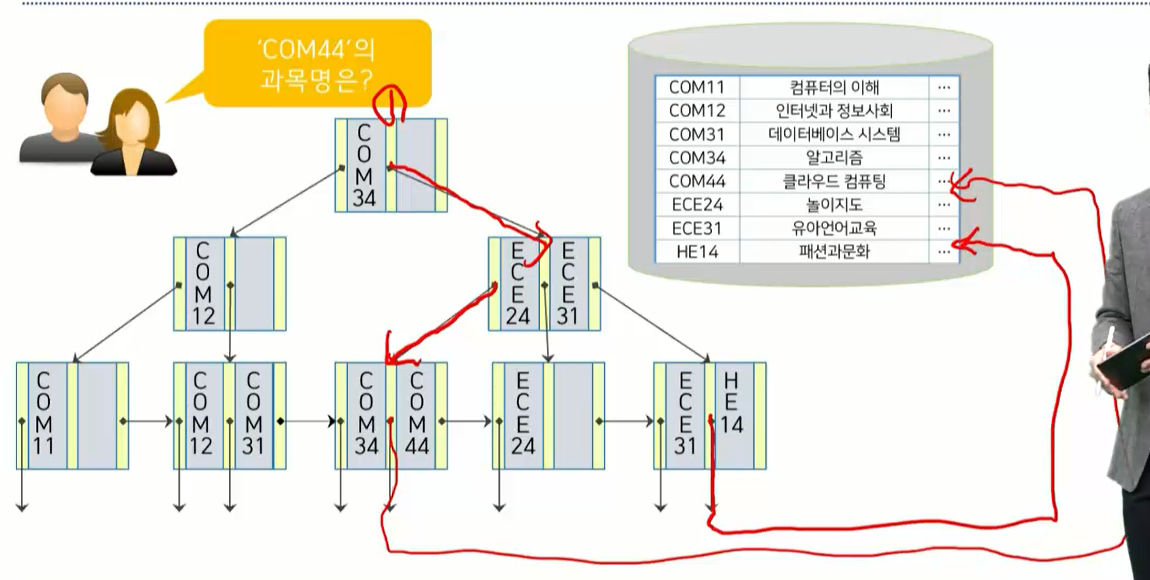
요청: 'COM44'의 과목명은?
- 루트노드부터 시작.
- COM44와 같거나 이것보다 큰 것중 가장 작은것을 찾는다.
- 현재는 COM44보다 큰것중 작은것이 없다. 만약 아무것도 없으면, 가장 오른쪽 노드를 따라간다
- ECE24, ECE31이 있는 노드로 이동.
- ECE24보다 COM44가 작다. -> 왼쪽 노드로 이동.
- COM34, COM44가 있는 노드로 이동
- COM44를 찾을때까지 한칸한칸 이동하다가, COM44를 찾으면 그 왼쪽의 포인터를 따라간다.
탐색키 삽입과 삭제
B+ 트리 상에서의 삽입, 삭제
1.레코드 삽입, 삭제 시 B+ 트리 수정
- 레코드 삽입: 노드에서 유지해야 할 탐색키와 포인터 수 증가로 인해 노드를 분할해야 하는 경우가 발생
- 레코드 삭제: 노드에서 유지해야 할 탐색키 값과 포인터 수 감소로 형제 노드와 키를 재분배 또는 병합해야 하는 경우가 발생
- 높이 균형 유지: 노드가 분할되고나 병합되면서 높이의 균형이 맞지않는 경우가 발생
-
삽입: 검삭과 같은 방법을 사용하여 삽입되는 레코드의 탐색키값이 속할 단말 노드를 탐색
- 해당 단말 노드에 <탐색키, 포인터> 쌍을 삽입
- 삽입 시 탐색키가 순서를 유지
=> 분할을 유발
-
삭제: 삭제될 레코드의 탐색키를 통해 삭제될 탐색키와 포인터를 포함한 단말 노드를 탐색
- 같은 탐색키 값을 가지는 다중 엔트리가 존재할 경우, 삭제될 레코드를 가지는 엔트리를 찾을 때까지 탐색 후 단말 노드에서 제거
- 단말 노드에서 제거된 엔트리의 오른쪽에 있는 엔트리들은 빈 공간이 없도록 왼쪽으로 이동
=> 병합을 유발
노드가 분할되는 삽입
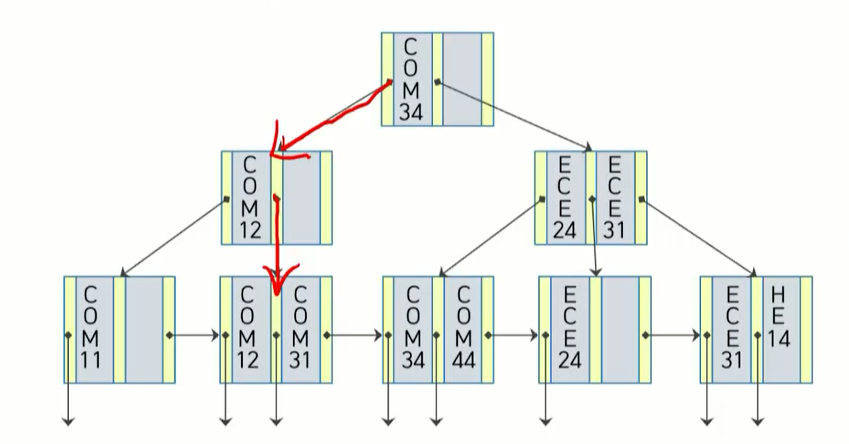
- COM24보다 큰것중에 가장 작은 것 = COM34
- COM24가 중간노드에 없음. 가장 큰 것중에 작은것도 없음. -> 가장 오른쪽에 있는 포인터를 따라감.
- ?? COM24가 들어갈 공간이 없음.
COM24 삽입
공간이 부족하므로 두개의 노드로 나누고, 부모의 노드도 하나씩 조정함
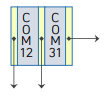
삽입 대상 노드에 추가적인 저장할 공간 부족: 노드분할
- COM12를 하나의 단말 노드로 구성
- COM24와 COM31이 하나의 단말 노드로 구성
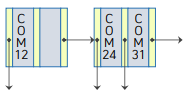
부모 노드에 탐색키를 조정하고 추가된 노드에 대한 포인터를 삽입
새롭게 추가된 단말 노드를 가리키는 포인터가 필요하므로, 부모노드도 수정해준다. 단말 노드를 밀어줬으므로, 가장 앞에있는 값인 COM24를 탐색기값에 넣고, 오른쪽의 포인터를 끝에 넣어준다.
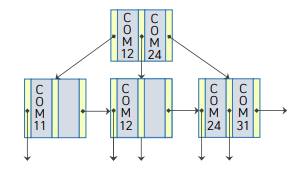
< 삽입 최종 결과물 >
탐색키의 삭제
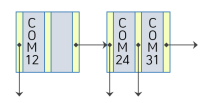
COM44 삭제
COM44 찾아서 삭제. (포인터도 같이 삭제)
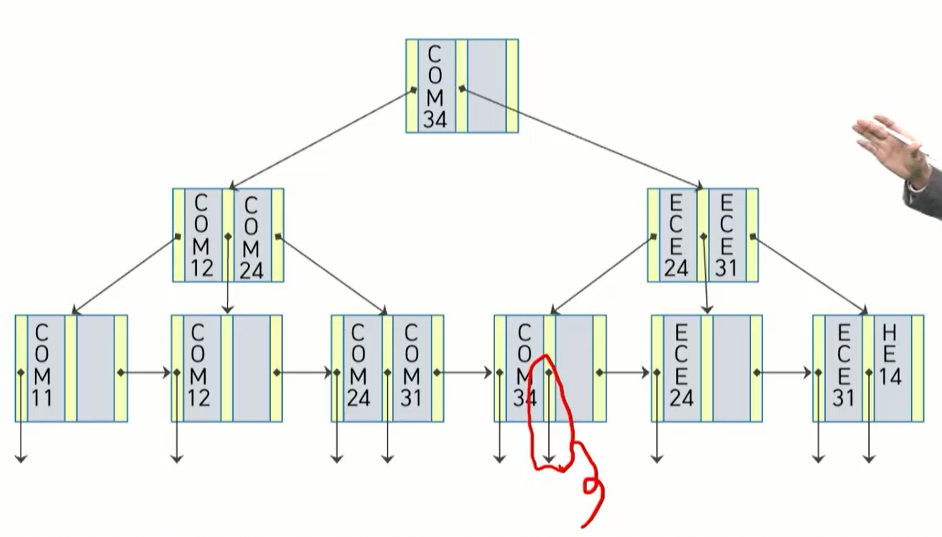
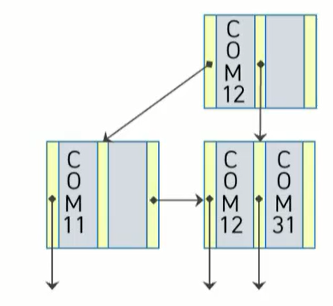
탐색키가 재분배되는 삭제
COM12 삭제
COM12가 있는 단말 노드를 검색하고 탐색키를 삭제
- 해당 단말 노드는 삭제 후 탐색키가 존재하지 않음
- (n-1)/2 개 보다 탐색키가 적으므로 다른 노드와 별도의 재구조화 작업이 필요 (더 적은수의 노드로 줄일 수 있음!)
=> COM12이 저장된 노드의 오른쪽 형제 노드와 키를 재분배!
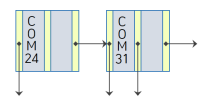
< 삭제 Before vs After >
| before | after |
|---|---|
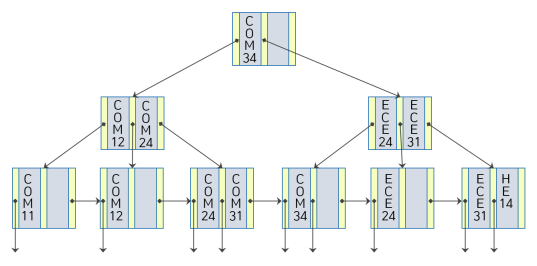 | 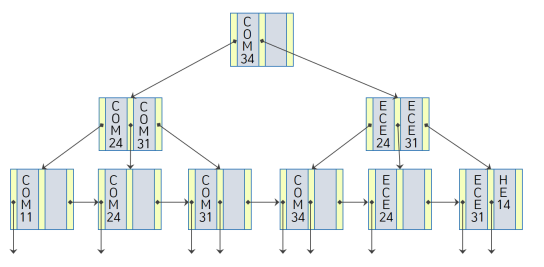 |
