신경망 모델 구성하기
- 신경망은 데이터에 대한 연산을 수행하는 계층/모듈로 구성되어 있습니다.(layer/module)
- torch.nn 네임스페이스는 신경망을 구성하는데 필요한 모든 구성 요수를 제공합니다.
- Pytorch의 모든 모듈은 nn.Module의 하위 클래스입니다.
-nn.Module : 모든 신경만 모듀르이 기본 클래스입니다. - 신경망은 다른 모듈(계층)로 구성된 모듈입니다.
- 이러한 중첩된 구조는 복잡한 아키텍처를 쉽게 구축하고 관리할 수 있습니다.
-아래 부터는 FashionMNIST 데이터셋의 이미지를 분류하는 신경망을 구성해보자
-시작 코드
import os
import torch
from torch import nn
from torch.utils.data import DataLoader
from torchvision import datasets, transforms학습을 위한 장치 얻기
- 신경망 모델을
nn.Module의 하위클래스로 정의하고, init에서 신경망 계층들을 초기화합니다. nn.Module을 상속받은 모든 클래스는forward메소드에 입력데이터에 대한 연산들을 구현합니다.
class NeuralNetwork(nn.Module):
def __init__(self):
super().__init__()
self.flatten = nn.Flatten()
self.linear_relu_stack = nn.Sequential(
nn.Linear(28*28, 512),
nn.ReLU(),
nn.Linear(512, 512),
nn.ReLU(),
nn.Linear(512, 10),
)
def forward(self, x):
x = self.flatten(x)
logits = self.linear_relu_stack(x)
return logits-
flatten은 numpy에서 제공하는 다차원 배열 공간으로 1차원으로 평탄화해주는 함수이다. -
nn.Sequential클래스는nn.Linear,nn.ReLU(활성화 함수) 같은 모듈들을 인수로 받아서 순서대로 정렬해놓고 입력값이 들어오면 순서대로 모듈을 실행해서 결과값을 리턴한다. -
nn.Linear는 선형 변환을 수행하는 클래스로 28*28 크기 데이터를 인풋하면 512크기 데이터로 아웃풋 해줍니다. -
nn.ReLU()Rectified Linear Unit의 약자, 입력이 0 이하일 경우에는 0을 출력하지만 입력이 0을 넘어가면 입력값 그대로 출력함
-nn.Linear(512, 512)바로 위 입력이 512여도 내부 연산으로 값이 바뀔수 있으므로 512,512를 해줌 -
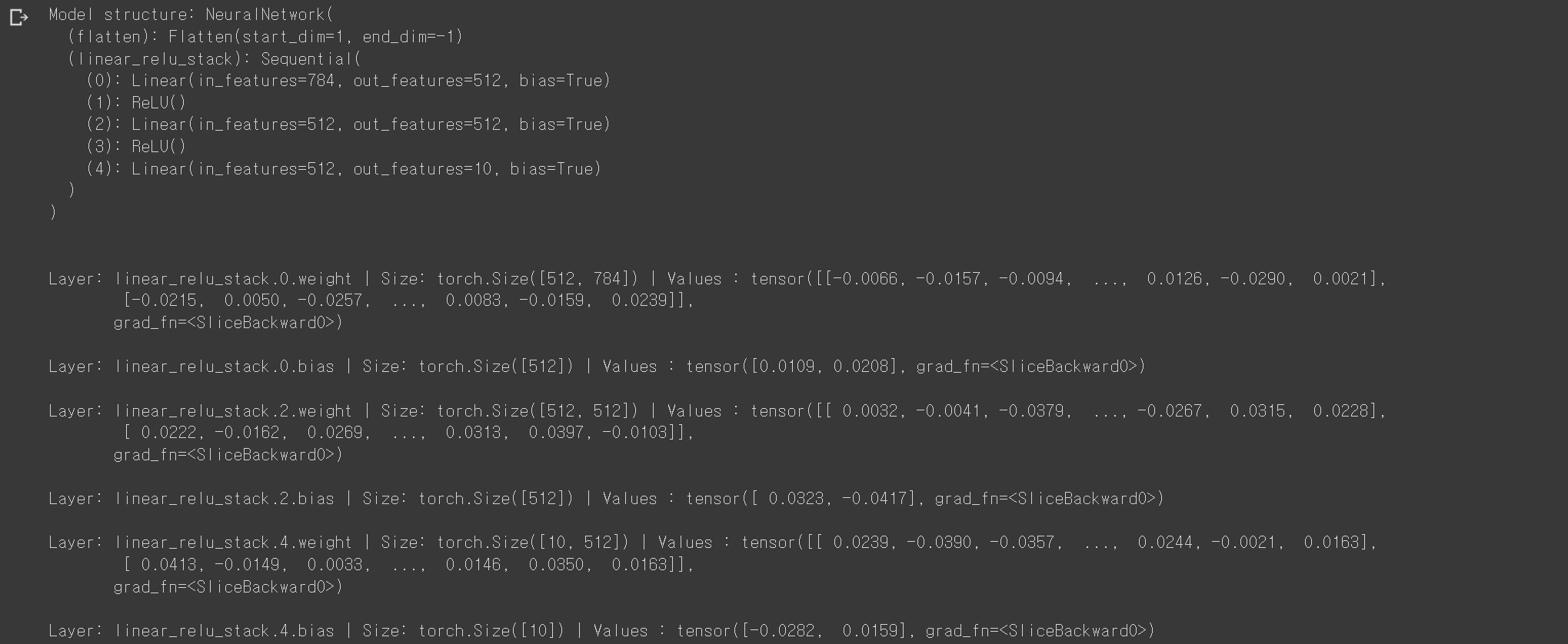
NeuralNetwork의 인스턴스를 생성하고 이를device로 이동한 뒤, 구조를 출력합니다. -
코드
model = NeuralNetwork().to(device)
print(model)-
결과

-
결과 값의 bias는 편향으로 모델이 실제 데이터와 얼마나 차이가 있는지를 나타내는 척도
-코드
X = torch.rand(1, 28, 28, device=device)
logits = model(X)
pred_probab = nn.Softmax(dim=1)(logits)
y_pred = pred_probab.argmax(1)
print(f"Predicted class: {y_pred}")-
모델을 사용하기 위해 입력 데이터를 전달합니다.
-이는 일부 백그라운드 연산들과 함께 모델의forward를 실행합니다.
*model.forward()는 직접 호출하지 말것 -
모델에 입력을 전달하여 호출하면 2차원 텐서를 반환합니다.
-
2차원 텐서의 dim = 0은 각 분류(class)에 대한 원시(raw) 예측값 10개가, dim=1에는 각 출력의 개별 값들이 해당함
-원시 예측값을nn.Softmax모듈의 인스턴스에 통과시켜 예측 확률을 얻습니다. -
Softmax Class의 개수가 여러개 일 때 사용하는 것이 바로 Softmax function으로 어떤 Score값에 대해서 각 Class일 확률을 뽑아낼 수 있다.
ex) Score 한개에 대해서 Class1일 확률, Class2일 확률, ... ClassN일 확률이 나온다면 모두 다 깂이 0~1이어야 하고 모두 다 더했을 때, 당연히 1이 나와야함 -
argmax: input tensor에 있는 모든 요소들 중에서 가장 큰 값을 가지는 공간의 인덱스 번호를 반환하는 함수
- 과대적합과 과소적합
-과대적합(overfitting): 머신러닝 모델을 학습할 때 학습 데이터셋을 지나치게 최적화하여 발생하는 문제. 즉, 모델을 지나치게 복잡하게 학습해 학습 데이터셋에서는 모델 성능이 높게 나타나지만 새로운 데이터가 주어졌을 때 정확한 예측/분류를 수행하지 못함
-과소적합(underfitting): 과대 적합의 반대 개념으로 머신러닝 모델의 최적화가 제대로 수행되지 않아 학습 데이터의 구조 패턴을 정확히 반영하지 못하는 문제
모델 계층(Layer)
-FashionMINST 모델의 계층들
-28X28 크기의 이미지 3개로 구성된 미니배치를 가져와, 신경망을 통과할 때 어떤 일이 발생하는지
-코드
input_image = torch.rand(3,28,28)
print(input_image.size())-결과

nn.Flatten
nn.Flatten를 사용하여 28X28의 2D이미지를 784 픽셀 값을 갖는 연속된 배열로 변환합니다.(dim=0의 미니배치 차원은 유지됩니다.)
- 미니배치(mini batch): 데이터의 일부를 무작위로 추려서 그 근사치로 이용할 수 있다. 이 일부가 되는 데이터를 미니배치라고 한다77
- 코드
flatten = nn.Flatten()
flat_image = flatten(input_image)
print(flat_image.size())- 결과

nn.Linear
-
nn.Linear선형 계층은 저장된 가중치와 편향을 사용하여 입력에 선형 변환을 적용하는 모듈입니다. -
코드
layer1 = nn.Linear(in_features=28*28, out_features=20)
hidden1 = layer1(flat_image)
print(hidden1.size())- 결과

nn.ReLU
- 비선형 활성화는 모델의 입력과 출력 사이에 복잡한 관계를 만듭니다. 비선형 활성화는 선형 변환 후에 적용되어 비선형성(nonlinearity)울 도입하고, 신경망이 다양한 현상을 학습할 수 있도록 돕습니다.
- 이 모델에서 nn.ReLU를 선형 계층들 사이에 사용하지만, 모델을 만들 때는 비선형성을 가진 다른 활성화를 도입할 수도 있습니다.
-코드
print(f"Before ReLU: {hidden1}\n\n")
hidden1 = nn.ReLU()(hidden1)
print(f"After ReLU: {hidden1}")-결과
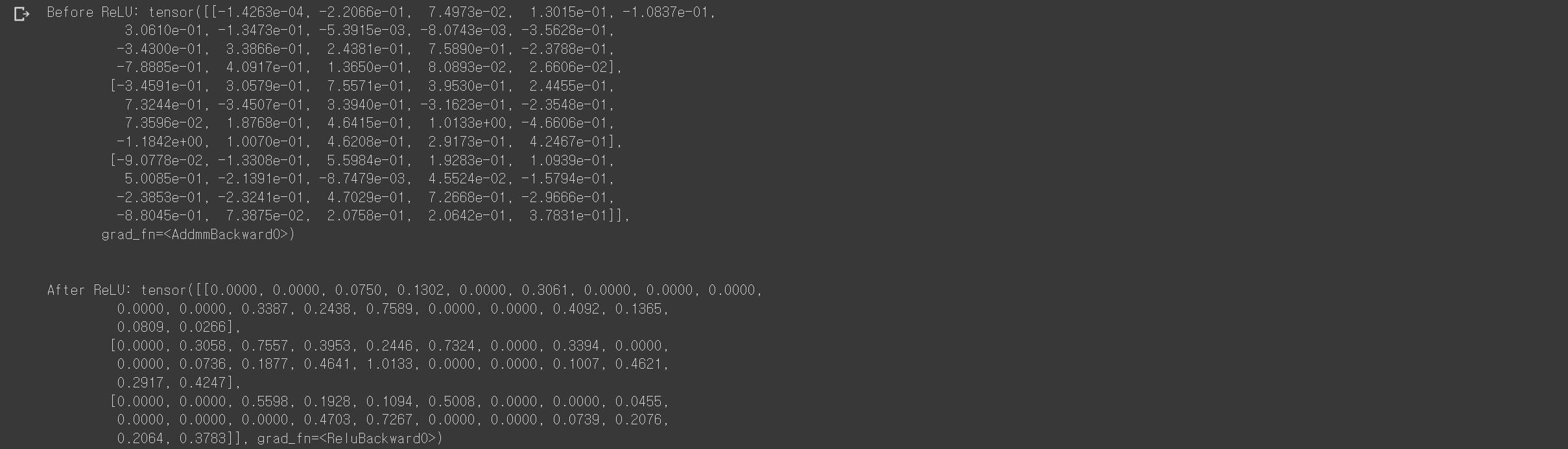
- 앞서 설명했던 것 처럼 ReLU는 0이하의 값을 0으로 0초과의 값은 그대로 반영해준다.
nn.Sequential
- 순거를 갖는 모듈의 컨테이너 입니다. 데이터는 정의된 것과 같은 순서로 모든 모듈들을 통해 전달됩니다. 순차 컨테이너(sequntial container)를 사용하여 아래의
seq_modules와 같은 신경망을 빠르게 만들 수 있습니다.
-코드
seq_modules = nn.Sequential(
flatten,
layer1,
nn.ReLU(),
nn.Linear(20, 10)
)
input_image = torch.rand(3,28,28)
logits = seq_modules(input_image)nn.Softmax
- 신경망의 마지막 선형 계층은 nn.Softmax 모듈에 전달될 ([-\infty,\infty] 범위의 원시 값(raw value)인)
logits를 반환합니다. logits는 모델의 각 분류(class)에 대한 예측 확률을 나타내도록 [0,1] 범위로 비례하여 조정(scale)됩니다.
-dim매개변수는 값의 합이 1이 되는 차원을 나타탭니다.
- 코드
softmax = nn.Softmax(dim=1)
pred_probab = softmax(logits)모델 매개변수
- 신경망 내부의 많은 계층들은 매개변수화(parameterize) 됩니다. 즉, 학습 중에 최적화되는 가중치와 편향과 연관지어집니다.
nn.Module을 상속하면 모델 객체 내부의 모든 필드들이 자동으로 추적되며, 모델의parameters()및named_parameters()메소드로 모든 매개변수에 접근할 수 있게 됩니다.
-named_parameters이름이 있는 파라미터 이 예제에서는 각 매개변수들을 순회하며, 매개변수의 크기와 값을 출력합니다.- 코드
print(f"Model structure: {model}\n\n")
for name, param in model.named_parameters():
print(f"Layer: {name} | Size: {param.size()} | Values : {param[:2]} \n")-결과