
모든 내용은 파이토치 공식 문서의 Google Colab 공부 문서를 이용해 공부했습니다.
텐서
- 텐서는 배열이나 행렬과 매우 유사한 자료구조 입니다.
- Pytorch에서 텐서를 사용하여 모델의 입력과 출력, 그리고 매개변수의 부호화합니다
-매개변수의 부호화란? '모델에 넣기 위해 매개변수를 바꿔준다.' - 텐서는 GPU나 다른 하드웨어 가속기에서 실행할 수 있다는 점만 제외하면 Numpy의 ndarray와 유사합니다.
-실제로 텐서와 Numpy배열은 종종 동일한 내부 메모리를 공유할 수 있어 데이터를 복사할 필요가 없습니다. - 텐서는 또한 자동 미분에 최적화 되어있음
Tensor 사용 전 Import
import torch
import numpy as np
Tensor 초기화
- Tensor는 여러 방법으로 초기화 할 수 있음
데이터로부터 직접 생성하기
- 데이터로 부터 직접 텐서를 생성할 수 있음
- 데이터의 자료형은 자동으로 유추합니다
->공부하면서 실험해 봤을 때 문자열이나 문자는 들어가지 않는 것으로 보아 float형인지 정수형인지를 구분하는 것이라 판단됩니다.
data = [[1, 2],[3, 4]]
x_data = torch.tensor(data)Numpy 배열로부터 생성하기
- Tensor는 Numpy 배열로 생성할 수 있습니다.
-그 반대도 가능합니다.
np_array = np.array(data)
x_np = torch.from_numpy(np_array)다른 텐서로부터 생성하기
- 명시적으로 재정의(override) 하지 않는다면, 인자로 주어진 텐서의 속성(shape,datatype)을 유지합니다.
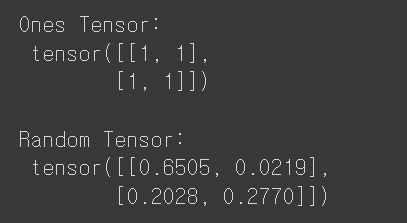
x_ones = torch.ones_like(x_data) # x_data의 속성을 유지합니다.
print(f"Ones Tensor: \n {x_ones} \n")
#ones_like 1로 채워진 텐서를 만들어줌
x_rand = torch.rand_like(x_data, dtype=torch.float) # x_data의 속성을 덮어씁니다.
print(f"Random Tensor: \n {x_rand} \n")
#int로 정하고 싶으면 torch.randint_like를 사용해야함->결과
무작위 또는 상수 값을 사용하기
- shape는 텐서의 차원을 나타내는 튜플로, 아래 함수들에서는 출력 텐서의 차원을 결정합니다.
shape = (2,3,)
#여기 후행 쉼표는 그냥 다음 차원으로의 구분을 위해서 만든 장치라고 이해하는데 이게 맞나
#후행 쉼표는 그냥 문법적 허용이라함
rand_tensor = torch.rand(shape)
ones_tensor = torch.ones(shape)
zeros_tensor = torch.zeros(shape)
print(f"Random Tensor: \n {rand_tensor} \n")
print(f"Ones Tensor: \n {ones_tensor} \n")
print(f"Zeros Tensor: \n {zeros_tensor}")->결과

Tensor의 속성
- 속성은 Tensor의 모양(shape), 자료형(datatype) 및 어느 장치에 저장되는 지를 나타냄
tensor = torch.rand(3,4)
print(f"Shape of tensor: {tensor.shape}")
print(f"Datatype of tensor: {tensor.dtype}")
#넘파이 배열이니까 float32
print(f"Device tensor is stored on: {tensor.device}")->결과

Tensor 연산(Operation)
- 전치(transposing), 인덱싱, 슬라이싱, 수학 계산, 선형대수, 임의 샘플링 등 100가지 이상의 텐선 연산들을 파이토치 공식문서 에서 확인 가능하다.
-Transposin : 상대적인 위치를 바꾸는 것, 수학적으로는 행과 열을 교환하는 것을 의미함 - 각 연산들은 GPU에서 실행할 수 있습니다.
-Colab을 사용하면 GPU할당 가능
- 상단의 보기 클릭 후 노트 설정 클릭
-그 후 선택 후 할당
-기본적으로 Tensor는 CPU에 생성됩니다.
-.to 메서드를 사용하면 GPU의 가용성을 확인한 뒤 GPU로 텐서를 명시적으로 이동할 수있음
* 장치간에 큰 tensor들을 복사하는 것은 시간과 메모리 측면에서 비용이 많이 들어감
# GPU가 존재하면 텐서를 이동합니다
if torch.cuda.is_available():
tensor = tensor.to("cuda")
print(torch.acos(tensor))-결과

- 현재 디바이스는 cuda즉 GPU에 할당되어 있음
NumPy식의 표준 인덱싱과 슬라이싱
코드
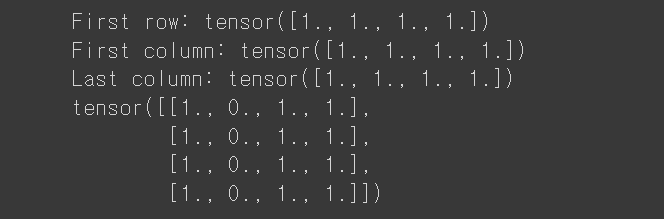
tensor = torch.ones(4, 4)
print(f"First row: {tensor[0]}")
print(f"First column: {tensor[:, 0]}")
print(f"Last column: {tensor[..., -1]}")
#...은 생략을 뜻함 뒤에는 범위를 넣으면 됨 그거 제외하고 나머지는 생략하는 것
tensor[:,1] = 0
print(tensor)- 첫번째 줄은 4x4의 1로 채워진 텐서를 초기화합니다.
- 두번째 줄은 첫번째 row를 출력합니다. 여기서 시작숫자는 1이 아닌 0입니다.
-[:,0]은 행의 범위는 :로 즉 전체를 가르키고, 열의 범위는 0 숫자의 시작은 0 이므로 첫번째 열을 가르키게 됩니다. - 세번째 줄은 마지막 column을 출력합니다.
-...은 생략을 뜻합니다. 뒷부분의 -1의 범위를 제외하고 나머지는 생략됩니다. - 네번째 줄은 전체 행의, 두번째 열(1)의 값을 0으로 바꾸는 것입니다.
결과
텐서 합치기
- torch.cat :를 사용하여 주어진 차원에 따라 일련의 텐서를 연결할 수 있음
- torch.cat 과 미묘하게 다른 torch.stack 도 있음
torch.stack 공식 문서
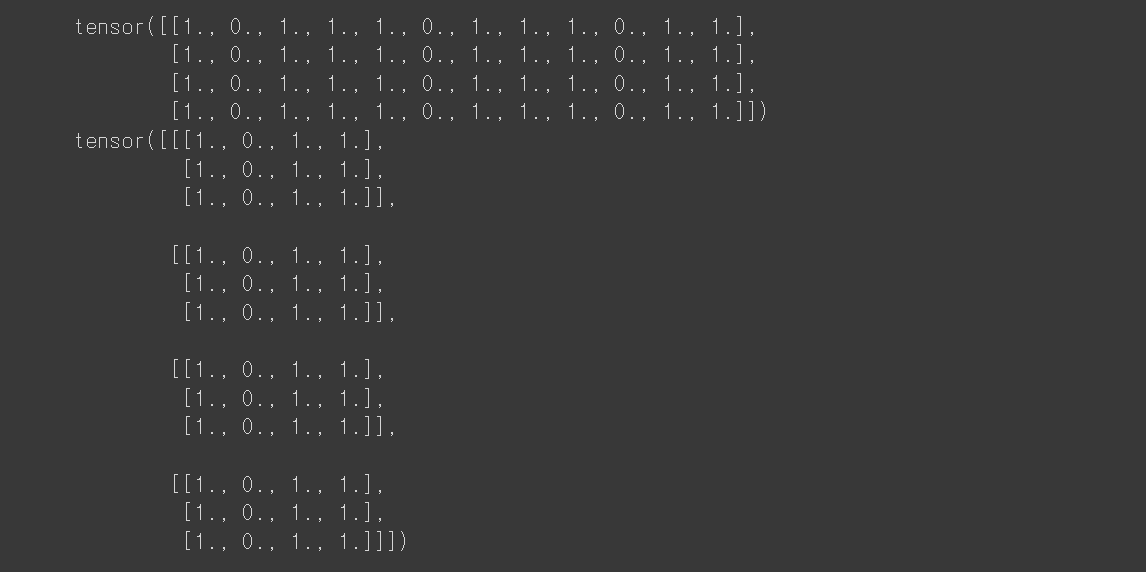
t1 = torch.cat([tensor, tensor, tensor], dim=1)
print(t1)
#torch.stack은 뭐가 다른 것인가?,stack의 dim=2이해 https://rfriend.tistory.com/781
t2 = torch.stack([tensor,tensor,tensor], dim=1)
print(t2)-
cat의 경우 새로운 차원으로 확장하지 않고 주어진 차원을 기준으로
-합치려는 차원을 제외한 나머지 차원의 shape는 모두 동일해야함 -
stack은 새로운 차원으로 주어진 텐서들을 붙입니다.
-예를 들어 (3,4) shape(크기)의 텐서 A를 붙이는 경우
-torch.cat([A,A], dim=0)의 결과는 (6,4)의 크기를 갖고
-torch.stack([A,A], dim=0)의 결과는 (2,3,4)의 크기를 갖습니다.
-결과
산술 연산
# 두 텐서 간의 행렬 곱(matrix multiplication)을 계산합니다. y1, y2, y3은 모두 같은 값을 갖습니다.
# ``tensor.T`` 는 텐서의 전치(transpose)를 반환합니다.
y1 = tensor @ tensor.T
y2 = tensor.matmul(tensor.T)
y3 = torch.rand_like(y1)
torch.matmul(tensor, tensor.T, out=y3)
#out은 y3에 넣는다
# 요소별 곱(element-wise product)을 계산합니다. z1, z2, z3는 모두 같은 값을 갖습니다.
z1 = tensor * tensor
z2 = tensor.mul(tensor)
z3 = torch.rand_like(tensor)
torch.mul(tensor, tensor, out=z3)- 여기서 @는 행렬 곱을 나타내는 기호입니다.
- 행렬곱은 matmul 함수로도 계산가능합니다.
-결과

단일 요소(single-element) 텐서
-텐서의 모든 값을 하나로 집계하여 요소가 하나인 텐서의 경우, item()을 사용하여 python 숫자 값으로 반환할 수 있습니다.
agg = tensor.sum()
agg_item = agg.item()
print(agg_item, type(agg_item))결과

바꿔치기(in-place) 연산
-연산 결과를 피연산자(operand)에 저장하는 연산을 바꿔치기 연산이라고 부르며, 접미사를 갖습니다. 예를 들어: x.copy(y) 나 x.t()는 x를 변경합니다.
print(f"{tensor} \n")
tensor.add_(5)
print(tensor)결과

-Note
-바꿔치기 연산은 메모리를 일부 절약하지만, 기록(history)이 즉시 삭제되어 도함수(derivative) 계산에 문제가 발생할 수 있습니다. 따라서, 사용을 권장하지 않습니다.
Numpy 변환(Bridge)
- CPU 상의 텐서와 Numpy 배열은 메모리 공간을 공유하기 때문에, 하나를 변경하면 다른 하나도 변경 됩니다.
텐서를 Numpy 배열로 변환하기
t = torch.ones(5)
print(f"t: {t}")
n = t.numpy()
print(f"n: {n}")결과

-텐서의 변경 사항이 Numpy 배열에 반영됩니다.
t.add_(1)
print(f"t: {t}")
print(f"n: {n}")Numpy 배열을 텐서로 변환하기
n = np.ones(5)
t = torch.from_numpy(n)-Numpy 배열의 변경 사항이 텐서에 반영됩니다.
np.add(n, 1, out=n)
print(f"t: {t}")
print(f"n: {n}")-결과

코딩 함 맛있게 요리해보겠심더
좋은 글 감사합니다. 자주 올게요 :)