해당 게시글은 운영체제 스터디를 위해 반효경 교수님 운영체제 강의를 보고 기록한 게시물입니다. 틀린 정보가 있다면 언제든 지적해주세요🙏🏻
가상메모리는 운영체제가 관여하고 실제로 대부분은 페이징 기법을 사용한다.
특히 Demand paging: 요청이 있으면 그 페이지를 메모리에 올리겠다. 방법을 사용한다 이를 통해서
- I/o 양의 감소
- 메모리 사용량 감소
- 빠른 응답 시간
- 더 많은 사용자 수용
할 수 있다.
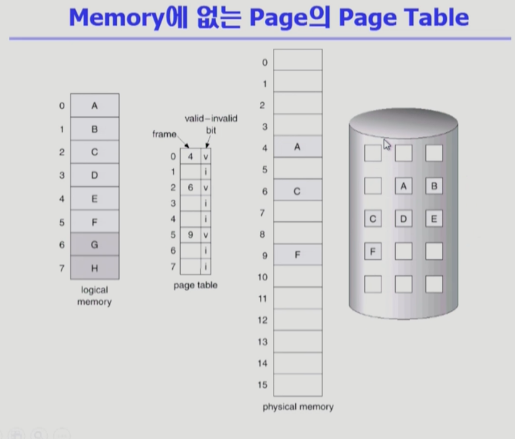
Valid/ Invalid bit의 사용
- Invalid의 의미: 사용되지 않는 주소 영역인 경우, 페이지가 물리적 메모리에 없는 경우
- 처음에는 모든 페이지 엔트리가 invalid로 초기화
- Address translation 시에 invalid bit이 set되어 있으면 page fault
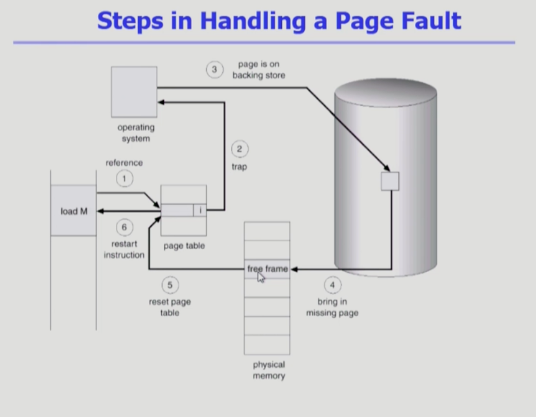
Page fault
- Invalid page를 접근하면 MMU가 trap을 발생시킴 (page fault trap)
- Kernel mode로 들어가서 page fault handler가 invoke됨
- 다음과 같은 순서로 page fault를 처리한다.
- Invalid reference? -> abort process
- Get an empty page frame 없으면 뺏어온다: replace
- 해당 페이지를 disk에서 memory로 읽어온다
- disk I/o가 끝나기까지 이 프로세스는 cpu를 preempt 당함(block)
- disk read가 끝나면 page tables entry 기록, valid/invalid bit = “valid”
- ready queued process를 insert -> dispatch later
- 이 프로세스가 cpu를 잡고 다시 running
- 중단되었던 instruction을 재개
대부분의 경우 Page fault가 발생하지 않는다. 하지만 Page fault가 한 번나면 엄청난 시간을 겪어야 한다...
Optimal algorithm
- min(opt): 가장 먼 미래에 참조되는 Page를 replace
- 미래의 참조를 어떻게 아는가? Offiline algorithm
- 다른 알고리즘의 성능에 대한 upper bound 제공
Belady’s optimal algorithm, MIN, OPT 등으로 불림

미래를 모르는 상태에서 사용하는 알고리즘
미래를 모를땐 어떻게 하나? 과거를 보면 된다.
- FIFO: 먼저 들어온 것을 먼저 쫓아내는 방법
메모리를 크기를 늘려도 성능이 좋아지지 않고 성능이 나빠질 수 있다.
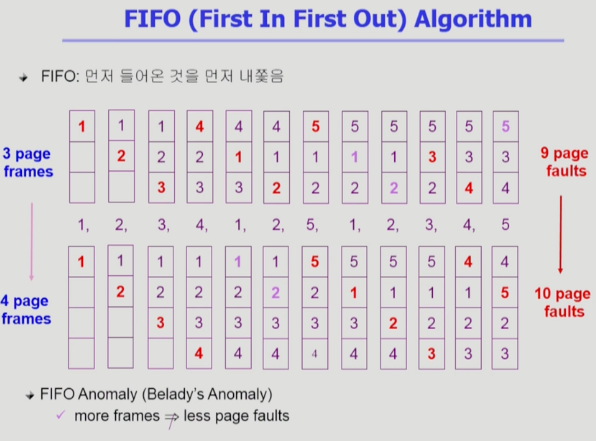
- LRU: 가장 오래된 걸 쫓아내는 방법.

- LFU: 참조횟수가 가장 적은 페이지를 쫓아내는 방법

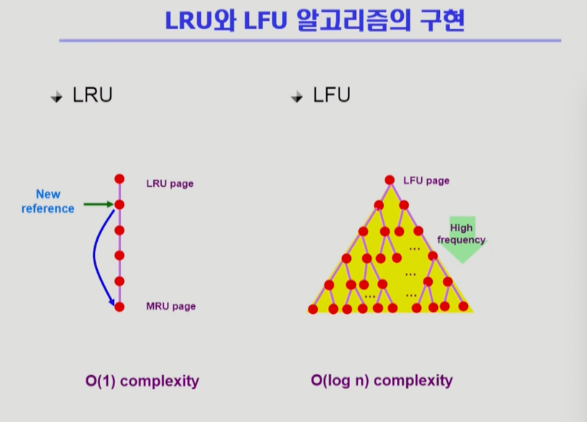
LRU와 LFU의 비교
LRU알고리즘은 리스트형태로 구현하게 된다면 복잡도는 O(1)

LFU알고리즘은 O(n) 복잡도를 가지게 되어서 힙 형태로 구현하게 된다
캐슁 환경
교체 알고리즘은 페이징에만 쓰이는 것이 아니라 다양한 곳에서 쓰이는데 이를 캐슁 환경이라고 할 수 있다.
빠른 공간의 갯수가 한계가 있기 때문에 다양한 캐슁 환경에서 캐슁 기법을 사용할 수가 있다.

Clock Algorithm
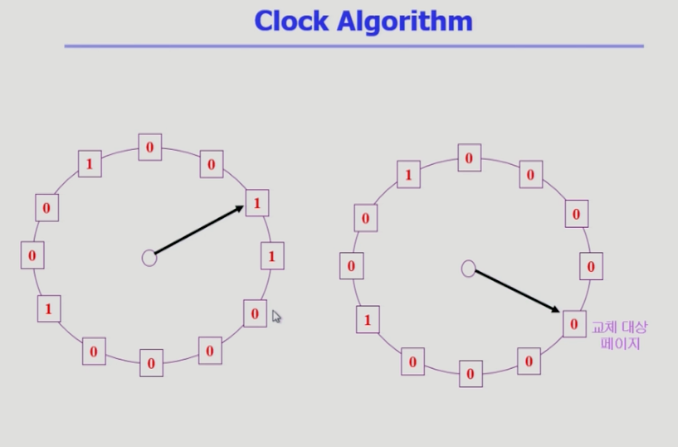
- 클락 알고리즘을 second-chance 알고리즘이라고도 부름.
- 읽기가 발생했을 때는 reference bit을 1로 만들고 쓰기가 발생 했을 때는 reference bit과 modified bit둘다 1로 만든다.
- 수정이 되었으면 수정된 것을 디스크에 써주고 쫓겨나야 하니 modified bit를 사용
-> 그냥 쫓겨날 것이냐 디스크에 쓰고 쫓겨날 것이냐의 차이

Page Frame의 Allocation
각 프로세스에 프레임을 할당.
Allocation problem: 각 프로세스에 얼마만큼의 page frame을 할당할 것인가?
Allocation의 필요성
- 메모리 참조 명령어 수행시 명령어, 데이터 등 여러페이지 동시 참조: 명령어 수행을 위해 최소한 할당되어야 하는 frame의 수가 있음
- Loop를 구성하는 page들은 한꺼번에 allocate 되는 것이 유리함: 최소한의 allocation이 없으면 매 loop마다 page fault
Allocation scheme - Equal allocation : 모든 프로레스에 똑같은 갯수 할당
- Proportional allocation: 프로세스 크키에 비례하여 할당
- Priority allocation: 프로세스의 priority에 따라 다르게 할당
Global vs. Local replacement
Global replacement는 할당을 안하는 것
Local replacement은 각 프로세스한테 일단 메모리를 할당해주고 프로세스가 어떤 페이지를 쫓아낼지 결정.
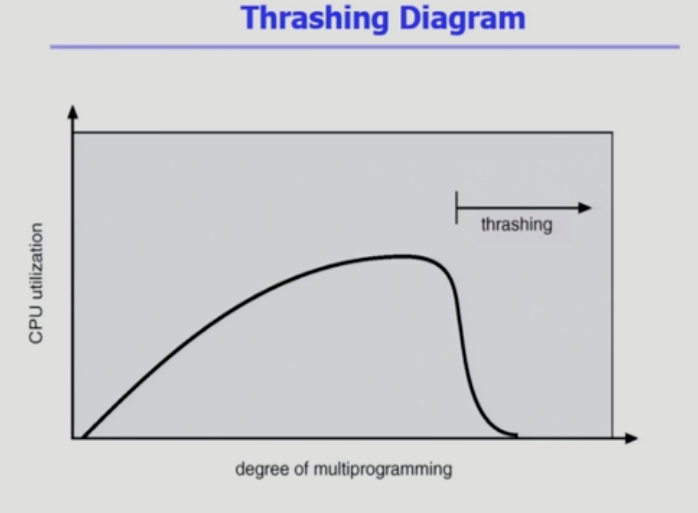
Thrashing
메모리에 올라가있는 프로그램 갯수가 늘어날수록 cpu 사용율이 어떻게 증가하는지 보자.
사용율이 뚝 떨어지는걸 쓰레싱이라고 부르는데
- 프로그램이 원활하게 실행되기 위해서 필요한 최소의 메모리도 갖지 못한 상황.
- 너무 메모리를 조금씩 갖고 있어서 계속 fault가 나오는 상황.
- 프로세스의 원활한 수행에 필요한 최소한의 page frame 수를 할당 받지 못한 경우 발생.
쓰레싱을 막기 위해 그 프로그램에 필요한 최소한의 메모린는 보장하자 -> working set model
Working-set Model
- Locality of reference 프로세스는 특정 시간 동안 특정 메모리를 집중적으로 사용하는 경향이 있다.
- 특정시점에 집중적으로 참조되는 해당 페이지들의 집합을 locality set이라고 한다. Locality set은 적어도 메모리에 보장을 해줘야 프로그램이 원할하게 실행됨
- Working-set Model: 한꺼번에 메모리에 올라와 있어야지만 효율적으로 사용되는 페이지들의 집합을 워킹셋이라고 부름.
- 워킹셋 모델에서는 프로세스의 워킹셋 전체가 메모리에 올라와 있어야 수행되고 그렇지 않을 경우는 모든 프레임을 반납한 후 swap out 된다(suspend)
Working-set algorithm
미래에 어떤 페이지가 쓰일지는 과거를 통해서 추정할 수 있다.
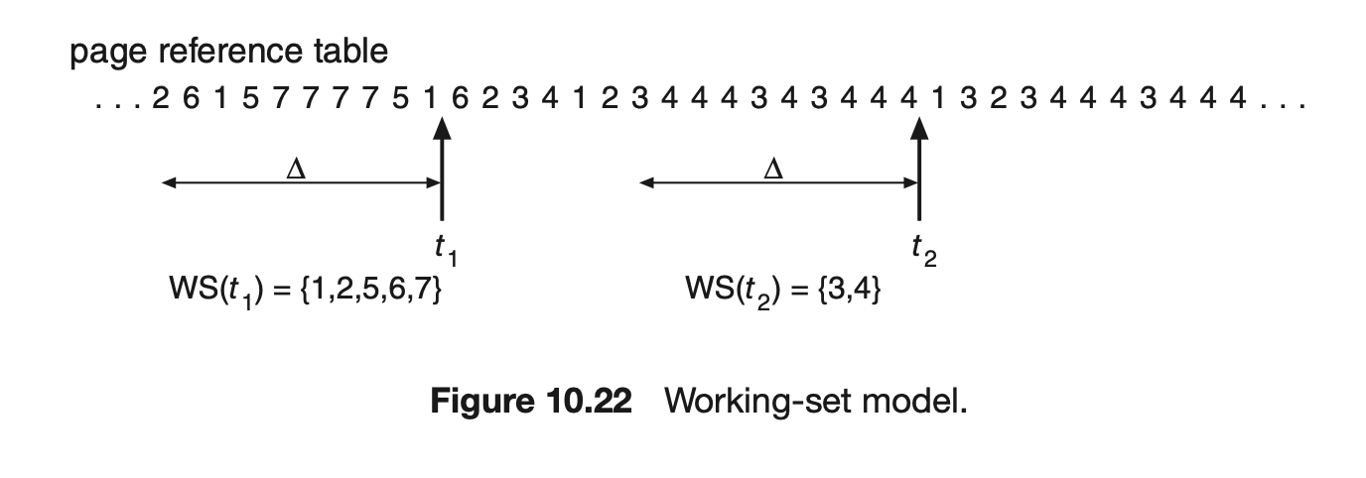
<출처 - Operating System Concepts 10th 2018 by Abraham Silberschatz>
특정윈도우에 크기 이내에 있는 페이지를 워킹셋이라고 인지하고 안에 있는 페이지만 갖고 있고 그렇지 않은 페이지는 버리는 것.
워킹셋을 보장받을 수 있는 프로그램만 메모리에 올려놓고 그렇지 않은 프로그램은 메모리에서 쫓아내는 것
PFF Scheme
각 프로세스의 페이지 폴트 비율을 참고하면서 페이지를 더줄지 덜줄지 결정.
빈 프레임이 없으면 일부 프로세스를 swap out.
페이지 사이즈의 결정
- 페이지 사이즈를 감소시키면
- 페이지 수 증가
- 페이지 테이블 크기 증가
- disk transfer의 효율성의 감소(페이지 사이즈가 작으면 디스크에서 매번 읽어와야 하기 때문에)
- 필요한 정보만 메모리에 올리는 것이라 메모리 이용에 효율적이지만 locality 활용 측면에서는 좋지 않다
현재는 큰 페이지 사이즈가 트렌드.
