해당 게시글은 운영체제 스터디를 위해 반효경 교수님 운영체제 강의를 보고 기록한 게시물입니다. 틀린 정보가 있다면 언제든 지적해주세요🙏🏻
메모리 관리
-
메모리는 주소를 이용해 접근하는 장치. 그 주소에는 두 가지가 있다. Logical Address & Physical Address
-
프로그래머가 주소를 먼저 볼때는 Symbolic Address로 보게 되고 컴파일러를 통해 독자적인 메모리 주소인 Logical Address가 생긴다. 이 후에 Physical Address로 변환한다.
-
물리적 주소로 변환하는 건 누가 하는가?하드웨어
그리고 그 물리적 주소로 변환하는 것을 주소 바인딩이라고 한다
주소 바인딩
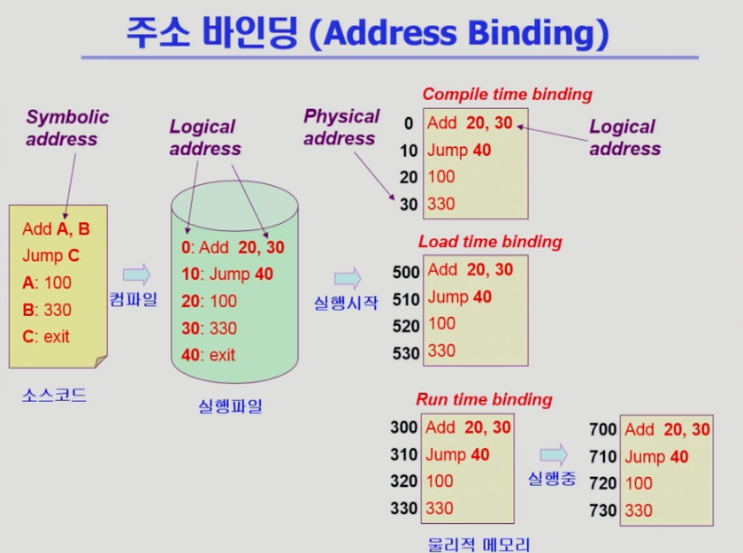
- Compile time binding
- 물리적 메모리 주소가 컴파일 시에 알려짐
- 시작 위치 변경시엔 재 컴파일
- 컴파일러가 절대코드 absolute code 생성
- Load time binding
- 컴파일러가 재배치 가능 코드 relocatable code를 생성한 경우 가능
- Execution time binding (=run time binding)
- CPU가 주소를 참조할 때마다 binding을 점검 -> address mapping table
- 하드웨어적인 지원이 필요 : 매번 주소변환을 해야하기 때문에
- Memory management unit
- Logical Address를 Physical Address로 매핑해주는 것.
다이나믹 로딩
- 프로세스 전체를 메모리에 미리 다 올리는 것이 아니라 해당 루틴이 불려질 때 메모리에 로드하는 것
- 가끔씩 사용되는 많은 양의 코드의 경우 유용
- 예) 오류 처리 루틴
- 메모리 이용률이 좋아진다
- 운영체제의 특별한 지원 없이 프로그램 자체에서 구현 가능
오버레이
- 메모리에 프로세스 부분 중 실제 필요한 부분만 올리는 것
- 다이나믹 로딩과 비슷하지만 역사적인 부분에서 차이가 난다.
- Manual Overay
Swapping
- 프로세스를 일시적으로 메모리에서 쫓아내는 것 -> 디스크로 쫓아냄
- 컴파일 파일 바인딩과 로드 타임 바인딩에서는 스와핑이 지원되기가 어려움
예시) 컴파일 파일 바인딩과 로드 타임 바인딩은 프로그램이 종료될때까지 주소가 유지된다. 이 주소를 메모리에서 Swapping한다면 이후에 메모리에서 여유가 생겼을때 다른 것이 들어올 수 있게 된다. 그렇게 된다면 메모리 주소가 바뀌게 되는데 이때 로드 타임 바인딩은 주소가 바뀌면 안되는 것이기 때문에 다른곳이 다 비어있어도 원래 있던 자리에 올려야함 -> 이것이 비효율적인 측면
스와핑이 제대로 활용되려면 런타임 바인딩에서 활용되는 것이 좋음.

Swapping은 실제로 I/O 하는 양이 많기 때문에 트랜스퍼 시간이 많이 걸린다.
여기까지 저번 내용 짤막 복습
메모리 관리
메모리는 일반적으로 두 영역으로 나뉘어 사용한다
- OS 상주영역: interrupt vector와 함께 낮은 주소 영역 사용
- 사용자 프로세스 영역: 높은 주소 영역 사용
- 페이징 기법은 프로세스를 구성하는 주소공간이 페이지로 쪼개져있다. 일반적인 페이지는 페이지 하나가 4kb.
- 요즘은 더 큰 페이지를 사용하기도 함. 같은 크기로 잘라져서 당장 필요한 페이지만 메모리에 올라가기 때문에 각각의 페이지마다 물리적인 주소가 필요하다. 잘라진 페이지가 많기 때문에 레지스터로는 감당할 수 없다. 그래서 잘라진 페이지를 관리하기 위해서 페이지 테이블이 존재.
Paging
- 프로세스를 동일한 사이즈의 페이지 단위로 나눔
- 당장 필요한 부분은 메모리에 올려놓고 swap area(보조기억장치)에 넣고 씀.

- 외부조각과 내부조각은 비어있는 공간.
외부조각: 공간이 작아서 다른 분할이 들어가지 못하는 공간
내부조각: 할당이 되었으나 사용하지 않는 부분.
-
페이징 기법에서는 적어도 외부조각은 발생하지 않는다. 하지만 내부조각은 생길 수 있다. -> 프로그램을 구성하는 주소공간을 4kb로 자르다보면 마지막에 4의 배수가 된다는 보장이 없기 때문에 자투리 공간이 남을 수 있다.
-
기본적으로 페이징 기법은 프로그램의 주소공간을 페이지로 잘라서 관리하게 됨
-
테이블 == 배열이라고 생각하면 됨. 시스템에서 구현을 위해 만들어진 배열을 테이블이라고 함.
-
테이블에서는 각각의 엔트리에 정보를 담음.
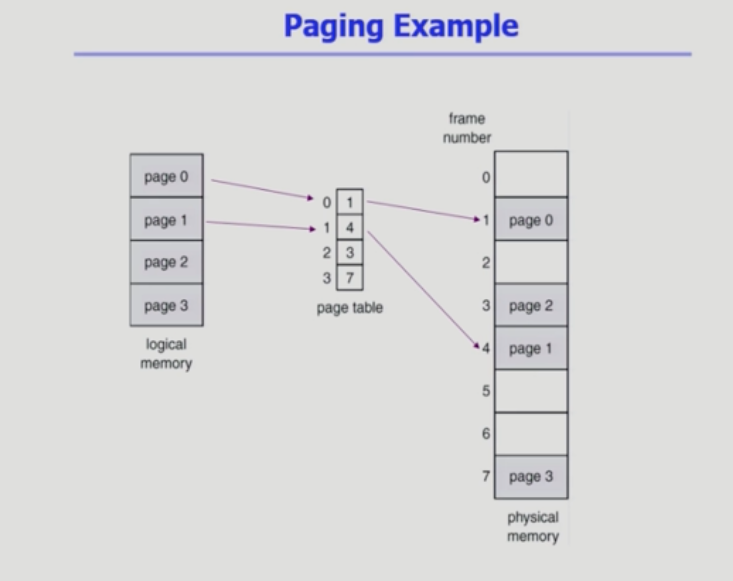 페이지 테이블에 넣기 위해 변환하는 과정에서 앞부분은 페이지 번호 그리고 뒷부분은 페이지가 어디에 위치해 있는지를 나타내는 오프셋이 됨.
페이지 테이블에 넣기 위해 변환하는 과정에서 앞부분은 페이지 번호 그리고 뒷부분은 페이지가 어디에 위치해 있는지를 나타내는 오프셋이 됨. -
프로그램의 페이지 수가 프로세스마다 백만개가 넘어가기 때문에 레지스터에 넣을 수 없어서 페이지 테이블 자체가 메인 메모리에 들어가게 된다.
- 페이지 테이블 베이스 레지스터는 페이지 테이블을 가르키고
페이지 테이블 렝스 레지스터는 테이블 크기를 보관한다.
- 페이지 테이블 베이스 레지스터는 페이지 테이블을 가르키고
-
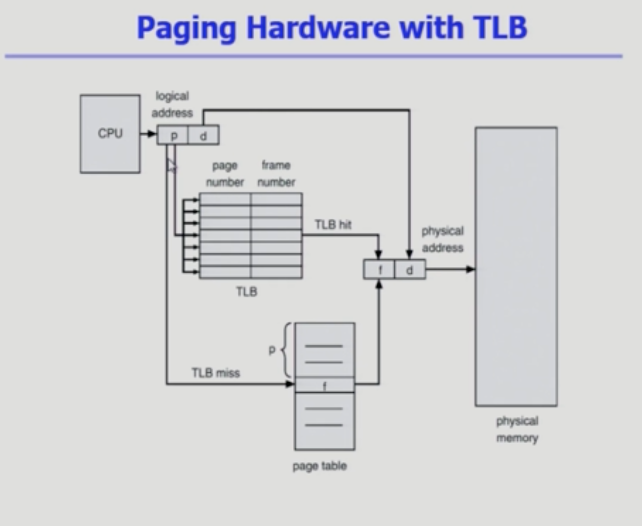
이에 따라 주소변환을 위해서 페이지 테이블에 1번 실제 데이터에 접근 1번 총 두번 하게 된다.
-> 속도 향상을 위해서 캐쉬 메모리(TLB translation look-aside buffer)를 사용한다. (주소 변환을 빠르게 하기 위함)
캐시 메모리에는 두 종류가 있는데 데이터를 위한 것과 주소변환을 위환 것. 여기에서 말하는 것은 주소변환.
페이지 테이블의 일부를 TLB에다가 담고 있어서 더 빠르게 주소 변환 할 수 있다.
-
TLB는 인덱스를 통해서 접근하는 것이 아니기 때문에 논리적 페이지 번호와 프레임 번호를 둘다 갖고 있어야 한다.
(페이지 테이블은 인덱스가 그 역할을 하기 때문에 논리적인 페이지 번호가 필요 없음.) -
TLB는 위에서 부터 모두 탐색해서 오버헤드가 큼 -> 그래서 병렬적으로 찾는 하드웨어 associateive register를 사용한다.
-
프로세스마다 페이지 테이블이 있다.

2단계 페이지 테이블
- 주소를 주면 안쪽 테이블을 통과해서 주소를 얻게 된다.
공간상 이득을 볼 수 있음.
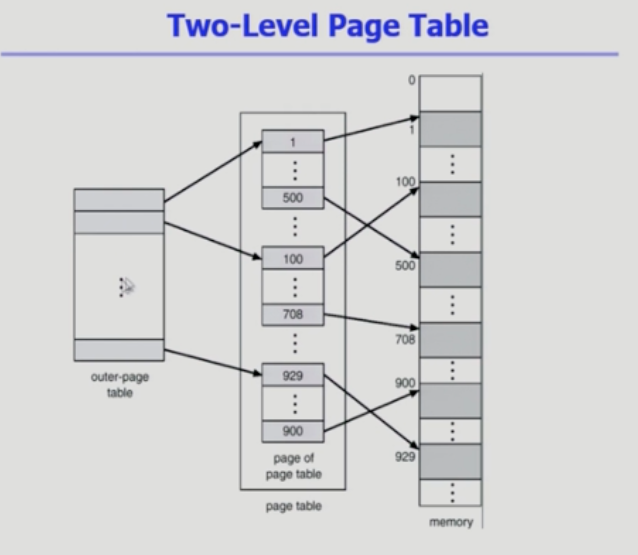
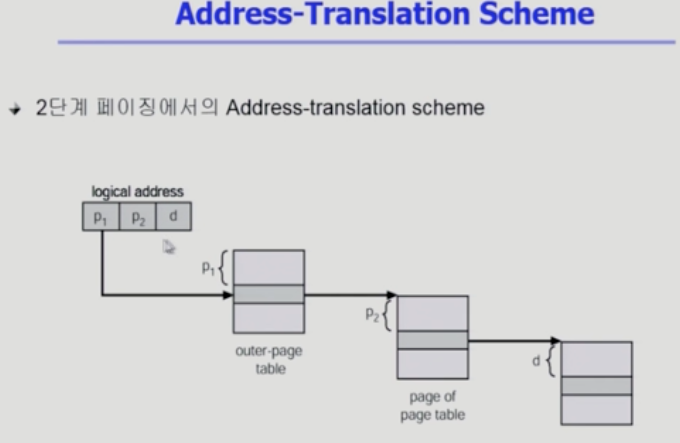
물리적인 메모리 관리는 어디에서 할까? 이 일은 하드웨어에서 하는일
메모리 관리에서 가장 중요한 일은 주소변환 -> 운영체제는 하는 일이 없고 하드웨어가 해준다
메모리 프로텍션
페이지 테이블의 각 엔트리마다 아래의 bit를 둔다
- Protection bit - 페이지에 대한 접근 권한
일종의 접근 연산. - Valid-invalid bit
Inverted page table
페이지 테이블이 매우 큰 이유? 모든 프로세스 별로 그 로지컬 어드레스에 대응하는 모든 페이지에 대해 페이지 테이블 엔트리가 존재하기 때문.
- Inverted page table은 페이지 프레임 하나당 페이지 테이블에 하나의 엔트리를 둔 것으로 각 페이지 테이블 엔트리는 각각의 물리적 메모리의 페이지 프레임이 담고 있는 내용을 표시한다.
- 단점은 테이블 전체를 탐색해야함
- 이 단점을 보완하기 위해 associative register사용
Shared page
- Shared code
- re-entrant code(=pure code)
- Read-only로 프로세스 간에 하나의 code만 메모리에 올린다.
- Shared code는 모든 프로세스의 logical address space에서 동일한 위치에 있어야 한다.
- Private code and data
- 각 프로세스들은 독자적으로 메모리에 올림. Private data는 logical address space의 아무 곳에 와도 무방
Segmentation
-
프로세스를 구성하는 주소공간을 코드, 데이터, 스택 각각 주소공간이 가지고 있는 의미를 기준으로 주소 공간을 자르고 각각의 segment는 물리적인 메모리의 서로 다른 위치에 올라갈 수 있도록 하는 것.
-
프로그램은 의미 단위인 여러 개의 segment로 구성. segment는 다음과 같은 logical unit들임.
-
Logical Address는 다음의 두 가지로 구성 <segment-number, offset>
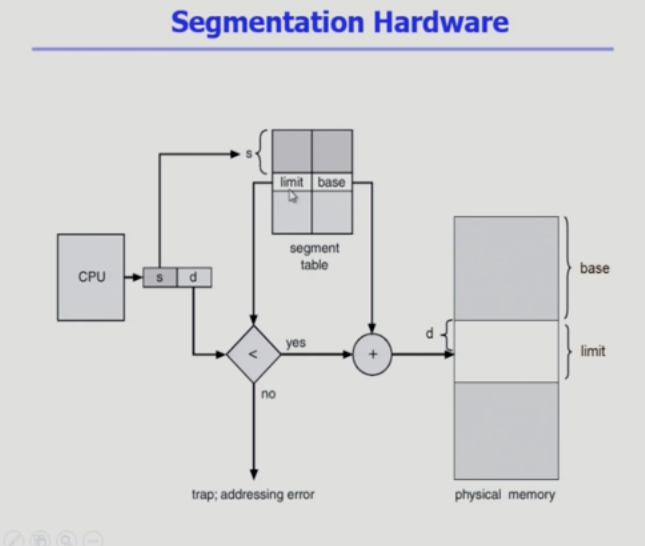
-
segment 길이가 각각 다르기 때문에 segment의 길이가 필요하다. -> 세그먼트 테이블이 이를 담고 있다.
-
세그먼트의 길이가 균일하지 않기 때문에 세그먼트의 시작을 알려주는 베이스 위치는 바이트 값이다.

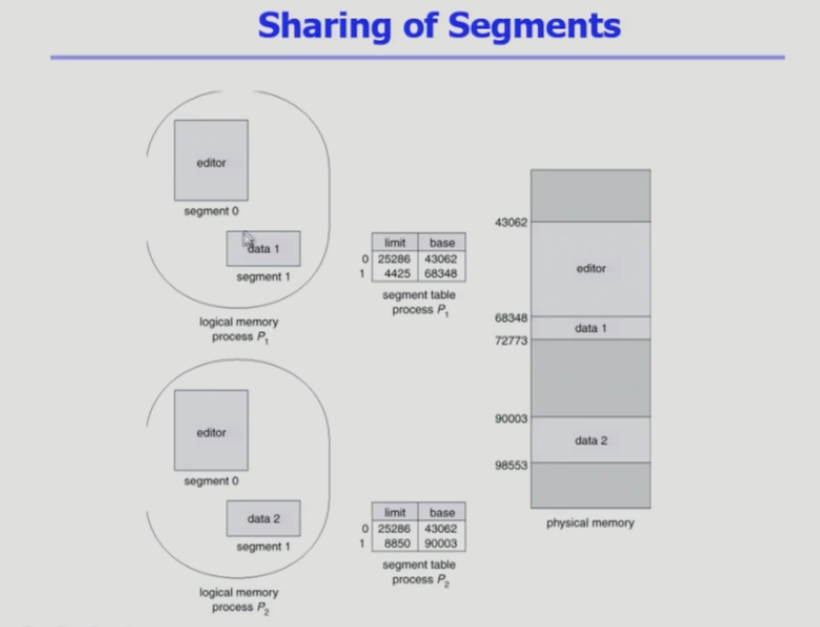
- 크기 단위로는 페이징이, 의미 단위로는 Segmentation이 유리하다
-> 논리적으로 이러하나 현실적으로 구현하기에는 Segmentation은 세그먼트 구성 개수가 많지 않다. 이에 반해 하나의 프로그램 구성하는 페이지가 굉장히 많다.
세그먼트 테이블은 엔트리수가 얼마 안되고 페이지는 아주 많기 때문에 현실적인 구현 측면에서보서는 메모리 공간 낭비는 페이징이 훨씬 심하다. 세그먼테이션은 상대적으로 적다.
Segmentation 자체를 메모리에 넣지 않고 캐시나 레지스터에 올려서 사용하는 다른방법도 생각할 수 있겠다.
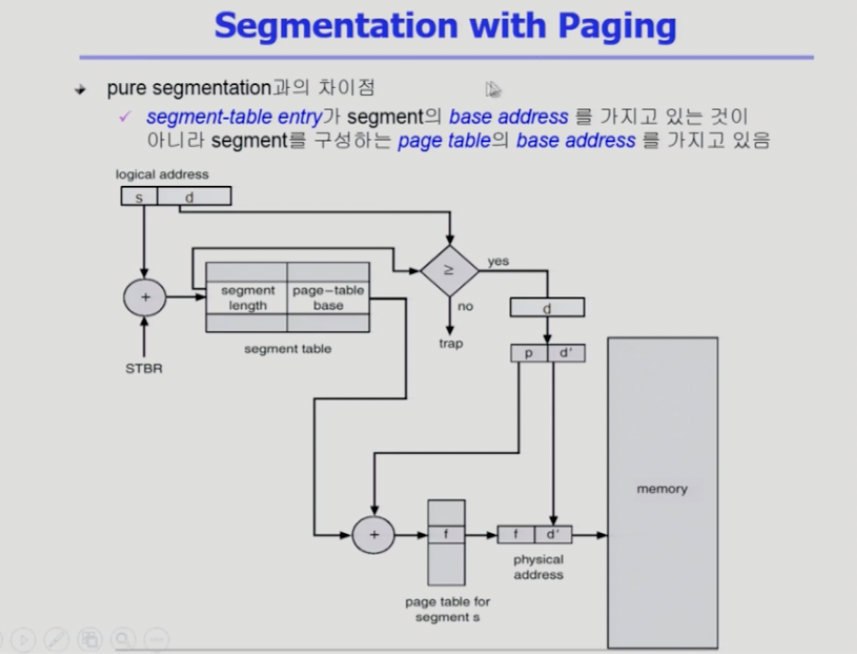
Paged segmentation
그래서 혼합한다면 세그먼테이션과 페이징을 혼합하는 방법을 쓸수도 있다.
기본적으로 세그먼테이션 방법을 쓰지만 세그먼트가 페이지로 각각 구성된다
세그먼트 크기가 페이지 길이의 배수가 된다.
세그먼트를 구성하는 페이지를 쪼개서 물리적인 메모리에 들어가게 구현.
세그먼트의 시작위치는 STBR(세그먼트 테이블 베이스 레지스터)가 가지고 있다